Sharp Monocular View Synthesis in Less Than a Second
Abstract: We present SHARP, an approach to photorealistic view synthesis from a single image. Given a single photograph, SHARP regresses the parameters of a 3D Gaussian representation of the depicted scene. This is done in less than a second on a standard GPU via a single feedforward pass through a neural network. The 3D Gaussian representation produced by SHARP can then be rendered in real time, yielding high-resolution photorealistic images for nearby views. The representation is metric, with absolute scale, supporting metric camera movements. Experimental results demonstrate that SHARP delivers robust zero-shot generalization across datasets. It sets a new state of the art on multiple datasets, reducing LPIPS by 25-34% and DISTS by 21-43% versus the best prior model, while lowering the synthesis time by three orders of magnitude. Code and weights are provided at https://github.com/apple/ml-sharp

















Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces SHARP, a fast way to turn a single photo into a 3D scene you can look around in. It predicts a detailed 3D model from one image in less than a second on a standard graphics card, and then renders nearby viewpoints smoothly at over 100 frames per second. The views look sharp and realistic, and the 3D scene has a true, real-world scale, which is helpful for AR/VR.
Objectives
The researchers wanted to make it easy to “peek around” inside a photo without long wait times or blurry results. In simple terms, they asked:
- Can we build a high‑quality 3D scene from just one picture, quickly?
- Can we render nearby viewpoints (like small head movements) in real time and keep the image sharp?
- Can the 3D scene have a real size (metric scale) so it works properly with devices like AR/VR headsets?
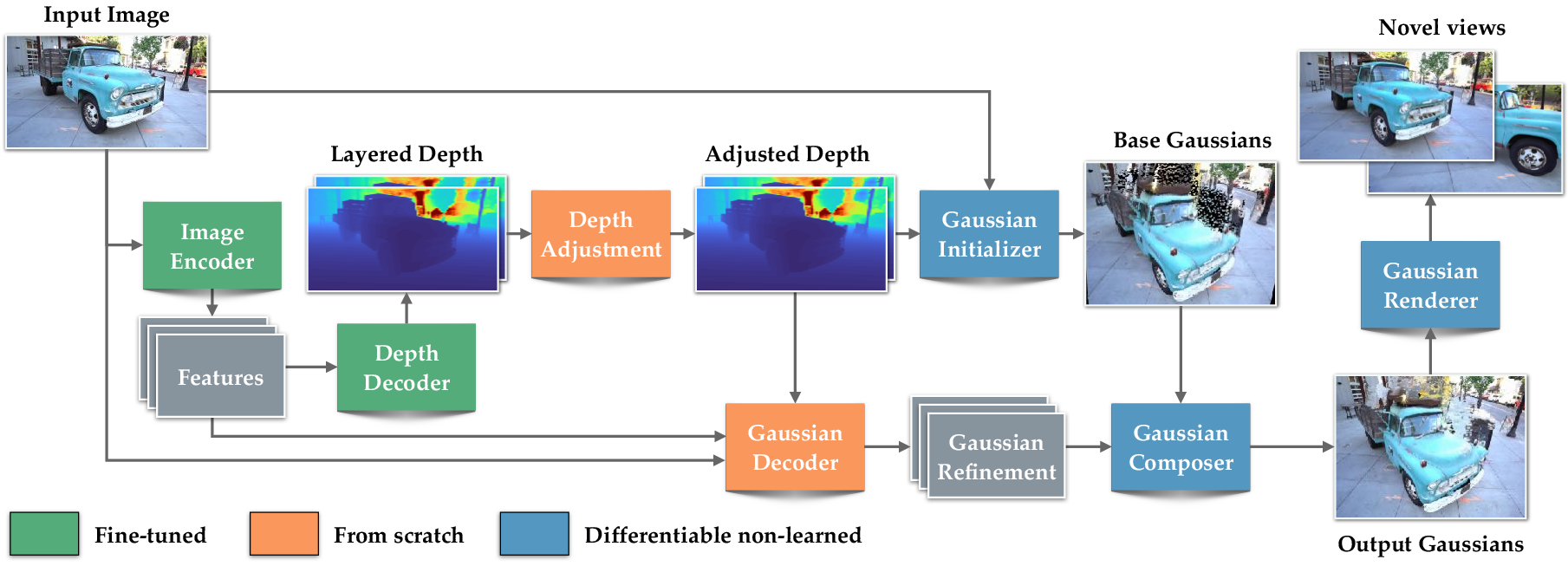
How SHARP Works (in everyday language)
Think of a photo as a window into a scene. SHARP tries to rebuild that scene behind the window so you can lean left or right and see slightly different views.
To do this, SHARP represents the world using millions of tiny, soft “blobs” in 3D. These blobs are called “3D Gaussians.” Each blob has:
- a position in space,
- a size and orientation,
- a color,
- and a transparency level.
Imagine painting a scene using lots of fuzzy, colored dots that, together, look like a realistic 3D picture. That’s the idea.
Here’s the simplified pipeline:
- It takes in one RGB image.
- It estimates depth (how far things are) for each pixel. Depth can be tricky from one image, so SHARP also learns a small “depth adjustment” that fixes common errors (like shiny or transparent surfaces).
- It uses the depth and color to place and initialize millions of 3D blobs.
- A neural network then refines all blob attributes (position, color, size, etc.) to make the 3D scene look right.
- A fast renderer draws new views from this 3D scene in real time.
Training uses two stages:
- Stage 1 (synthetic data): The model learns on clean, computer‑generated scenes where the correct depth and views are known. This teaches the basics of how 3D scenes should look.
- Stage 2 (real images): The model fine‑tunes itself using real photos. It creates a “pseudo” new view from each photo, then learns to match the original photo from that new viewpoint. This self‑supervision helps it handle real‑world messiness.
About “metric scale”: SHARP’s 3D scene isn’t just a guess; it has a true size. That means moving a camera by, say, 5 cm in the virtual world lines up with a real 5 cm movement in the physical world—important for AR/VR headsets.
Explaining a few terms simply
- Monocular: Using just one camera image.
- View synthesis: Generating what a scene would look like from a slightly different position or angle.
- 3D Gaussian: A soft 3D dot (like a tiny fuzzy ball) that contributes color and shape to the final image.
- Renderer: The program that turns the 3D scene into a 2D image you can see.
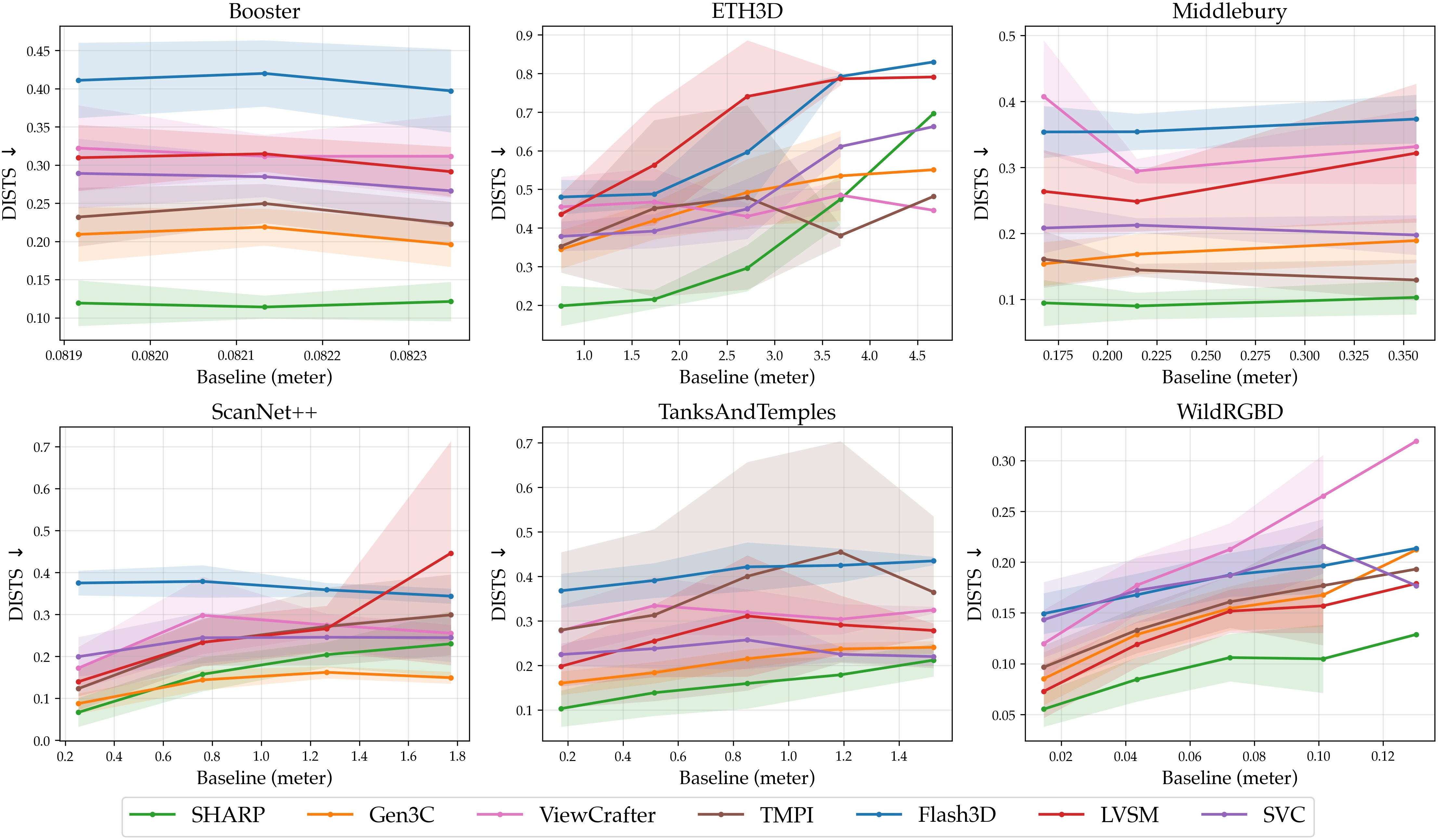
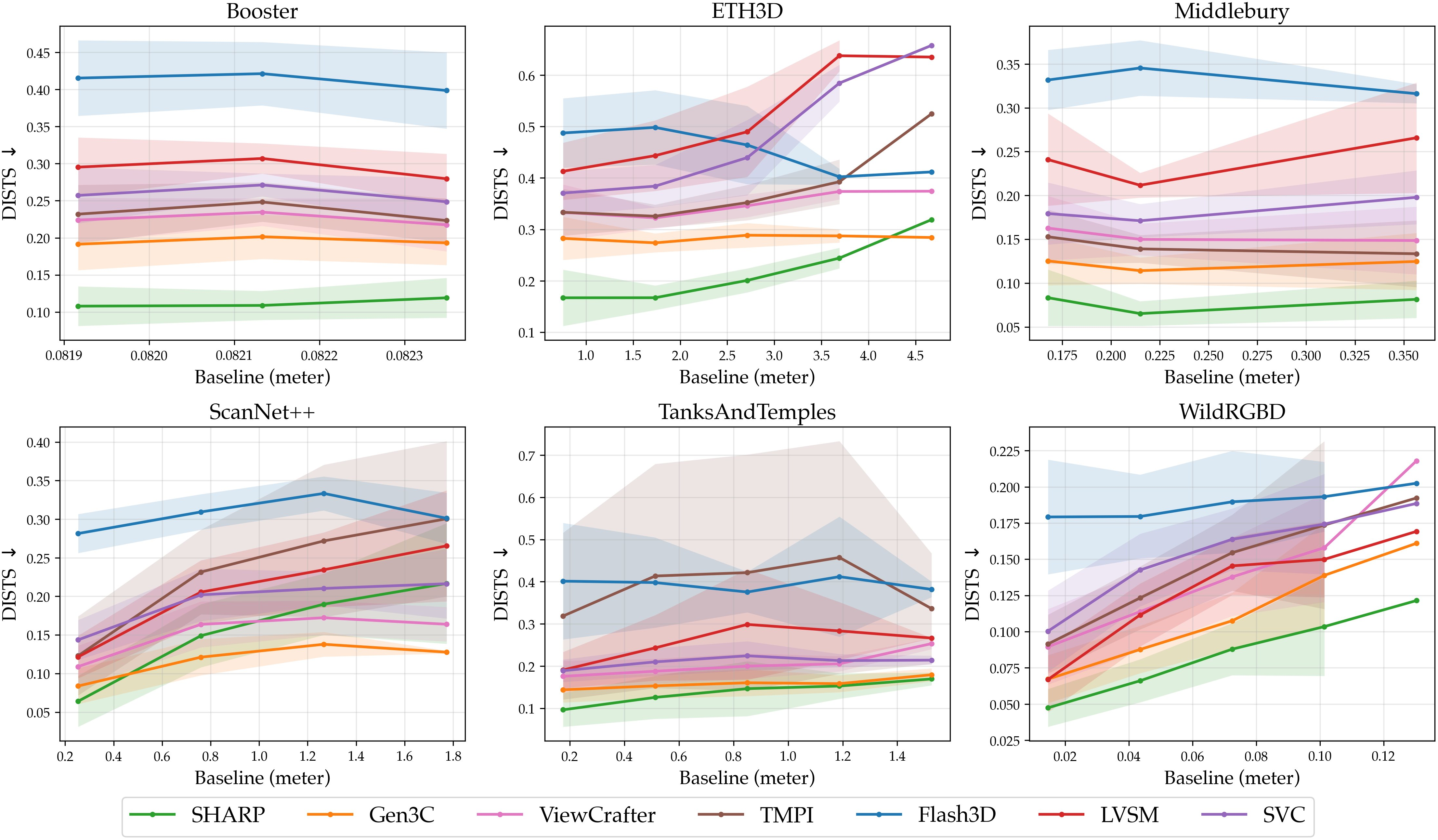
- LPIPS and DISTS: Scores that measure how similar a generated image looks compared to the real image. Lower scores mean better quality.
Main Findings
- SHARP creates high‑quality 3D scenes from a single photo in under a second, then renders nearby views at over 100 frames per second.
- It produces sharper, more realistic images than previous methods, especially for nearby viewpoints (like natural head movements).
- On multiple benchmarks, SHARP beats other state‑of‑the‑art systems by big margins:
- It reduces LPIPS by about 25–34% and DISTS by about 21–43% compared to the strongest prior model.
- It is also much faster—two to three orders of magnitude faster than many diffusion-based approaches (minutes vs. under a second).
- It generalizes well (zero‑shot) to new datasets it wasn’t trained on.
Why this is important:
- Speed and sharpness together make SHARP practical for interactive experiences—like browsing your photo library and instantly getting a “3D feel” of each picture.
- The metric scale means it can plug into AR/VR with realistic movement.
Implications and Impact
SHARP shows that you can get photorealistic, real‑time 3D views from just one photo—fast enough for everyday use. This could:
- Make AR/VR experiences feel more natural when viewing personal photos.
- Enable apps where you quickly “step into” a memory or turn any single photo into an interactive 3D scene on phones or headsets.
- Serve as a foundation for future systems that also handle faraway viewpoints or combine single images with multi‑view data or video.
Looking ahead, combining SHARP’s speed with the creative reach of diffusion models could extend it to wider camera moves while keeping nearby views crisp and the rendering fast.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper makes strong progress on single-image view synthesis, but it leaves a number of important issues unresolved. The following concrete gaps can guide future research:
- Quantify “nearby views” operationally and report the exact headbox: Define and measure the maximum translation/rotation (in meters/degrees) within which SHARP maintains high fidelity, and characterize fidelity degradation as a function of viewpoint displacement.
- Absolute scale recovery from a single image: Specify how SHARP determines metric scale at inference (e.g., reliance on EXIF intrinsics, focal length priors, or learned scale) and evaluate scale error across cameras with different intrinsics, focal lengths, and sensor sizes.
- Pose and intrinsics handling: The Gaussian initializer ignores source intrinsics and lens distortion; test and report performance on extreme FOV lenses (wide/fisheye), distorted optics, and rolling shutter, and assess whether the normalized-space strategy introduces systematic geometric biases.
- Transparent/reflective/view-dependent effects: Without spherical harmonics and with BCE penalizing alpha on the input view, SHARP may suppress legitimate transparency/specularity. Evaluate and improve modeling of BRDFs, specular highlights, and semi-transparency (e.g., via SH, per-Gaussian view-dependent color, or learned material priors).
- Two-layer depth sufficiency: Justify and test whether two depth layers suffice for complex occlusion chains, translucency, and fine structures; compare against multi-layer or volumetric density representations and quantify memory–quality trade-offs.
- Temporal stability under camera motion: Measure flicker/popping artifacts during continuous viewpoint changes (e.g., short head motions in AR/VR) and introduce/benchmark temporal consistency losses or motion-conditioned decoding.
- Far-view synthesis performance: Provide a controlled study of fidelity vs. view distance, including failure modes for larger parallax, and explore concrete hybrid pipelines (e.g., diffusion-assisted far views + SHARP for near views) with latency/fidelity trade-offs.
- Depth adjustment module training/inference mismatch: Clarify how the depth adjustment is trained in Stage 2 when ground-truth depth is absent, and quantify its impact once removed at inference; explore lightweight test-time depth calibration/adaptation to resolve residual ambiguities.
- Geometry accuracy metrics: Go beyond image metrics and evaluate 3D accuracy (depth RMSE, point cloud completeness, reprojection error, multi-view consistency) to validate the predicted geometry, especially for thin structures and high-parallax views.
- Robustness to real-world capture artifacts: Evaluate SHARP under motion blur, noise/grain, HDR/auto-exposure changes, and strong lighting contrasts; ablate preprocessing or normalization steps that improve resilience.
- Computational footprint and deployability: Report memory usage and throughput for inference and real-time rendering on consumer GPUs (e.g., RTX 3060/4070) and mobile SoCs; explore compression (pruning, quantization) and Gaussian count reduction while preserving quality.
- Scalability to higher resolutions: Assess fidelity and latency at 2K/4K inputs and outputs; study how Gaussian count, decoder capacity, and renderer throughput scale and propose mechanisms for resolution-aware prediction.
- Renderer transparency and reproducibility: The in-house differentiable renderer is not fully specified; release rendering details and benchmark compatibility with public 3DGS renderers to ensure reproducibility and fair comparison.
- Occlusion-aware supervision: The view frustum mask only checks NDC bounds; incorporate true visibility (z-buffer/occlusion tests) in loss masking to avoid supervising occluded regions and quantify the improvement.
- Fairness and domain alignment in comparisons: Several baselines are diffusion-based, trained on non-metric or different domains and sometimes cropped; provide domain-aligned training/evaluation or cross-domain calibration to ensure fair, apples-to-apples comparisons.
- AR/VR coupling pipeline: Describe and evaluate the end-to-end calibration pipeline for coupling the metric 3D representation with a physical headset (pose tracking, scale alignment, drift), including user comfort metrics and latency constraints.
- Data transparency and bias: The synthetic dataset and SSFT pseudo-label generation are only loosely described; release summaries/statistics and analyze scene/material biases (e.g., proportion of glass/metal, thin structures) that may affect generalization.
- Handling dynamic content: The method assumes static scenes; explore extensions for dynamic or transient elements (people, vegetation) and assess failure modes when the single image contains motion blur or moving objects.
- Material/illumination consistency: Investigate physically grounded shading (shadows, interreflections) and consistency under slight viewpoint changes; evaluate whether constant per-Gaussian color leads to shading inconsistencies and propose lightweight learned reflectance models.
- Headset power and thermal constraints: Provide energy and thermal measurements during interactive rendering on edge devices, and propose scheduling/LOD strategies to maintain 100+ FPS under real-world constraints.
- Integration with multi-view/video inputs: Although suggested as future work, specify concrete architectures/training regimes to unify single-view and multi-view/video inputs, and measure gains from using sparse additional frames.
- Failure case taxonomy: Catalog recurring artifacts (floaters, blobby Gaussians, color bleeding, depth “holes”) by scene category and correlate them with specific losses/modules to guide targeted improvements.
Glossary
- 3D Gaussian representation: An explicit 3D scene model using Gaussian primitives with position, scale, orientation, color, and opacity attributes. "SHARP produces a 3D Gaussian representation~\citep{kerbl2023tog} of the depicted scene via a single forward pass through a neural network."
- 3D Gaussian Splatting: A rendering technique that projects 3D Gaussian primitives to the image plane for fast, photorealistic view synthesis. "3D Gaussian Splatting \citep{kerbl2023tog} significantly accelerated rendering while maintaining visual fidelity through explicit 3D primitives."
- Adam optimizer: A stochastic gradient-based optimization algorithm that combines momentum and adaptive learning rates. "We trained the network using the Adam optimizer~\citep{kingma2015iclr} with a cosine learning rate schedule~\citep{loshchilov2017iclr}."
- Alpha (rendered alpha): The per-pixel transparency output of a renderer, used to control opacity. "We apply a Binary Cross Entropy (BCE) loss to penalize rendered alpha on the input view to discourage spurious transparent pixels:"
- Amortized inference cost: A setup where heavy computation is done once, enabling fast reuse during subsequent inference. "In contrast to image diffusion models, the inference cost is amortized: once a 3D representation is synthesized, it can be rendered in real time from new viewpoints."
- Appearance flow: A method that learns pixel-wise 2D flow to synthesize novel views from a single image. "synthesized novel views from a single image through appearance flow."
- Auto-correlation: A statistic measuring similarity of a signal with shifted versions of itself; used in feature-space matching. "This loss matches the auto-correlation of the latent features, further enhancing feature space similarity and boosting image sharpness."
- Backpropagation: The algorithm for computing gradients through networks to update parameters during training. "This enables the full view synthesis training to adapt the depth prediction modules via backpropagation, in conjunction with downstream modules, for the end-to-end view synthesis objectives."
- Binary Cross Entropy (BCE): A loss function commonly used for binary classification or per-pixel alpha supervision. "We apply a Binary Cross Entropy (BCE) loss to penalize rendered alpha on the input view to discourage spurious transparent pixels:"
- Camera extrinsics: The pose (rotation and translation) of a camera in world coordinates. "where and are the intrinsic and extrinsic matrices of the source view, and and are those of the target view."
- Camera intrinsics: The calibration parameters of a camera (e.g., focal length, principal point) describing projection geometry. "where and are the intrinsic and extrinsic matrices of the source view, and and are those of the target view."
- Conditional Variational Autoencoder (C-VAE): A generative model that learns a conditional latent distribution to resolve ambiguity in predictions. "we take inspiration from the line of work on Conditional~Variational~Autoencoders~(C-VAE)~\citep{sohn2015learning}, which addresses the ambiguity by designing a posterior model."
- Cosine learning rate schedule: A learning rate schedule that decays following a cosine function, often improving convergence. "with a cosine learning rate schedule~\citep{loshchilov2017iclr}."
- Cost volume: A 3D tensor encoding multi-view matching costs across depths, used for geometry estimation. "MVSNeRF \citep{chen2021iccv} reconstructed neural radiance fields from a few input images via cost volume processing."
- Dense Prediction Transformer (DPT): A transformer-based decoder for dense outputs (e.g., depth, segmentation) from image features. "Our depth decoder is based on the Dense Prediction Transformer (DPT)~\citep{ranftl2021iccv}."
- DISTS: A perceptual image similarity metric aligned with human visual judgments. "We employ LPIPS~\citep{zhang2018cvpr} and DISTS~\citep{ding2022pami} to quantitatively assess the quality of novel view synthesis."
- Disparity: The inverse of depth, often used for robust supervision and regularization. "We apply an L1 loss between the predicted and ground-truth disparity, only on the input view, exclusively on the first depth layer:"
- Differentiable renderer: A renderer with gradients w.r.t. scene parameters, enabling end-to-end learning. "which can be rendered to arbitrary views using a differentiable renderer."
- Diffusion models: Generative models that iteratively denoise to produce high-quality images or 3D-aware outputs. "Diffusion models have emerged as powerful tools for novel view synthesis with sparse input, offering high-quality results through iterative denoising processes~\citep{Po2023}."
- Feed-forward methods: Approaches that perform a single network pass at inference without per-scene optimization. "SHARP improves image fidelity by substantial factors versus prior feed-forward methods."
- Floaters: Artifacts in 3D Gaussian scenes where isolated semi-transparent blobs appear due to misestimated geometry. "Additionally, we apply a regularizer to suppress floaters with large disparity gradients:"
- Gram matrix loss: A loss that matches feature auto-correlation (style) to improve sharpness or plausibility. "and revived the Gram matrix loss~\citep{reda2022eccv} that was originally designed for style transfer."
- Gradient checkpointing: A memory-saving technique that trades compute for reduced activation storage. "Gradient checkpointing is another option, but it can drastically impair training efficiency."
- HDR environment maps: High dynamic range radiance maps used as environment lighting for realistic illumination. "We also use high-dynamic-range (HDR) environment maps, which are sampled from a curated collection off high-resolution HDRIs."
- Headbox: The physical region of natural head motion around a viewpoint considered for near-view rendering. "supporting a headbox that allows for natural posture shifts while maintaining photographic quality."
- Image-based rendering (IBR): Techniques that synthesize new views using captured images and geometric proxies. "Early image-based rendering approaches synthesized new views with minimal 3D modeling."
- Inpainting: Filling in missing or occluded regions of an image using learned priors. "We employ the perceptual loss aimed at improving inpainting."
- Information bottleneck: A regularization mechanism that constrains latent variables to encode minimal necessary information. "During training this latent vector would be passed through an information bottleneck in the form of a KL divergence."
- Inverse depth: Depth represented as its reciprocal, often beneficial for learning and regularization. "takes both the predicted inverse depth and the corresponding ground truth as inputs"
- KL divergence: A measure of divergence between distributions used to regularize variational posteriors. "During training this latent vector would be passed through an information bottleneck in the form of a KL divergence."
- Layered Depth Images: A representation that stores multiple depth samples per pixel to handle occlusions. "Layered Depth Images \citep{shade1998siggraph} addressed occlusions by storing multiple depth values per pixel."
- LPIPS: A learned perceptual image similarity metric widely used for evaluating visual fidelity. "We employ LPIPS~\citep{zhang2018cvpr} and DISTS~\citep{ding2022pami} to quantitatively assess the quality of novel view synthesis."
- MAE loss: Mean Absolute Error loss, used for robust supervision (e.g., scale maps). "We regularize the depth adjustment with an MAE loss and a multiscale total variation regularizer:"
- Metric poses: Camera poses with known absolute scale enabling physically accurate movement coupling. "We evaluate our approach on multiple datasets with metric poses:"
- Monocular depth estimation: Predicting depth from a single RGB image despite inherent scale ambiguity. "Although monocular depth estimation has made impressive advances in recent years, the depth estimator still needs to deal with the inherent ambiguity of the task."
- Multiplane Images (MPI): A layered plane-based scene representation used for view synthesis and warping. "and multiplane images (MPI)~\citep{zhou2018tog, tucker2020cvpr}."
- Neural radiance fields (NeRF): Continuous volumetric scene representations learned from images to render novel views. "Neural radiance fields (NeRF) \citep{mildenhall2020eccv} introduced continuous implicit representations that support remarkable levels of photorealism~\citep{barron2023iccv}."
- Normalized Device Coordinates (NDC): A normalized 3D coordinate system used in graphics pipelines. "we apply the activation function in NDC space, i.e. we first map "
- Occlusions: Regions hidden from the current viewpoint due to obstructing geometry. "addressed occlusions by storing multiple depth values per pixel."
- Opacity: The per-Gaussian transparency parameter controlling visibility during rendering. "The rotation and opacity are initialized to a unit quaternion and a fixed value of $0.5$, respectively."
- Perceptual loss: A loss computed in feature space to encourage visually plausible synthesis and inpainting. "We further use a perceptual loss~\citep{johnson2016perceptual,gatys2016cvpr,suvorov2021resolution} on novel views to encourage plausible inpainting:"
- PSNR: Peak Signal-to-Noise Ratio, a pointwise metric sensitive to small misalignments. "older pointwise metrics such as PSNR and SSIM can be overly sensitive to small translations"
- Quaternion (unit quaternion): A 4D rotation representation used for Gaussian orientation. "The rotation and opacity are initialized to a unit quaternion "
- Ray transformers: Transformer modules operating along rays to aggregate multi-view features. "IBRNet \citep{wang2021cvpr} generalized image-based rendering across scenes using learned features and ray transformers."
- Scale map: A spatial map of per-pixel multiplicative factors used to adjust depth. "by interpreting as a scale map "
- Self-supervised finetuning (SSFT): Adapting models on real data without ground truth by generating pseudo-supervision. "Stage 2: Self-supervised finetuning (SSFT)."
- Spherical harmonics: Basis functions for representing angular variation (e.g., view-dependent color). "We do not use spherical harmonics~\citep{kerbl2023tog}"
- SSIM: Structural Similarity Index, a pointwise image quality metric. "older pointwise metrics such as PSNR and SSIM can be overly sensitive to small translations"
- Tiled Multiplane Images (TMPI): A scalable MPI variant that partitions the image into tiles with fewer planes each. "Tiled Multiplane Images~(TMPI), which splits an MPI into many small tiled regions with fewer depth planes per tile, reducing computational overhead while maintaining quality."
- Total variation regularizer: A smoothness prior penalizing spatial gradients to reduce noise/artifacts. "We apply a total variation regularizer on the second depth layer to promote smoothness:"
- U-Net: An encoder-decoder convolutional architecture with skip connections for dense prediction tasks. "we use a small U-Net~\citep{Ronneberger2015} with 2M parameters"
- Unprojection: Mapping image pixels and depths back to 3D coordinates. "We then unproject the resulting depth map $$ to produce mean vectors"
- Vision Transformer (ViT): A transformer-based image encoder operating on patches or tokens. "The Depth Pro backbone consists of two Vision Transformers (ViTs)~\citep{Dosovitskiy2021}"
- View frustum masking: A technique that masks target-view pixels not visible in the source frustum during supervision. "We implement a view frustum masking technique to address ambiguity in view synthesis~-- regions occluded in the original view have multiple plausible reconstructions."
- View-dependent effects: Appearance changes with viewpoint (e.g., reflections) modeled in layers or properties. "The first layer represents the primary visible surfaces, while the second layer may represent occluded regions and view-dependent effects."
- Volumetric effects: Light transport phenomena like scattering or absorption within a volume. "view-dependent and volumetric effects~\citep{Verbin2024}."
- Warp-back strategy: A training approach that constructs supervision by warping synthesized views back to the source. "AdaMPI~\citep{han2022siggraph} adapted multiplane images to diverse scene layouts through plane depth adjustment and depth-aware color prediction, trained using a warp-back strategy on single-view image collections."
- Zero-shot generalization: Model performance on unseen datasets without task-specific fine-tuning. "Experimental results demonstrate that SHARP delivers robust zero-shot generalization across datasets."
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging SHARP’s ability to convert a single image into a metric, high‑fidelity 3D Gaussian representation in under a second and render it at >100 FPS from nearby viewpoints.
- Consumer photo experiences: interactive parallax and “memory replay”
- Sectors: consumer software, AR/VR, media
- Tools/products/workflows:
- Photo app feature that turns any photo into a 3D “headbox” experience for AR/VR headsets or phones (tilt-to-parallax)
- VR gallery “memory revisit” mode with natural posture shifts
- Dynamic wallpapers/lock screens that react to device motion using the 3D Gaussian asset
- Assumptions/dependencies:
- Best quality for small viewpoint changes (nearby views/headbox); not designed for “walk around”
- Requires known/estimated camera intrinsics for metric coupling to device motion
- Mobile deployment may need on-device GPU/NPU optimization or edge/cloud inference
- Social media and messaging: 3D parallax posts and stories from a single photo
- Sectors: media, advertising
- Tools/products/workflows:
- Server-side SHARP inference that outputs a compact 3D Gaussian asset; client renders real-time parallax
- Templates for subtle dolly/tilt camera moves for short-form content
- Assumptions/dependencies:
- Gaussian renderer support on client (GL/WebGPU/Metal backends or pre-rendered videos)
- Tight moderation/provenance policies for generative 3D content
- E-commerce product pages: interactive micro-views from a single hero image
- Sectors: retail, advertising
- Tools/products/workflows:
- “Inspect in 3D” widget enabling slight perspective shifts (no full spin) for realism and depth cues
- Batch pipeline converting hero images to 3D Gaussian assets for catalog SKUs
- Assumptions/dependencies:
- Optimized for small viewpoint deltas; complex self-occlusions/reflective surfaces may still exhibit artifacts
- Consistent camera metadata across product shoots improves metric scale reliability
- Post-production and design: fast “2.5D” shot effects from stills
- Sectors: film/TV, marketing, creative tools
- Tools/products/workflows:
- Nuke/After Effects/DaVinci Resolve plugin for parallax camera moves, synthetic aperture, and focus pulls from a single still
- Export of 3D Gaussian assets to standard DCC pipelines for previs/animatics
- Assumptions/dependencies:
- Integration requires Gaussian-to-video render or native 3DGS viewers; extreme camera moves will break plausibility
- AR filters and scene anchoring from a single frame
- Sectors: AR frameworks, mobile apps
- Tools/products/workflows:
- Instant background depth and occlusion from a single captured frame for AR stickers/effects
- Metric coupling to head or device pose for natural parallax in AR try-ons
- Assumptions/dependencies:
- Robustness depends on camera intrinsics and device calibration; near-range interactions preferred
- Robotics and autonomy: data augmentation with small viewpoint perturbations
- Sectors: robotics, autonomy, computer vision
- Tools/products/workflows:
- Generate nearby-view augmentations for single-frame datasets to train pose-robust detectors/trackers
- Rapid “what-if” visualizations in teleoperation UIs
- Assumptions/dependencies:
- Domain gap and photometric inconsistencies should be accounted for; augmentations limited to small baselines
- UX/UI depth effects across apps
- Sectors: software, operating systems
- Tools/products/workflows:
- Real-time parallax for app backgrounds, widgets, and lock screens using on-device Gaussian rendering
- Assumptions/dependencies:
- Battery/thermal constraints; need efficient GPU/metal implementations or pre-rendered assets
- Real estate and cultural heritage: enhancing single-image archives
- Sectors: real estate, museums, education
- Tools/products/workflows:
- Slight perspective shifts on listing photos; museum kiosks turning historical photos into interactive 3D experiences
- Assumptions/dependencies:
- Small, realistic camera moves; reliable camera metadata improves metric accuracy
- Research and ML engineering: training recipes and tooling
- Sectors: academia, ML infrastructure/software
- Tools/products/workflows:
- Baseline for monocular view synthesis benchmarks; open-source code (github.com/apple/ml-sharp)
- Deploy the depth adjustment module and self-supervised finetuning (SSFT) in other monocular tasks to reduce ambiguity
- Apply the “computation-graph surgery” strategy to keep perceptual-loss training memory-efficient in large models
- Assumptions/dependencies:
- Requires differentiable Gaussian renderer and modern GPU stack; careful hyperparameter tuning for perceptual losses
Long-Term Applications
These directions require further research (e.g., better handling of faraway views), scaling, or engineering to reach production maturity.
- Full 6-DoF “walk-around” experiences from a single image
- Sectors: AR/VR, gaming, media
- Tools/products/workflows:
- Hybrid pipelines combining SHARP’s fast regression with diffusion priors or distilled models for faraway views
- Unified single-/multi-view/video view-synthesis workflows for creative tools
- Assumptions/dependencies:
- Research needed to maintain near-view sharpness while enabling large baselines; diffusion distillation for latency reduction
- Single-image to production 3D assets (meshes/materials)
- Sectors: gaming, VFX, virtual production
- Tools/products/workflows:
- Converters from 3D Gaussian representations to meshes or neural surface models with PBR materials
- Gaussian-native editing tools (deformation, relighting) and interoperability standards
- Assumptions/dependencies:
- Robust geometry/material recovery from one view is ill-posed; will need priors or multi-shot refinement
- On-device, real-time mobile deployment
- Sectors: edge computing, mobile SoCs, XR devices
- Tools/products/workflows:
- Quantization, pruning, and architecture distillation of the ~340M parameter model
- Hardware acceleration for 3DGS splatting (Metal/Vulkan/WebGPU kernels, NPU offload)
- Assumptions/dependencies:
- Memory/compute budgets on phones/AR glasses; battery/thermal limits; dedicated hardware support
- Video-level dynamic 3D and telepresence
- Sectors: communications, AR passthrough, live media
- Tools/products/workflows:
- Per-frame or keyframe SHARP inference with temporal consistency to yield dynamic 3D scenes from monocular video
- Gaze correction and virtual camera moves in video calls using live Gaussian scenes
- Assumptions/dependencies:
- Temporal coherence, latency constraints, and drift handling; potential fusion with SLAM or optical flow
- Standards and hardware support for 3D Gaussian content
- Sectors: standards bodies, semiconductor, web/graphics platforms
- Tools/products/workflows:
- Open interchange formats for 3D Gaussian assets; web viewers (WebGPU) for real-time rendering
- GPU driver/runtime support and ISA extensions for efficient Gaussian splatting
- Assumptions/dependencies:
- Industry consensus on formats; backward compatibility with existing 3D pipelines
- Content provenance and policy for generative 3D from a single image
- Sectors: policy, platforms, media safety
- Tools/products/workflows:
- C2PA-like provenance tags for 3D Gaussian assets derived from photos
- Platform guidelines for disclosure, watermarking, and responsible AI use in 3D content
- Assumptions/dependencies:
- Ecosystem-wide adoption; robust watermarking for 3D representations
- Healthcare and scientific communication: 3D explainer visuals from limited images
- Sectors: healthcare, education, science communication
- Tools/products/workflows:
- Patient education tools creating depth-enhanced visuals from single clinical photos or microscopy
- Assumptions/dependencies:
- High stakes demand validated accuracy; typically requires domain-specific training and multiple views for reliability
- Improved monocular depth and geometry learning using SHARP’s training techniques
- Sectors: academia, perception research
- Tools/products/workflows:
- Incorporating the depth adjustment module and SSFT regime into monocular depth networks for better scale-consistent outputs
- Loss designs (Gram-matrix-enhanced perceptual loss, frustum masking) for sharper, artifact-suppressed reconstructions
- Assumptions/dependencies:
- Access to metric datasets and differentiable renderers; careful regularization to avoid overfitting to priors
In summary, SHARP’s core innovations—fast single-pass regression to a metric 3D Gaussian scene, real-time high-resolution rendering, a depth adjustment module for ambiguity, and robust training with perceptual/regularization strategies—enable immediate parallax-rich experiences across consumer, creative, and AR use cases, while opening long-term paths toward full 6-DoF, standardized Gaussian content pipelines, and mobile-first deployments.
Collections
Sign up for free to add this paper to one or more collections.