- The paper introduces a novel formulation of the N-Body Problem to synthesize multi-agent parallel executions from egocentric video while optimizing speed-up and task coverage.
- The paper employs a structured prompting framework for vision-language models, achieving up to 91.3% action coverage and significantly reducing collision and conflict rates.
- The paper demonstrates practical applications in collaborative robotics and digital twins by enabling rapid prototyping of feasible execution plans from unscripted video data.
The N-Body Problem: Multi-Agent Parallel Execution from Egocentric Video
This paper formalizes the N-Body Problem, which is defined as synthesizing hypothetical multi-agent parallel executions from a single-person egocentric video. The canonical objective is to maximize speed-up and task coverage when “dividing” the original set of tasks among N agents; however, purely greedy or naive segment assignment inevitably violates critical real-world constraints, including physical spatial collisions, simultaneous object usage, and causal ordering. The central insight is that unscripted egocentric videos encompass latent opportunities for concurrency, but robust parallelization requires holistic spatiotemporal, semantic, and causal reasoning—well beyond simple resource-constrained scheduling.
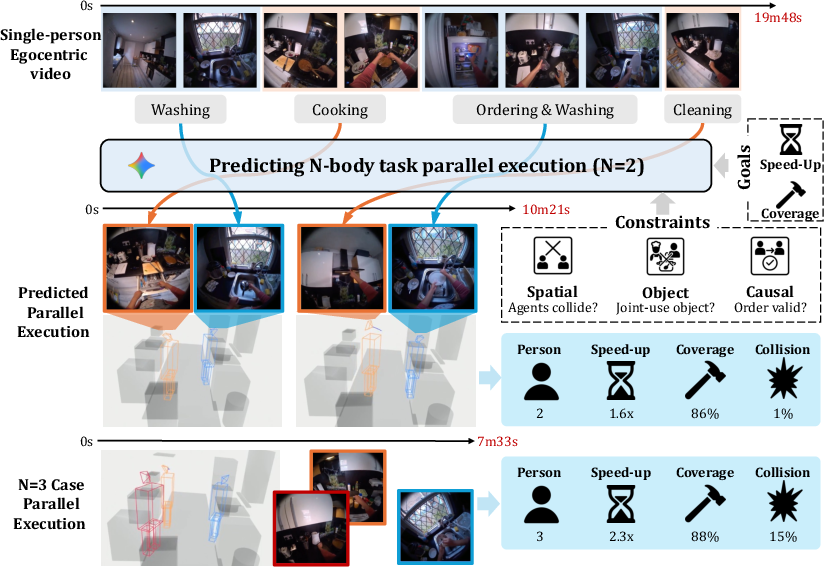
Figure 1: Egocentric input, predicted 2-body and 3-body parallel executions, with significant speed-up and spatial coverage visualized in 3D.
Methodology and Architectural Innovations
To tackle the N-Body Problem, the authors propose a suite of evaluation metrics for both performance (speed-up, coverage) and feasibility (collision, object conflict, causal correctness). The input is parsed into non-overlapping assignable segments, which must be allocated to agents such that spatial constraints (collision-free occupancy), object constraints (exclusive instance usage), and causality constraints (temporal dependencies among actions) are respected.
A key contribution is the development of a structured prompting framework for Vision-LLMs (VLMs), specifically Gemini 2.5 Pro, instructing the model to reason over 3D spatial environments, track objects, and maintain causal temporal structure. The spatial prompt divides the physical kitchen plane into zones and provides explicit guidance on zone occupancy durations, mitigating collision rates. Objective-driven prompting further instructs Gemini to optimize for speed-up and coverage while minimizing constraint violations. Notably, no model weights are fine-tuned; improvements derive solely from prompt engineering.
Experimental Results and Quantitative Analysis
Extensive experiments are conducted on 100 long-form egocentric videos (EPIC-KITCHENS and HD-EPIC), leveraging ground-truth annotations solely for evaluation. Major findings include:
Naive and heuristic scheduling baselines (half-half split, HEFT) lead to unacceptable rates of collision and constraint violations, demonstrating the ill-posedness of simple temporal division. Open-weight VLMs (Qwen2.5-VL-72B) are unable to solve the problem reliably and fail on a significant subset of inputs.
Qualitative and Analytical Insights
Qualitative results reveal interpretable parallel task allocations: typically, one agent is assigned stationary tasks in spatial hotspots (e.g., cooking), while others traverse to perform preparatory, cleaning, or fetching activities. Analysis shows one agent often handles a majority of cooking or cleaning, and walking distance tends to concentrate on mobile roles—indicative of emergent collaborative behavior learned via prompt structure.
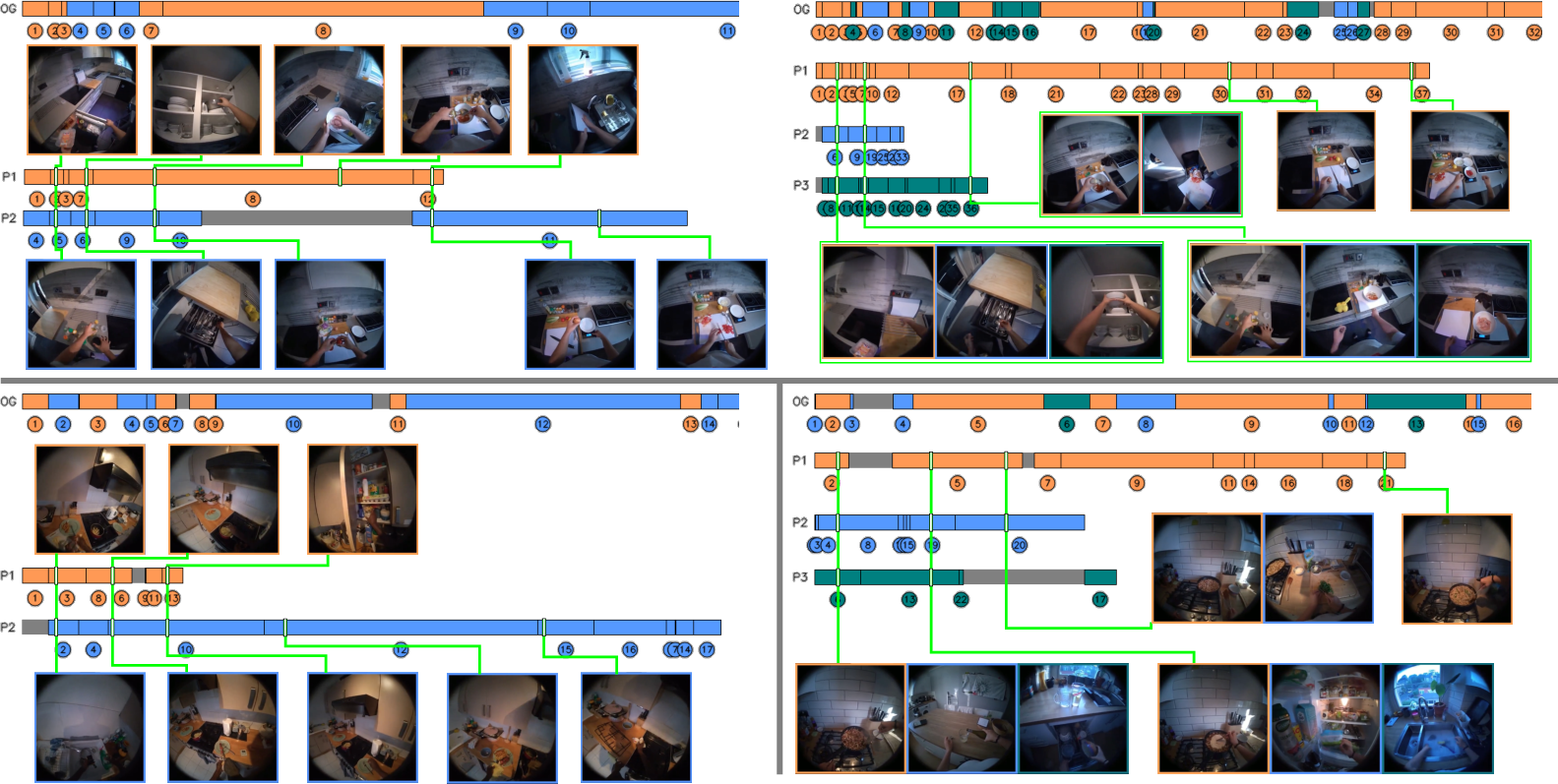
Figure 3: Qualitative task splits for N=2/N=3 agents; distinct roles and division of labor emerge naturally.

Figure 4: Analysis of agent cooking time, prep-step role assignment, and walking distance splits, highlighting emergent collaborative behaviors.
Implications and Theoretical/Practical Significance
The formulated N-Body Problem pushes video understanding from passive temporal segmentation toward generative simulation of plausible multi-agent collaboration, grounded in explicit physical and logical constraints. The findings quantitatively demonstrate that advanced VLMs—when carefully prompted—can synthesize feasible parallel execution plans from single-user demonstrations, opening new horizons for generalizing from human activity traces.
Practically, this enables rapid prototyping for collaborative robotics, digital twins, and task planning agents in environments where annotated multi-agent data is scarce. The methodology is extensible to other structured environments (factory, healthcare, smart home) and robust to long-term, unscripted activities. Theoretically, the work suggests that prompt engineering, not just model training, is a critical bottleneck for unlocking spatial-temporal reasoning capabilities in multimodal foundation models.
Limitations and Future Directions
While the approach yields strong empirical improvements, some challenges remain: precise temporal alignment in multi-agent cooking (e.g., waiting for food), discovery of implicit procedural dependencies, robustness to higher values of N, and intrinsic spatial reasoning in VLMs without spatial prompts. Future research could focus on integrating explicit action graphs, unsupervised discovery of causal structure, or architectural enhancements that directly model agent-object-environment interactions without textual scaffolding. Evaluation techniques for real multi-agent execution (e.g., robotic agents) will be necessary for translation to embodied AI applications.
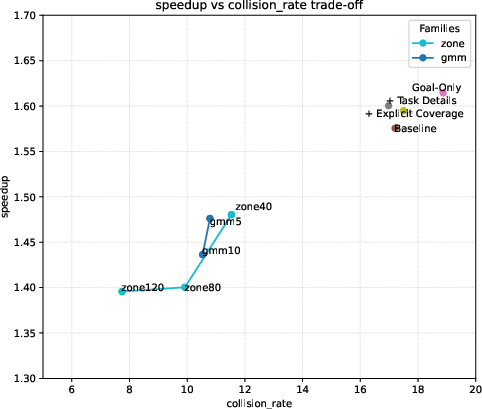
Figure 5: Speed-up versus collision rate trade-off visualized over diverse methods and spatial prompt variants.
Conclusion
This paper delivers a rigorous framework and empirical validation for the N-Body Problem, showing that with appropriate prompting, current VLMs can infer feasible, efficient multi-agent parallel executions from single-person egocentric video. The combination of new evaluation metrics, constraint-driven prompt engineering, and multi-modal reasoning sets a robust foundation for future research in agentic AI, collaborative planning, and human-centric video understanding (2512.11393).
