- The paper introduces a focused attention mechanism that computes differential attention maps to filter out noisy context and enhance relevant dependencies.
- The paper employs a noise-robust self-supervision task alongside a contrastive InfoNCE objective, ensuring representation invariance and more predictive feature extraction.
- The paper demonstrates significant improvements in Recall and NDCG metrics across multiple datasets, validating its effectiveness over standard models.
FAIR: Focused Attention for Generative Sequential Recommendation
Introduction
Generative recommendation frameworks have advanced the modeling of user interaction sequences by leveraging Transformer-based architectures to generate semantic item codes. A persistent challenge in this regime is the expansion of sequence length due to multi-code item discretization, which amplifies the susceptibility of standard Transformers to attention diffusion and allocation to irrelevant or noisy context. This noise degrades modeling efficiency and impairs next-item prediction accuracy.
The paper introduces FAIR (Focused Attention Is All You Need for Generative Recommendation) (2512.11254), a non-autoregressive generative recommendation framework explicitly designed to address attention noise. FAIR introduces a focused attention mechanism, a noise-robustness self-supervision task, and a mutual information maximization objective, thereby enforcing the model to prioritize informative contextual dependencies and suppress noise in behavioral sequences.

Figure 1: Standard Transformers over-allocate attention to irrelevant context, while FAIR sharpens focus on relevant items and suppresses noise.
Methodology
Focused Attention Mechanism
FAIR departs from classical self-attention by introducing a dual-branch design wherein two separate sets of query/key matrices yield independent attention maps. The framework computes the difference between these two attention distributions, normalizes the result, and applies this differential attention to the value representations. This approach is formally defined as:
A=Norm(λ1A1−λ2A2)
where A1 and A2 are softmax-normalized attention scores from the two branches, and λ1,λ2 modulate their importance. The subtraction operation enhances the model’s capability to filter out redundant or spurious correlations while amplifying informative dependencies.
Multi-head extensions are employed, independently applying focused attention in each head and linearly recombining the results for output.
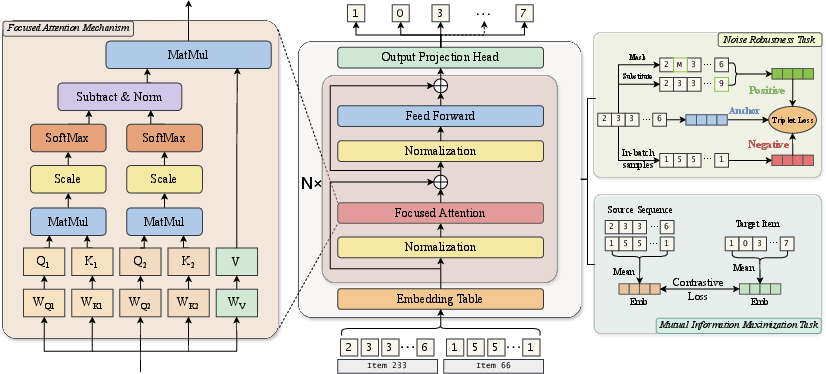
Figure 2: Overview of the FAIR architecture with Focused Attention Mechanism, Noise-Robustness Task, and Mutual Information Maximization.
Noise-Robustness Objective
To directly enhance robustness to sequence perturbations that induce attention drift, the training regime includes a self-supervised task. The model generates noisy variants of the input by stochastic masking or random substitution (with probabilities pmask and psub). A triplet loss brings the hidden representations of the clean and noisy sequences closer while pushing them away from negative batch samples.
This objective enforces representation invariance to input corruption, counteracting Transformer tendencies to shift attention under input noise.
FAIR further introduces a contrastive InfoNCE objective to maximize the mutual information between pooled contextual embeddings and their associated target representations. Positive sample similarity is reinforced, and negatives are discouraged, effectively constraining the model to extract features maximally predictive of the next item. This guides attention towards statistically informative context while diminishing irrelevant attention allocation.
Model Training
The final loss function is a weighted aggregation:
L=LMTP+αLNR+βLMIM
with LMTP for parallel multi-token prediction, and α, β as loss balancing coefficients.
Experimental Results
Benchmarks and Baselines
Experiments span four Amazon datasets with varying scale and sparsity. FAIR is evaluated against classical sequential models (e.g., SASRec, GRU4Rec, BERT4Rec), semantic-enhanced Transformers, and state-of-the-art generative methods (e.g., VQ-Rec, TIGER, RPG, HSTU).
Quantitative Results
FAIR achieves consistent empirical gains over all baselines on Recall@5/10 and NDCG@5/10 across datasets. For instance, on the "Toys" dataset, FAIR yields a 13.2% improvement in Recall@5 and an 11% improvement in NDCG@5 compared to the strongest competitor. All improvements are statistically significant (p<0.05).
Ablation and Component Analysis
Ablations demonstrate that each architectural and objective component—focused attention mechanism (FAM), noise-robustness task (NRT), and mutual information maximization (MIM)—contributes to the overall performance. Removal of any single element leads to significant degradation, confirming that mitigating attention noise requires joint architectural and objective-level intervention.
Hyperparameter Sensitivity
Sensitivity studies show monotonic improvement with increasing code sequence length L and embedding dimension d up to dataset-dependent thresholds, after which performance plateaus or degrades, indicating the effect of overcapacity and optimization complexity.
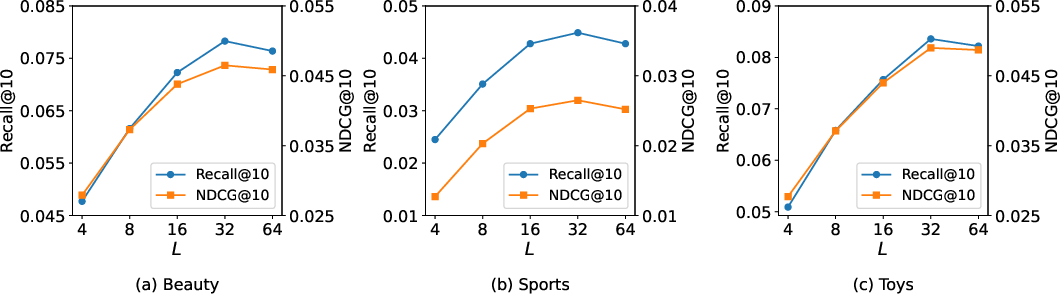
Figure 3: Performance increases with code sequence length L up to a threshold, after which overfitting or redundancy emerges.
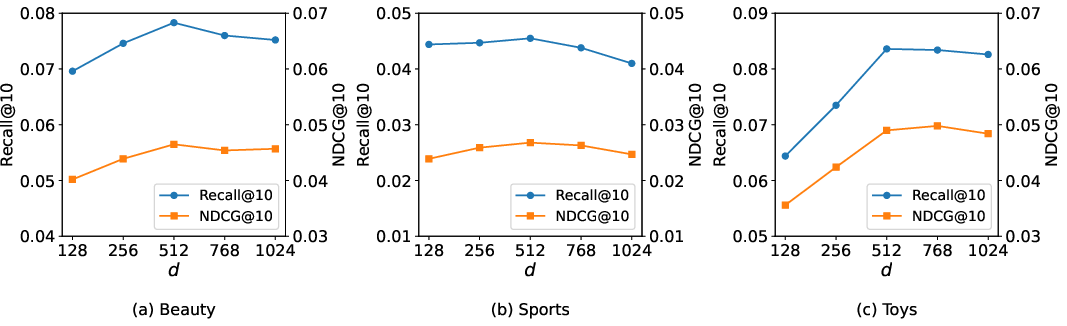
Figure 4: Model performance with increasing embedding dimension d illustrates a saturation point balancing expressiveness and generalization.
The loss coefficients α and β and regularization parameters reveal that FAIR maintains robust performance across a range of values. Unlike standard Transformers, the explicit robustness modeling reduces reliance on generic regularizers like dropout.
Qualitative Analysis
Case studies visualize attention allocation across ablation settings, confirming that the full FAIR model effectively suppresses irrelevant historical items and promotes sharp attention to decision-relevant context. The focused attention mechanism initially shifts attention towards relevant items but requires the auxiliary objectives (NRT and MIM) to enforce meaningful, robust, and predictive allocation.
Implications and Future Directions
The research demonstrates that Transformer-based generative recommendation can be considerably enhanced by explicitly addressing context noise at the architectural and objective level. The differential attention mechanism is theoretically motivated and empirically validated to directly counteract attention diffusion in long discrete code sequences typical of advanced generative recommenders.
From a practical standpoint, focused attention enables more effective scaling of item sequence discretization and supports deployment for industrial-scale catalogs. The self-supervised robustness and mutual information objectives reduce the need for post-hoc or architectural regularization strategies.
The approach also suggests broader implications: the differential or subtractive attention paradigm may generalize to other domains suffering from attention instability under long-range sequence expansion—potentially informing LLMs, multimodal representation learning, and robust sequential inference more generally.
Conclusion
FAIR establishes a robust and semantically principled framework for generative sequential recommendation via focused attention, robustness to input perturbations, and representation informativeness optimization. The method attains strong empirical results with moderate computational overhead, offering a scalable strategy for addressing noisy sequence modeling in generative recommenders and motivating advances in focused inductive bias for self-attention architectures (2512.11254).