Agile Flight Emerges from Multi-Agent Competitive Racing
Abstract: Through multi-agent competition and the sparse high-level objective of winning a race, we find that both agile flight (e.g., high-speed motion pushing the platform to its physical limits) and strategy (e.g., overtaking or blocking) emerge from agents trained with reinforcement learning. We provide evidence in both simulation and the real world that this approach outperforms the common paradigm of training agents in isolation with rewards that prescribe behavior, e.g., progress on the raceline, in particular when the complexity of the environment increases, e.g., in the presence of obstacles. Moreover, we find that multi-agent competition yields policies that transfer more reliably to the real world than policies trained with a single-agent progress-based reward, despite the two methods using the same simulation environment, randomization strategy, and hardware. In addition to improved sim-to-real transfer, the multi-agent policies also exhibit some degree of generalization to opponents unseen at training time. Overall, our work, following in the tradition of multi-agent competitive game-play in digital domains, shows that sparse task-level rewards are sufficient for training agents capable of advanced low-level control in the physical world. Code: https://github.com/Jirl-upenn/AgileFlight_MultiAgent


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Clear, Simple Summary of “Agile Flight Emerges from Multi-Agent Competitive Racing”
Overview
This paper is about teaching small racing drones to fly fast and smart—like human racers—using artificial intelligence. Instead of telling the drones exactly how to fly, the researchers let two AI-controlled drones race against each other and only rewarded them for winning. Surprisingly, the drones learned both high-speed flying and clever race tactics (like overtaking and blocking) on their own. Even better, this “learn by competing” approach worked well in real-life tests, not just in computer simulations.
What questions did the researchers ask?
The team wanted to know:
- Can drones learn to race well by simply trying to win, without being told exactly how to move at every moment?
- Does training with an opponent (multi-agent competition) make drones better at flying fast and handling tricky situations, like obstacles?
- Do these learned skills work outside the simulator—on real drones in the real world?
- Do drones trained this way adapt to racing against new opponents they haven’t seen before?
How did they do it? Methods and key ideas
Think of teaching a player in a racing game:
- A common way is to give the player points constantly for “good behavior,” like staying close to the center of the track. This is called a dense reward.
- The new approach gives points only when the player passes a gate first or finishes the lap before the opponent. This is called a sparse reward.
Here’s how they trained the drones:
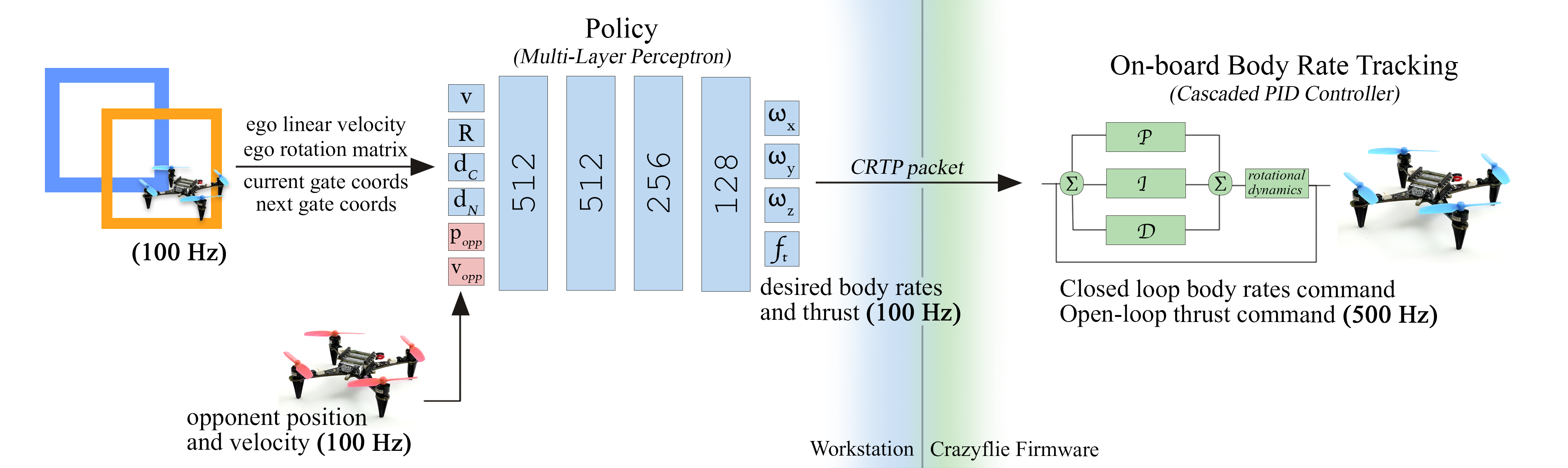
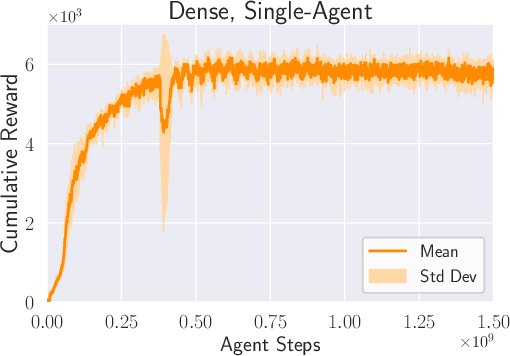
- Two AI agents raced head-to-head in a simulator (Isaac Sim). The only goal: beat the other drone. No extra points for “fly smoothly” or “follow the perfect line.”
- The AI controlled simple commands: how much upward thrust to use and how fast to rotate (roll, pitch, yaw). You can think of this as “how hard to press the gas” and “how much to tilt or turn.”
- A built-in controller on the drone handled the fine details of making those body rotations happen (like cruise control for turning).
- The drones “saw” information like their speed, orientation, where the next gates are, and where the opponent is.
- They used a popular training method from reinforcement learning (a way for AIs to learn from trial and error). Specifically, a multi-agent version of PPO, called IPPO.
- To make the skills transfer to real drones, they added “randomness” during training (slight changes to physics and conditions). This makes the AI more robust to small differences between simulation and reality.
What did they find? Main results and why they matter
The main discoveries:
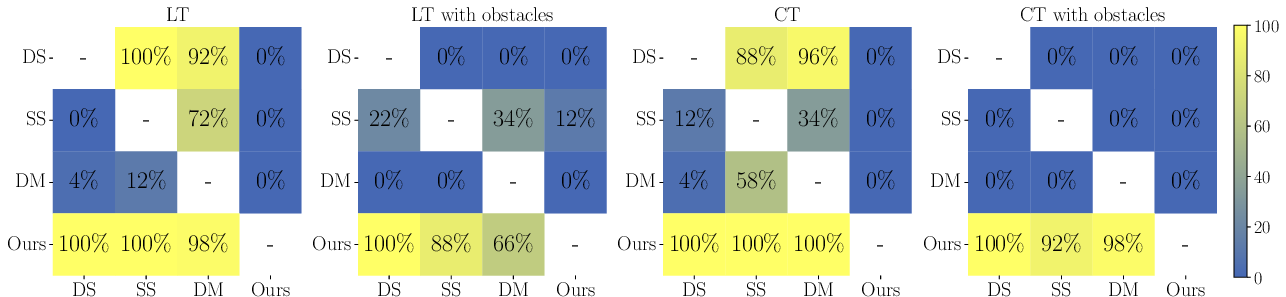
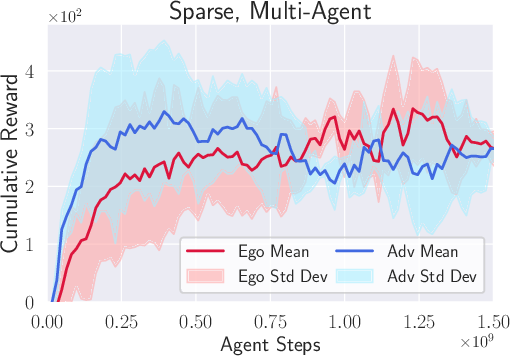
- Racing skills and strategies emerge naturally. Even with just the “win the race” reward, drones learned to fly fast, overtake, block, and avoid collisions—without being told to do these things.
- This approach beat the more traditional method (dense rewards that reward constant progress along the track), especially on complex tracks with obstacles. Dense rewards often got stuck: the drone tried too hard to stay on a straight line to the next gate and failed when obstacles required detours.
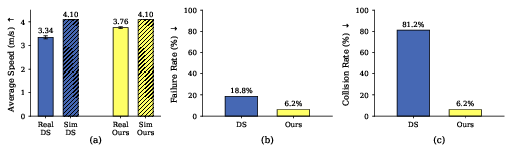
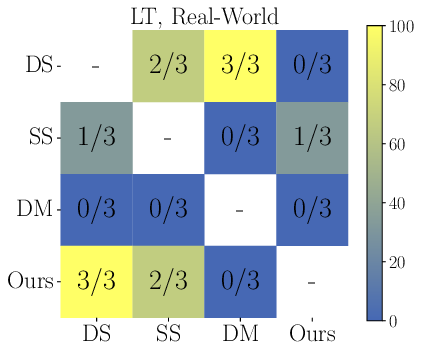
- Better transfer to real-world drones. Policies trained by competition in the simulator flew closer to their simulated speeds and had fewer crashes in real races, compared to the dense reward method. In short: sim-to-real worked better.
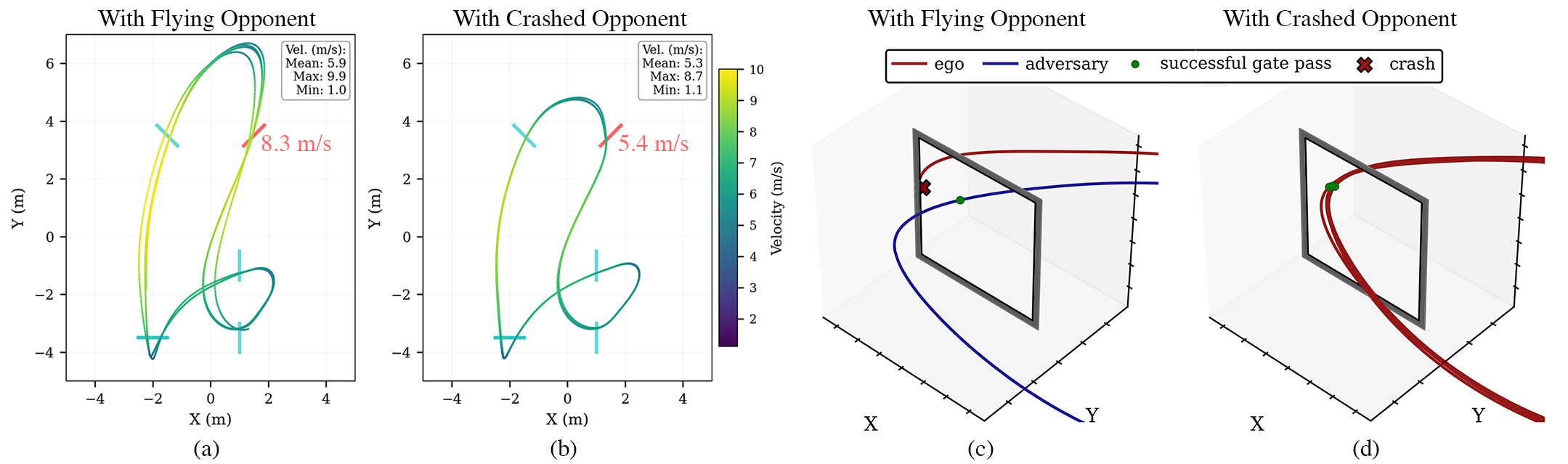
- Generalization to new opponents. The drones trained by competition handled rivals they hadn’t seen during training fairly well.
- In head-to-head races:
- The competitive, sparse-reward method won most races in simulation, including 100% wins on one track against the dense-reward baseline and 84% on another track.
- In real-world tests, the competitive method matched or beat other methods and handled obstacle tracks more reliably.
A simple takeaway: giving the drones the high-level goal of “win the race” was enough to make them both fast and smart.
Why it matters: implications and impact
- It suggests a shift in how we design AI for physical robots: instead of hand-crafting detailed instructions and rewards for every behavior, we can set a clear task-level goal and let smart strategies emerge.
- This can make robots more adaptable and effective in messy, real-world situations where strict rules don’t always work (like racing with obstacles or against unpredictable opponents).
- Beyond drones, the idea applies to other competitive or interactive tasks—self-driving cars, robot sports, or multi-robot teamwork—where high-level goals and interaction can lead to smarter behaviors.
- It also hints that competitive training can improve the “sim-to-real” gap, making it faster and cheaper to develop robotics systems that work outside the lab.
In short, the research shows that competition plus simple goals can teach robots to be both fast and tactical—no step-by-step instructions required.
Knowledge Gaps
Below is a focused list of the paper’s unresolved knowledge gaps, limitations, and open questions. Each item pinpoints a concrete direction for future research.
- Reliance on motion capture: Policies assume accurate, high-rate global pose (ego and opponent) from Vicon; it remains unknown how the approach performs with onboard sensing (vision, IMU, GNSS) under noisy, partial observability and occlusions.
- Opponent observability: The agent receives opponent position/velocity directly; evaluate performance when opponent state must be estimated onboard (e.g., through vision or UWB) with delays, noise, and intermittent visibility.
- Track generalization: Policies are trained and evaluated on the same (or similar) tracks; assess zero-shot generalization to unseen geometries, gate sizes, gate orientations, and arena dimensions, including outdoor environments.
- Dynamic elements: Obstacles are static; test against moving obstacles (e.g., swinging gates), dynamic clutter, and multiple non-cooperative agents to probe strategy and safety under nonstationary environments.
- Number of agents: Only two-agent races are studied; analyze scalability to fields of 3–8 drones, including emergent behaviors, training stability, collision risk, and computational demands.
- Population diversity: Self-play uses a single pair of agents; evaluate population-based training or league methods (e.g., PSRO) to increase opponent diversity and robustness to unseen strategies.
- Domain randomization: The paper hypothesizes “adversarial domain randomization” effects but does not test them; perform ablations of randomization types/ranges (dynamics, delays, sensing noise, aerodynamics) to quantify what drives sim-to-real transfer.
- Real-world sample size and statistics: Real-world evaluation uses very few races (three per matchup); expand trials, report confidence intervals, and conduct statistical tests to substantiate claims on win rates and transfer.
- Safety and collision handling: No explicit penalty for contact with an opponent (only ground/out-of-bounds crashes); study safety-constrained rewards or rule-based constraints to reduce dangerous blocking/ramming while preserving competitiveness.
- Energy and actuation regularization: Energy term penalizes body rates but not thrust; explore alternative regularizers (thrust penalties, jerk/acceleration smoothing) and their impact on speed, safety, and transfer.
- Action interface: Thrust is sent as open-loop motor commands while body rates use PID; evaluate closed-loop thrust/altitude control and different low-level controllers (e.g., nonlinear, adaptive) for robustness and consistency across platforms.
- PID gain sensitivity: Fixed low-level PID gains are assumed; quantify sensitivity of emergent behaviors and transfer to gains, and investigate auto-tuning or learning low-level controllers jointly.
- Centralized vs. decentralized critics: IPPO with independent critics is used; compare against MAPPO (shared critic), MADDPG, QMIX, and opponent-modeling approaches to assess learning speed, stability, and emergent strategies.
- Latency and communication: Radio/CRTP latency, packet loss, and bandwidth limits are not modeled; simulate and test real communication constraints to evaluate resilience and strategic adaptation under delays.
- Aerodynamics and physics fidelity: The simulation includes a simple drag model; perform ablations that add ground effect, prop wash, motor saturation/nonlinearity, battery sag, and wind to isolate contributors to sim-to-real gaps.
- Strategy robustness to erratic opponents: The paper notes failures against poorly transferring baselines (DM); design stress tests with adversarial/erratic opponents and measure robustness, recovery behaviors, and collision rates.
- Online adaptation: Authors suggest test-time adaptation could help but do not implement it; evaluate meta-RL, system identification, or few-shot adaptation for rapid adjustment to new opponents and conditions.
- Metrics beyond win rate: Current evaluation emphasizes win rate; add fairness (e.g., collision-inducing maneuvers), overtaking counts, pass success rates, minimum separation distances, path efficiency, and safety margins.
- Human comparison: No evaluation against human pilots; benchmark emergent strategies and agility against skilled humans to assess competitiveness and safety.
- Track information assumptions: Policies use gate corner positions in body frame; investigate performance when gate geometry is unknown and must be perceived/estimated online (e.g., AprilTags, visual detection).
- Generalization across hardware: Only a micro-quad (Crazyflie-class) is tested; validate on larger platforms with different inertia, propulsion, and sensor stacks, including outdoor racing drones.
- Training stability and curricula: Multi-agent training shows variability; examine curricula (progressive track complexity), reward annealing, and opponent sampling strategies to improve stability and reduce catastrophic phases.
- Reward sensitivity: No systematic reward-weight ablations are reported (e.g., pass bonuses, lap bonuses, crash penalties, energy weights); conduct sensitivity analyses to identify robust configurations and trade-offs.
- Ethical/rule compliance: Emergent blocking can increase collision risk; explore rule-constrained RL that enforces race regulations (e.g., no intentional contact) while maintaining competitive performance.
- Wind and environmental disturbances: Not modeled or tested; evaluate robustness to wind gusts, temperature, and lighting changes (for vision) that commonly affect real racing.
- Compute and deployment: Onboard compute and autonomy constraints (policy inference latency, power, thermal) are not discussed; assess end-to-end, fully onboard pipelines without mocap and offboard compute.
Practical Applications
Immediate Applications
The following applications can be deployed with modest adaptation in controlled environments similar to the paper’s setup (indoor track, motion-capture state estimation, small quadrotors, Isaac Sim-based training).
- Opponent-aware autonomous drone racing agents (robotics, sports/entertainment)
- Use learned multi-agent, sparse-reward policies as competitive opponents or pace-setters in indoor drone racing leagues and demonstrations.
- Tools/products/workflows: “Opponent zoo” of trained agents; head-to-head race management; analytics on win rate, lap times, collision risk; race-strategy tutors for human FPV pilots.
- Assumptions/dependencies: Accurate, low-latency state estimation (e.g., Vicon >100 Hz); similar dynamics to training (Crazyflie-class platforms); safety netting/kill switches; controlled tracks.
- Benchmarking suite for embodied multi-agent RL (academia, software)
- Adopt the released code and training pipeline (Isaac Sim + IPPO + domain randomization) as a standard benchmark for emergent tactics in physically realistic settings.
- Tools/products/workflows: Reproducible training recipes (sparse competitive rewards); standardized metrics (speed gap sim-to-real, failure/collision rates); environment packs (tracks with/without obstacles).
- Assumptions/dependencies: GPU compute for training; Isaac Sim/Isaac Lab stack; policy evaluation harness.
- Curriculum modules for teaching sparse-reward, multi-agent RL on real robots (education/academia)
- Course labs demonstrating how winner-take-all rewards induce agile, low-level control and tactics (overtaking/blocking) without dense shaping.
- Tools/products/workflows: Stepwise labs from simulation to zero-shot deployment; safety and evaluation checklists.
- Assumptions/dependencies: Access to motion capture or equivalent precise tracking; small indoor arena; instructor oversight for safety.
- Stress testing of multi-robot interaction policies in constrained spaces (robotics/logistics)
- Use competitive self-play to generate adversarial agents that pressure-test existing collision-avoidance or throughput algorithms in warehouses/testbeds.
- Tools/products/workflows: Adversary generation for edge-case discovery; logs of near-miss/collision scenarios; regression tests.
- Assumptions/dependencies: Indoor, well-instrumented test areas; compatibility with existing robots’ low-level PID loops; safety supervision.
- Sim-to-real validation harness for agile control (aerospace/QA, standards)
- Adopt the paper’s evaluation protocol (speed-transfer gap, failure/collision rates) to compare controllers and randomization strategies before field trials.
- Tools/products/workflows: SIL/HIL pipelines; dashboards tracking sim-real gaps per track/condition; acceptance criteria for deployment.
- Assumptions/dependencies: Comparable simulation fidelity and randomization; consistent hardware between sim and real tests.
- AI rivals and training partners for FPV pilots (sports/entertainment, daily life)
- Provide adaptable AI opponents in simulators and small indoor arenas to help human pilots practice overtaking, blocking, and risk management.
- Tools/products/workflows: Difficulty scaling via opponent selection; “race coaching” hints derived from agent behavior; mixed human-vs-AI events.
- Assumptions/dependencies: Safety protocols for shared airspace; calibration of agent aggressiveness for human comfort and safety.
- Early-stage counterfactual behavior analysis tools (academia/industry)
- Analyze emergent agent strategies (e.g., risk-averse slowdown after opponent crash) to inform meta-controllers, race strategy planners, or safety supervisors.
- Tools/products/workflows: Trajectory/velocity profiling; scenario labeling (competitive vs non-competitive opponent); explainability dashboards.
- Assumptions/dependencies: Rich telemetry; well-defined task events (gate passes, crashes).
Long-Term Applications
These require further research and engineering to remove motion-capture reliance, scale to new domains, or satisfy safety/regulatory constraints.
- Vision-based, onboard opponent-aware flight (robotics, autonomy)
- Replace motion capture with onboard cameras/IMU and active perception policies that learn to track gates/opponents and plan tactically at high speed.
- Tools/products/workflows: End-to-end visuomotor policies; active perception curricula; online adaptation.
- Assumptions/dependencies: High-rate, low-latency perception; powerful edge compute; robust state estimation in clutter and poor lighting.
- Multi-UAV deconfliction and airspace management via learned tactics (UTM/aviation, public safety)
- Train self-play agents to resolve conflicts (merges, crossings) with emergent behaviors that balance aggression and safety in dense traffic.
- Tools/products/workflows: Agent pools spanning compliance styles; scenario generators; safety constraint layers (e.g., control barrier functions).
- Assumptions/dependencies: Formal safety envelopes; verifiability/assurance for emergent policies; integration with UTM protocols.
- Counter-UAS interception, herding, and denial maneuvers (defense/public safety)
- Exploit learned overtaking/blocking to steer or contain non-cooperative drones with minimal collisions.
- Tools/products/workflows: Multi-agent intercept simulators; risk-managed engagement policies; human-on-the-loop oversight.
- Assumptions/dependencies: Legal/ethical constraints; robust perception/identification; safe kinetic/non-kinetic effectors.
- Tactical deconfliction for delivery drones in dynamic environments (logistics, smart cities)
- Apply competitive training to learn right-of-way negotiation, occlusion handling, and obstacle-rich routing in urban canyons.
- Tools/products/workflows: City-scale simulators; mixed cooperative–competitive training; multi-objective optimization (safety, ETA, energy).
- Assumptions/dependencies: Reliable mapping and comms; certification standards for AI-driven deconfliction.
- Multi-agent tactical driving (automotive)
- Use sparse, outcome-based multi-agent training to acquire overtaking, merging, and blocking strategies that complement rule-based planners in autonomous racing or complex traffic.
- Tools/products/workflows: Self-play racing/traffic environments; safety shields; sim-to-real validation suites.
- Assumptions/dependencies: Strong guarantees for road safety/legal compliance; domain shift mitigation from race-like to traffic scenarios.
- Resource contention and routing in mobile robot fleets (industrial automation)
- Learn emergent norms (yielding, blocking, slotting) for shared aisles, narrow passages, or docking stations.
- Tools/products/workflows: Warehouse-scale multi-agent simulators; throughput vs collision trade-off tuning; policy deployment frameworks.
- Assumptions/dependencies: Interoperability with existing fleet managers; safety governance.
- Rapid opponent adaptation and robustification (software, robotics, gaming)
- Add meta-learning/domain randomization adversaries so policies adapt to unseen behaviors and reduce brittleness observed with out-of-distribution opponents.
- Tools/products/workflows: “Opponent zoo” covering diverse priors; test-time adaptation; distribution shift monitors.
- Assumptions/dependencies: Onboard learning or fast update pathways; safeguards against catastrophic adaptation.
- Assurance and certification frameworks for emergent controllers (policy/regulation, insurance)
- Develop evaluation standards and safety cases for sparse-reward, multi-agent policies operating in shared spaces.
- Tools/products/workflows: Formal verification where feasible; scenario coverage metrics; incident replay/forensics.
- Assumptions/dependencies: Regulator–industry collaboration; interpretable risk metrics acceptable to insurers.
- Standardized embodied multi-agent RL benchmarks (academia/consortia)
- Extend beyond drone racing to manipulation, legged locomotion, and heterogeneous teams to study emergent cooperation/competition with sim-to-real metrics.
- Tools/products/workflows: Open tracks/tasks; common reward templates; leaderboards emphasizing transfer and safety.
- Assumptions/dependencies: Community adoption; cross-hardware comparability.
- Human-in-the-loop co-training and coaching (sports training, HRI)
- Mixed self-play vs human pilots/drivers to tailor difficulty and provide tactical feedback; personalized training regimens.
- Tools/products/workflows: Skill assessment models; adaptive opponent selection; explainable strategy hints.
- Assumptions/dependencies: Usability and safety for non-experts; calibrated agent aggression.
- Search-and-rescue and emergency response in clutter (public safety, robotics)
- Learn risk-aware agility to maneuver around dynamic obstacles (falling debris, moving responders) while prioritizing task completion.
- Tools/products/workflows: Disaster scenario generators; hierarchical objectives (survivor reach time, safety margins).
- Assumptions/dependencies: Robust perception and comms in adverse conditions; strict safety bounds.
- Edge autopilots for learned high-rate control (hardware)
- Embed 100–500 Hz learned controllers on lightweight boards with integrated safety PIDs and supervisory logic.
- Tools/products/workflows: Real-time neural inference stacks; fallback controllers; health monitoring.
- Assumptions/dependencies: Deterministic low-latency compute; certifiable software/hardware stack.
Notes on feasibility across applications:
- The paper’s strongest results rely on indoor motion capture, small drones, and controlled tracks; removing these constraints requires advances in onboard perception and safety assurance.
- Policy robustness depends on the opponent distribution; “opponent zoo” coverage and adaptation mechanisms are key to avoid brittleness.
- Multi-agent training exhibits higher variance; reproducibility and monitoring (e.g., curriculum, seeding, evaluation at scale) are important for stable deployment.
- Safety layers (e.g., control barrier functions, collision cones, geofencing) are recommended when deploying emergent controllers in shared or human-populated spaces.
Glossary
- Aerodynamic effects: Forces and torques generated by airflow that oppose motion, modeled to capture drag on the quadrotor. "we model aerodynamic effects as forces and torques proportional to the translational and angular velocities"
- Adversarial domain randomization: A training strategy that purposefully selects challenging environment variations to improve robustness and transfer. "We believe this improved sim-to-real transfer to be related to adversarial domain randomization~\cite{khirodkar2018adversarial}"
- Agile flight: High-speed, aggressive maneuvering that pushes a drone to its physical limits. "agile flight (e.g., high-speed motion pushing the platform to its physical limits)"
- Body frame: The coordinate frame fixed to the drone’s body used to express velocities and positions relative to the vehicle. "the linear velocity of the drone expressed in body frame"
- Body rates: Angular velocity components (roll, pitch, yaw) of the drone’s body. "Body rates are tracked via on-board rate PID"
- Blocking maneuver: An opponent-aware tactic where a leading drone obstructs the follower’s optimal path to maintain advantage. "Blocking maneuvers are another indicator of rich opponent-aware strategies emerging from sparse competitive multi-agent rewards."
- Cascaded control architecture: A layered control design with high-level setpoint generation and low-level tracking loops. "Our quadrotor simulation, implemented in Isaac Sim~\cite{mittal2023orbit}, models a cascaded control architecture."
- Crazy Real-Time Protocol (CRTP): A communication protocol used to send control commands to Crazyflie drones. "which is then sent to the drone via Crazy Real-Time Protocol (CRTP) at 100 Hz."
- Critic (network): The value function estimator that evaluates the expected return given states or state-action pairs. "For simplicity, we use separate critic networks for the two agents."
- Decentralized Markov Decision Process (Dec-MDP): A Markov decision process where multiple agents make decisions without centralized coordination. "two-agent, finite horizon decentralized Markov decision process (Dec-MDP)."
- Dense progress-based reward: A frequently updated reward that encourages moving toward the next gate or along a predefined line. "dense progress-based rewards such as progress on the segment connecting two consecutive gates"
- Discount factor: A scalar γ that weighs future rewards relative to immediate rewards in RL. "The discount factor is denoted by ."
- Domain randomization: Training-time randomization of simulation parameters to enhance robustness to real-world variations. "relying on domain randomization during training and rapid adaptation at test time."
- Ego (agent): The primary agent of interest whose performance is evaluated against an adversarial opponent. "referred in the following as the ego and adversary."
- Emergent behaviors: Complex strategies or skills that arise naturally from simple objectives without explicit instruction. "rich behaviors emerge from simple task-level competitive rewards."
- First-order motor model: A motor dynamics approximation where motor speed responds exponentially to commands with a single time constant. "We model the motor dynamics with a first-order model governed by the motor constant :"
- Finite-horizon objective: An optimization target over a fixed number of time steps. "maximize the following discrete-time finite-horizon objective:"
- General-sum game: A game-theoretic setting where agents’ payoffs are not strictly zero-sum and can vary independently. "We define drone racing as a multi-agent general-sum game"
- Inertia matrix: The matrix describing a rigid body’s resistance to angular acceleration about its principal axes. "after scaling by the inertia matrix :"
- IPPO (Independent Proximal Policy Optimization): A multi-agent RL algorithm where each agent is trained independently using PPO-style updates. "using IPPO~\cite{yu2022surprising}, a multi-agent variant of PPO~\cite{schulman2017proximal}."
- Isaac Sim: NVIDIA’s robotics simulation platform used to build and run physically realistic environments. "For the simulation, we employed Isaac Lab v2.2.0 and Isaac Sim v4.5.0 \cite{mittal2023orbit}"
- Lemniscate track: A figure-eight style racing track used for training and evaluation. "the lemniscate track measures "
- MAPPO (Multi-Agent PPO): A centralized-training variant of PPO for multi-agent settings that can use shared critics. "Unlike MAPPO, IPPO does not employ a shared critic"
- Model Predictive Control (MPC): A trajectory optimization-based control method that solves optimal control problems online over a receding horizon. "Model Predictive Control (MPC) and its variants are by far the most widely adopted."
- Model Predictive Contouring Control (MPCC): An MPC variant that optimizes path-following by penalizing contouring and lag errors relative to a reference. "Model Predictive Contouring Control (MPCC) methods~\cite{romero2021model, romero2022replanningRAL} perform online adaptation of the path, velocities, and accelerations"
- Overtaking reward: A reward term added to encourage passing the opponent in multi-agent racing setups. "complements the progress reward with the dense overtaking reward"
- PID control law: A proportional–integral–derivative controller used to track desired angular rates via torque commands. "converted to desired torques via a PID control law"
- Privileged input: Additional state information available to the critic (but not necessarily to the actor) to improve value estimation. "Each critic receives privileged input in the form of the concatenated joint state"
- Proximal Policy Optimization (PPO): A policy gradient algorithm that stabilizes updates via clipped objectives or trust-region-like constraints. "a multi-agent variant of PPO"
- Rigid body: An object whose shape does not deform under applied forces, used to model the quadrotor’s physical body. "which is modeled as a rigid body."
- Sim-to-real transfer: The process of deploying policies trained in simulation directly to real-world hardware with minimal adaptation. "In addition to improved sim-to-real transfer, the multi-agent policies also exhibit some degree of generalization"
- Split-S maneuver: An aerobatic maneuver involving a half-roll followed by a descending half-loop to reverse direction. "including a split-S maneuver"
- Surrogate objective: The auxiliary loss used in PPO-based algorithms to approximate and stabilize the true policy improvement objective. "the surrogate objective is computed as the average of the individual agents' surrogate losses."
- Thrust coefficient: A parameter relating motor speed squared to generated thrust. "using the thrust coefficient "
- Thrust-to-weight ratio: The ratio of a vehicle’s maximum thrust to its weight, indicating available acceleration and agility. "high thrust-to-weight ratio (slightly greater than~3)"
- Thrust-to-wrench static mapping: The linear mapping that converts individual rotor thrusts into the net force and torque (wrench) on the body. "inverse of the thrust-to-wrench static mapping"
- Vicon motion capture system: A high-precision optical tracking system that provides ground-truth poses at high frequency. "receives ego-centric and opponent state estimates at 100 Hz from the Vicon motion capture system."
- Wrench: The combined force and torque applied to a rigid body. "the actual forces and wrench applied to the body"
- Zero-shot transfer: Deploying a trained policy in a new setting (e.g., the real world) without additional fine-tuning. "deploy them zero-shot to the real world."
Collections
Sign up for free to add this paper to one or more collections.