- The paper introduces Tamo, a universal transformer-based policy that eliminates per-task surrogate fitting in multi-objective optimization.
- The paper employs reinforcement learning on diverse synthetic GP tasks to achieve competitive Pareto quality and speed up proposals by 50–1000×.
- The paper demonstrates robust generalization across variable dimensions and objectives, enabling plug-and-play optimization in heterogeneous scientific workflows.
In-Context Multi-Objective Optimization: A Unified Amortized Transformer Policy for Black-box Design
Introduction and Motivation
Balancing multiple, often conflicting, objectives is essential across scientific and engineering applications, from drug discovery to experimental design. Traditional multi-objective Bayesian optimization (MOBO) methods, which leverage surrogate models such as Gaussian processes (GPs) and acquisition functions like hypervolume improvement, demonstrate strong sample efficiency but suffer from several limitations: task-specific surrogate and acquisition engineering, repeated refitting with every problem instance, high computational overhead for parallelization, and critically, myopic query selection strategies. These limitations hinder scalability in fast-paced or parallelized scientific workflows.
"In-Context Multi-Objective Optimization" (2512.11114) proposes a universal, fully amortized transformer-based policy, Tamo, for black-box multi-objective optimization. Tamo is trained offline using reinforcement learning (RL) to propose queries for diverse multi-objective designs, operating across variable input and output dimensionalities. At deployment, Tamo eliminates per-task surrogate/acquisition optimization, producing instant proposals in a single forward pass. This framework enables transfer across problems, objective counts, and design spaces, facilitating plug-and-play deployment for heterogeneous scientific discovery tasks.
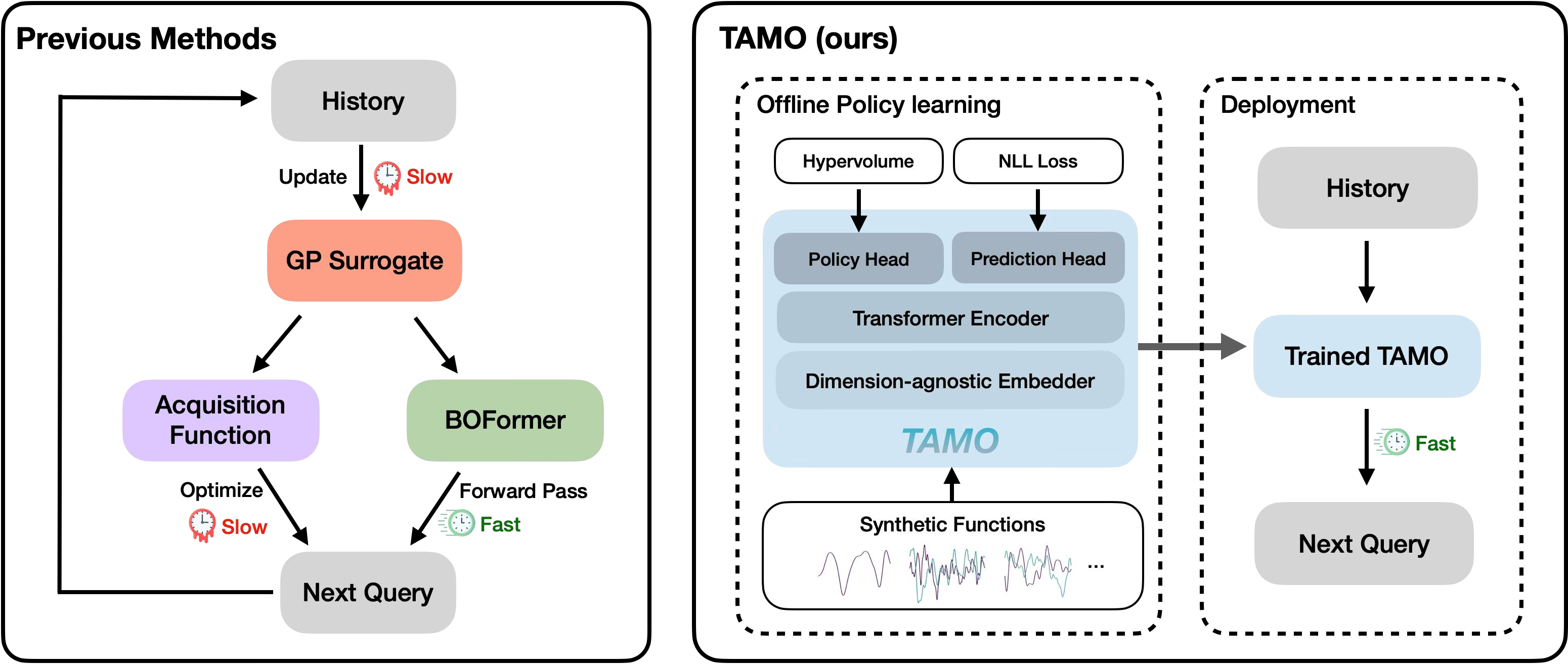
Figure 1: Comparison of multi-objective optimization workflows, contrasting traditional MOBO and BOFormer (left) with Tamo’s fully amortized, dimension-agnostic transformer policy (right).
Methodology
Pretraining Corpus and Task Distribution
Tamo is pretrained on a distribution of synthetically-generated GP tasks varying in input and output dimensionality, output correlations (task covariance structure), and function smoothness. For each episode, the training set is partitioned into history/query (for RL policy learning) and context/target (for auxiliary regression), mimicking the incomplete and diverse data encountered in real-world MOO.
Model Architecture
Tamo employs a single transformer backbone with architectural innovations for dimension-agnosticity:
- Dimension-agnostic Embedding: Inputs and outputs of arbitrary sizes are expanded via learned scalar-to-vector mappings and positional encodings, passed through shared transformer layers.
- Flexible Task Conditioning: Lightweight task- and time-specific tokens enable the same model to interpret variable evaluation budgets and design spaces, and switch between prediction and optimization modes.
- Shared Processing and Heads: All data are processed identically through the backbone; bifurcated heads handle in-context regression (Gaussian mixture prediction) and acquisition utility computation.
The architecture is shown to scale gracefully with input/output dimensionality (not with the total number of observations), permitting the efficient handling of large search spaces.
Training Procedure
The model is first warmed up on in-context prediction to stabilize representations. Subsequently, RL-based training maximizes expected cumulative normalized hypervolume improvement (HV), directly rewarding long-horizon Pareto identification rather than myopic gains. The overall loss sums the RL objective and the prediction loss, with the latter accelerating training convergence and improving amortized representations.
At test time, Tamo proposes queries via greedy maximization of utility across a candidate set, iteratively updating observed data and approximating the Pareto frontier under a fixed function evaluation budget.
Experimental Results
Synthetic and Real-world Benchmarks
Tamo is benchmarked on synthetic multi-objective GP draws, classic analytic functions (Ackley–Rastrigin, Ackley–Rosenbrock, Branin–Currin composition), and real-world material design tasks (oil-sorbent, Laser-Plasma Acceleration HPO). It is compared to established MOBO (qNEHVI, qParEGO), amortized BOFormer, and random search.
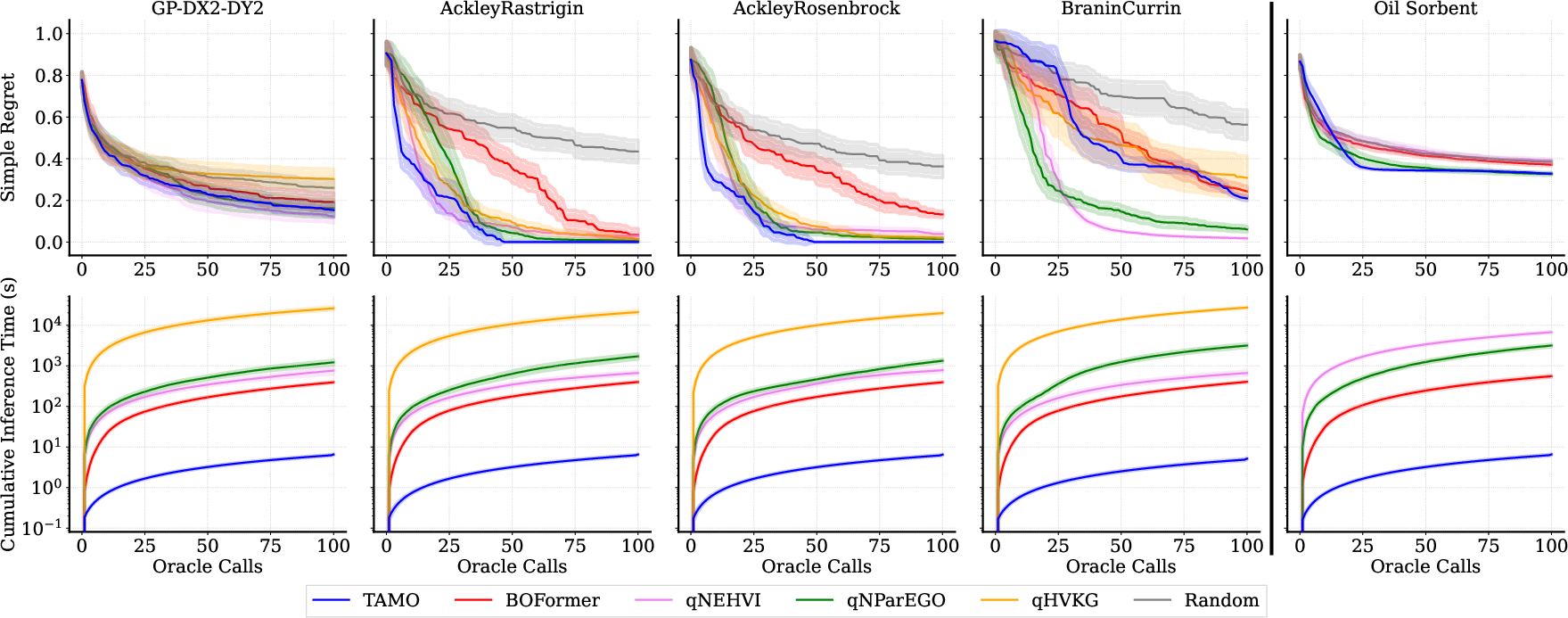
Figure 2: Tamo matches or outperforms GP-based MOBO methods on synthetic and real-world tasks, achieving competitive simple regret while reducing proposal time by 50–1000×.
Key findings:
- Pareto Quality and Sample Efficiency: On in-distribution synthetic tasks, Tamo matches state-of-the-art regret of GP-based MOBO. For out-of-distribution tasks (unseen length scales, correlations, and dimensionalities), Tamo remains broadly competitive, with only minor degradation.
- Wall-clock Efficiency: Tamo’s single-forward-pass proposal time is orders of magnitude lower (50–1000×) than conventional approaches requiring repeated surrogate fitting and acquisition optimization.
- Generalization: Tamo generalizes well to novel input/output dimensionalities and to decoupled objective settings (where objectives are probed independently and feedback may be partial) without retraining or architecture changes.
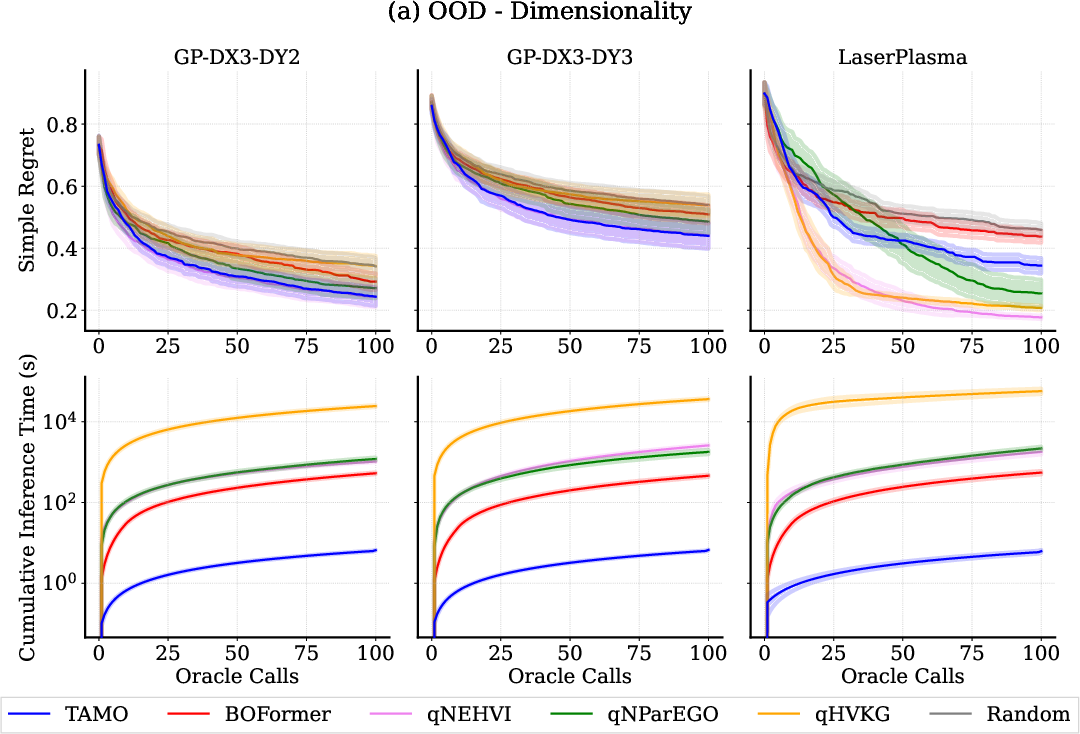
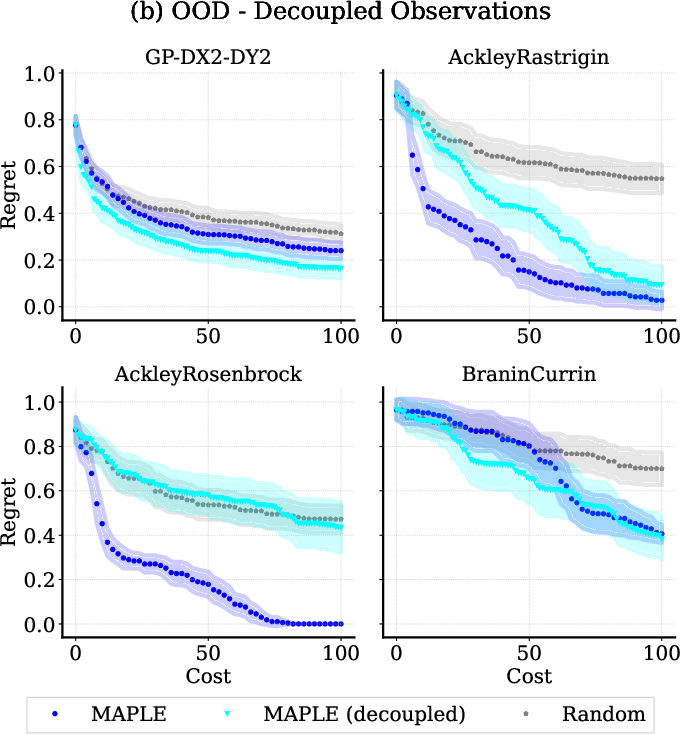
Figure 3: Out-of-distribution evaluation shows Tamo’s competitive regret and dramatic inference speed-up for tasks with unseen dimensionality (left); Tamo also maintains performance under decoupled/partial objective observation protocols (right).
Ablation Studies
Systematic ablations reveal:
- Batch Size and Query Set Size: Regret is robust to parallel batch size and query pool size, with larger pools incurring only linear increases in inference time but yielding minimal impact on solution quality.
- Prediction Term and RL Horizon: Auxiliary prediction loss is essential for stable and effective policy learning. Training with longer horizons confers measurable gains over myopic policies.
- Pretraining Data Composition: Performance and generalization are influenced by the diversity and structure of the pretraining corpus, motivating future exploration of tailored synthetic task design.
Figure 4: Effect of batch size on regret and sample efficiency for Tamo. Increase in batch size results in a mild slowdown in convergence, but enables parallel evaluation for potential wall-clock savings.
Figure 5: On single-objective optimization, Tamo matches the best GPs in regret while offering much lower proposal time.
Theoretical and Practical Implications
This work establishes that transformer-based policies, pretrained on diverse black-box optimization problems, can directly amortize the entire MOBO workflow—including surrogate learning and acquisition engineering—across variable dimensions and objectives. The empirical results challenge the previously-assumed necessity of per-task surrogate fitting and hand-tuned acquisition design, especially under tight evaluation budgets or parallel/real-time scenarios.
The practical advantages are substantial:
- Plug-and-Play Optimization: A single, universal optimizer can be deployed across scientific domains, eliminating the need for model reengineering.
- Scalability: Orders-of-magnitude improvement in wall-clock latency enables MOBO to be applied in high-throughput or closed-loop experimental settings.
- Transferability and Generalization: The transformer-based approach supports rapid transfer to tasks outside the pretraining regime, potentially reducing the barrier to adoption in new domains.
Theoretically, the work connects amortized meta-learning, RL-based non-myopic planning, and dimension-agnostic sequence models for black-box design.
Limitations and Future Directions
Current limitations include reliance on finite candidate pools (common in catalog search but restrictive in continuous or combinatorial design) and sensitivity to the structure of the pretraining dataset. Scaling to high-dimensional or continuous action spaces will require more expressive proposal mechanisms or latent generative policies. Future research should systematically study the impact of different synthetic pretraining distributions and extend the framework to constraints, cost-awareness, and multi-fidelity settings. Integration with generative modeling for de novo design and adaptation to further modalities (e.g., preferences, ranked feedback) also constitute promising avenues.
Conclusion
"In-Context Multi-Objective Optimization" presents a universal, transformer-based amortized policy (Tamo) for black-box multi-objective optimization. Through a combination of RL-amortized training, dimension-agnostic design, and empirical validation, Tamo demonstrates competitive Pareto quality, robust generalization across tasks and domains, and orders-of-magnitude lower wall-clock proposal times relative to classical and amortized baselines. This positions amortized transformer policies as foundation model optimizers capable of seamless transfer and deployment in heterogeneous scientific design workflows.