- The paper introduces a hybrid REMODEL-LLM pipeline combining static AST analysis with quantized LLM inference to translate C code to Java.
- It benchmarks 19 open-source LLMs under 20B parameters, revealing only select models consistently produce compiling and functionally correct Java outputs.
- The study highlights key failure modes, including syntactic deficiencies and semantic mismatches, and suggests fine-tuning and iterative feedback for improvements.
Automated C-to-Java Translation via Quantized LLMs: An Empirical Assessment
Introduction
Automated legacy code migration, particularly from C to Java, poses non-trivial challenges due to substantial divergences in language paradigms, memory models, and type systems. While the transition from procedural C to object-oriented Java promises security, maintainability, and platform-independence, the translation task requires not only syntactic mapping but also sophisticated semantic reasoning. Traditional rule-based transpilers--operating on deterministic AST transformations--have failed to robustly handle complex idiomatic and architectural discrepancies. Large proprietary LLMs have shown promising code translation capabilities but are inaccessible for data-sensitive enterprise scenarios due to their size and reliance on cloud APIs.
This paper evaluates whether small, quantized, open-source models (<20B parameters), deployable on edge hardware, can reliably perform semantic C-to-Java translation when guided with hybrid AST analysis and highly constrained, rule-based prompting.
Methodology
The proposed REMODEL-LLM pipeline adopts a hybrid approach that fuses static AST-based program analysis with quantized LLM inference and prompt engineering. C source files are decomposed into categorized components (globals, functions, structs) via pycparser AST traversal. These are injected, along with context and explicit translation rules, into an LLM under a guardrail-driven prompt template tailored to the specific code category (function, global, or struct). Generated outputs undergo rigorous postprocessing to eliminate LLM hallucinations, ensure syntactic conformity, and enforce target structure. Final Java artifacts are then statically compiled and executed; functional equivalence with the reference C binary is ascertained by strict stdout comparison.
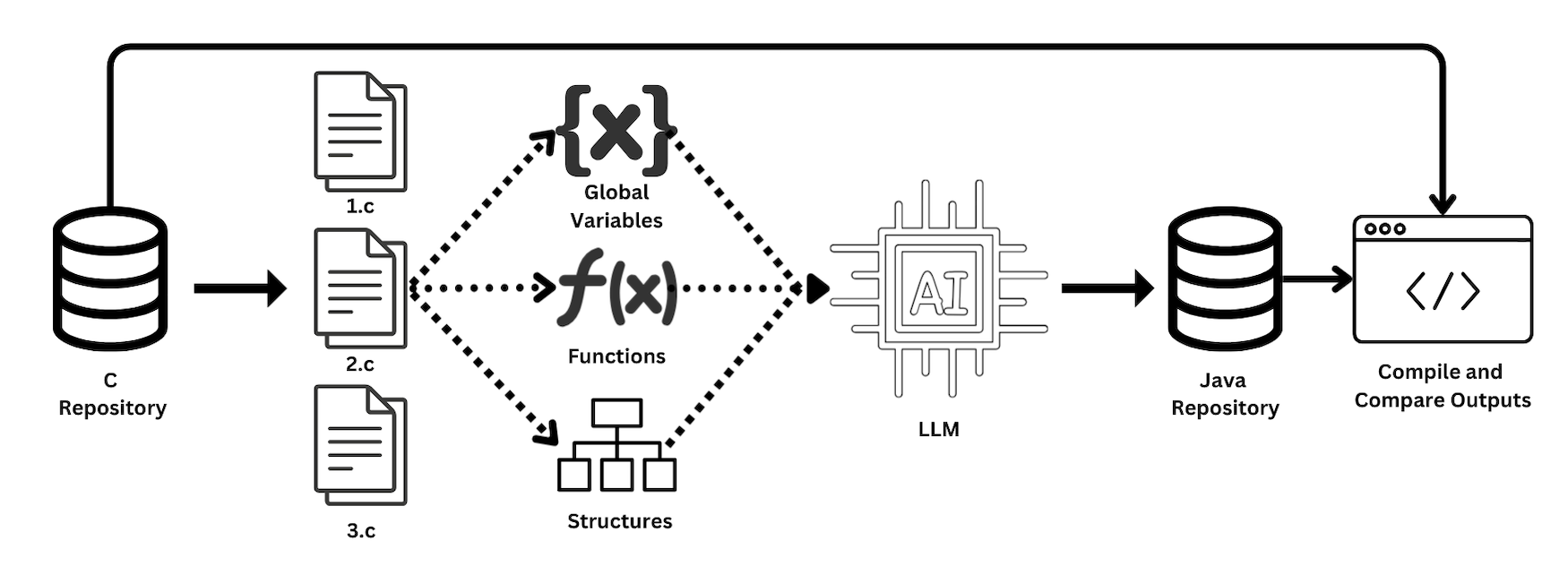
Figure 1: The REMODEL-LLM pipeline integrating AST-based decomposition and LLM-guided synthesis, with automated equivalence testing.
A benchmark suite of 20 hand-crafted C cases interrogates a spectrum of difficult C idioms (e.g., function pointers, unions, pointer arithmetic, goto refactoring) that require translation beyond superficial syntax mapping. This task suite serves not to test bulk translation, but to pinpoint reasoning deficiencies in LLMs.
Benchmark Models
Nineteen open-source decoder-only LLMs, each under 20B parameters, spanning both code-specialized and generalist architectures, were evaluated. This set included SOTA open models such as deepseek-coder-v2, phi4, mistral, codeqwen, codellama, starcoder2, and various others.
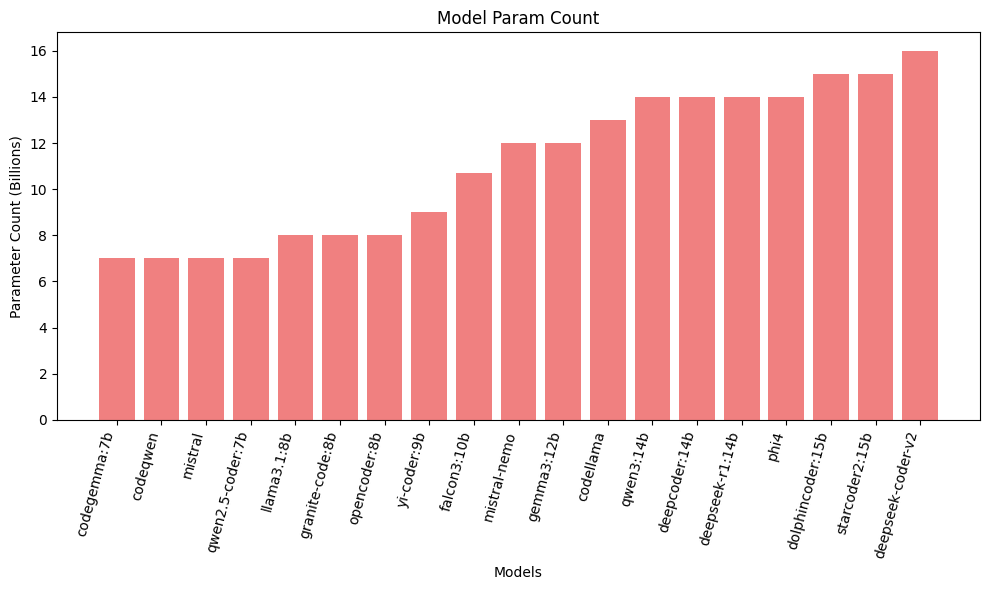
Figure 2: Distribution of parameter counts for all models evaluated, highlighting the scale and diversity of architectures considered.
All inference was conducted locally using the Ollama framework with quantized (4-8 bit) weights, ensuring strict adherence to on-premise/edge deployment constraints.
Experimental Results
A categorical, tiered breakdown of results emerges. Only Tier 1 models (deepseek-coder-v2, codeqwen, phi4; scores: 13/20, 11/20, 11/20) consistently produced compiling and functionally correct Java outputs on more than half the suite. Tier 2 models (e.g., mistral-nemo, mistral) produced valid Java at times, but exhibited dangerous semantic errors or failed on more advanced idioms. The majority, Tier 3 (14/19 models, including all major generalists and several code-specific LLMs), failed every test; these models were fundamentally unable to generate runnable Java, often hallucinating boilerplate, explanations, or malformed code.
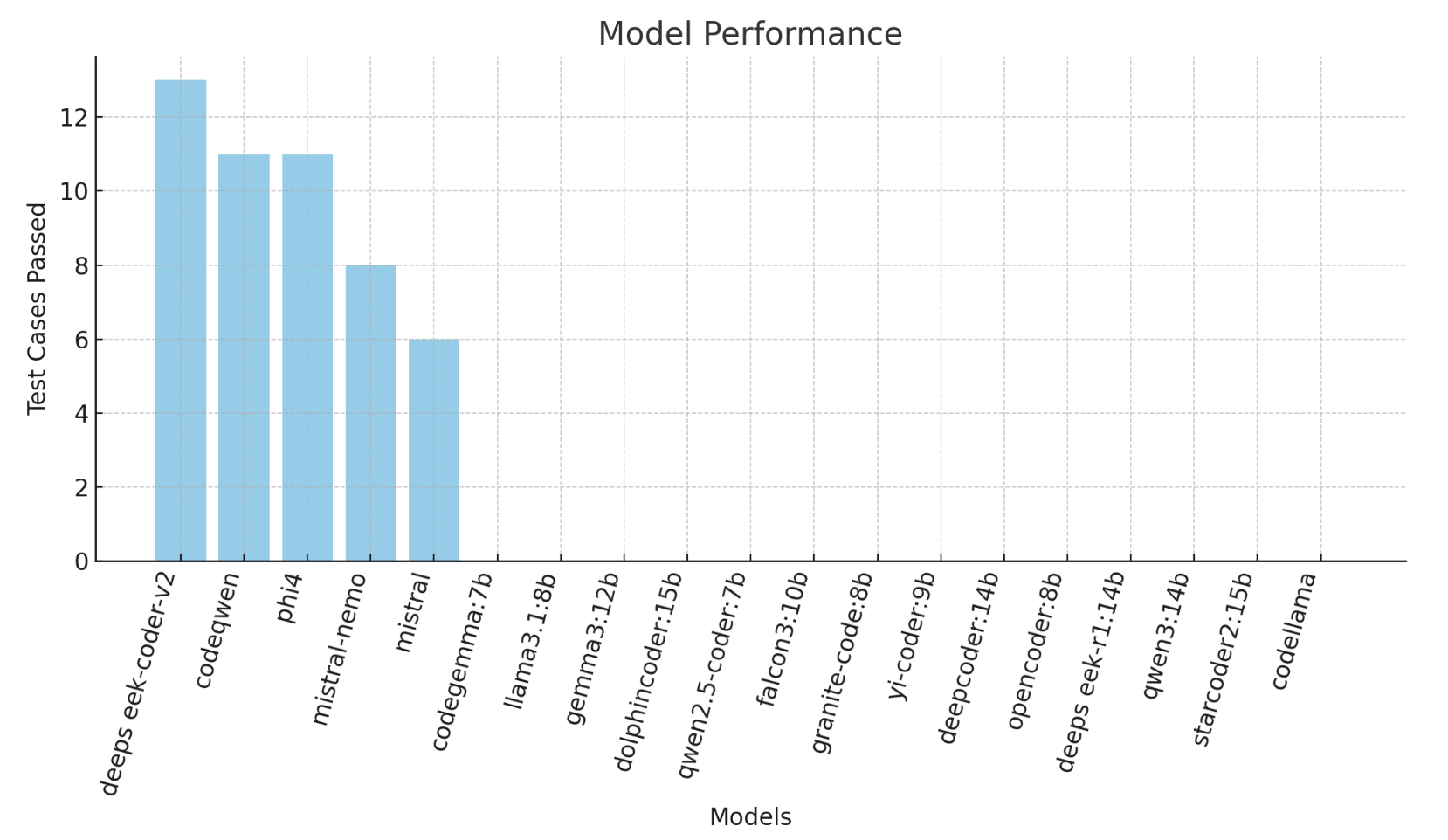
Figure 3: Pass statistics per model on the 20-case benchmark, illustrating the prominent performance stratification.
Case Studies in Translation Fidelity
Successes are typified by Test Case 1, probing pointer arithmetic. deepseek-coder-v2 translated C pointer iterations and arithmetic into idiomatic array index manipulations in Java, strictly adhering to prompt rules.

Figure 4: Test Case 1 – pointer arithmetic, a core C idiom requiring context-sensitive refactoring.
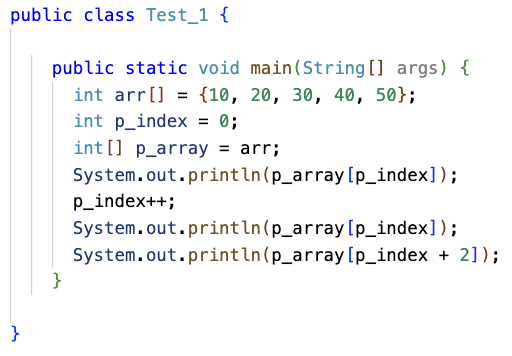
Figure 5: deepseek-coder-v2 translation output, correctly refactoring C pointer-based logic into Java idioms using array indices.
In contrast, advanced idioms such as backward-jumping goto loops (Test Case 13) highlighted clear ceilings. Even Tier 2 models failed, with outputs exhibiting literal, invalid translations (e.g., mapping goto to Java’s continue outside any loop context).

Figure 6: Test Case 13 – backward goto control flow, demanding semantic restructuring to a Java loop.

Figure 7: mistral-nemo failure on Test 13, producing a non-compilable Java output due to literal, unstructured translation.
No model in any tier successfully handled C function pointers, nested struct traversal, or idioms requiring type-punning (union, sizeof, int**, and enum/integer aliasing). The only passing model on union and bitfield emulation (deepseek-coder-v2) succeeded specifically because it both retained and applied the detailed conversion rule specified in the prompt (e.g., using Float.floatToIntBits for type-punning).
Analysis of Failure Modes
Four distinct failure categories were identified:
- Syntactic Deficiency: Tier 3 models systematically failed to produce valid Java class scaffolding, omitting required main methods, outputting explanations or pseudocode, or misaligning file and class names. These failures indicate an inability to parse and adhere to Java’s strict syntactic requirements under highly constrained prompts.
- Literal Translation: Frequent direct copying of C-only constructs—such as
malloc, free, printf format specifiers, goto, and function pointers—revealed pattern-matching behavior, absent any deep language interoperation understanding.
- Semantic Mismatch: Some models could compile and run outputs that nonetheless produced semantically incorrect behavior due to shallow handling of pass-by-value/pointer distinctions, enum handling, or bit-width considerations for unsigned types.
- Unaddressed Semantic Gap: On tasks requiring architectural reformulation (e.g., function pointers to Java interfaces), all models failed, indicating that even with explicit prompt-based rules, quantized small models lack the depth to effectuate paradigm translation.
Implications and Directions
While the work underscores progress in edge-deployable LLMs for code translation, a clear upper bound is observable: only a small subset of models, under explicit, fine-grained constraints and with specialized prompting, can approach the minimal threshold for high-impact migrations. However, these models uniformly fail on idioms requiring cross-file semantic integration, deep control-flow restructuring, or multifaceted type coercion, precluding automated use in complex real-world modernization tasks.
Three avenues for advancement are indicated:
- Targeted Instruction Fine-Tuning: Training models on a rich, parallel corpus spanning C-Java idiosyncrasies could bake translation rules into parameter space, reducing reliance on exhaustive run-time prompting.
- Self-Correction/Iterative Feedback: Pipelines looping compiler/runtime feedback through the LLM hold promise for incremental error repair and adaptation.
- Hierarchical/Multi-Pass Refactoring: Combining initial syntactic translation with subsequent semantic-aware refactoring modules that holistically analyze and rewrite larger program units may be required to overcome current semantic bottlenecks.
The experimental scope is necessarily limited to isolated, file-level idioms. Real legacy systems implicate dependency trees, complex build orchestration, and intertwined state/memory models potentially unrepresentable within current quantized LLMs’ context windows. Scaling successful isolated idiom translation to full-system migration remains an unsolved problem.
Conclusion
This work demonstrates that, under a hybrid AST plus rule-constrained LLM pipeline, only a small minority of currently available open, quantized models can reliably translate non-trivial C programs to Java. Even the best fail on advanced semantic constructs, and the majority are irredeemably blocked by basic syntactic or hallucination errors. The practical implication is that while selective, rule-rich prompting can unlock surface translation ability in some code-specialized LLMs, small quantized models are insufficient for robust, automated semantic migration, especially for production-scale, real-world C projects.
Continuous research into fine-tuned, context-aware, and multi-stage code migration pipelines—potentially leveraging larger, private, or ensemble LLMs with integrated program analysis—remains critical for meaningful progress on legacy code modernization.
Reference: "REMODEL-LLM: Transforming C code to Java using LLMs" (2512.11402)