Omni-Attribute: Open-vocabulary Attribute Encoder for Visual Concept Personalization
Abstract: Visual concept personalization aims to transfer only specific image attributes, such as identity, expression, lighting, and style, into unseen contexts. However, existing methods rely on holistic embeddings from general-purpose image encoders, which entangle multiple visual factors and make it difficult to isolate a single attribute. This often leads to information leakage and incoherent synthesis. To address this limitation, we introduce Omni-Attribute, the first open-vocabulary image attribute encoder designed to learn high-fidelity, attribute-specific representations. Our approach jointly designs the data and model: (i) we curate semantically linked image pairs annotated with positive and negative attributes to explicitly teach the encoder what to preserve or suppress; and (ii) we adopt a dual-objective training paradigm that balances generative fidelity with contrastive disentanglement. The resulting embeddings prove effective for open-vocabulary attribute retrieval, personalization, and compositional generation, achieving state-of-the-art performance across multiple benchmarks.








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new tool called Omni-Attribute. It helps an AI “pay attention” to just the part of an image you care about—like a person’s smile, the color of a car, or an art style—while ignoring everything else. Then, it can use that specific attribute to create new images that fit a description, without accidentally copying unwanted details from the original picture.
In short: it’s a way to personalize images by transferring only the chosen attribute, cleanly and faithfully, into new scenes.
What questions did the researchers ask?
The researchers wanted to solve a common problem in image generation: when you try to transfer one attribute (for example, someone’s hairstyle) from a photo to a new image, the AI often drags along extra stuff (like their shirt or lighting), causing “copy-and-paste” mistakes.
They asked:
- Can we teach an AI to extract only the attribute we care about and ignore the rest?
- Can this work for any attribute described in words (open-vocabulary), not just a fixed checklist?
- Can these attribute “representations” be reused and combined—like mixing a vase’s shape from one image and its material from another?
How did they do it?
To make this work, the team designed both special training data and a training method that encourages the AI to focus on the right details.
Building smart training data
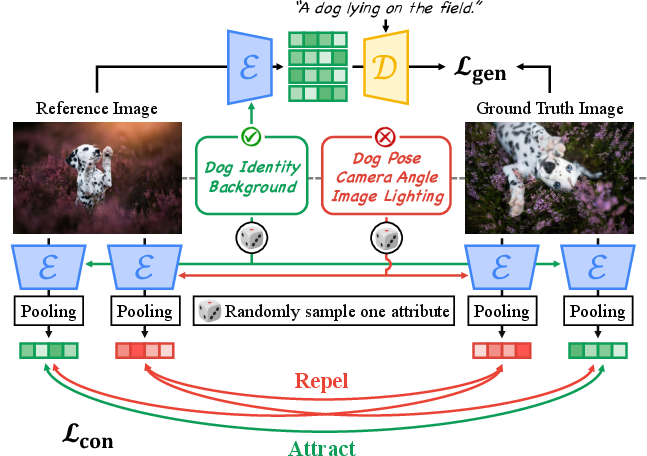
They created pairs of related images and labeled each pair with:
- Positive attributes: things the two images have in common (e.g., both show “smiling,” both have “brown fur”).
- Negative attributes: things that differ (e.g., one has “curly hair,” the other has “straight hair”).
This teaches the AI what to preserve and what to suppress. Think of it like telling a student: “Keep the smile the same, but don’t copy the clothing.”
To scale up high-quality labels, they first used a powerful vision-LLM to annotate carefully, then trained a smaller, faster model to do the same style of labeling. This made the process much cheaper and quicker.
Training with two goals
They trained the attribute encoder with two complementary objectives:
- Generative goal: Make sure the AI can use the chosen attribute from one image to help reconstruct or generate the matching attribute in the paired image. Analogy: if you give an artist a reference smile and a scene description, they should paint that smile accurately in the new scene.
- Contrastive goal: Pull together embeddings (representations) for attributes that should be similar, and push apart those that should be different. Analogy: imagine magnets where “same attribute” magnets attract, and “different attribute” magnets repel. This helps the AI keep attributes clearly separated.
Together, these goals help the model capture fine-grained details of the target attribute while filtering out irrelevant stuff.
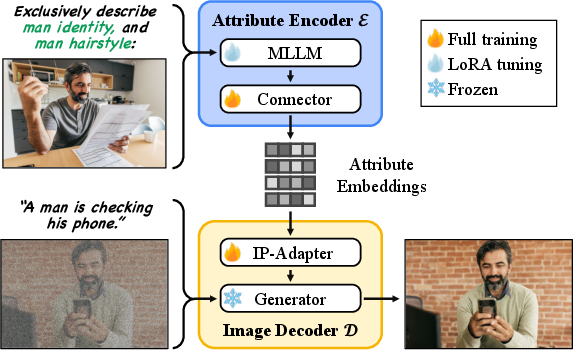
Model design
- Attribute encoder: A vision-LLM that takes both the image and the text attribute (like “hairstyle: bob cut”) as input. It’s lightly adapted using LoRA (a tuning method that tweaks only small parts of the model) to preserve what the model already knows while specializing it for attribute disentanglement.
- Image decoder: A high-quality image generator that takes the attribute representation and a text prompt (like “a portrait near a window”) and creates a new image. A small adapter module helps pass the attribute information cleanly to the generator.
Because the encoder focuses on just the requested attribute, the generator can place that attribute into a new context without copying unwanted elements.
Composing multiple attributes
The learned attribute embeddings are composable. That means you can mix attributes from different sources—for example:
- Take “material: glass” from one vase image.
- Take “pattern: blue flowers” from another.
- Combine them to generate “a glass vase with blue flower patterns” in a new scene.
The system blends these attribute influences in a controlled way, like mixing ingredients in a recipe.
What did they find, and why does it matter?
Across several tests, Omni-Attribute performed better than popular baselines:
- It transferred attributes more faithfully, with fewer “copy-and-paste” errors.
- It worked well not only for concrete things (like “red sneakers” or “blonde hair”) but also for abstract concepts (like “moody lighting” or “cartoonish style”), where many systems struggle.
- It allowed clean composition: mixing attributes from multiple images to create a single coherent output.
- It supported attribute-based image retrieval: given an attribute like “hairstyle,” it could find images with matching hairstyles more accurately than text-based retrieval.
- Human testers and automated evaluations both showed improved naturalness and alignment with the intended attributes and prompts.
Why this matters:
- More control means fewer mistakes in creative workflows, product design, education, and entertainment.
- Being “open-vocabulary” means you can ask for almost any attribute in plain language, not just a fixed list.
What is the potential impact?
Omni-Attribute is a step toward more controllable and interpretable image generation. It helps creators, students, and designers:
- Transfer just the attribute they want (like “smile,” “lighting,” or “style”) into new scenes.
- Combine attributes from different sources without causing visual glitches.
- Search and organize image collections by specific visual attributes.
In practical terms, this can boost creativity, reduce editing time, and make vision-language AI systems easier to use. Overall, it moves image generation from “copying whole pictures” toward “understanding and reusing just the parts you need,” which opens the door to cleaner personalization and richer visual storytelling.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Open-vocabulary generalization: No systematic evaluation on truly long-tail, rare, or compositional attributes (e.g., “Victorian botanical engraving style with rim lighting”), nor on paraphrases, synonyms, and negations; multilingual attribute inputs are not assessed.
- Dataset transparency and scalability: The paper does not report dataset size, distribution, domains, or release plans for the semantically linked image pairs and annotations; the cost/quality/bias trade-offs of the two-stage MLLM annotation pipeline lack quantitative error analysis and robustness checks.
- Annotation reliability: There is no validation of positive/negative attribute labels beyond model intuition (e.g., inter-rater reliability, consistency across different annotators/MLLMs, error typology for mislabeling, and the impact of annotation noise on disentanglement).
- Negative sampling strategy: Contrastive learning uses a single sampled negative attribute with no hard-negative mining, category-aware negatives, or multiple negatives; the effect of negative selection on disentanglement and leakage is left unexplored.
- Pooling choice for contrastive head: Average pooling of token sequences is adopted without comparing alternatives (CLS token, attention pooling, spatial/region pooling, Fisher vectors) or testing sensitivity to pooling on spatially localized attributes.
- Spatial disentanglement and localization: The encoder does not explicitly model spatial extent or masks; performance on attributes requiring spatial control (e.g., “red hat on the head,” “smile only on mouth region”) is not evaluated.
- Generator dependence: Results are tied to a single flow-matching generator with IP-Adapter modules; portability to diffusion backbones, DiTs, VAEs, or other conditioning mechanisms is not assessed.
- Composition scaling and conflict resolution: Linear combination of conditional flow fields lacks principled treatment for conflicting attributes (e.g., “smiling” + “not smiling”), non-linear interactions, and scaling to many (>3–5) simultaneous attributes; automatic weight selection (w_i) is not studied.
- Robustness under distribution shifts: There is no systematic evaluation under occlusions, extreme lighting, cluttered backgrounds, domain shifts (e.g., medical, satellite, cartoons), or adversarial/ambiguous prompts.
- Leakage quantification: Beyond cosine-similarity gaps and human/MLLM scores, the paper lacks standardized disentanglement/leakage metrics (e.g., mutual information estimates, controlled intervention tests, counterfactual analysis).
- Evaluation breadth and scale: Personalization is tested on 350 samples across 15 attributes; larger-scale and more diverse benchmarks (including identity, fine-grained categories, and abstract/compound attributes) are needed for general claims.
- Retrieval evaluation: Attribute-oriented retrieval is demonstrated qualitatively with a bespoke baseline (GPT-4o+CLIP) without quantitative metrics (mAP, Recall@k) or comparison to established retrieval/disentanglement methods (e.g., OADis, DeCLIP, token-based modulation baselines).
- Training objective details: The generative loss φ is underspecified (L2 vs flow-matching vs perceptual losses); the impact of different reconstruction losses, multi-task balancing, and regularizers on fidelity vs disentanglement is not examined.
- Hyperparameter sensitivity: While some contrastive hyperparameters are ablated, there is no systematic analysis of the joint sensitivity of λ_gen, λ_con, τ, connector depth/width, and LoRA ranks on performance and stability.
- Inference efficiency and deployment: The paper claims feed-forward inference but does not report latency, memory footprint, throughput, or on-device viability compared to encoder-only baselines or optimization-based methods.
- Continual learning and extension: How to add new attributes or domains without catastrophic forgetting (for the LoRA-tuned MLLM) is unresolved; procedures for incremental updates or adapters per attribute are not provided.
- Failure modes and diagnostics: No explicit catalog of failure cases (e.g., attribute conflation, over-suppression, artifacts under composition) or diagnostic tools (e.g., attention maps for attributes, attribution analyses) is given.
- Safety and privacy: Identity transfer risks, unauthorized personalization, and potential misuse are not addressed with technical safeguards (e.g., identity consent checks, watermarking, content authenticity signals).
- Cross-lingual and multimodal extensions: The approach is tested on images and English text only; applicability to video personalization (temporal consistency), 3D, or cross-lingual/multiscript attributes remains unexplored.
- Theoretical grounding: The linear composability assumption for conditional flows lacks theoretical analysis; conditions under which attribute embeddings remain additive vs interact non-linearly are not formalized.
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed with the techniques and artifacts demonstrated in the paper, assuming access to a capable multimodal encoder (e.g., Qwen-VL-like backbone), a compatible generator (e.g., flow-matching/diffusion backbone with IP-Adapter), and the curated attribute-paired data or similar training data.
- Attribute-controlled photo and video editing (Software, Creative tools, Social/AR)
- What: Preserve or transfer specific attributes (e.g., identity, expression, lighting, clothing style) while synthesizing new contexts, minimizing “copy-and-paste” artifacts.
- Where: Consumer photo apps, AR lenses (e.g., makeup or hairstyle transfer without background leakage), creator tools, ad post-production.
- Tools/Workflows: Attribute encoder plug-in for diffusion/flow-matching backends; UI to select attribute(s) to keep/transfer; compositional sliders to mix multiple reference attributes.
- Assumptions/Dependencies: GPU inference for encoder+generator; prompt/attribute quality matters; guardrails for sensitive attributes; content usage rights for identity transfer.
- Attribute-aware image retrieval for digital asset management (Media/Advertising, E-commerce, Software)
- What: Retrieve images that match a specific attribute of a query (e.g., “same fabric texture,” “similar smile,” “matching studio lighting”).
- Where: DAM libraries, brand/stock-image platforms, creative search within enterprises.
- Tools/Workflows: Index images with attribute-conditioned embeddings; query by image+attribute text; ranking by cosine similarity in the attribute space.
- Assumptions/Dependencies: Open-vocabulary inputs must align to language priors; precompute embeddings per attribute family or compute on-demand; bias monitoring for human attributes.
- Compositional mood-board to concept synthesis (Design, Fashion, Advertising)
- What: Combine attributes from multiple references (e.g., color palette from A, material pattern from B, silhouette from C) into one coherent image.
- Where: Creative ideation, campaign concepting, style exploration.
- Tools/Workflows: Linear combination of conditional flow fields (as described) with per-attribute weighting; UI for multi-reference mixing and strength tuning.
- Assumptions/Dependencies: Same generator-family as in the paper; attribute mixing may need manual balancing; potential failure modes with many conflicting conditions.
- Product photography augmentation while preserving identity (E-commerce, Retail media)
- What: Keep product identity (logo, shape) while varying backgrounds, lighting, or scene styling for localized creatives and A/B tests.
- Where: Online marketplaces, retail ads, catalog standardization.
- Tools/Workflows: Pipeline that locks “product identity” embedding and varies “lighting/background” attributes via prompts; batch generation API.
- Assumptions/Dependencies: Clear product segmentation or attribute text (“product identity”) provided; brand control policies; generator must render text/logos faithfully.
- Controlled avatar and NPC content generation (Gaming, Social/Avatars)
- What: Generate consistent character identity while changing attire, expression, or environment; compose features from multiple references (e.g., hair from one avatar, outfit from another).
- Where: Character editors, avatar stores, game asset pipelines.
- Tools/Workflows: Attribute encoder feeding a frozen generator; attribute libraries for identity/expression; compositional control for multi-attribute blends.
- Assumptions/Dependencies: Consistency over sequences may require additional temporal smoothing; IP and likeness rights for identity.
- Brand/identity-preserving creative localization (Marketing, Advertising)
- What: Maintain brand identity (mascot, product features) while adapting creative style (seasonal aesthetics, regional motifs) without leaking irrelevant details.
- Where: Global campaign localization.
- Tools/Workflows: Attribute prompt templates (“preserve brand identity; adopt <regional style>”); automated QA based on attribute/text fidelity metrics used in the paper.
- Assumptions/Dependencies: Strong brand-identity prompts; human-in-the-loop review; monitoring for hallucinated or altered brand marks.
- Dataset annotation acceleration using the two-stage MLLM pipeline (Academia, Industry ML teams)
- What: Generate positive/negative attribute annotations on paired images at scale using a high-capacity “teacher” MLLM and a finetuned “student” annotator.
- Where: Building datasets for disentanglement, personalization, retrieval, and editing tasks.
- Tools/Workflows: Train a smaller MLLM on teacher-labeled pairs to reduce cost/latency; integrate Chain-of-Thought-style prompts for richer attributes.
- Assumptions/Dependencies: Access to a capable teacher MLLM; quality control on sensitive or subjective attributes; domain shift for specialized imagery.
- Attribute-oriented evaluation and interpretability dashboards (Academia, Model governance)
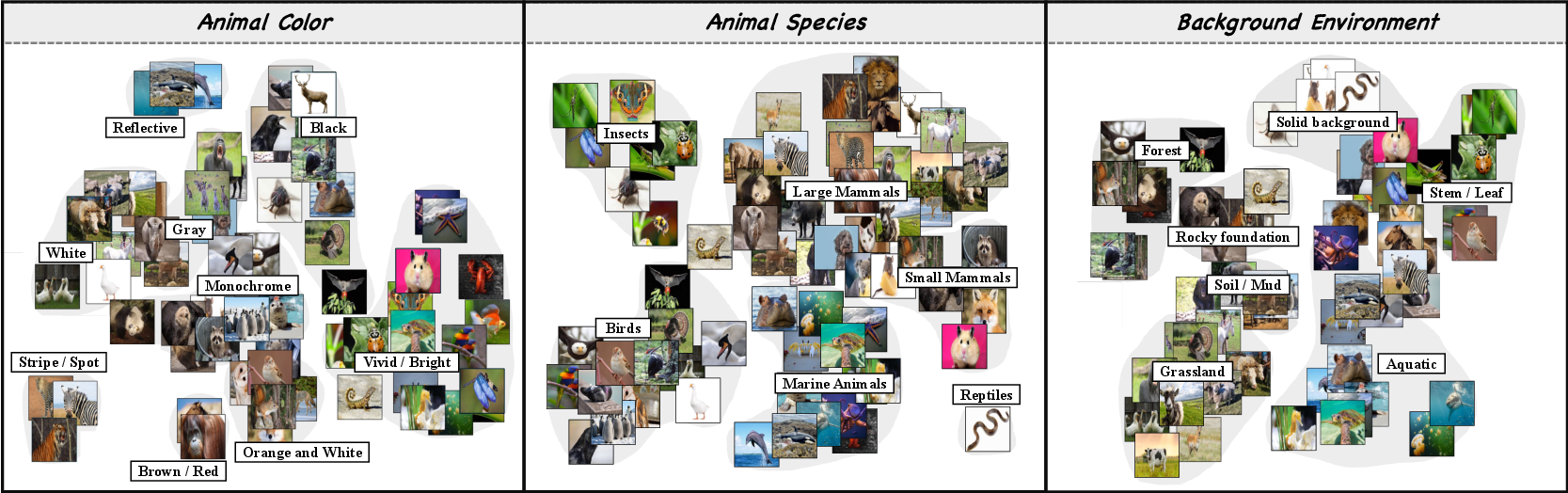
- What: Use attribute-conditioned embeddings and t-SNE-like projections to audit how models encode identity vs. confounders (e.g., lighting, background).
- Where: Research labs, MLOps/Responsible AI teams.
- Tools/Workflows: Visualization suite for per-attribute embedding spaces; cosine-similarity gap metrics between positive/negative pairs for regression tests.
- Assumptions/Dependencies: Reference pairs with attribute labels; caution with human attributes and privacy; comparisons depend on stable encoder versions.
- Creative safety guardrails via attribute filters (Policy, Platform Trust & Safety)
- What: Disallow or down-weight editing requests involving sensitive attributes (e.g., race/skin tone) while allowing others (e.g., lighting, background).
- Where: Content platforms, UGC creation tools.
- Tools/Workflows: Policy-mapped attribute lexicon; pre-checks on input attributes; audit logs recording which attributes were preserved/changed.
- Assumptions/Dependencies: Clear policy definitions; robust detection of paraphrased sensitive attributes; user consent and transparency.
- Benchmarking and reproducible research kits (Academia)
- What: Release the attribute-personalization benchmarks and training code to standardize evaluation of disentanglement and compositional generation.
- Where: Vision & language research, generative modeling.
- Tools/Workflows: Leaderboards covering attribute fidelity, text fidelity, and image naturalness; ablation templates (contrastive/generative loss, temperatures, weights).
- Assumptions/Dependencies: Dataset licenses; standard generator backbones for comparability; community adoption.
Long-Term Applications
These use cases are promising but require additional research, scaling, domain adaptation, or integration work (e.g., better temporal coherence, specialized datasets, or stronger safety frameworks).
- Temporally consistent video attribute transfer (Media production, AR/VR)
- What: Apply per-attribute control consistently across frames (e.g., preserve actor identity while changing lighting or expression in video).
- Gaps: Temporal consistency modules; training on video pairs with attribute annotations; latency constraints for real-time AR.
- Dependencies: Video-capable generators; temporal contrastive objectives; edge acceleration.
- Domain-specific disentanglement (Healthcare imaging, Scientific imaging)
- What: Separate disease-related features from acquisition artifacts (e.g., scanner/lighting) for generation, retrieval, or augmentation.
- Gaps: Domain-supervised attribute vocabularies; regulatory approval; rigorous bias/robustness studies.
- Dependencies: Medical-grade datasets; clinical oversight; certified deployment pipelines.
- Robotics and autonomous systems perception (Robotics, Automotive)
- What: Use attribute-specific embeddings to focus on task-relevant cues (e.g., pose, shape) while suppressing confounders (e.g., lighting, background) to improve generalization.
- Gaps: Real-time constraints; training on robotics-relevant attribute annotations; quantitative gains on downstream tasks (detection, pose).
- Dependencies: On-device acceleration; integration with existing perception stacks.
- Forensic analysis and attribution of edits (Policy, Digital provenance)
- What: Attribute-level “change logs” that describe which visual factors were edited, aiding transparency and deepfake detection.
- Gaps: Secure, standardized metadata formats; watermarking/tamper-evident provenance chains; cross-vendor interoperability.
- Dependencies: Industry standards (e.g., C2PA); regulatory alignment; privacy-preserving logging.
- KYC and identity verification stress-testing (Finance, Security)
- What: Generate controlled attribute variants (lighting, pose) while preserving identity to test robustness of biometric systems.
- Gaps: Ethical and legal frameworks; clear separation from identity spoofing; certified test protocols.
- Dependencies: Secure sandboxes; synthetic data watermarking; governance processes.
- CAD-to-concept and engineering co-design (Manufacturing, Automotive, Consumer electronics)
- What: Preserve product geometry while exploring materials, finishes, and lighting for rapid design iteration.
- Gaps: Tight coupling to CAD/PLM systems; guarantees that geometry/critical dimensions are unchanged; photoreal constraints.
- Dependencies: Domain-aligned attribute vocabularies; high-fidelity material models; validation loops.
- Personalized education and training content generation (Education)
- What: Maintain core concept visuals while adapting context/style (e.g., same geometric proof with different visual styles or scaffolding levels).
- Gaps: Pedagogical validation; accessibility requirements; bias/fairness checks for demographic imagery.
- Dependencies: Curriculum-aligned attribute libraries; educator-in-the-loop tools.
- Cross-modal attribute disentanglement (Multimodal AI, XR)
- What: Extend to audio/3D (e.g., preserve speaker identity while varying emotion; preserve mesh geometry while changing texture/lighting).
- Gaps: 3D/Audio generators with attribute coupling; paired datasets with positive/negative attributes across modalities.
- Dependencies: Multimodal encoders/decoders; dataset creation pipelines akin to the paper’s two-stage MLLM procedure.
- Real-time, on-device attribute editing (Mobile, Edge AI)
- What: Deploy lightweight versions for AR filters that selectively transfer attributes with millisecond latency.
- Gaps: Model compression (LoRA + distillation), efficient generators, memory constraints.
- Dependencies: Hardware acceleration (NPUs), quantization-aware training, caching strategies.
- Policy toolkits for attribute-sensitive generation (Governance, Standards)
- What: Frameworks that classify, restrict, or require consent for certain attributes; standardized disclosures for edited attributes.
- Gaps: Consensus on sensitive attributes and consent flows; audits for open-vocabulary parsing errors.
- Dependencies: Cross-platform adoption; user education; robust NLP to detect attribute semantics.
Notes on feasibility across applications:
- Open-vocabulary generalization depends on the MLLM’s language and visual priors; domain adaptation may be required for specialized use.
- The dual-objective (generative + contrastive) balance must be tuned per domain; large λ_con or temperature values improve disentanglement but can reduce fidelity.
- Compositional generation is powerful but can be unstable with many conflicting attributes; UI affordances (weights, previews) and human oversight help.
- Ethical, legal, and IP considerations are central for identity and human attributes; deploy guardrails and transparency-by-design where applicable.
Glossary
- AdaLN conditioning: Conditioning mechanism using Adaptive LayerNorm parameters to control generative models; often limits control to affine transforms. "the usage of AdaLN conditioning restricts control to simple, limited affine transformations (scale-and-shift)."
- attribute disentanglement: Separation of distinct visual attributes so one can be manipulated without affecting others. "adapt the model to the attribute disentanglement task"
- attribute embeddings: Learned vectors that represent a specific visual attribute from an image-text pair. "the attribute embeddings are required to capture sufficient information for the high-fidelity reconstruction of the target attributes"
- attribute fidelity score: Metric assessing how faithfully a generated image preserves the target attribute. "attribute fidelity score, which measures the faithfulness of the personalized attributes"
- attribute-level embeddings: Representations focused on a single attribute rather than the whole image content. "Learning high-fidelity, attribute-level embeddings is inherently a dual-objective optimization problem."
- attribute-oriented image retrieval: Retrieving images based on similarity with respect to a specified attribute. "attribute-oriented image retrieval"
- Chain-of-Thought: Prompting technique that elicits step-by-step reasoning to improve label quality. "Inspired by Chain-of-Thought, we enhance label quality"
- catastrophic forgetting: Loss of previously learned knowledge during finetuning of large models. "mitigates catastrophic forgetting compared to full finetuning"
- classifier-free guidance (CFG): Technique that combines conditional and unconditional model predictions to steer generation. "generalizing classifier-free guidance (CFG)"
- closed set of attributes: A fixed and predefined set of attributes a model is limited to. "restricted to a fixed, closed set of attributes."
- Composable Diffusion: A diffusion-based approach that composes multiple conditions during generation. "Composable Diffusion achieves multi-condition synthesis"
- composable embeddings: Representations that can be combined to control multiple attributes jointly. "producing disentangled and composable embeddings"
- compositional generation: Synthesizing images by integrating multiple concepts or attributes into one coherent output. "Compositional image generation aims to synthesize a coherent output"
- conditional flow field: The component of a flow model’s velocity attributable to a specific conditioning signal. "we first compute the conditional flow field for each image-attribute pair"
- contrastive disentanglement: Using contrastive objectives to separate representations of different attributes. "balances generative fidelity with contrastive disentanglement."
- contrastive loss: Objective that pulls together positives and pushes apart negatives to obtain discriminative embeddings. "a contrastive loss that introduces a repulsive force between embeddings associated with negative attributes."
- cosine similarity: Similarity metric measuring the angle between two vectors, used to compare embeddings. "the gap between the cosine similarities of positive and negative attributes"
- DiTs: Diffusion Transformers; transformer-based diffusion models whose modulation spaces can be manipulated. "manipulate the modulation space of DiTs to represent image attributes"
- flow-matching generator: A generative model trained with flow matching to map noise to images via learned velocity fields. "we adopt a similar concept in our flow-matching generator."
- frozen image generator: A pretrained generator kept fixed while other components are trained around it. "which consists of a frozen image generator preceded by trainable IP-Adapter modules"
- generative loss: Reconstruction-oriented objective that encourages embeddings to preserve information needed to synthesize target images. "a generative loss that ensures embeddings extracted from a reference image can effectively reconstruct its paired image"
- holistic embeddings: Single representations that entangle many visual factors rather than isolating specific attributes. "rely on holistic embeddings from general-purpose image encoders"
- information leakage: Unintended transfer of irrelevant attributes alongside the intended attribute during personalization. "This often leads to information leakage and incoherent synthesis."
- IP-Adapter: A conditioning module that injects image features into a generator via cross-attention for personalization. "trainable IP-Adapter modules for personalization."
- LoRA tuning: Low-Rank Adaptation; parameter-efficient finetuning that adds low-rank updates to preserve pretrained knowledge. "LoRA tuning better preserves pretrained representations and mitigates catastrophic forgetting compared to full finetuning"
- MLLM (multimodal large-LLM): Large model jointly processing text and images to align vision-language representations. "72B-parameter multimodal large-LLM (MLLM)"
- modulation space: The parameter space (e.g., scales/shifts) that modulates layers of a generative model to control outputs. "manipulate the modulation space of DiTs"
- negative attributes: Attributes that differentiate two images in a paired sample and should be suppressed. "negative attributes that highlight the characteristics that differ between them."
- open-vocabulary: Not restricted to a predefined attribute set; can handle arbitrary textual attribute descriptions. "the first open-vocabulary image attribute encoder"
- per-token modulation: Controlling models at the token level, often limiting phrase-level personalization. "per-token modulation hinders the personalization of multi-token (phrase-level) concepts"
- positive attributes: Attributes shared by both images in a pair that should be preserved in encoding. "positive attributes, which describe shared semantic properties"
- repulsive force: Contrastive mechanism pushing apart embeddings of different or negative attributes. "introduces a repulsive force between embeddings associated with negative attributes."
- semantically linked image pairs: Paired images curated to share some attributes and differ in others for supervision. "our training samples consist of semantically linked image pairs."
- t-SNE: Dimensionality reduction method for visualizing high-dimensional embeddings in two dimensions. "using t-SNE"
- vision-language prior: Pretrained knowledge aligning visual and textual modalities that improves multimodal tasks. "a strong vision-language prior"
Collections
Sign up for free to add this paper to one or more collections.