- The paper introduces a novel two-phase evaluation using VLMs and transformer encoders to generate detailed, domain-specific captions.
- It demonstrates significant retrieval improvements, with nDCG@10 scores of 0.941 for spiral galaxies compared to baseline methods.
- The study shows that AI-driven captioning and re-ranking enable scalable discovery of rare astronomical phenomena, reducing reliance on manual annotations.
Semantic Retrieval in Astronomical Imaging: AION-Search Using AI-Generated Captions
The exponential growth of digital astronomical surveys such as the Legacy Survey and HSC has created archives containing hundreds of millions of galaxy images. Exhaustive manual annotation pipelines, typified by efforts like Galaxy Zoo, are unsustainable at the scales required for modern and forthcoming surveys (e.g., Euclid, LSST). Furthermore, traditional volunteer-based approaches are limited by their reliance on fixed-question taxonomies, labor-intensity, human annotation biases, and the lack of support for open-vocabulary, natural language queries. Previous machine learning pipelines, whether self-supervised or trained on manually labeled datasets, fail to support flexible retrieval or scale efficiently.
Recent advances in Vision-LLMs (VLMs) have shown promise for automated image captioning and cross-modal alignment, including domain-specific models such as PAPERCLIP and AstroCLIP. However, these earlier approaches suffered from misaligned or overly generic image-text pairs. Synthetic captioning using large-scale VLMs as annotators, though relatively unexplored in astrophysics, raises the possibility of creating a generative pipeline for semantic search on previously unlabeled scientific datasets.
Methodological Framework
VLM-based Description Generation and Benchmarking
The paper establishes a two-phase evaluation pipeline for VLMs. First, the performance of several VLMs from OpenAI and Google is assessed in their ability to answer the hierarchical Galaxy Zoo morphology annotation tree and to generate free-form domain-relevant captions. An LLM-based judge is used to map VLM-provided open-ended descriptions back onto the Galaxy Zoo answer space for quantitative performance comparison with human consensus, revealing a significant, though imperfect, alignment between VLM and expert annotation.
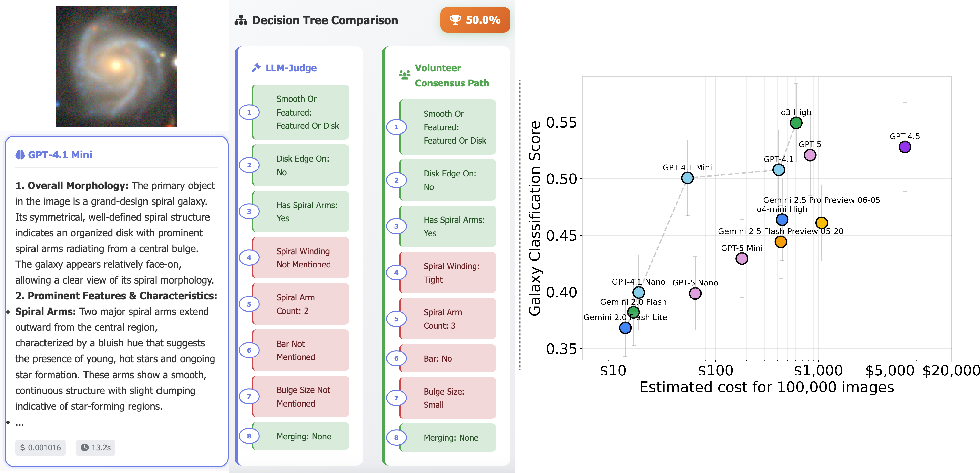
Figure 1: The left panel describes the transformation of VLM free-form galaxy captions into Galaxy Zoo answers; the right panel quantifies the accuracy/cost trade-off for various VLMs, highlighting the accuracy per dollar Pareto frontier.
GPT-4.1-mini is selected as the captioning model of choice, achieving 50.1±3.3\% accuracy on the testbed while optimizing for cost.
Dataset Construction and Cross-Modal Alignment
The semantic search dataset is constructed from 255,948 images representing a balanced telescope and modality sampling from HSC and Legacy Survey data. Multi-band image cutouts are converted into VLM-compatible RGB composites using astronomy-specific scaling. For each image, a detailed open-domain description is generated by GPT-4.1-mini via a prompt optimized with AIDE for physical interpretability and completeness. Descriptions are subsequently embedded using OpenAI's text-embedding-3-large model.
To enable semantic image search at archival scale, the AION-1-Base transformer-based foundation model (pretrained on >200M images via masked modeling) is leveraged as the image encoder. Rather than storing text embeddings for all >100M images (which is cost-prohibitive), the system instead learns to map images to semantic space via contrastive alignment of AION and text-embedding-3-large projections with InfoNCE loss. Architecturally, four-layer residual MLP heads are attached and trained on a single A100 GPU, with the weights of the major encoders kept frozen.
Search Evaluation and VLM Re-ranking
Retrieval is evaluated following the AION protocol using nDCG@10 for three key scientific categories: spiral galaxies, mergers, and strong gravitational lenses. These classes sample a controlled range of rarity, illuminating the system's ability to recover phenomena at the distributional tail. Retrieval queries are cast as short, natural language text (e.g., 'gravitational lens') rather than provision of anchor images. Performance is measured against cross-modal and purely visual baselines, including AstroCLIP, DINOv2, and three AION model variants.

Figure 2: Example AION-Search retrievals demonstrate flexible, open-vocabulary querying for complex astronomical phenomena without supervised training sets.
An additional post-retrieval VLM-based re-ranking stage is implemented: for the top-1000 search candidates, the full GPT-4.1 suite is used to (1-10)-score each image's match to the query, with N-sample averaging to control test-time compute. Performance is analyzed as a function of model capacity and inference-time augmentation, particularly for rare lensing phenomena.

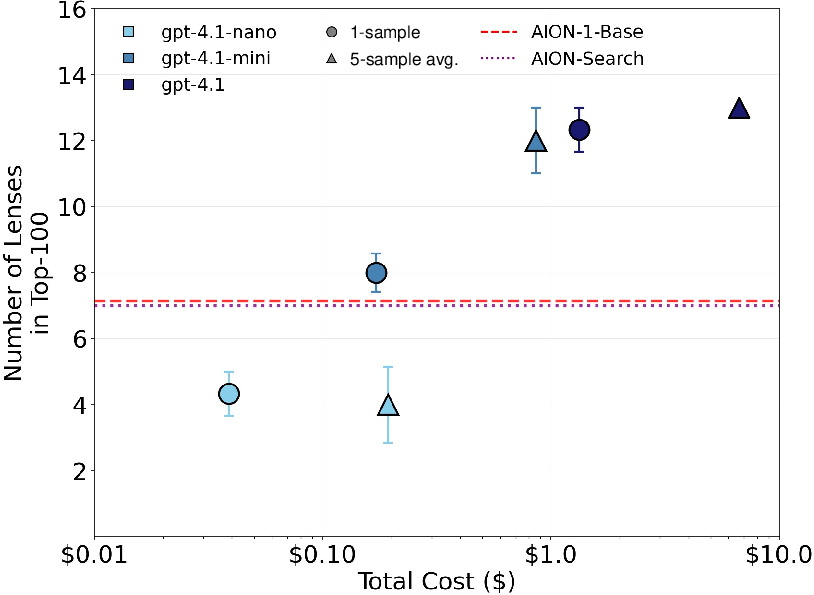
Figure 3: VLM re-ranking boosts lens retrieval and scales with compute; left shows the first three lenses discovered post re-ranking, right plots confirmed lens recovery as compute increases.
Empirical Results
AION-Search achieves large improvements in zero-shot semantic retrieval versus all tested baselines. For spiral galaxies, nDCG@10 reaches 0.941 (AION-Search), compared to 0.643 for the strongest similarity-based baseline (AION-1-L). Performance for mergers (0.554 vs. 0.384) and gravitational lenses (0.180 vs. 0.015) shows even more dramatic relative gains. These results underscore the importance of cross-modal alignment—direct image similarity methods fail for rare or subtle features not easily represented in the training distribution.
Qualitative examples (Figure 2) show the discovery of galaxies with complex morphologies that previously required dedicated, campaign-style labeling.
The re-ranking stage consistently improves retrieval quality, especially for rare phenomena. For strong lenses, doubling of recall is observed in the top-100 results (from 7 to 13 confirmed lenses) when employing GPT-4.1 with five-fold scoring. Both model scale and increased compute at test time lead to monotonic improvements, indicating re-ranking strategies can be systematically deployed to exploit available compute budgets (Figure 3).
Implications and Limitations
AION-Search demonstrates that VLM-generated captions provide sufficiently information-rich signal to train effective semantic encoders for scientific imagery, supporting flexible open-vocabulary retrieval at previously unachievable scales. This capability offers a practical alternative to large, rigid volunteer-labeled datasets, directly addressing the challenge of rare object discovery in astronomy and, by extension, other data-intensive scientific domains.
Notable limitations include VLM hallucinations and the potential for feature omission, particularly for fine or poorly represented astrophysical structures. Captions inherit the inductive biases and pretraining exposures of GPT-4.1-mini, and current benchmarks focus on structured taxonomy mapping rather than holistic description coverage. As VLM science-oriented pretraining improves and free-form domain reference descriptions become available for evaluation, both annotation quantity and quality are expected to improve. Extension to other scientific disciplines (e.g., Earth observation, materials microscopy) will depend on the richness of available descriptive corpora.
Agentic and tool-augmented re-ranking, leveraging domain-specific external computation and analysis (e.g., lens modeling with lenstronomy), are cited as natural next steps for further performance scaling and automation of discovery and validation loops.
Conclusion
This work establishes that, for the first time, it is possible to semantically search >100M galaxy images using AI-generated captions, without reliance on manual annotation. Contrastively aligning astronomy foundation model encoders to synthetic VLM descriptions yields substantial improvements in retrieval for common and rare phenomena. VLM-based re-ranking further increases precision, with performance scaling directly with compute expenditure at inference time. With the increasing scope of astronomical surveys, such AI-driven pipelines are poised to become critical infrastructure for data-driven scientific discovery, and their generalization to other high-volume scientific image domains is both feasible and imminent.