- The paper introduces DOS, a self-supervised framework that distills observable softmaps to capture spatial semantic organization in 3D point clouds.
- It leverages a novel Zipf-Sinkhorn regularization to align prototype assignment with real-world long-tail distributions, enhancing rare class representation.
- DOS achieves state-of-the-art performance in segmentation, detection, and linear probing, demonstrating strong label efficiency and cross-domain transfer.
Self-Supervised Point Representation via Distilling Observable Softmaps of Zipfian Prototypes
Introduction
This work introduces DOS, a self-supervised learning (SSL) framework for 3D point cloud representation that addresses critical limitations of prior SSL paradigms in this domain, namely irregular geometry, shortcut-prone reconstruction, and semantic category imbalance. DOS leverages distillation of semantic softmaps at unmasked ("observable") points, and regularizes prototype assignment with a Zipfian prior via a novel Zipf-Sinkhorn optimal transport procedure. This framework achieves robust semantic abstraction, better long-tail modeling, and strong transferability in linear probing, full fine-tuning, and few-shot settings.
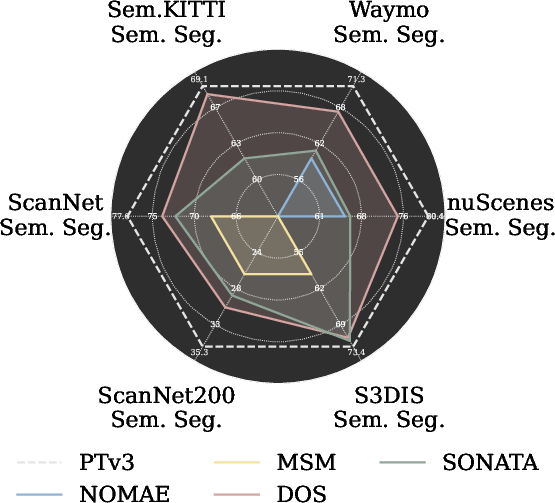
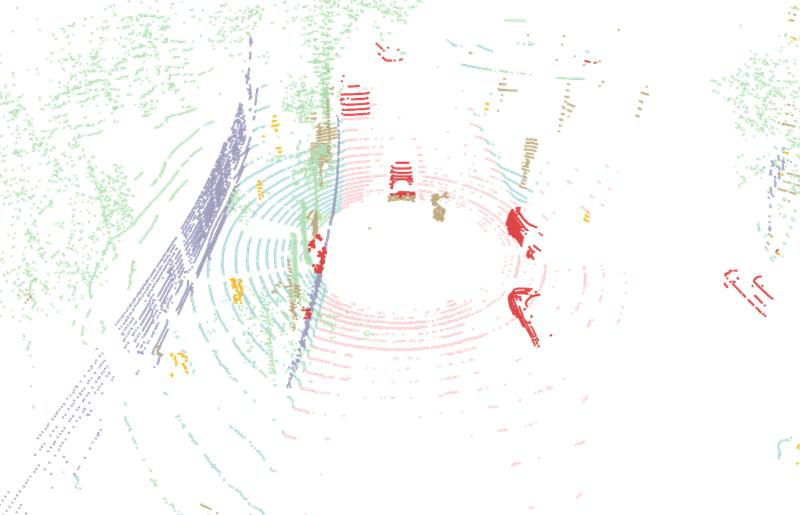
Figure 1: Overview of DOS. DOS distills label-free 3D representations by softmap assignment at observable points, regularizes for semantic diversity, demonstrates SOTA linear probing on 3D benchmarks, and enables strong segmentation in unseen domains with a few samples.
DOS Architecture: Observable Softmap Distillation
DOS adopts a student-teacher self-distillation architecture. A point cloud is augmented into two views; students process masked subsets (observable points only), whereas the teacher encodes the entire cloud and produces targets filtered to these points. Both student and teacher project embeddings to a fixed set of learnable prototypes. Similarities to prototypes are spatially normalized over points, resulting in prototype-specific "softmaps," which capture the spatial distribution of semantic concepts across the scene.
The key distillation loss is a KL divergence between the student's and the Zipf-Sinkhorn-regularized teacher's softmaps, enforcing the student to match not local feature vectors but the spatial semantic organization inferred from the teacher, yielding more stable and structured representation learning.

Figure 2: High-level DOS workflow: Augmentation, masking, teacher/student encoding, prototype similarity, softmap normalization, and the Zipf-Sinkhorn regularization for long-tail semantics.
Comparison to Other Approaches
Traditional contrastive and clustering losses either contrast point/prototype pairs (InfoNCE) or align to prototypes per point (clustering), but do not explicitly model inter-point semantic competition. DOS's softmap loss normalizes over the spatial dimension, explicitly encouraging prototypes to compete spatially, promoting robust and spatially discriminative representations.
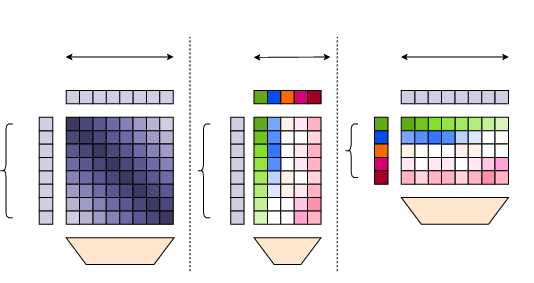
Figure 3: DOS softmap distillation versus contrastive (InfoNCE) and clustering-based methods. Only softmap distillation applies the softmax over points, enhancing spatial competition.
Handling the Zipfian Long-Tail: Prototype Assignment
A key innovation in DOS is Zipf-Sinkhorn regularization of the teacher's softmaps. In real-world 3D data, semantic category frequencies follow a Zipfian (power-law) distribution. Standard Sinkhorn balancing (as in SwAV and its 3D variants) enforces uniform prototype usage and does not fit this distribution. DOS, instead, incorporates a Zipfian prior into the Sinkhorn-Knopp normalization, aligning prototype usage frequency to reflect the long-tailed reality of 3D semantic distributions. Empirically, this improves semantic diversity and coverage, prevents over-segmentation, and enhances the discriminability of rare classes and regions.
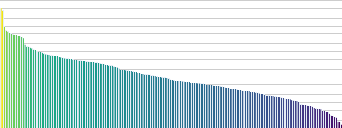

Figure 4: Top: Empirical category frequencies in ScanNet200 follow Zipf's law. Bottom: Prototype activation—Zipf prior improves focus on frequent regions and reduces fragmentation, unlike the uniform prior.
Empirical Results
Semantic Segmentation and Detection
DOS establishes new SOTA across multiple large-scale 3D benchmarks (nuScenes, Waymo, SemanticKITTI, ScanNet, ScanNet200, S3DIS). In linear probing, DOS reaches up to 0.95× supervised performance and consistently surpasses strong previous SSL baselines (e.g., Sonata, MSM, NOMAE). In full fine-tuning, DOS matches or exceeds performance of the best supervised and pretraining-based methods, notably in the context of limited annotation (few-shot settings), confirming strong label efficiency.
For 3D object detection (nuScenes), DOS pretraining gives significant boosts (+4.3 NDS, +7.9 mAP) when integrated into standard detectors (e.g., CenterPoint), in both data-rich and data-scarce regimes.
Cross-Domain Robustness and Few-Shot Analysis
DOS demonstrates strong cross-domain transfer: models pretrained on one dataset generalize well to unseen domains and outperform previous approaches, even without fine-tuning. The method enables zero- and few-shot transfer, with strong segmentation ability on completely novel scenes (e.g., ParisLuco3D) after fine-tuning with as few as five labeled samples.




Figure 5: Zero-shot transfer: DOS pretrained on SemanticKITTI segments previously unseen ParisLuco3D urban scenes, outperforming a supervised backbone without additional adaptation.
Ablations
Incremental ablations on masking, softmap target, and prototype prior confirm large gains from (1) observable-point-only distillation (14.6 mIoU improvement over baselines), (2) softmap loss over feature or cluster assignment regression, and (3) the Zipfian prior (especially for rare/tail classes). Neither classical clustering nor feature regression alone achieves similar performance or diversity.
Varying the Zipf exponent, the best results are achieved for moderate α (e.g., 1.3)—strict uniformity under-fits rare classes, while excessive sharpness destabilizes training and reduces prototype utilization. Softmap objectives furthermore enjoy faster convergence and saturate with fewer prototypes than clustering methods.
Theoretical and Practical Implications
By decoupling spatial reasoning from feature-level similarity, DOS infuses semantic structure into point cloud representations in a self-supervised, annotation-agnostic manner. The framework's capacity to learn robust, semantic, and spatially discriminative features without access to labels or 2D pretraining signals represents a major advance for SSL in truly 3D domains. Practically, DOS reduces annotation burden (label efficiency), supports robust open-domain deployment (generalization), and provides a foundation for downstream tasks beyond segmentation and detection.
Theoretically, the Zipf-Sinkhorn objective highlights the impact of incorporating priors reflecting real-world data imbalances into SSL prototype-based learning, opening new directions for unsupervised structure regularization and non-uniform contrastive objectives.
Future Directions
The extension of DOS to unified, multi-domain pretraining for both indoor and outdoor scenarios remains open. Surpassing supervised linear probing baselines and expanding the approach to multi-modal or adaptive prototype schemes are promising avenues. The architecture's flexible abstraction and pretraining signal may catalyze progress in autonomous driving, robotics, and large-scale spatial scene understanding.
Conclusion
DOS introduces a principled, scalable, and effective SSL framework for 3D point cloud understanding, integrating observable-point distillation, semantic softmaps, and Zipfian-regularized prototype competition. It offers SOTA performance across semantic scene understanding and detection tasks, robust cross-domain transfer, and compelling label efficiency. DOS's methodological innovations—particularly spatial softmap distillation and Zipf-aware Sinkhorn assignments—establish strong priors for the future of self-supervised geometric learning.
(2512.11465)