- The paper presents OPV, integrating outcome-based and process-based verification to summarize long chains-of-thought and pinpoint logical errors.
- It employs an iterative active learning framework with rejection fine-tuning and reinforcement learning to update on uncertain reasoning steps.
- OPV outperforms larger models on mathematical benchmarks, reducing annotation costs while improving error detection in complex reasoning tasks.
Outcome-based Process Verifier (OPV): A Paradigm Shift in Efficient Long Chain-of-Thought Verification
Introduction and Problem Motivation
The verification of long chains of thought (CoTs) generated by LLMs is central to developing robust reasoning systems. Traditionally, verifiers are deployed in two major paradigms: outcome-based, which only assesses the final answer against ground truth, and process-based, which attempts fine-grained inspection by verifying each step. However, outcome-based verifiers (OVs) are incapable of detecting erroneous intermediate logic, yielding high false positive rates by accepting flawed derivations that coincidentally yield correct answers. Conversely, process-based verifiers (PVs) have limited efficacy in error localization within complex, lengthy CoTs due to annotation bottlenecks and computational inefficiency.
"OPV: Outcome-based Process Verifier for Efficient Long Chain-of-Thought Verification" (2512.10756) introduces the Outcome-based Process Verifier (OPV), which integrates the strengths of both paradigms. OPV summarizes verbose CoT trajectories into streamlined solution paths, facilitating scalable, high-fidelity intermediate verification. This approach addresses both the inefficiency and brittleness of previous validators as encountered in advanced mathematical reasoning tasks.

Figure 1: Conceptual comparison of OV, PV, and OPV — highlighting OPV's efficient detection of process errors from summarized rationales.
The OPV system consists of two principal stages: solution summarization and structured verification. Given a CoT, OPV performs content summarization, pruning redundant or speculative steps and preserving only the minimal set necessary for the final result. Subsequently, the verifier sequentially inspects each summarized step, issuing a verdict regarding the first logical error and providing a natural language rationale.
Because step-level annotation is expensive, the authors propose an iterative active learning loop. In each iteration, the current OPV identifies solutions with the highest prediction uncertainty (measured by low consistency across multiple rollouts). Human annotators then supply fine-grained judgments — error positions and error explanations — only for these most ambiguous cases. New data updates the verifier using rejection fine-tuning (RFT) and reinforcement learning (RL), leveraging both on-policy data and filtered expert-aligned generation trajectories to maximize training signal.
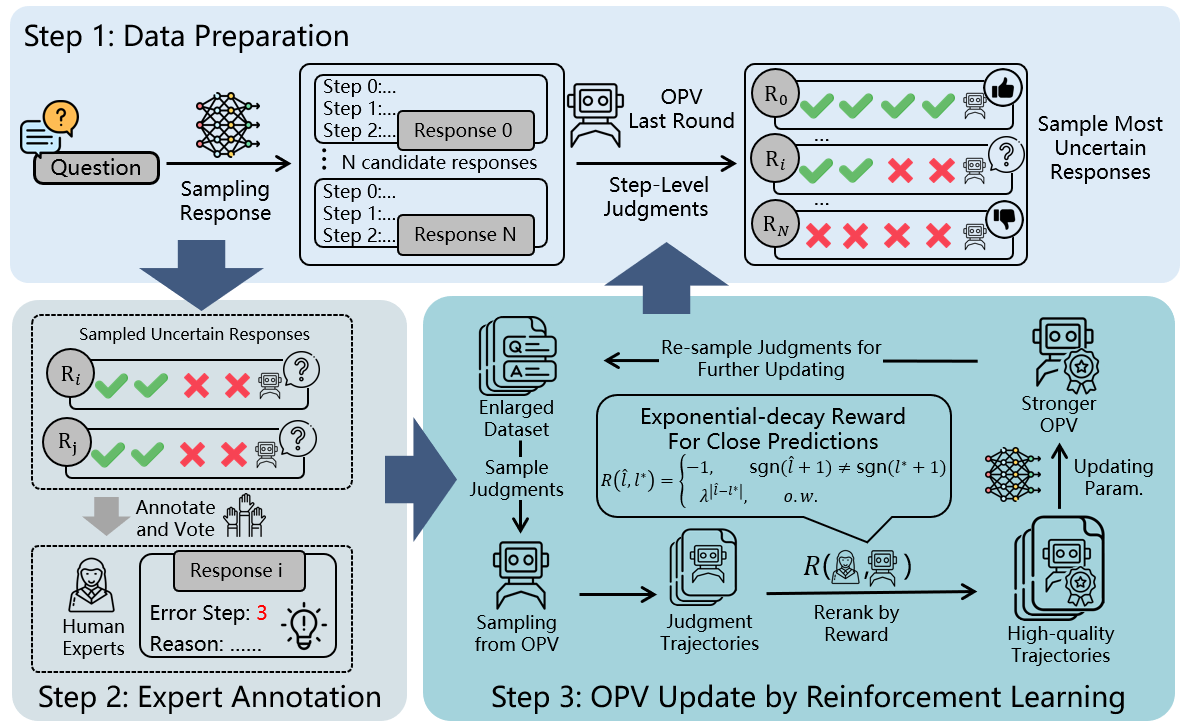
Figure 2: Iterative active learning structure: OPV identifies uncertain samples, experts annotate, and the model is updated using curated data.
This framework supports dataset scaling under a fixed annotation budget and rapidly drives the verifier towards non-trivial error regimes.
Empirical Results and Comparative Evaluation
OPV demonstrates strong performance on multiple mathematical reasoning benchmarks, especially the challenging custom-annotated \texttt{thisbench}, which comprises 2.2k rigorously labeled instances. On \texttt{thisbench}, OPV yields an F1 score of 83.1, outperforming models up to 2x its size, such as Qwen3-Max-Preview (F1: 76.3). OPV also detects false positives in outcome-verified synthetic datasets at a rate matching expert reassessment (estimated 7.0% process errors on AM-DeepSeek-R1-0528-Distilled).
When integrated into collaborative answer selection for policy models, OPV boosts test-time accuracy as the sampling budget increases. For instance, on AIME2025, DeepSeek-R1-Distill-Qwen-32B achieves an accuracy uplift from 55.2% to 73.3% under verifier voting with increased sampling.
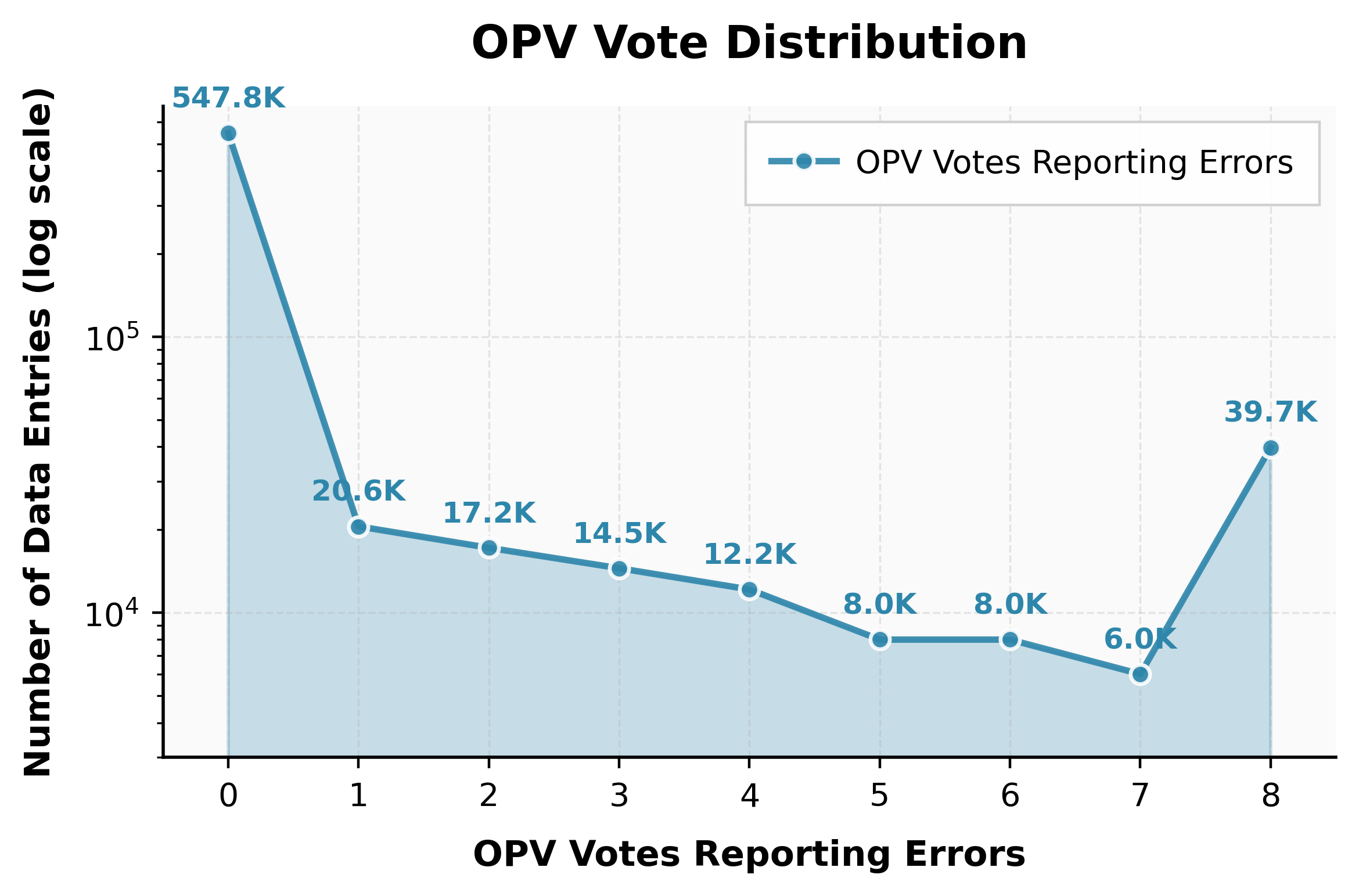
Figure 3: Distribution of OPV votes on AM-DeepSeek-R1-0528-Distilled, illustrating reliable flagging of process errors in synthetic data.
The evaluation also reveals pronounced differences between benchmarks saturated with elementary errors (where all strong verifiers perform similarly), versus benchmarks with subtle logical failures (where OPV outperforms by precise localization and fine discrimination).
Dataset Scaling and Topic Coverage
Active learning enables the construction of a large-scale, high-quality annotated dataset. Over 40k process-annotated solutions spanning K-12, high school competition, and undergraduate-level mathematics were collected, with error annotations distributed across early and mid solution steps. The topic distribution confirms a wide coverage of knowledge domains and mathematical categories, supporting robust generality claims about OPV.
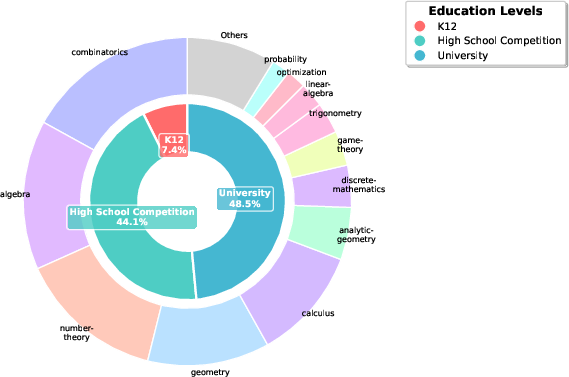
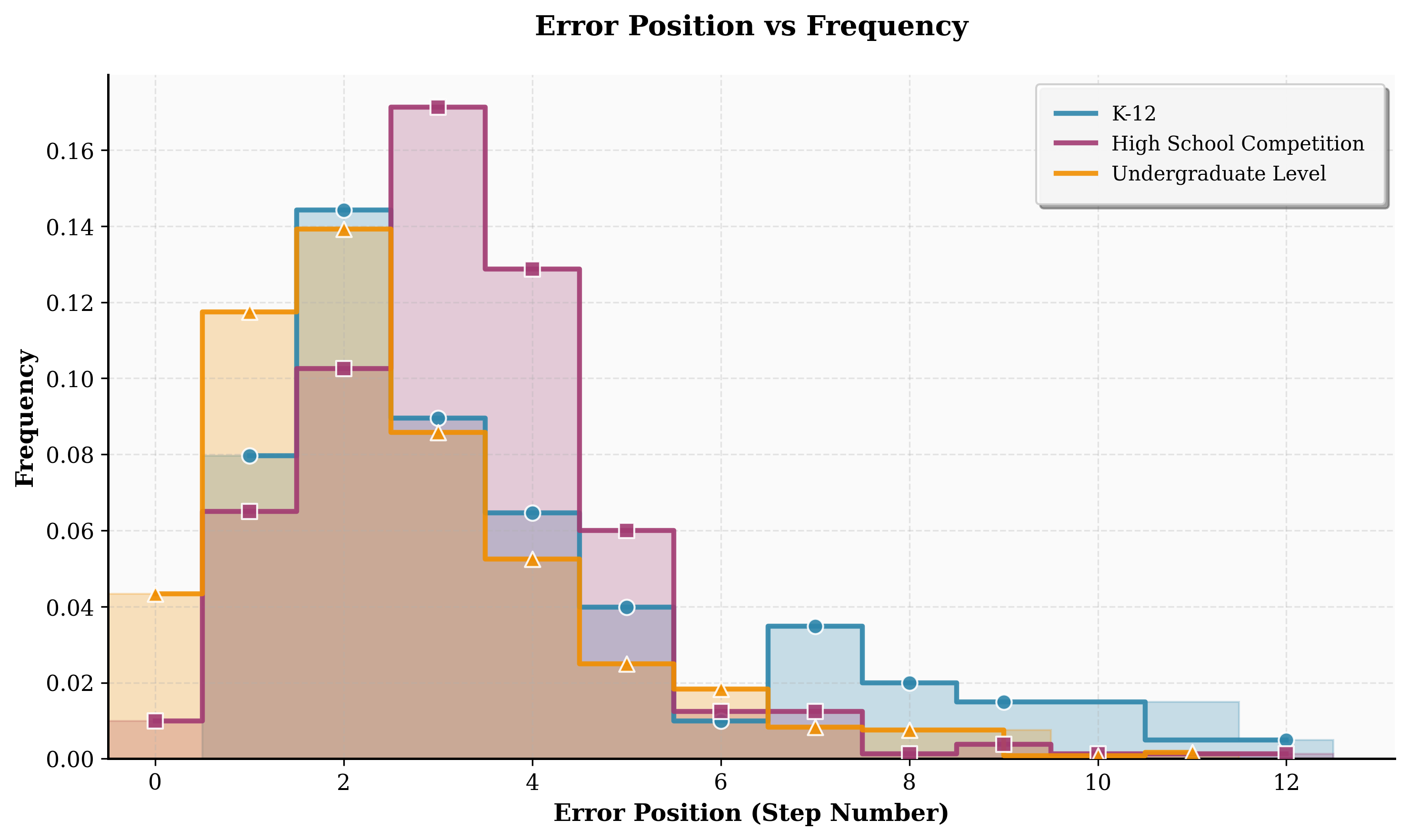
Figure 4: Topic distribution across categories and domains in the expert-annotated dataset, evidencing range and diversity.
Theoretical and Practical Implications
By introducing outcome-based process verification over summarized solution paths, OPV dramatically reduces human annotation cost and verification complexity without sacrificing the granularity required for reliable intermediate checking. This hybrid strategy circumvents limitations of both OVs and PVs: it neither over-relies on correct end results nor becomes trapped by the annotation bottleneck of exhaustive step-level supervision.
Practically, OPV supports both data curation (removing process-invalid synthetic training examples) and collaborative inference-time reasoning (selection of validated chains from sampled generations), unlocking new avenues for scalable, trustworthy LLM deployment in mathematical, scientific, and general multi-step reasoning domains.
Theoretically, outcome-based stepwise verification establishes a framework where the trainability and evaluation of LLMs can exploit aligned supervision at non-terminal solution positions, advancing the study of process reward modeling. The iterative active learning scheme further catalyzes research on effective annotation allocation and scalable reward model construction under fixed budgets.
Limitations and Future Directions
Some limitations persist. OPV's performance can be bounded by the quality of summarization: poor summaries with omitted steps can yield misjudgments. Additionally, the approach's efficacy in proof-heavy or highly non-linear domains may warrant further exploration, as the definition of "key steps" becomes less clear.
Looking forward, integrating differentiable summarization into the verification loop, aligning process reward signals to hierarchical (not merely linear) solution graphs, and extending OPV-like verifiers to non-mathematical domains (e.g., scientific discovery, program synthesis) are natural continuations. Further, automating the expert annotation protocol, including adversarial rounds or LLM-in-the-loop labeling, could facilitate even more scalable dataset expansion.
Conclusion
The Outcome-based Process Verifier (OPV) proposes a highly efficient and scalable paradigm for the verification of long chains of reasoning produced by LLMs. Through solution summarization, targeted expert annotation, and hybrid RL/rejection fine-tuning, OPV achieves strong empirical results and generalizes across problem types and domains. Its framework resolves the annotation-precision dichotomy that hindered prior verifiers and is immediately impactful for both reasoning benchmark construction and trustworthy model deployment. This work substantiates the principle of verifying minimally sufficient rationales for long-form reasoning and positions OPV as a scalable methodological blueprint for future research on process-level oversight in advanced AI systems.