- The paper introduces a modular design that decouples MLLM-based high-level reasoning from low-level proposal selection, enabling efficient multi-target visual grounding.
- It employs a frozen pretrained MLLM with a dedicated decoder, achieving constant inference latency and enhanced precision in dense object scenarios.
- Modular enhancements like the RL-based QuadThinker and mask-aware labels yield significant improvements, including a +20.6% F1 boost on challenging benchmarks.
VGent: Modular Visual Grounding through Reasoning–Prediction Disentanglement
Introduction
The paper "VGent: Visual Grounding via Modular Design for Disentangling Reasoning and Prediction" (2512.11099) presents a modular encoder–decoder architecture for visual grounding that addresses core limitations of existing approaches based on Multimodal LLMs (MLLMs). The primary motivation is to decouple high-level multimodal reasoning from low-level localization. Current paradigms either adopt auto-regressive MLLMs—which incur high latency and hallucination risks—or perform aggressive MLLM re-alignment for localization, often at the expense of reasoning capability. VGent leverages a frozen, pretrained MLLM as a high-level reasoning encoder and delegates bounding box selection to a decoder armed with high-recall proposals sourced from generic detectors. This compositional design enables parallel inference, modular upgrades, and improved transfer of reasoning capacity while maintaining precise, efficient target localization especially in complex multi-target scenarios.
VGent Framework Overview
VGent utilizes a two-stage modular architecture. The encoder is a frozen MLLM (e.g., Qwen2.5-VL-7B), preserving its pretrained multimodal reasoning signals, processed as hidden states across all transformer layers. The decoder, initialized from the encoder’s LLM parameters, interprets proposals (projected into LLM space) from off-the-shelf detectors through cross-attention over encoder hidden states. Proposal interactions are enriched via self-attention, and layerwise initialization aligns semantic reasoning with spatial selection. The output consists of binary object presence scores, with auxiliary learnable queries for set cardinality predictions. The overall workflow is shown below.
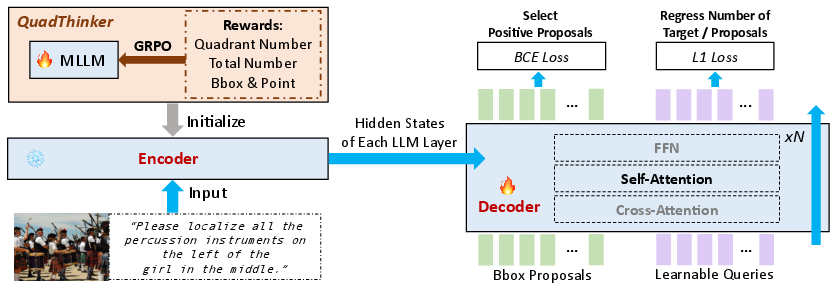
Figure 1: VGent adopts a modular encoder–decoder design, separating high-level reasoning (encoder) from low-level proposal selection and prediction (decoder).
A salient advantage of this architecture is parallel proposal evaluation. In contrast to auto-regressive MLLM methods whose latency grows linearly with the number of targets, VGent exhibits constant-latency inference even in dense multi-target settings, as highlighted in Figure 2.
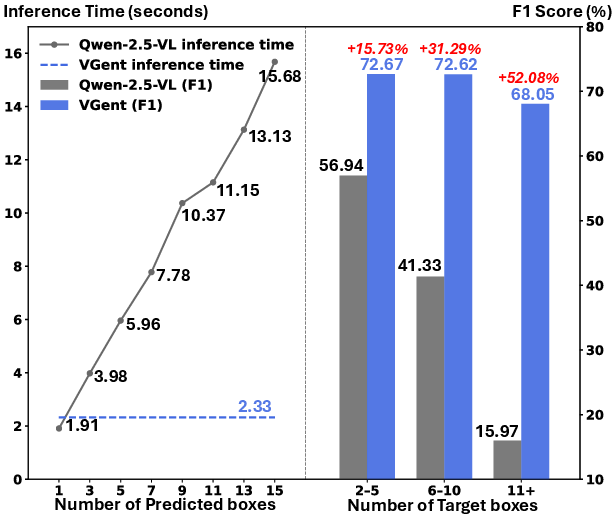
Figure 2: VGent maintains constant, fast inference latency as target count grows, unlike auto-regressive MLLMs which scale linearly and struggle with dense object scenarios.
Modular Enhancements
The modular template enables targeted upgrades to both encoder and decoder, yielding significant empirical gains.
QuadThinker: RL-Based Reasoning Enhancement
Pretrained MLLMs degrade in multi-target grounding due to insufficient explicit multi-object supervision. The QuadThinker approach utilizes Generalized Reinforcement Prompt Optimization (GRPO) to fine-tune the MLLM with prompts and rewards that explicitly enforce region-to-global, multi-step reasoning—target counts per image quadrant, global count aggregation, and fine object localization—while penalizing hallucinations and format violations. This shift reduces degeneracy in dense-object settings and robustifies grounding under compositional language.

Figure 3: Example QuadThinker prompt with region-wise counting and verifiable instruction, supporting RL-based multi-target reasoning enhancement.
Mask-Aware Label: Bridging Detection and Segmentation
Detector proposals typically follow box-level matching (IoU) which fails under segmentation ambiguity or for small/fragmented entities present in the ground truth mask. VGent introduces “mask-aware labels” using Intersection-over-Area (IoA) against unified ground truth masks, efficiently capturing fine-grained regions such as thin structures ignored by IoU box matching. Two decoder heads are trained: one for classic box-aware (IoU) detection and one for mask-aware (IoA) segmentation, harmonizing both paradigms.
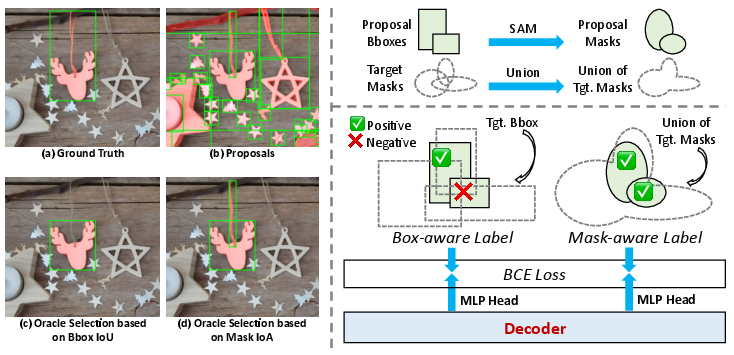
Figure 4: Mask-aware labels use IoA to improve fine-grained region recall, resolving cases where IoU box matching would miss small or ambiguous regions.
Global Target Recognition: Proposal Aggregation and Set Prediction
To further improve recall and context, proposals from multiple detectors are unified and fed as queries. Learnable queries are concatenated to predict the global number of targets and positive proposals. A shared self-attention mechanism propagates global priors across queries, increasing holistic understanding and set consistency.
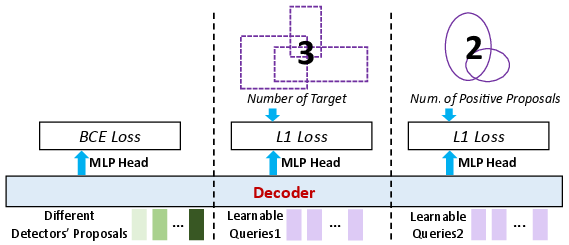
Figure 5: Aggregation of proposals from multiple detectors, with learnable queries enhancing global target recognition and holistic proposal selection.
Experimental Results
Multi-Target Visual Grounding
On ORES (MaskGroups-HQ), a challenging high-resolution, multi-entity benchmark, VGent surpasses the previous state-of-the-art by +20.6% F1, +8.2% gIoU, and +5.8% cIoU. This improvement holds across both referential and non-referential splits, solidifying the claim that modular disentanglement and hidden state decoding yield material advancements over traditional MLLMs and end-to-end detector paradigms.
Single-Target Visual Grounding
VGent achieves an average 90.1% accuracy on REC benchmarks (RefCOCO, RefCOCO+, RefCOCOg), outperforming substantially larger MLLMs (InternVL3.5-20B, 38B) and bringing +3.5% accuracy improvement over its Qwen2.5-VL-7B MLLM backbone. These results demonstrate that modularization does not only benefit dense object settings but transfers to canonical single-object scenarios as well.
Qualitative Results
VGent robustly handles occlusion, distractors, small-scale targets, and fine-grained visual references (Figure 6).

Figure 6: VGent output visualizations in challenging scenarios; blue masks denote visual reference regions.
Ablation Studies
- Freezing the encoder is essential; unfreezing leads to reasoning degradation despite more parameters.
- RL-based reward shaping in QuadThinker boosts multi-target performance, especially beyond 10 targets per scene.
- Adding mask-aware label and global target recognition progressively increase F1, gIoU, and cIoU, especially for segmentation generalization and instance-level discrimination.
Implications and Future Directions
The architectural decoupling proposed by VGent reifies the hypothesis that monolithic MLLMs are fundamentally ill-suited for jointly solving high-level reasoning and precise low-level localization. Compositional, modular, and parallel evaluation architectures are crucial for scaling visual grounding to real-world, dense, multi-object, and referential scenarios required by emerging multimodal interaction, embodied AI, and perception-guided agent frameworks.
Future directions include:
- Scaling the approach to open-vocabulary and long-tail grounding domains by further increasing detector diversity and leveraging dense retrieval.
- Investigating integrating additional perceptual modalities (e.g., temporal or 3D cues) in the modular reasoning–prediction template.
- Exploring triggering adaptive proposal generation conditioned on reasoning signals to close the annotation–detection granularity gap.
Conclusion
VGent redefines visual grounding as a modular multi-stage pipeline, ensuring highly efficient, robust, and semantically-aligned localization through the explicit separation of high-level reasoning and low-level prediction. Empirical advances on difficult benchmarks validate that modularization mitigates hallucination, latency, and reasoning degradation. VGent’s design is likely to inform downstream multimodal AI architectures that require flexible, interpretable, and upgradable pipelines for referential understanding and complex visual reasoning (2512.11099).