- The paper proposes a framework, Streaming Continual Learning (SCL), that leverages in-context LTMs to reconcile stability and plasticity in dynamic data streams.
- It details a dual-memory data selection strategy combining distribution matching and compression to enhance retention and rapid adaptation on nonstationary tabular data.
- Empirical results show improved performance over traditional methods, highlighting memory efficiency and reduced need for frequent model retraining.
Bridging Streaming Continual Learning via In-Context Large Tabular Models
Introduction: Unifying Continual and Stream Learning Paradigms
The paper "Bridging Streaming Continual Learning via In-Context Large Tabular Models" (2512.11668) formalizes an algorithmic and conceptual synthesis between two historically isolated branches of lifelong machine learning: Continual Learning (CL), which prioritizes long-term retention and mitigation of catastrophic forgetting, and Stream Learning (SL), which emphasizes rapid real-time adaptation on high-frequency data streams but often neglects forgetting. The authors argue that large in-context tabular models (LTMs) present a unique opportunity to bridge these paradigms through a novel framework, Streaming Continual Learning (SCL). Central to this approach is on-the-fly summarization of unbounded streams into compact sketches that LTMs can consume, inheriting efficient compression guarantees from SL and the replay-based desiderata of CL. The paper frames the unification around two core axes for in-context data selection: distribution matching (managing stability-plasticity trade-offs) and distribution compression (driving memory diversification and retrieval mechanisms).
Background: Architectural Disparities and Divide-to-Conquer in SL/CL
SL has traditionally relied on incremental decision trees (IDTs) and their ensembles, which can efficiently process streams via one-pass statistics, quick convergence, and concept drift handling through subtree replacement.
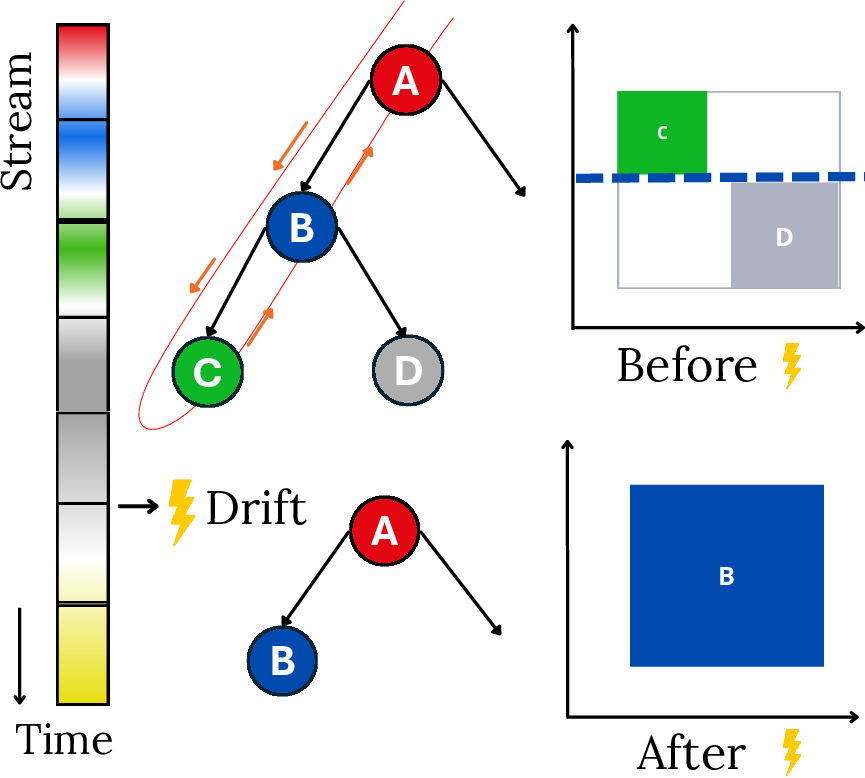
Figure 1: IDT ensembles incrementally expand to manage concept drift in streaming data.
However, these approaches are limited in representation capacity, prone to forgetting (especially with class-conditional or rare event estimation), and struggle to capture feature dependencies or adaptation beyond local minima. In contrast, CL leverages deep learning architectures with extensible parameter spaces, supporting structural adaptation and complex data.
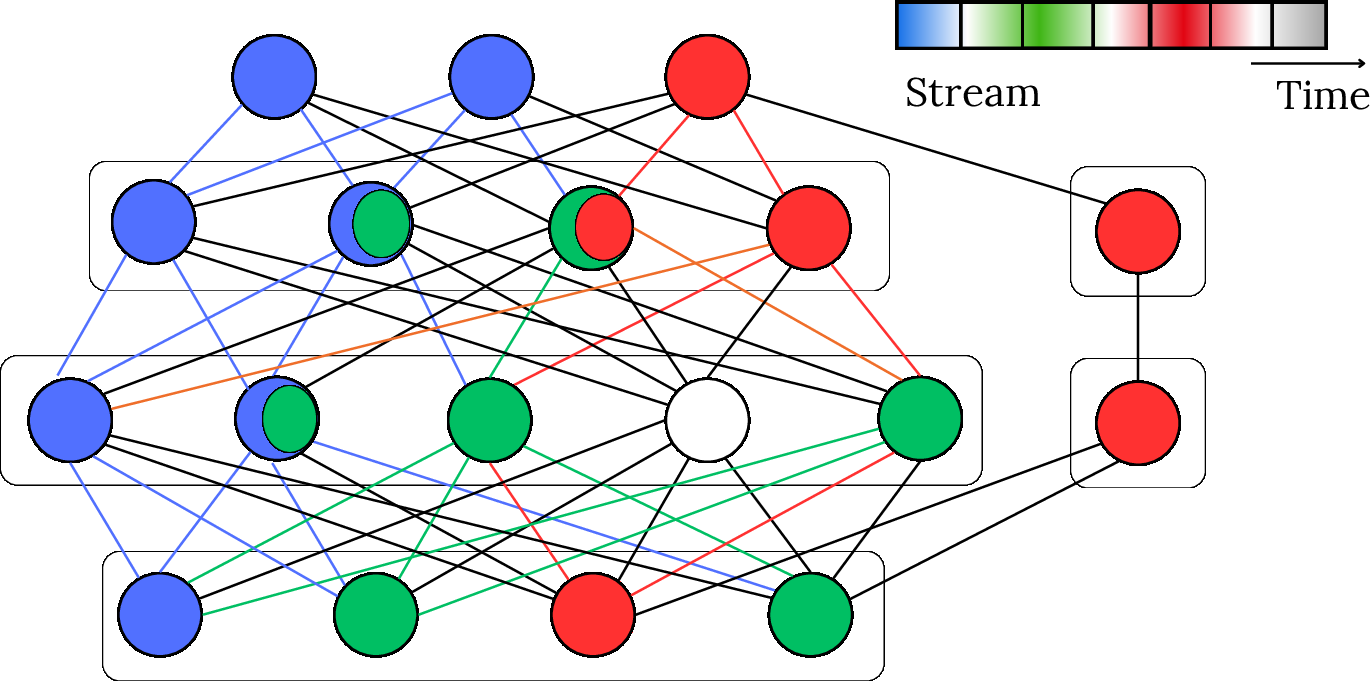
Figure 2: CL leverages advanced parameter adaptation and activation schemas in deep learning.
Yet, these models typically require multiple epochs to learn effectively under entangled parameterization, are susceptible to overwriting prior knowledge (catastrophic forgetting), and underperform on irregular tabular data due to inappropriate inductive biases. As a result, both domains have developed complex, often narrowly scoped "divide-to-conquer" strategies to balance plasticity (fast adaptation) and stability (knowledge retention), as depicted by the incrementally shrinking solution space for shared parameterizations.
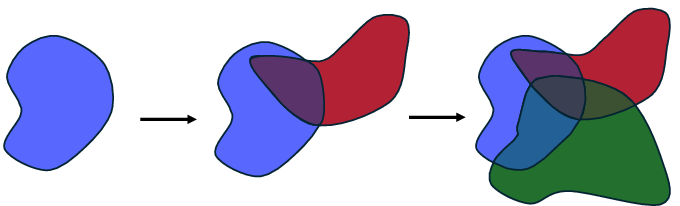
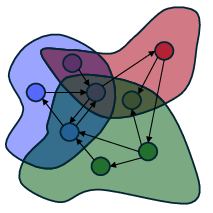
Figure 3: Parameter space becomes increasingly constrained as more concepts are incrementally accumulated.
The unresolved tension is that unlimited parameter sharing maximizes generalization but exacerbates interference, while disjoint parameterization scales poorly. Ensembles and modular, compositional methods offer a middle ground via selective reuse and dynamic specialization.
SL and CL Desiderata Mapped to Data Selection
The authors distill SL and CL's operational imperatives into four intertwined desiderata, all of which are reframed in the LTM-centric SCL context:
- Stability: Maintaining predictive power on previously encountered concepts/classes.
- Plasticity: Rapid adaptation to new, possibly nonstationary distributions.
- Diversification: Ensuring stored/replayed data (or submodels) are non-redundant and cover the full relevant distribution.
- Retrieval: Quickly and selectively recalling or activating representation pathways or data relevant to upcoming patterns.
Classic examples include IDTs forgetting due to missing class priors and estimators after concept drift—visualized in the paper for class-incremental settings:
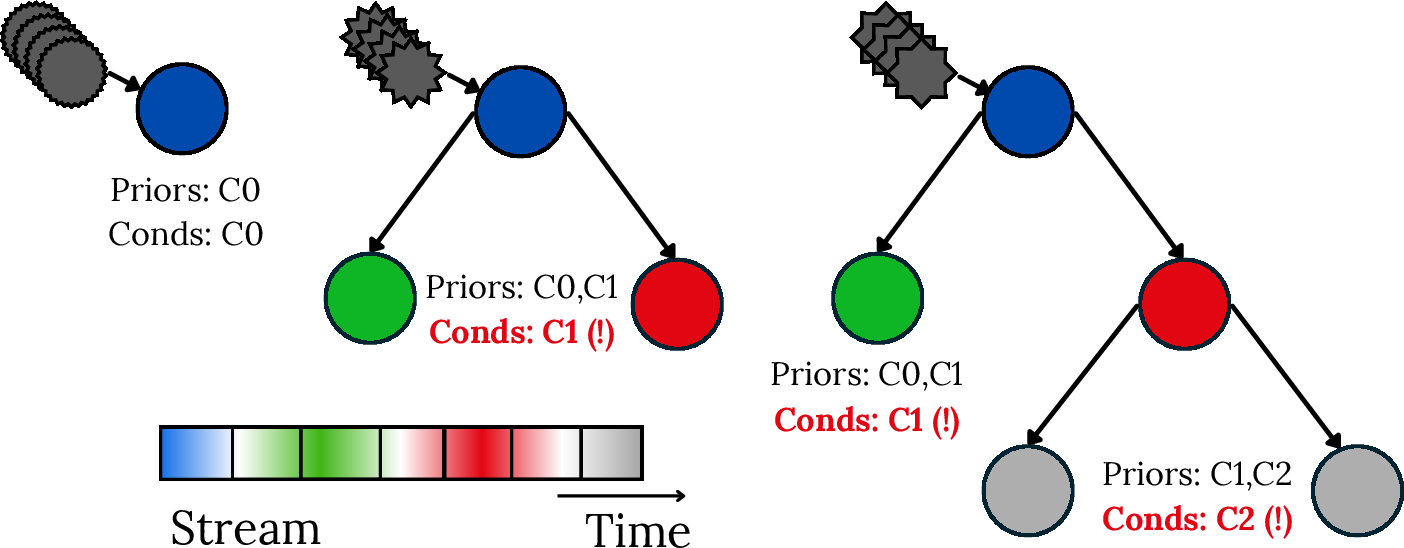
Figure 4: IDTs’ conditional classification mechanisms fail in class-incremental streams due to missing prior estimates for previously observed classes.
In deep networks, optimization for new tasks may transiently degrade old task performance as SGD traverses loss landscapes, even with regularization-based stability methods:
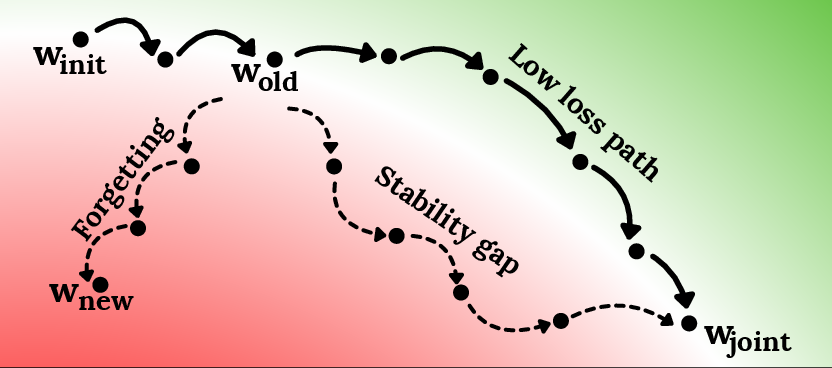
Figure 5: SGD traverses high-loss regions for old tasks when optimizing for joint objectives, temporarily increasing forgetting.
Diversification and Retrieval in Ensembles and Modules
Diversification in SL often arises from ensemble structure—diverse subtrees, random subspaces, or heterogeneous meta-models, as illustrated below:
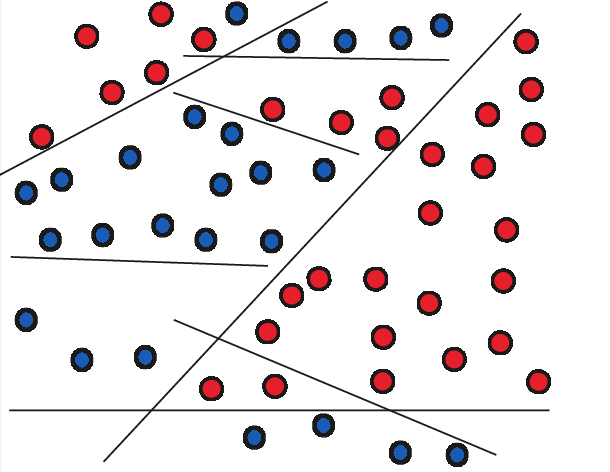
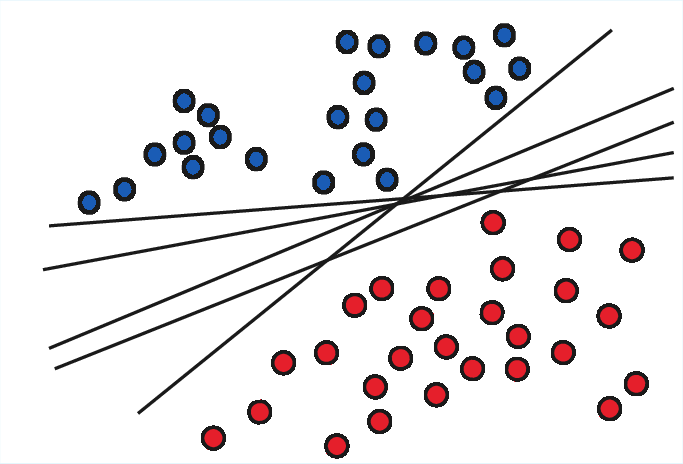
Figure 6: Diversification through complementary perspectives in complex feature spaces.
Retrieval, whether probabilistic or meta-learning-based, orchestrates the selection or activation of components/models best suited to the immediate data regime, as illustrated in the modular and mixture-of-experts contexts:
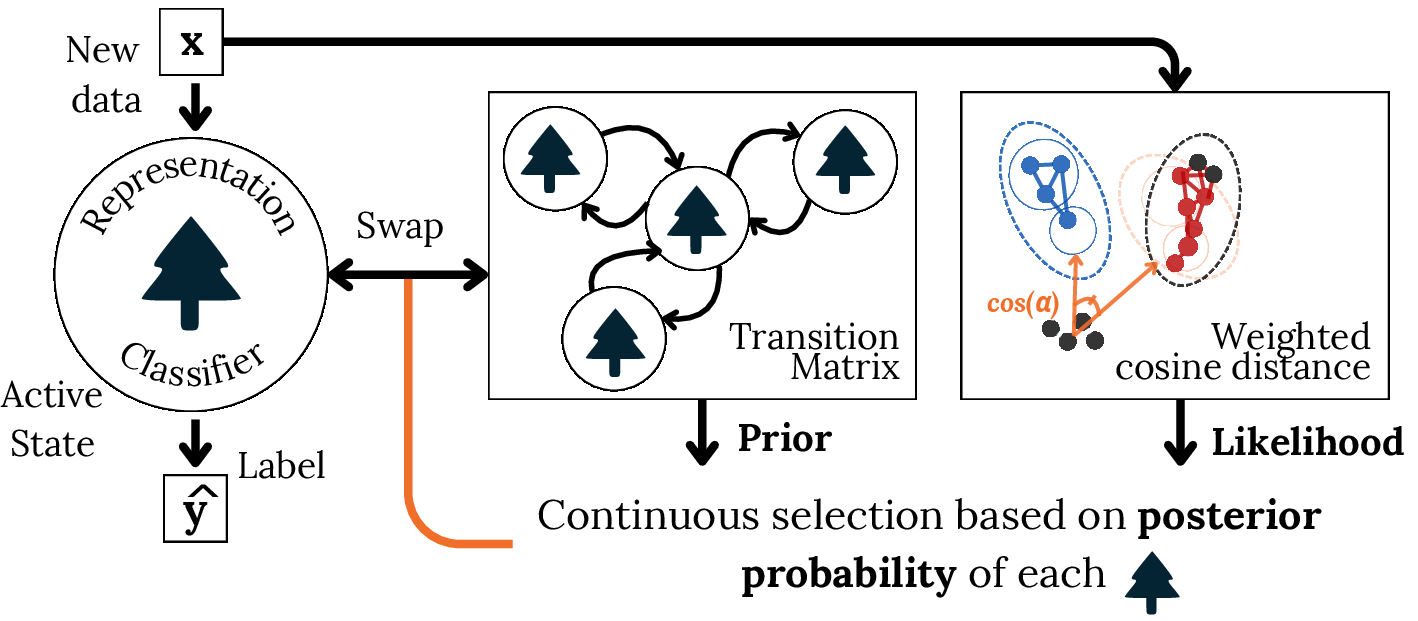
Figure 7: Bayesian retrieval with priors and likelihoods for candidate model selection.
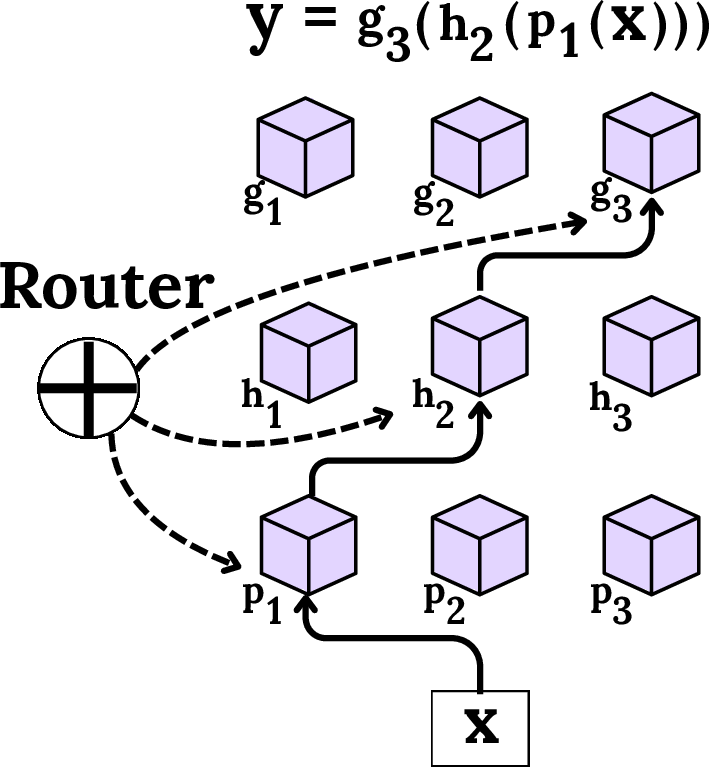
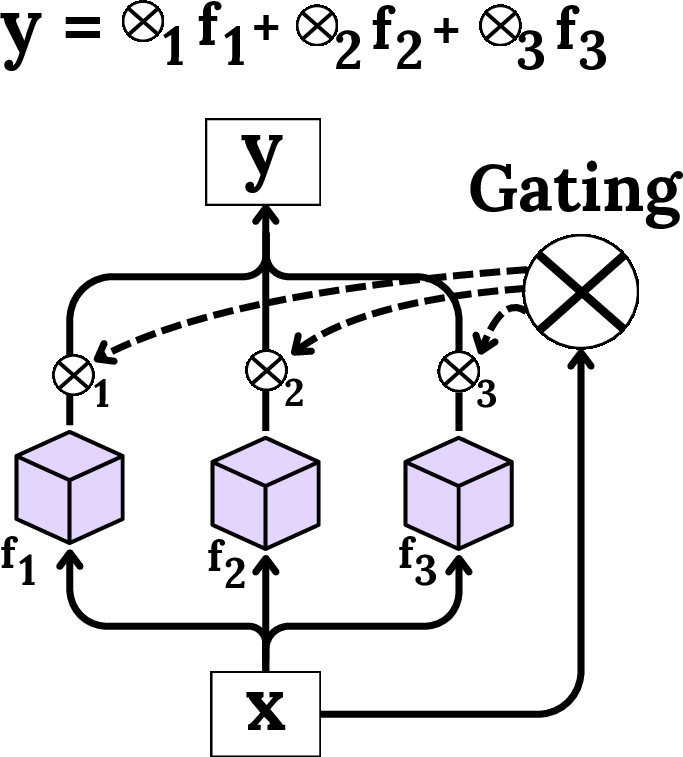
Figure 8: Modular routing for compositional specialist retrieval.
The LTM Paradigm: In-Context Data Selection as Stateful Learning
Modern LTMs, such as pre-trained transformer models for tabular data, invert the classic model-centric learning loop. Rather than frequently retraining model parameters, the system adapts by summarizing streaming data into a limited “context window”—directly selected, diversified, and retrieved at inference time. This framework is visualized, contrasting traditional SL/CL (where model parameters are constantly adapted) with SCL, where the learned object is the data context itself:
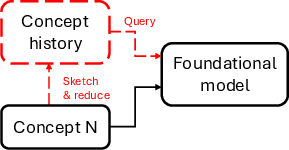
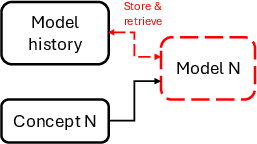
Figure 9: In-context stream mining: LTMs adapt by curating the data in their context, keeping model parameters fixed.
The LTM architecture—typically transformer-based and pre-trained on generative/causal tabular data—can process extremely large contexts, supporting classification and regression tasks in a single forward pass without further parameter updates.
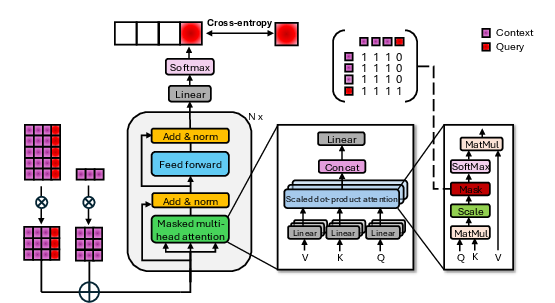
Figure 10: Transformer-based LTM architecture and pre-training design.
This paradigm neatly merges SL’s and CL’s key strengths: computational guarantees from data stream summarization and resource-bounded memory management (SL), with explicit episodic memory replay and distributional support across nonstationary tasks (CL).
Data Selection Principles: Distribution Matching and Compression
Distribution Matching: Balancing Plasticity and Stability
The context construction problem becomes fundamentally a data selection challenge: which points from an unbounded stream should be preserved in the limited context for inference? Viewed from a frequentist perspective, LTMs are highly sensitive to the distribution of in-context samples, with significant implications for both variance and bias:
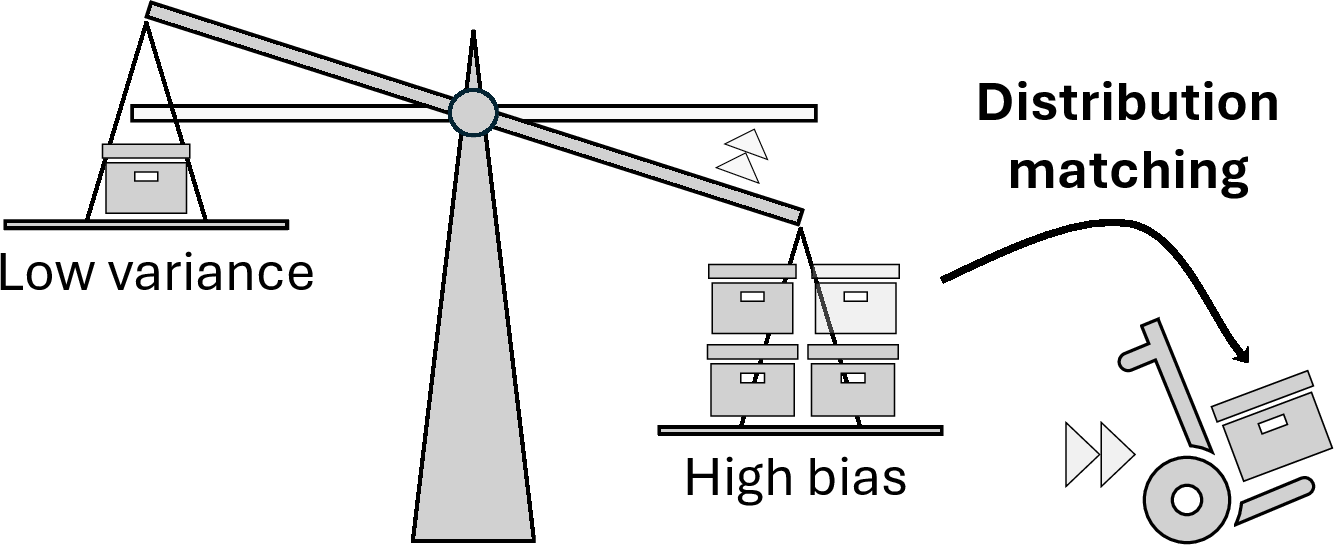
Figure 11: The effect of context sample distribution on model bias and variance in in-context learning.
A dual-memory FIFO system is proposed as a baseline: short-term memory preserves recent (plastic) instances, long-term memory preserves rare or historically significant (stable) classes.
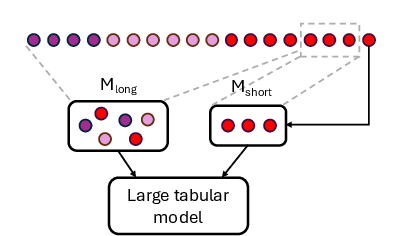
Figure 12: Short-term memory tracks transient adaptations; long-term memory secures rare but important classes for stability.
Distribution matching involves selecting either recent or historic data to tune this trade-off, but naïve policies (such as fading or round-robin) provide only coarse-grained control. Inductive biases on similarity, density, clustering, or manifold structure are advocated to improve selection and promote generalization.
Distribution Compression: Diversification, Retrieval, and Efficiency
Efficient memory use is formulated as distribution compression—diversification ensures non-redundant coverage, and retrieval prioritizes contextually relevant or maximally informative samples. The mechanism is depicted as follows:
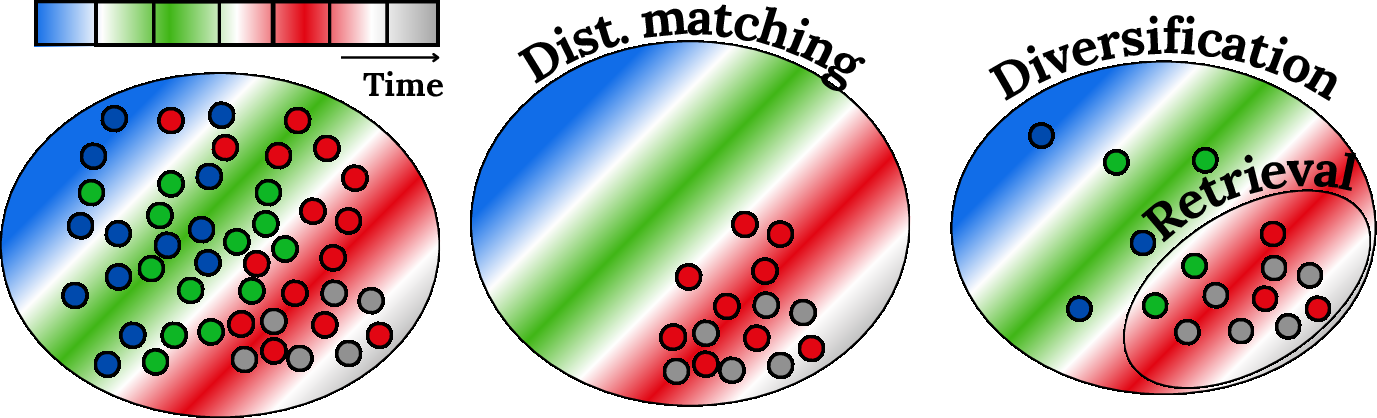
Figure 13: Distribution matching aligns context to target; distribution compression maintains an efficient and diversified memory with targeted retrieval.
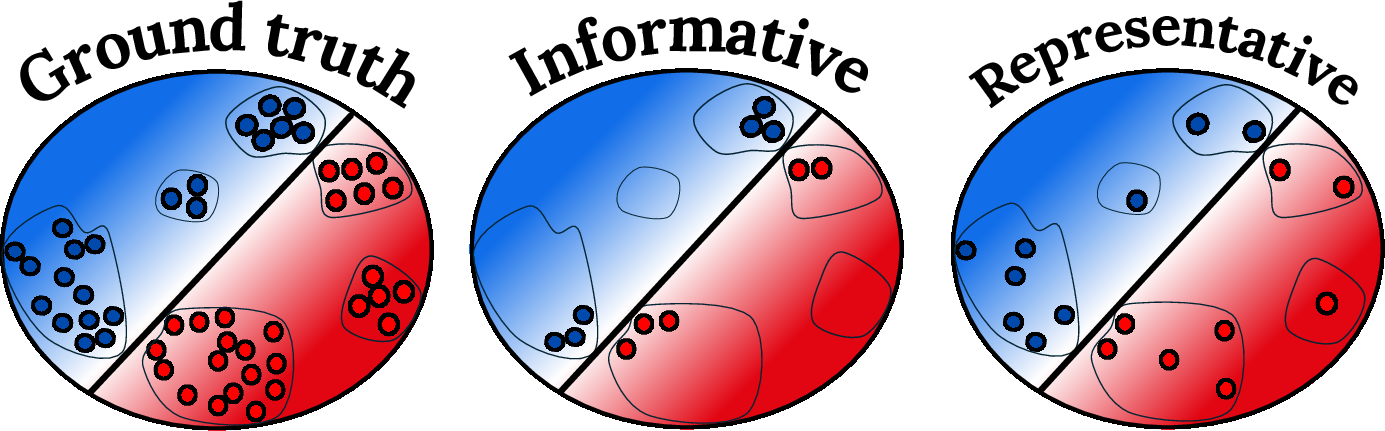
Empirical evidence is reported that combining similarity and diversity scoring (rather than pure similarity) consistently yields improved performance:
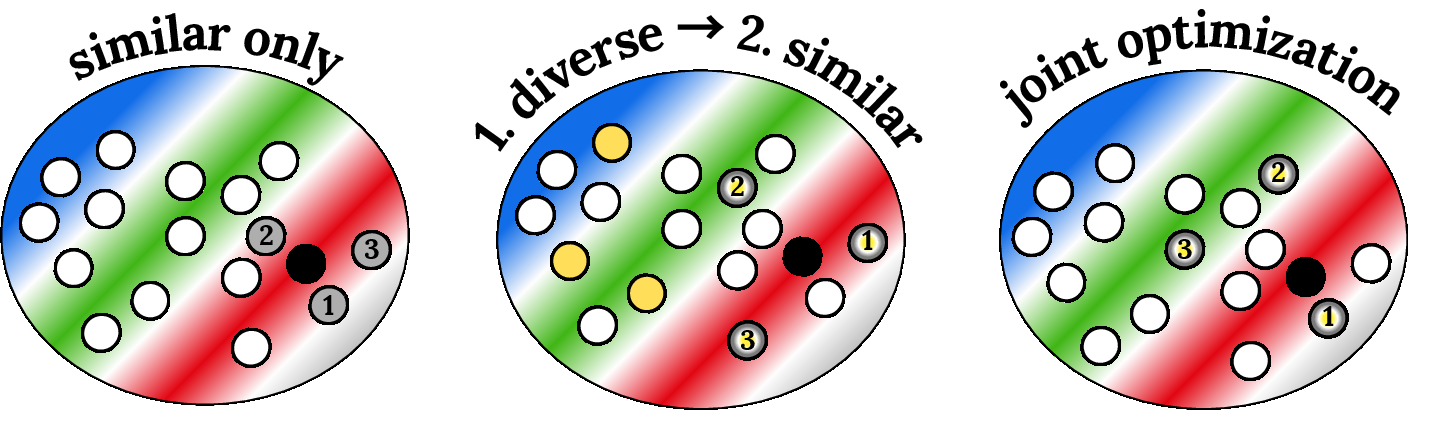
Figure 14: Different context selection policies—naïve similarity, similarity from a compressed set, or a similarity-diversity balance—have distinctive impacts on coverage and generalization.
Two major classes of scoring functions are outlined:
The context construction challenge is thus elevated from individual sample selection to subset selection under resource and memory constraints, integrating experience from active learning, continual learning, and streaming data summarization for multi-objective optimization.
Implications, Limitations, and Theoretical Outlook
The outlined framework has marked practical implications: LTMs—coupled with rigorous data selection—can simultaneously address memory efficiency, adaptivity, and knowledge retention in unbounded, nonstationary stream settings, without complex continual (re-)training procedures. This approach abstracts away from parametric model adaptation, focusing entirely on the optimal organization of context data at inference.
Numerical results summarized from prior work indicate consistent outperformance of this strategy over traditional methods such as Adaptive Random Forest and Streaming Random Patches on canonical streaming benchmarks, with particular improvements on datasets characterized by rapid distribution shifts or rare class re-occurrence.
Contradictory to prevailing dogma, the authors claim that SCL challenges the necessity of frequent model retraining in dynamic data stream environments, instead leveraging LTM's in-context capabilities to achieve competitive or superior performance simply through intelligent data subset curation.
Future theoretical advances may allow further end-to-end solutions: instance-specific activation of LTM modules, meta-learned prompters, or hierarchically optimized context construction policies using reinforcement or bandit algorithms, as suggested by recent work in in-context learning and prompt engineering. However, the authors caution that deployment of LTMs at the edge or in extreme real-time scenarios may still face engineering constraints, best addressed by ongoing work in TinyML and hardware-aware ML.
Conclusion
"Bridging Streaming Continual Learning via In-Context Large Tabular Models" (2512.11668) delivers a comprehensive, data-centric framework reconciling the foundational trade-offs of stability, plasticity, diversification, and retrieval that govern lifelong learning on streams. By formalizing context construction in LTMs as a dual objective—maximizing both distributional matching and compression—the paper articulates a new research direction for scalable, memory-efficient, and adaptive tabular learning. The approach not only dissolves entrenched boundaries between SL and CL, but also positions in-context data selection as a first-class algorithmic citizen in future lifelong learning paradigms for tabular data and beyond.