- The paper demonstrates a modular neuro-symbolic approach that integrates foundational perception models, LLM-based high-level planning, and deterministic control to enhance safety and interpretability.
- It validates the framework in both simulation and on a real UR3e robot, achieving up to 100% success in LLM-direct planning and effective real-time safety handling through ASR.
- The study addresses 'action hallucination' in LAMs by enforcing formal plan verification and enabling human oversight, offering a blueprint for scalable, secure robotics.
Modular Neuro-Symbolic Architectures for Large Action Models in Human-in-the-Loop Robotics
Introduction
This paper presents a detailed architecture for constructing Large Action Models (LAMs) in intelligent, human-interactive robotic systems without resorting to monolithic, end-to-end neural sequence models. Instead, the authors utilize a composition of foundation models for perception, LLMs for high-level decision making, and deterministic symbolic wrappers that ensure interpretability, reliability, and control. The framework is validated in a real-world ROS2-based robot system and in simulation, with emphasis on modularity, verifiability, and human-in-the-loop safety. This approach is situated as a response to the current limitations of black-box LAMs, particularly concerning “action hallucination” and the lack of formal safety and interpretability guarantees.
System Architecture
The framework is architected as a stratified planning hierarchy that tightly integrates multi-modal perception, various tiers of planning, and deterministic control. Each functional layer is modular and realized as independent ROS2 nodes, supporting the design’s extensibility and computational tractability.
Following the perception and speech acquisition, the system interprets high-level natural language commands via LLMs and translates them into verified, feasible robot actions through either a neuro-symbolic or neural-direct pipeline. A central tenet is the restriction of LLMs to the generation of intermediate, human-interpretable symbolic representations (such as PDDL or curated API calls), which are always reviewed pre-execution—either automatically or by human operators.
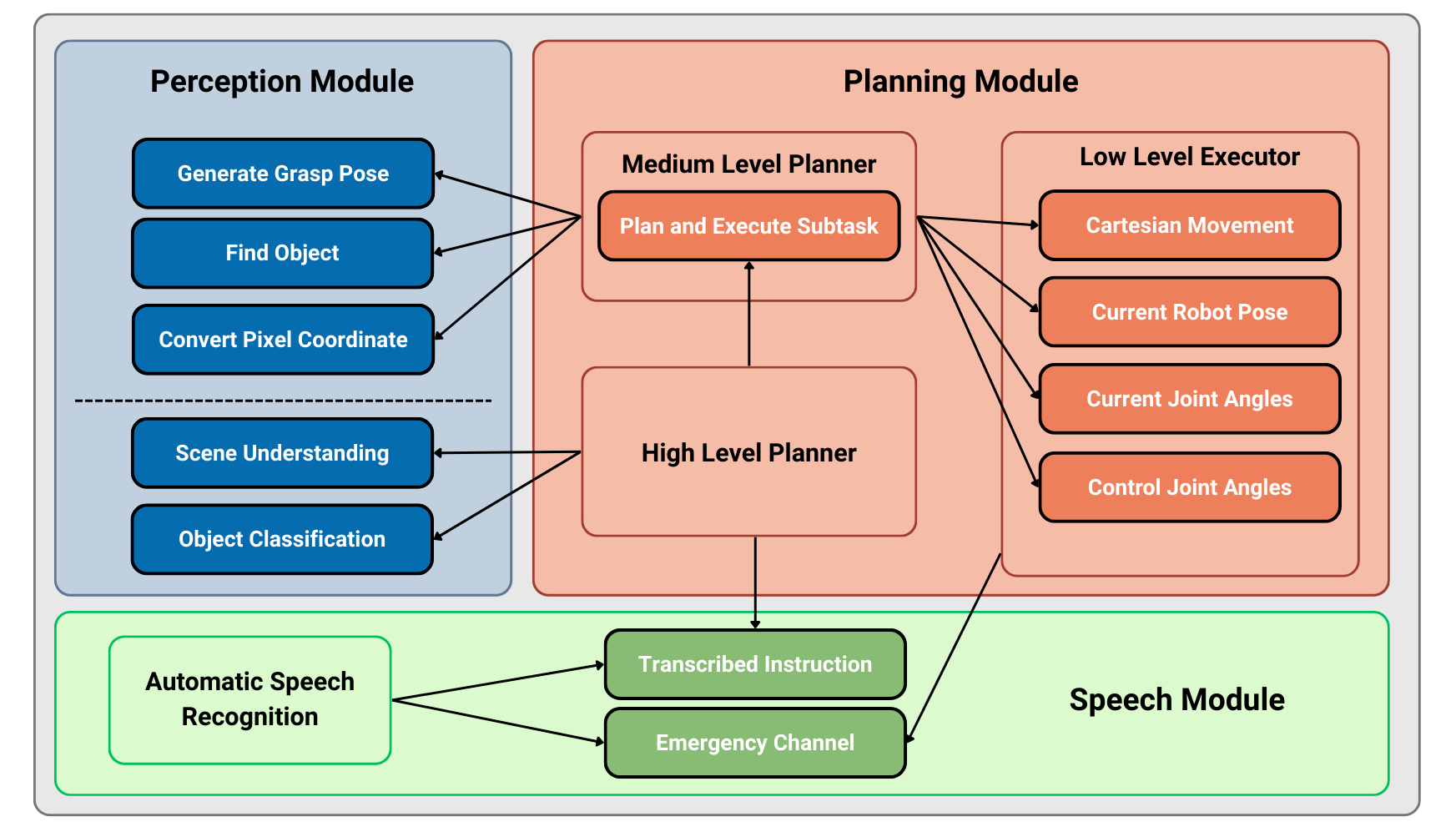
Figure 1: The overall system architecture, connecting cognitive reasoning with deterministic motion control in a hierarchical fashion.
The architecture’s strength lies in its separation of concerns: perception is handled by highly specialized models, control is managed by deterministic planners (e.g., MoveIt2), and only the translation of user intent and high-level reasoning is left to the stochastic LLMs, tightly constrained by symbolic “wrappers.”
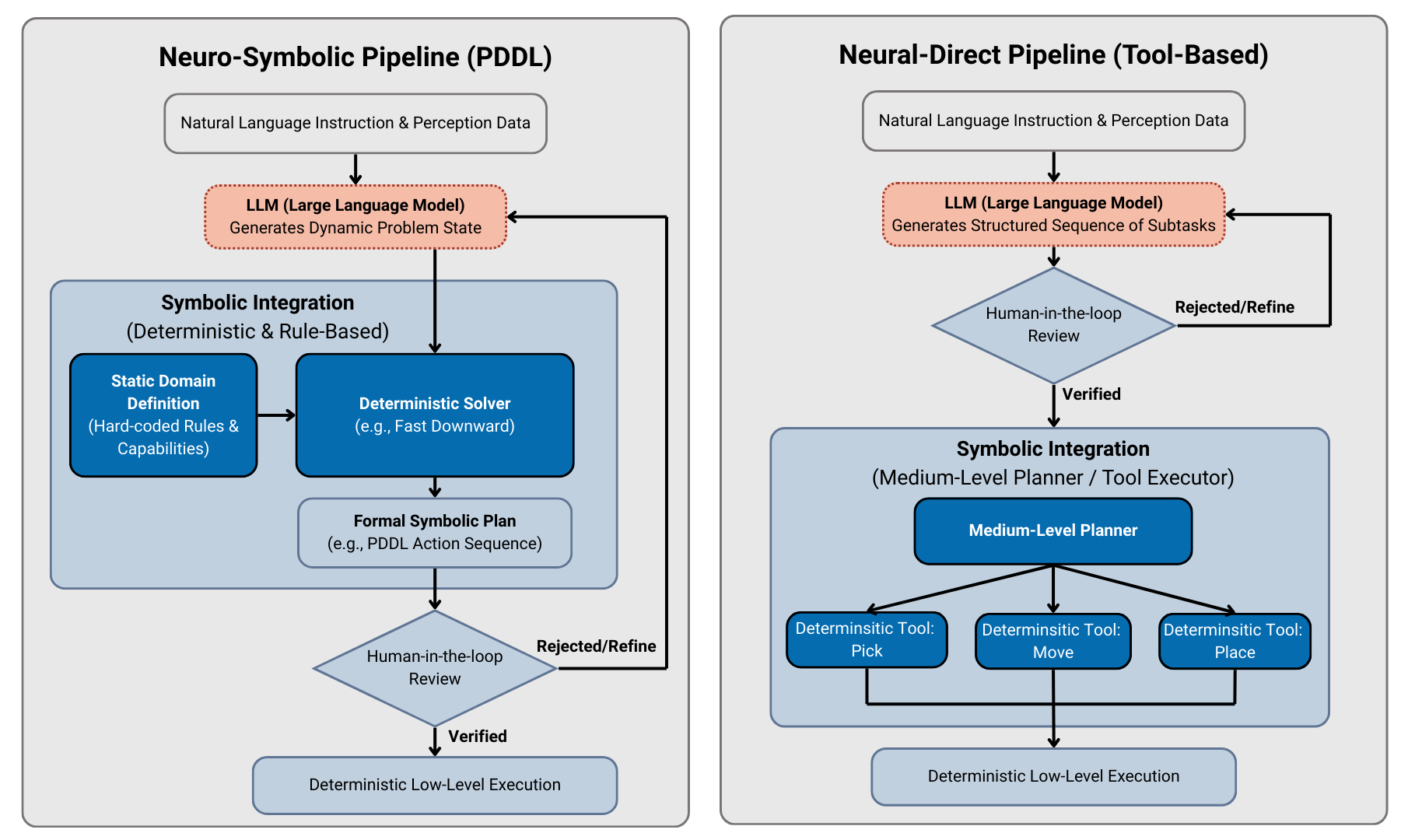
Figure 2: Symbolic wrappers insulate LLMs using intermediate verifiable representations, supporting human-in-the-loop debugging and formal logic-based safety checks.
Perception and Speech Modules
The perception subsystem leverages open-vocabulary foundation models for instance segmentation and classification, e.g., SAM for segmentation, CLIP for semantic classification, and GraspNet for geometric affordances and grasp configuration estimation. The system maintains modularity at the ROS2 node level, with specialized nodes for transformation and scene understanding, permitting both on-demand querying for efficiency and fine-grained control over computational resources.
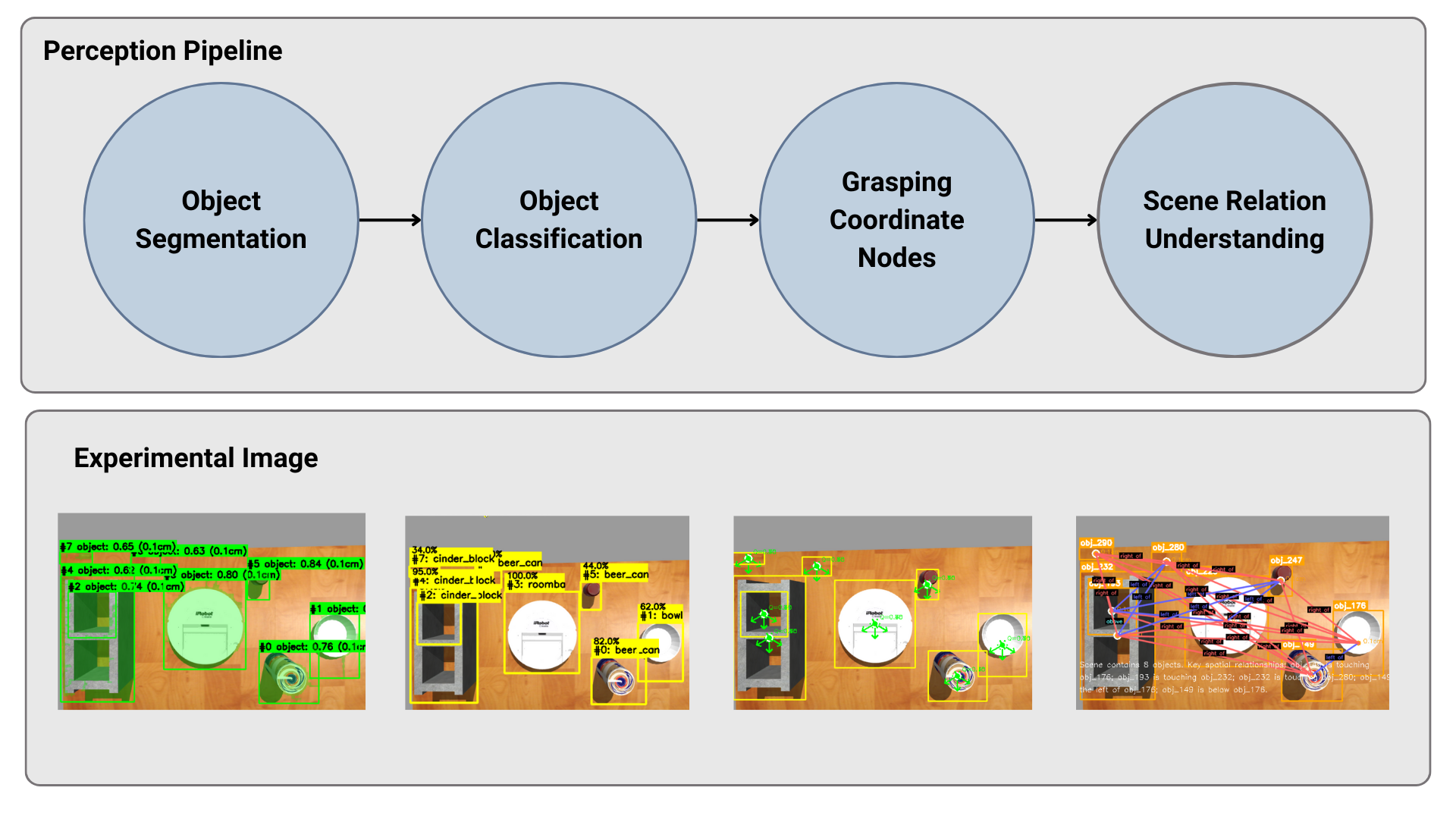
Figure 3: Modular ROS2 perception architecture mapping RGB-D sensory streams into usable semantic and geometric constructs.
The speech interface employs a state-of-the-art neural automatic speech recognition (ASR) system, with robust deactivation-word and emergency interruption mechanisms to guarantee responsiveness in operational and safety-critical scenarios.
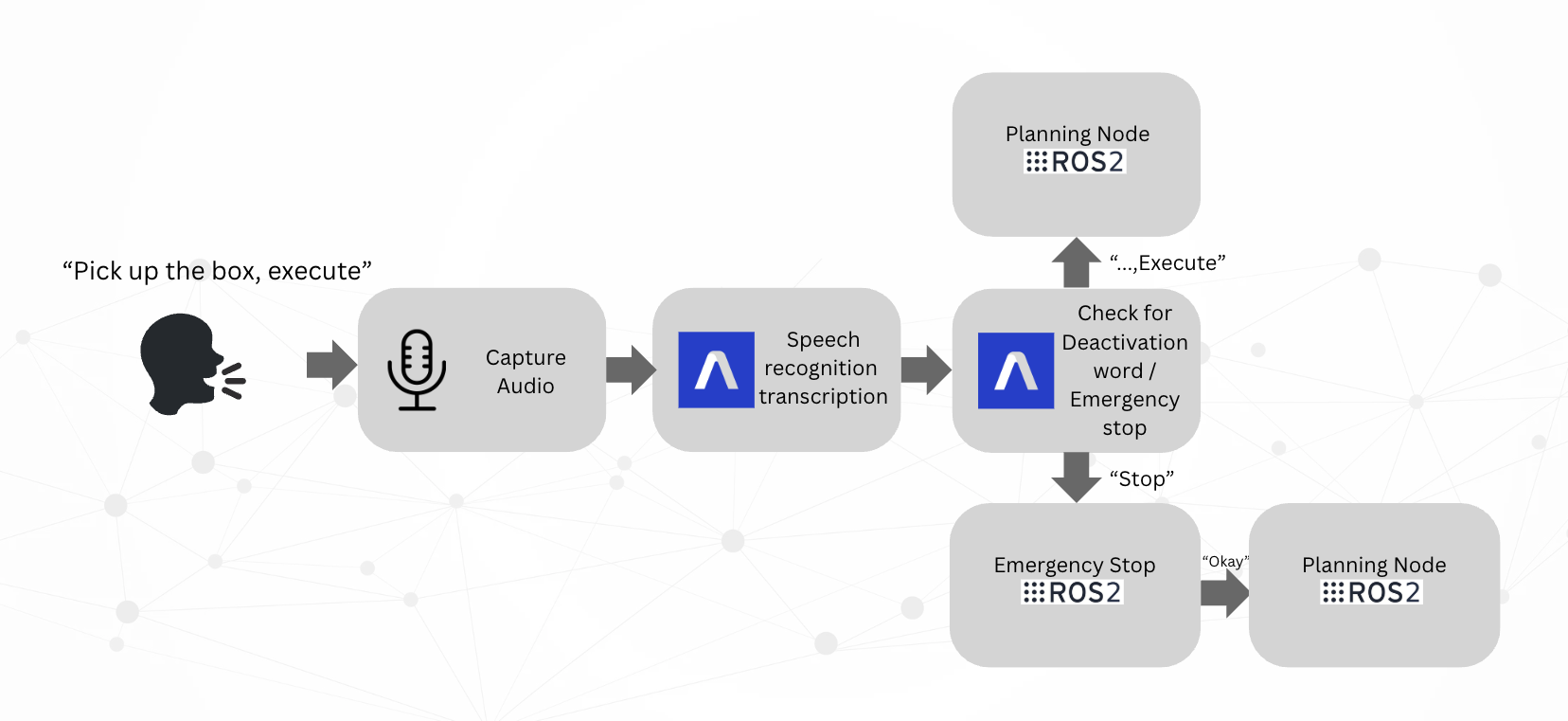
Figure 4: Overview of the ASR pipeline enabling robust, real-time verbal command interpretation and safety handling.
Central to the paper is the stratified planning module, composed of:
- High-Level Planner: Utilizes LLMs (via LangChain) either for direct structured tool-use planning (“neural-direct”) or translation to formal PDDL problems (“neuro-symbolic”). In both pipelines, LLM generation does not extend to direct, arbitrary robot code but always through tightly bounded interfaces.
- Medium-Level Planner: Interprets verified high-level outputs into deterministic service/tool invocations, managing orchestration and feedback.
- Low-Level Executor: Handles motion planning (MoveIt2), trajectory computation, and adheres strictly to hardware safety and kinematic constraints.
In both neural-direct and neuro-symbolic approaches, human-in-the-loop review is always possible; all plans may be presented for approval or edited for correctness before robot execution.
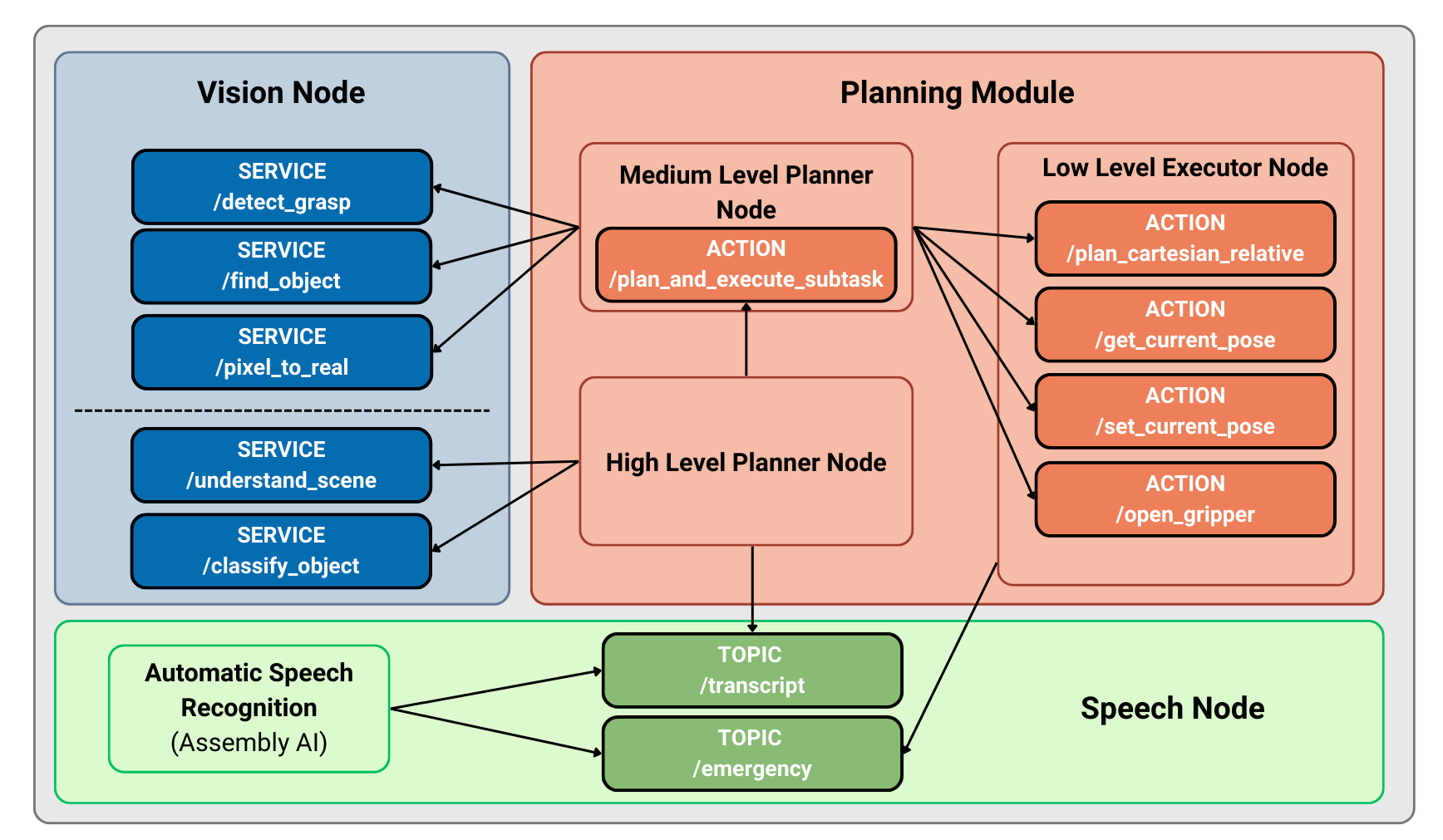
Figure 5: Complete ROS2 graph with distributed nodes for perception, speech, planning, and low-level execution.
Experimental Validation
The proposed architecture is validated in both simulated (Gazebo) and physical (UR3e robot with Robotiq gripper) environments, showing end-to-end portability and architectural consistency.
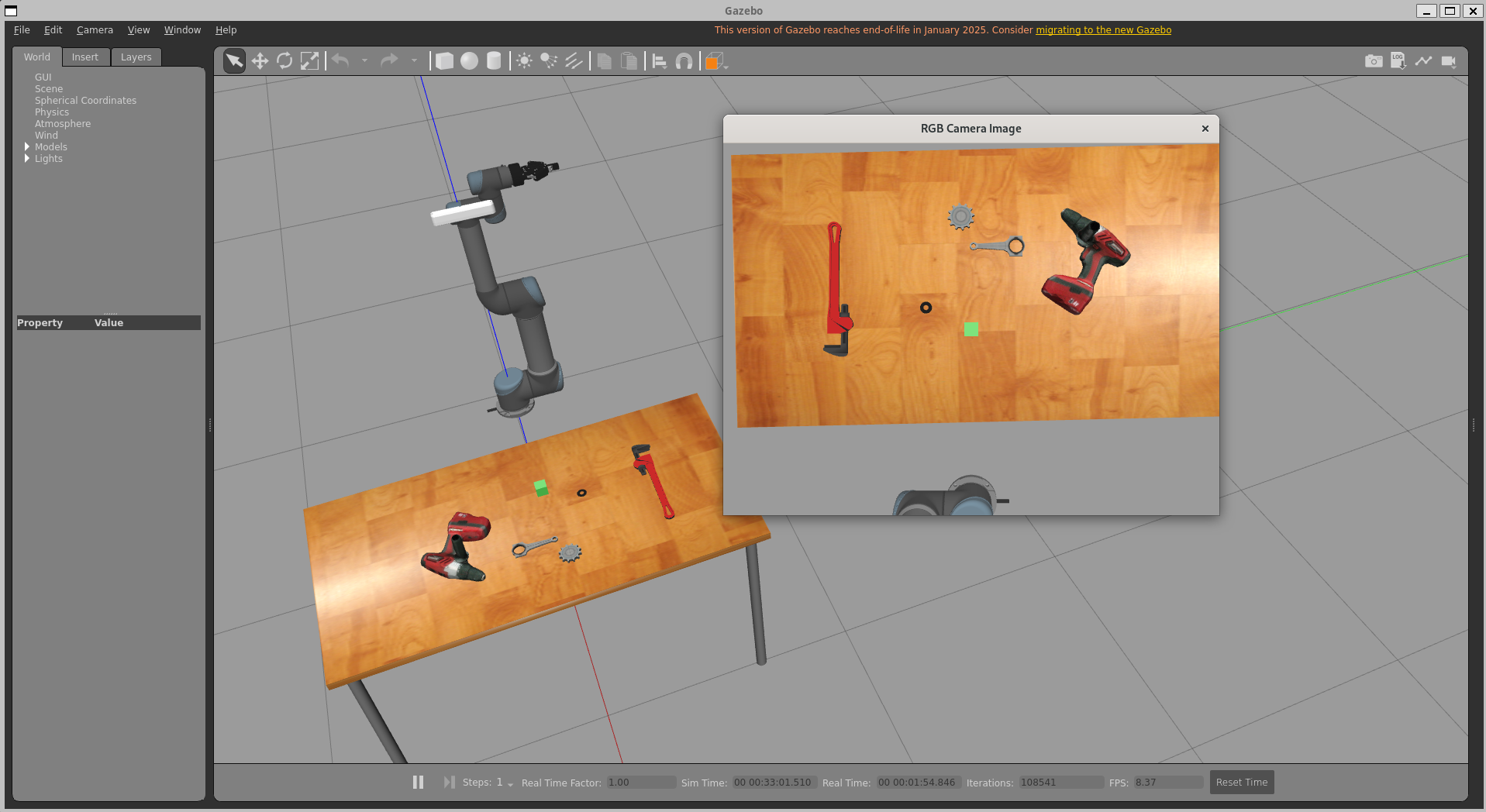
Figure 6: Gazebo-based simulation environment for component validation with standard ROS2 interfaces.
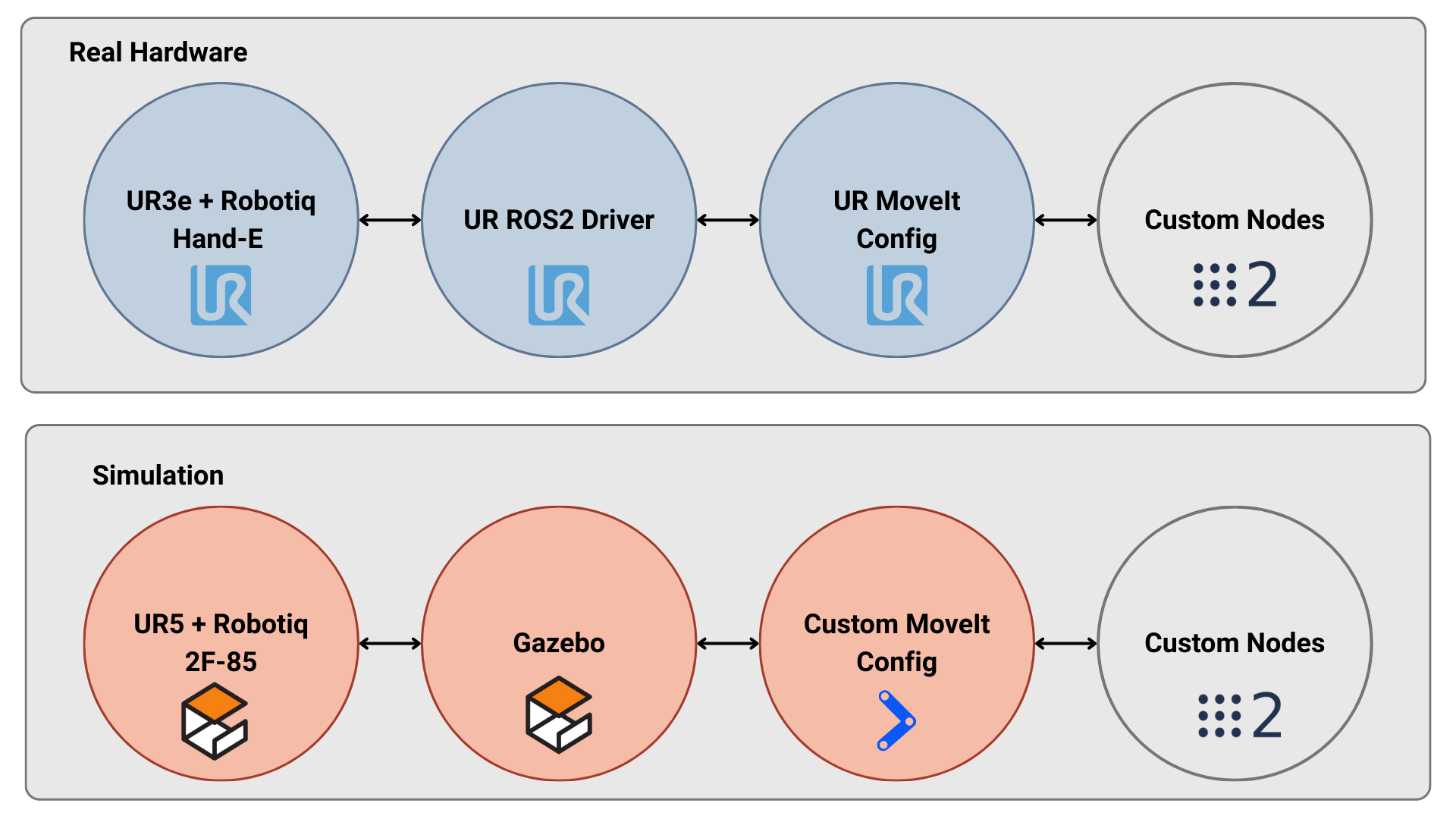
Figure 7: Hardware-software consistency demonstrated via simultaneous operation in simulation and on real-world UR3e robot hardware.
Perception Results
On multi-object scenes, the perception stack demonstrates:
- AP (IoU≥0.5): 0.741 (SAM segmentation)
- Top-1 accuracy (CLIP classification): 0.85
- Grasp quality: 0.746 (GraspNet)
- Scene relational understanding: 0.98
- Pixel-to-real RMSE: 0.054m
Occlusion and object overlap are challenge points for geometric modules, but semantic grounding is robust—sufficient for natural language condition grounding.
Speech Recognition
The ASR system achieves 97.9% mean accuracy over a suite of 30 complex commands and consistently detects safety keywords, ensuring reliable, real-time system control.
Planning Evaluation
Two planning pipelines are compared:
- LLM-Direct ("Tool-Use"): 100% success, maximal flexibility for abstract instructions, average execution of 7.2s/step.
- Neuro-Symbolic (PDDL-based): 91% success, lower execution time (6.83s/step), mathematically verifiable plans, more sensitive to PDDL syntax errors.
Both frameworks confine LLM stochasticity to plan reasoning, enforce plan interpretability, and guarantee human revision capabilities before actuation. Emergency stop latency is empirically bounded at 1.41±0.14 seconds, demonstrating effective safety separation between high-level planning and low-level actuation layers.
Theoretical and Practical Implications
The findings indicate that LAM intelligence is achievable without prohibitively expensive end-to-end model training or inference. Fundamental capabilities such as plan verifiability, human oversight, and flexible integration of new perception modules are maintained through symbolic encapsulation and modular design.
This work challenges the prevailing focus on larger, monolithic LAMs—arguing that hybrid neuro-symbolic systems can deliver state-of-the-art performance while addressing the persistent safety and interpretability limitations identified in recent surveys (e.g., (Li et al., 4 Jan 2025, Wang et al., 2024)). The architectural paradigm further provides a template for other domains where safety, transparency, and human oversight are paramount.
The symbolic wrapping strategy addresses the crucial challenge of “action hallucination,” preventing invalid or unsafe robot behaviors by enforcing formal plan verification prior to execution. The modularity of the architecture facilitates straightforward extension and adaptation to new robotic domains or regulatory requirements.
Future Directions
Key bottlenecks remain in the syntactic and semantic brittleness of neuro-symbolic pipelines—particularly the correctness of PDDL code generation by LLMs under ambiguous or complex instructions. Future research should focus on iterative plan refinement, self-diagnosing generation errors, and the dynamic auto-generation of domain models, as well as on scaling hybrid architectures to less-structured, more dynamic environments.
Conclusion
This paper demonstrates that robust, transparent, and efficient Large Action Models can be realized through a modular neuro-symbolic approach. By wrapping stochastic LLM reasoning in deterministic, verifiable symbolic interfaces—and embedding human-in-the-loop review at the plan level—the system achieves high success rates, verifiable safety, and full interpretability. This framework provides an actionable blueprint for practitioners aiming to deploy LAMs in real-world, safety-critical applications, offering a pathway to scalable agentic intelligence that does not compromise on control or transparency.