V-RGBX: Video Editing with Accurate Controls over Intrinsic Properties
Abstract: Large-scale video generation models have shown remarkable potential in modeling photorealistic appearance and lighting interactions in real-world scenes. However, a closed-loop framework that jointly understands intrinsic scene properties (e.g., albedo, normal, material, and irradiance), leverages them for video synthesis, and supports editable intrinsic representations remains unexplored. We present V-RGBX, the first end-to-end framework for intrinsic-aware video editing. V-RGBX unifies three key capabilities: (1) video inverse rendering into intrinsic channels, (2) photorealistic video synthesis from these intrinsic representations, and (3) keyframe-based video editing conditioned on intrinsic channels. At the core of V-RGBX is an interleaved conditioning mechanism that enables intuitive, physically grounded video editing through user-selected keyframes, supporting flexible manipulation of any intrinsic modality. Extensive qualitative and quantitative results show that V-RGBX produces temporally consistent, photorealistic videos while propagating keyframe edits across sequences in a physically plausible manner. We demonstrate its effectiveness in diverse applications, including object appearance editing and scene-level relighting, surpassing the performance of prior methods.








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces V‑RGBX, a new way to edit videos by directly controlling the “hidden ingredients” that make a scene look real—things like the object’s true color, the light in the room, how shiny a surface is, and the direction surfaces face. Instead of only painting over pixels, V‑RGBX understands and edits the physical parts of a scene, so changes look natural and stay consistent across the whole video.
What questions does it try to answer?
The researchers focus on three simple questions:
- How can we take a normal video and pull it apart into meaningful layers, like base color, lighting, and material?
- Can we rebuild a realistic video from those layers?
- If we edit just one frame (a keyframe), can we spread that edit—like changing a shirt’s fabric or the room’s lighting—across the entire video smoothly and accurately?
How did the researchers do it?
Think of a video as a cake. A normal video shows the cake fully baked. V‑RGBX learns to:
- Separate the cake into ingredients (layers)
- Albedo: the object’s paint-underneath color (no shadows or shine).
- Normal: which way each tiny patch of the surface faces; this affects how light hits it.
- Material: what the surface is like—rough, shiny, metallic, etc.
- Irradiance: the light falling on the scene (brightness and color from the environment).
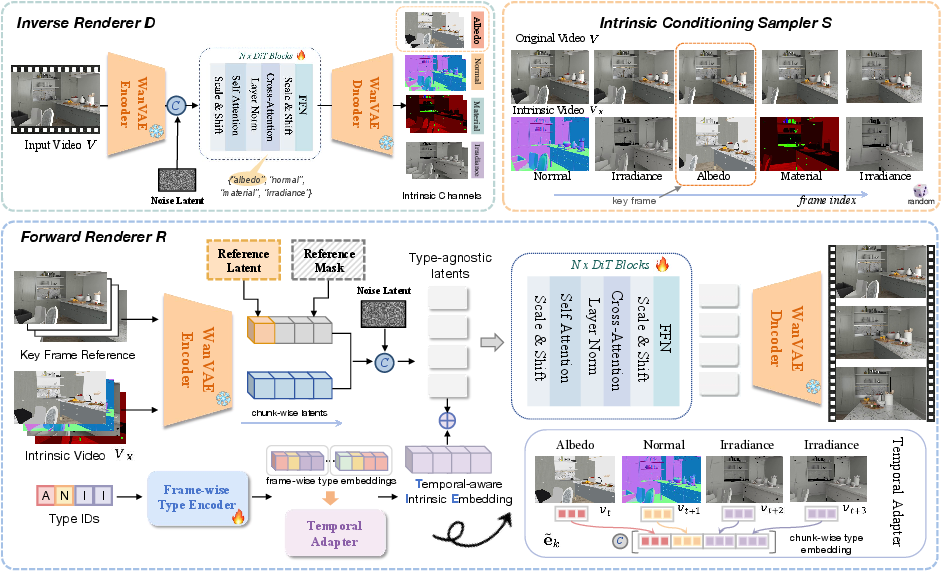
This “pulling apart” step is called inverse rendering (RGB→X): from the final picture, figure out the ingredients.
- Let you edit a keyframe
- You change one frame—maybe repaint a couch, make a floor shinier, or warm up the room lighting.
- The system figures out which ingredient(s) you changed (color? material? lighting?).
- Mix edited and original layers smartly
- Instead of feeding all layers for every frame (which can be heavy and conflicting after edits), they “take turns” using different layers across frames in a controlled sequence. This is called interleaved conditioning—imagine each layer stepping in like players in a relay race.
- The model also attaches a clear label to each frame’s layer (a “type tag”) so it never confuses, say, lighting with color.
- Rebuild the video from layers
- The forward rendering step (X→RGB) puts the ingredients back together into a photorealistic video.
- It uses your edited keyframe as a reference to guide the style and look, so the edit spreads over time consistently without flicker or drift.
In short:
- Break video into layers → edit a keyframe → interleave and label the layers → rebuild a high‑quality edited video.
What did they find, and why is it important?
The team shows that V‑RGBX:
- Keeps edits consistent over time: If you change the fabric of a chair or the color of the lighting in one frame, the change sticks properly across all frames without weird changes popping up later.
- Edits the right thing: Changing lighting doesn’t accidentally repaint objects, and changing texture doesn’t mess up shadows.
- Looks realistic: The rebuilt videos are sharp, stable, and physically believable.
- Beats previous methods: Compared to earlier tools that edit appearance only, V‑RGBX better preserves the physical properties and reduces problems like flickering, drifting colors, or unintended new objects appearing.
Why this matters:
- It gives creators precise control: you can retexture objects, relight a scene, or tweak materials across an entire video with less manual work.
- It’s more predictable: since the model understands the “why” behind what you see (light, color, materials), changes behave more like the real world.
What could this change in the future?
This approach could make video editing tools much smarter and faster for:
- Filmmakers: relight a scene after shooting without reshooting.
- Designers and advertisers: change product materials or colors consistently across shots.
- Game and AR/VR creators: keep scenes physically consistent while experimenting with looks.
The authors note some limits: the model was trained mostly on indoor scenes, so outdoor scenes may be harder; it currently samples one “ingredient” per frame in the conditioning step; and it relies on a large video model that can be heavy to run. Future work could handle longer videos, more complex edits at once, and broader environments.
Overall, V‑RGBX is a big step toward video editors that understand the physics of what they’re changing—so your edits look not just different, but right.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of gaps and open questions that remain unresolved, focusing on what is missing, uncertain, or left unexplored and framed to be actionable for future research:
- Dataset and domain generalization:
- The model is trained primarily on synthetic indoor Evermotion scenes; generalization to outdoor environments, diverse real-world lighting, and varied materials is untested. Establish benchmarks and training protocols on real, outdoor, HDR videos with complex illumination.
- No domain adaptation strategies (e.g., self-supervision, cycle-consistency, style transfer) are explored to bridge synthetic-to-real gaps.
- Intrinsic representation fidelity and physical grounding:
- The definition, dynamic range, and physical calibration of the “irradiance” channel are under-specified (e.g., SDR vs HDR, absolute units). Evaluate whether irradiance predictions are physically meaningful (energy conservation, consistent shading) and explore HDR training/inference.
- The pipeline uses a generative forward renderer instead of physically composing albedo/irradiance/material/normal; quantify physical plausibility (e.g., shadow accuracy, specular/reflection behavior, interreflections) and consider hybrid or differentiable rendering baselines.
- Albedo scaling ambiguity is mitigated for metrics via per-channel scaling, but edit-time color constancy and global scale consistency across frames remain unaddressed; propose calibration/normalization schemes.
- Material channel evaluation and metrics:
- Quantitative evaluation for the material channel (roughness, metallic, AO) is missing. Define metrics and datasets for supervised/weakly supervised material estimation and assess disentanglement quality for material edits.
- Depth and geometry conditioning:
- Depth is mentioned conceptually but not included in the inverse renderer or conditioning in experiments. Investigate adding depth (and camera extrinsics/intrinsics) for occlusion handling, view-dependent effects, and geometry-aware edit propagation.
- Interleaving and conditioning design:
- The intrinsic conditioning samples exactly one modality per frame. This limits multi-attribute edits and could introduce modality-switching artifacts. Study multi-modality-per-frame conditioning (stacking, learned fusion/gating, dynamic routing) and quantify memory/quality trade-offs.
- The formal specification of the sampling function is incomplete (“Formally, v_tx = …” is left blank). Provide the exact algorithm for conflict detection, sampling schedule, randomness seeds, and handling of multiple edited modalities.
- Memory-efficiency claims versus “empty tokens” in baselines are not quantified. Profile memory/latency across conditioning strategies and number of modalities.
- Keyframe editing workflow:
- Automatic detection of which intrinsic modalities changed in edited keyframes relies on external inverse rendering tools but is unspecified and potentially brittle. Develop robust modality-change detection with confidence scores and error handling.
- Evaluation primarily uses a single first-frame keyframe; multi-keyframe scenarios (distributed in time, conflicting edits) are not studied. Explore strategies for edit scheduling, conflict resolution, and temporal alignment of multiple keyframes.
- Masked/region-level editing and instance-aware propagation are not evaluated. Add segmentation-guided intrinsic editing to constrain edits spatially and preserve untouched regions more reliably.
- Temporal coherence and long-range propagation:
- The backbone compresses every 4 frames into a chunk, potentially limiting fine-grained temporal resolution. Study chunk size effects and alternative temporal models (e.g., recurrent/streaming DiTs, long-context transformers) for minute-scale propagation.
- VBench Smoothness is the primary temporal metric. Introduce intrinsic-aware temporal metrics (e.g., flicker in albedo/irradiance, drift in normals/material) and edit-consistency measures across frames.
- Occlusion/disocclusion handling (surfaces becoming visible/hidden) is not analyzed. Investigate persistence mechanisms for edits through occlusions.
- Robustness to challenging phenomena:
- Performance under specular/anisotropic materials, glossy reflections, transparency/translucency, participating media, complex cast shadows, rapid motion, motion blur, and dynamic lighting changes is not evaluated. Create stress-test suites and failure analyses for these cases.
- Disentanglement guarantees:
- Quantitative evidence that editing one intrinsic (e.g., albedo) leaves others unchanged across time is limited to qualitative claims. Define disentanglement metrics (e.g., change in non-edited channels under targeted edits) and test cross-modal leakage.
- Reference conditioning and guidance:
- Classifier-free guidance is applied only to the reference branch, with a fixed scale (s=1.5). Explore joint guidance over intrinsic channels, adaptive guidance scheduling, and analyses on fidelity–edit-consistency trade-offs.
- Backbone dependency and scalability:
- The approach heavily relies on WAN 2.1 (T2V-1.3B). Assess portability to other video backbones, effects of model size, and scalability in video length. Consider efficient architectures for real-time or interactive editing.
- Inference speed and latency are not reported. Provide throughput benchmarks and investigate model compression/distillation for interactive workflows.
- Baseline comparability:
- Comparisons to DiffusionRenderer require environment maps and use estimates from the first frame, which may be suboptimal. Establish matched baselines with comparable lighting inputs or unified protocols to ensure fairness.
- Explainability and diagnostics:
- There is no analysis of how each intrinsic modality contributes to the final RGB output (e.g., attribution, sensitivity analysis). Develop interpretability tools to understand failure modes and increase user trust.
- Reproducibility and release:
- Code, trained models, and datasets are not explicitly stated as released (website is mentioned). Provide full training/evaluation pipelines, data splits, and pre/post-processing details to enable replication.
Practical Applications
Immediate Applications
Below is a concise list of practical, deployable use cases that build directly on the paper’s methods and findings. Each item notes the target sector, potential tools/workflows, and feasibility assumptions or dependencies.
- Bold scene relighting in post-production
- Sector: media and entertainment, advertising
- What: Relight entire sequences from a single edited keyframe without breaking temporal consistency (e.g., adjust light color, soften shadows, match brand lighting across shots).
- Tools/Workflows: “Intrinsic Relight” plugin for Adobe After Effects/Premiere; workflow = RGB→X decomposition → keyframe edit → interleaved intrinsic conditioning → forward render → creative review.
- Assumptions/Dependencies: Works best on indoor scenes similar to training domain; requires GPU-backed inference; high-quality inverse rendering for accurate irradiance; licensing/access to the Wan VAE/DiT backbone and model weights.
- Material and texture changes on moving objects
- Sector: e-commerce, product videography, social media content creation
- What: Swap or retune material attributes (roughness, metallic, albedo) for products/furniture across a video (e.g., try finishes for a lamp across a room walkthrough).
- Tools/Workflows: “MaterialSwap” video editor extension; in-app material sliders mapped to intrinsic channels; per-keyframe edits with automatic propagation.
- Assumptions/Dependencies: Clean object visibility; stable camera motion improves propagation; indoor lighting common; edits need reasonable segmentation/keyframe preparation.
- Consistent removal or adjustment of shadows and lighting artifacts
- Sector: professional photography/video retouching, marketing
- What: Reduce harsh shadows or normalize uneven lighting in multi-shot campaigns while preserving texture and geometry.
- Tools/Workflows: Intrinsic-aware shadow control panel; batch-processing pipeline for multi-clip campaigns; quality control via side-by-side LPIPS/SSIM metrics.
- Assumptions/Dependencies: Reliable irradiance estimation; editor’s intent correctly mapped to intrinsic channels; sufficient compute for multiple clips.
- Intrinsic-aware object insertion and compositing
- Sector: VFX, virtual production, AR prototyping
- What: Insert assets whose materials and lighting match the host scene; use normals and irradiance for physically plausible integration.
- Tools/Workflows: “Geometry-Aware Insert” compositing module bridging 3D assets and V-RGBX; X→RGB forward renderer aligns appearance to scene intrinsics.
- Assumptions/Dependencies: Accurate host-scene normals/irradiance; asset material parameters known or estimated; resolution constraints (e.g., 832×480) may require upscaling or super-resolution.
- Brand color compliance across video campaigns
- Sector: marketing/branding, enterprise creative ops
- What: Enforce brand-albedo across scenes (e.g., clothing or packaging color consistency) without altering lighting aesthetics.
- Tools/Workflows: Albedo validation dashboard; automated albedo correction via keyframe-driven propagation; QA metrics (PSNR/SSIM checks).
- Assumptions/Dependencies: Robust albedo separation; careful color management (display profiles); legal compliance workflows for disclosure.
- Education and training for graphics/vision
- Sector: academia, EdTech
- What: Demonstrate intrinsic decomposition in class (albedo vs. shading vs. normals), and show physically grounded edits on real videos.
- Tools/Workflows: Teaching notebooks with RGB→X and X→RGB demos; model-in-the-loop labs; interactive assignments on temporal propagation.
- Assumptions/Dependencies: Access to trained weights; classroom GPUs or cloud credits; curated indoor video samples.
- Batch relighting and material A/B testing for real estate and interior design videos
- Sector: real estate, architectural visualization
- What: Preview different lighting moods or material finishes in walkthroughs (e.g., floor texture and light warmth).
- Tools/Workflows: “Virtual Staging Video” pipeline: decompress → keyframe edits (materials/lights) → forward render → client review.
- Assumptions/Dependencies: Indoor scenes; consistent camera paths help; quality depends on inverse rendering accuracy and scene coverage.
- Creator-grade smartphone app for quick video edits
- Sector: daily life, prosumer tools
- What: Recolor clothing, soften shadows, tweak room lighting across short clips using intuitive sliders tied to intrinsic channels.
- Tools/Workflows: Mobile UI with keyframe mark-and-edit; server-side inference; presets like “Golden Hour Relight,” “Matt Finish.”
- Assumptions/Dependencies: Cloud inference to overcome on-device compute limits; latency acceptable for short clips; user consent for content processing.
- Dataset generation and benchmarking for intrinsic video tasks
- Sector: academia, research infrastructure
- What: Use V-RGBX to produce pseudo-ground-truth intrinsic sequences for new benchmarks; evaluate temporal consistency in RGB→X→RGB cycles.
- Tools/Workflows: Automated pipeline to compute PSNR/LPIPS/SSIM/FVD and VBench smoothness; controlled synthetic-to-real studies.
- Assumptions/Dependencies: Awareness of domain bias (indoor-heavy training); careful curation; transparent reporting of limitations.
Long-Term Applications
The following applications are feasible with further research, scaling, and development (e.g., generalization, real-time constraints, outdoor coverage).
- Real-time, on-set relighting and material control for live broadcast and virtual production
- Sector: live TV, virtual production stages
- What: Interactive adjustment of lighting/materials during recording, maintaining temporal coherence across long sequences.
- Tools/Workflows: Low-latency inference on dedicated GPUs/ASICs; integration into switcher/LED wall control; operator-friendly UIs.
- Assumptions/Dependencies: Significant model optimization; long-range temporal modeling; robust outdoor/general lighting; fail-safe controls.
- Outdoor and open-world generalization of intrinsic-aware editing
- Sector: media, AR navigation, autonomous systems
- What: Reliable intrinsic decomposition and editing in complex outdoor scenes (hard shadows, specular highlights, weather).
- Tools/Workflows: Expanded training (outdoor datasets, varied weather/time-of-day); domain adaptation; uncertainty-aware editing to avoid artifacts.
- Assumptions/Dependencies: Large-scale, diverse training data; non-Lambertian effects; improved irradiance/environment mapping.
- Intrinsic-aware AR for consumer apps and commerce
- Sector: AR/VR, retail
- What: Try-on and home visualization apps that match inserted items to real scene lighting/material dynamics in video and live view.
- Tools/Workflows: On-device intrinsics estimation; per-frame material fit; consistent video relighting for AR overlays.
- Assumptions/Dependencies: Efficient mobile models; privacy-friendly on-device processing; calibration of device cameras/sensors.
- Physically grounded stylization and cinematic grading
- Sector: creative tools, film color grading
- What: Style transforms that operate in intrinsic space (e.g., grading shading separately from albedo), yielding more credible results than pixel-only methods.
- Tools/Workflows: “Intrinsic Grade” panels in DaVinci Resolve/Adobe; parameterized styles mapped to albedo/irradiance/normal channels.
- Assumptions/Dependencies: Broad scene generalization; UX that exposes intrinsics intuitively; cooperative workflows with color science teams.
- Forensic analysis and edit provenance via intrinsic inconsistency detection
- Sector: policy, trust & safety
- What: Detect suspicious edits by checking inconsistencies between observed RGB and recovered intrinsics across time; support disclosure and labeling.
- Tools/Workflows: Intrinsic consistency scanners; provenance metadata linking keyframes and edit regions; reporting dashboards.
- Assumptions/Dependencies: Reliable decomposition under adversarial content; standardized provenance frameworks (e.g., C2PA); careful false-positive management.
- Robotics and autonomous systems domain randomization with intrinsic control
- Sector: robotics, simulation
- What: Generate training videos where lighting/material variations are controlled independently to improve robustness of perception models.
- Tools/Workflows: Sim-to-real pipelines using X→RGB synthesis; curriculum design for lighting/material invariance; evaluation with task metrics.
- Assumptions/Dependencies: Bridging sim-to-real gap; outdoor compatibility; integration with robot data pipelines.
- Long-range video editing (minutes-scale) with persistent keyframe controls
- Sector: media production, sports analytics
- What: Multi-touch edits that persist over long segments with controlled drift; hierarchical keyframes for segments and sub-segments.
- Tools/Workflows: Temporal memory modules; hierarchical conditioning; edit timelines akin to NLEs but operating in intrinsic space.
- Assumptions/Dependencies: Extended DiT architectures for long context; memory-efficient conditioning; robust propagation under scene changes.
- Intrinsic-aware search and indexing in video archives
- Sector: media asset management, education
- What: Search by physical attributes (e.g., “scenes with cool lighting,” “highly reflective surfaces”), enabling targeted reuse and teaching.
- Tools/Workflows: Batch RGB→X decomposition; feature extraction per channel; semantic indexing; UI for attribute queries.
- Assumptions/Dependencies: Scalable offline processing; standardized descriptors for intrinsics; acceptable storage overhead.
- Enterprise API for intrinsic-aware video editing at scale
- Sector: SaaS, creative ops
- What: Cloud APIs that expose functions like “set_albedo(color), adjust_irradiance(hue/intensity), set_material(roughness/metallic)” with keyframe inputs.
- Tools/Workflows: REST/gRPC endpoints, job queueing, SLA-backed inference; audit logs and compliance tagging.
- Assumptions/Dependencies: Cost control for GPU inference; regional data residency; content rights management.
- Interactive learning platforms for graphics with intrinsic feedback
- Sector: EdTech, professional training
- What: Practice modules where learners manipulate intrinsics and see immediate, temporally coherent outcomes, building intuition for rendering physics.
- Tools/Workflows: Browser-based demos with lightweight models; guided labs; assignments that measure temporal coherence and channel disentanglement.
- Assumptions/Dependencies: Model distillation to run in-browser or on modest hardware; accessible datasets; pedagogy aligned with course outcomes.
Glossary
- Albedo: The intrinsic, shadow-free color of a surface, independent of lighting. "such as albedo, normal, material, and irradiance"
- Ambient occlusion: A shading component that approximates soft global shadows in creases and cavities. "The material channel consists of surface attributes such as roughness, metallic, and ambient occlusion;"
- CLIP embeddings: Vector representations from the CLIP model used to encode text prompts for conditioning. "The target modality name is encoded as a text prompt using CLIP embeddings~\cite{radford2021learning}."
- Classifier-free guidance: A sampling technique that blends conditional and unconditional model outputs to control generation strength. "At inference time, classifier-free guidance~\cite{ho2022classifier} is applied to the reference conditioning to balance fidelity and edit consistency."
- Cycle consistency: An evaluation where data is transformed out and back (e.g., RGB→X→RGB) to assess fidelity and coherence. "V-RGBX can also be evaluated in an end-to-end manner via cycle consistency."
- Diffusion models: Generative models that synthesize data via iterative denoising from noise. "Diffusion models have become the leading paradigm for visual synthesis"
- Diffusion Transformer (DiT): A transformer-based architecture adapted for diffusion modeling in images/videos. "We adopt a Diffusion Transformer (DiT) backbone~\cite{wan2025}"
- DiffusionRenderer: A prior method for intrinsic-aware rendering and decomposition using diffusion techniques. "DiffusionRenderer~\cite{DiffusionRenderer} enables video decomposition and re-composition"
- Environment map: A representation of surrounding illumination used to model reflections and lighting. "estimate an environment map from the first frame of each video sequence"
- FID: Fréchet Inception Distance; a metric for visual fidelity comparing distributions of deep features. "with noticeable gains in PSNR, LPIPS, FID, FVD, and smoothness."
- FVD: Fréchet Video Distance; a metric assessing video quality via distributional distance in learned video features. "To assess video generation quality, we use FVD~\cite{unterthiner2019fvd}"
- Interleaved conditioning: Mixing multiple conditioning modalities over time to guide generation. "an interleaved conditioning mechanism that enables intuitive, physically grounded video editing"
- Inverse rendering: Estimating scene intrinsic properties (materials, lighting, geometry) from images or video. "Image-space inverse rendering techniques~\cite{zeng2024rgb, Luo2024IntrinsicDiffusion} are then applied"
- Intrinsic channels: Disentangled, physically meaningful image components like albedo, normals, materials, and irradiance. "into intrinsic channels, such as albedo, normal, material, and irradiance,"
- Intrinsic image decomposition: Splitting an image into components (e.g., albedo and shading) that explain its appearance. "There has been increasing focus on intrinsic image decomposition, composition, and editing."
- Irradiance: The amount of light arriving at a surface, integrated over incoming directions. "such as albedo, irradiance, normal, and depth."
- Keyframe referencing: Using edited keyframes as visual guidance inputs during generation. "Keyframe referencing."
- LPIPS: Learned Perceptual Image Patch Similarity; a metric for perceptual similarity based on deep features. "We evaluate both forward and inverse rendering performance using PSNR, SSIM, and LPIPS~\cite{zhang2018unreasonable}."
- Modality-aware embedding: A learned embedding indicating the specific conditioning modality (e.g., albedo vs. normal) for each frame. "a unified and interleaved sequence modulated with a modality-aware embedding"
- Normal: Surface orientation vectors used for shading and geometric reasoning. "such as Albedo, Normal, Material, and Irradiance,"
- One-hot modality indicator: A binary vector marking the active modality type for embedding. "where is a one-hot modality indicator"
- Patchification: Converting feature maps into patches for transformer processing. "After patchification, each latent chunk is modulated"
- PSNR: Peak Signal-to-Noise Ratio; a fidelity metric measuring reconstruction accuracy. "We evaluate both forward and inverse rendering performance using PSNR, SSIM, and LPIPS"
- Relighting: Editing the lighting of a scene while preserving materials and geometry. "including object appearance editing and scene-level relighting"
- Smoothness score: A metric quantifying temporal consistency across video frames. "for temporal coherence, we adopt the smoothness score from VBench~\cite{huang2024vbench}."
- SSIM: Structural Similarity Index; a metric capturing perceived structural similarity between images. "We evaluate both forward and inverse rendering performance using PSNR, SSIM, and LPIPS"
- Temporal adapter: A module that aggregates or arranges per-frame embeddings to align with temporally compressed latent chunks. "we then construct a packed embedding for each latent chunk via a temporal adapter,"
- Temporal-aware Intrinsic Embedding (TIE): A packed embedding that encodes per-frame modality identities within temporally compressed chunks. "we propose a Temporal-aware Intrinsic Embedding (TIE) that packs per-frame modality embeddings within the chunk dimension"
- Temporal multiplexing: Alternating different conditioning modalities over time to form a single sequence. "denotes a temporal multiplexing operation that alternates intrinsic modalities over time."
- U-Net: A convolutional encoder–decoder architecture with skip connections, widely used in diffusion models. "adopt U-Net~\cite{ronneberger2015unet}-based architectures"
- Velocity-prediction objective: A training objective for diffusion models predicting the “velocity” (v) of denoising dynamics. "We fine-tune the backbone with the velocity-prediction objective~\cite{peebles2023scalable}"
- Wan-VAE: The variational autoencoder component from the WAN model used for encoding/decoding video latents. "the frozen Wan-VAE decoder"
Collections
Sign up for free to add this paper to one or more collections.