- The paper presents a unified RL policy that achieves robust, zero-shot fall recovery across diverse humanoid robot morphologies with performance gains over specialist approaches.
- It employs a cross-morphology training methodology using CrossQ-SAC and extensive domain randomization to enhance generalization and sample efficiency.
- Extensive evaluations demonstrate that continuous and overlapping morphology coverage is critical to achieve high transfer success rates for scalable robotic deployment.
Unified Fall Recovery for Diverse Humanoid Robots via Morphology-Agnostic RL
Introduction
This paper, "Learning to Get Up Across Morphologies: Zero-Shot Recovery with a Unified Humanoid Policy" (2512.12230), presents a morphology-agnostic reinforcement learning (RL) approach for robust fall recovery in humanoid robots. Unlike typical DRL and classical KFB methods that require per-robot engineering, this work demonstrates a single policy trained via CrossQ-SAC generalized across seven bipedal robots with significant variation in size, mass, and limb geometry, operating in the MuJoCo simulator.

Figure 1: Visual of the seven humanoid morphologies spanning height and weight diversity, with a shared bipedal structure enabling a common control policy.
Morphology-Agnostic Policy Construction
The approach defines a unified action space, reducing actuator control to a shared set of pitch joints (shoulder, elbow, hip, knee, ankle). The observation space avoids explicit morphology encodings; it only contains proprioceptive and task-relevant physical quantities such as joint states, trunk orientation, and head height. The reward function is designed to be generic, incentivizing upright posture, vertical alignment, smooth actions, and penalizing self-collisions without morphology-specific pose priors.
Extensive domain randomization is employed, perturbing the mass, friction, and sensor parameters to increase robustness against both unseen morphologies and sim-to-real variability. CrossQ is utilized over vanilla SAC for improved sample efficiency in the large state-action space arising from multi-morphology training.
Experimental Evaluation
Leave-One-Out (LOO) Zero-Shot Transfer
The LOO protocol assesses generalization by holding out each morphology during training and evaluating zero-shot get-up success on the unseen target. Policies are trained and evaluated across multiple seeds for statistical rigor.
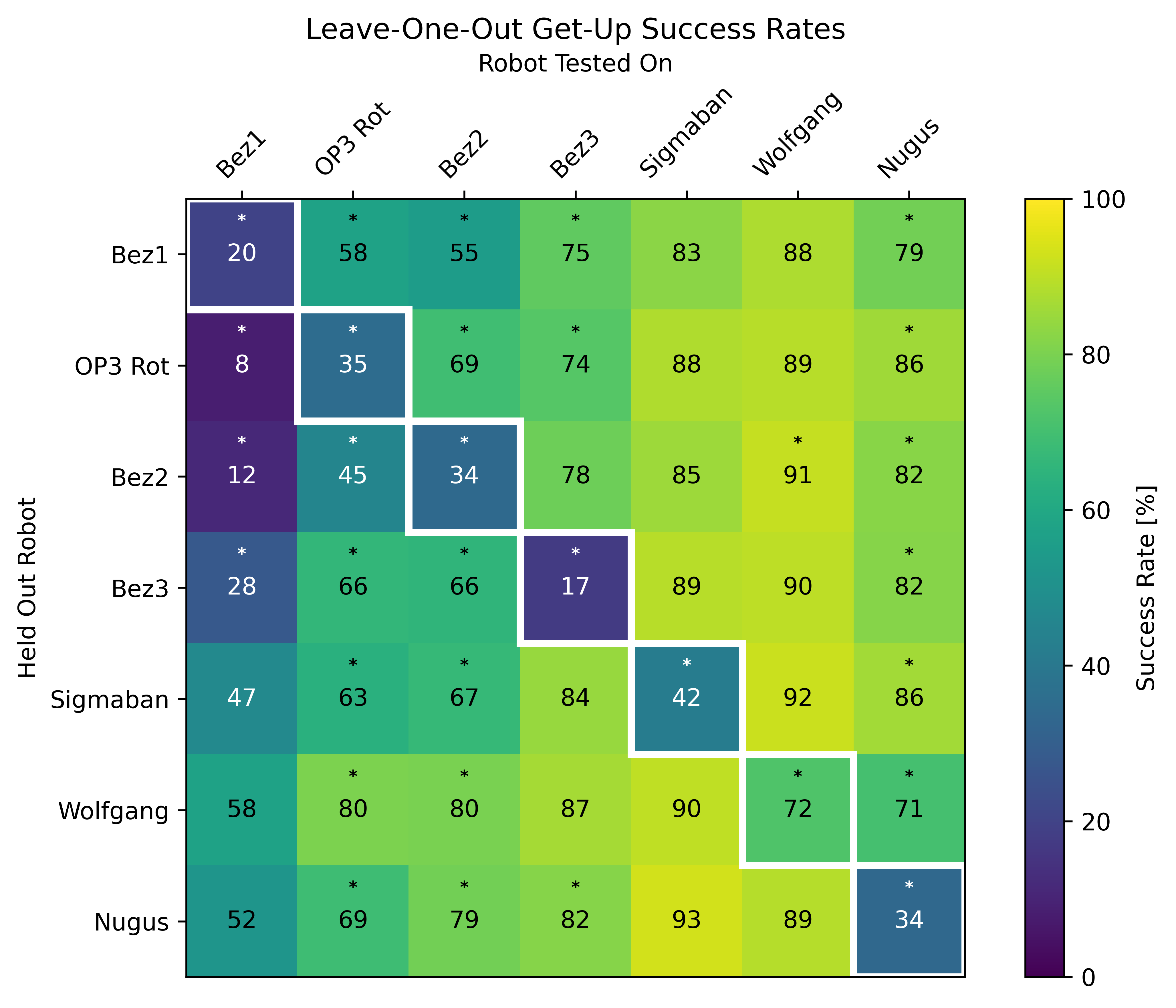
Figure 2: Leave-one-out generalization heatmap showing zero-shot and cross-transfer get-up rates for each morphology; diagonal elements indicate pure zero-shot transfer.
Results show that, for select morphologies (e.g., Wolfgang), zero-shot policies trained without direct exposure still achieve high get-up rates (72 ± 21%). Performance on others (e.g., Sigmaban, NUGUS) demonstrates significant dependence on inclusion of morphologically similar robots during training, with failure cases elucidating the need for continuous coverage of the morphology space. Notably, smaller robots displayed robust transfer provided that similar-sized morphologies are represented in the training dataset.
Specialist vs. Shared Policies
Comparison between specialist (per-robot) and shared (multi-robot) policies provides quantitative analysis of generalization cost and transfer benefits.
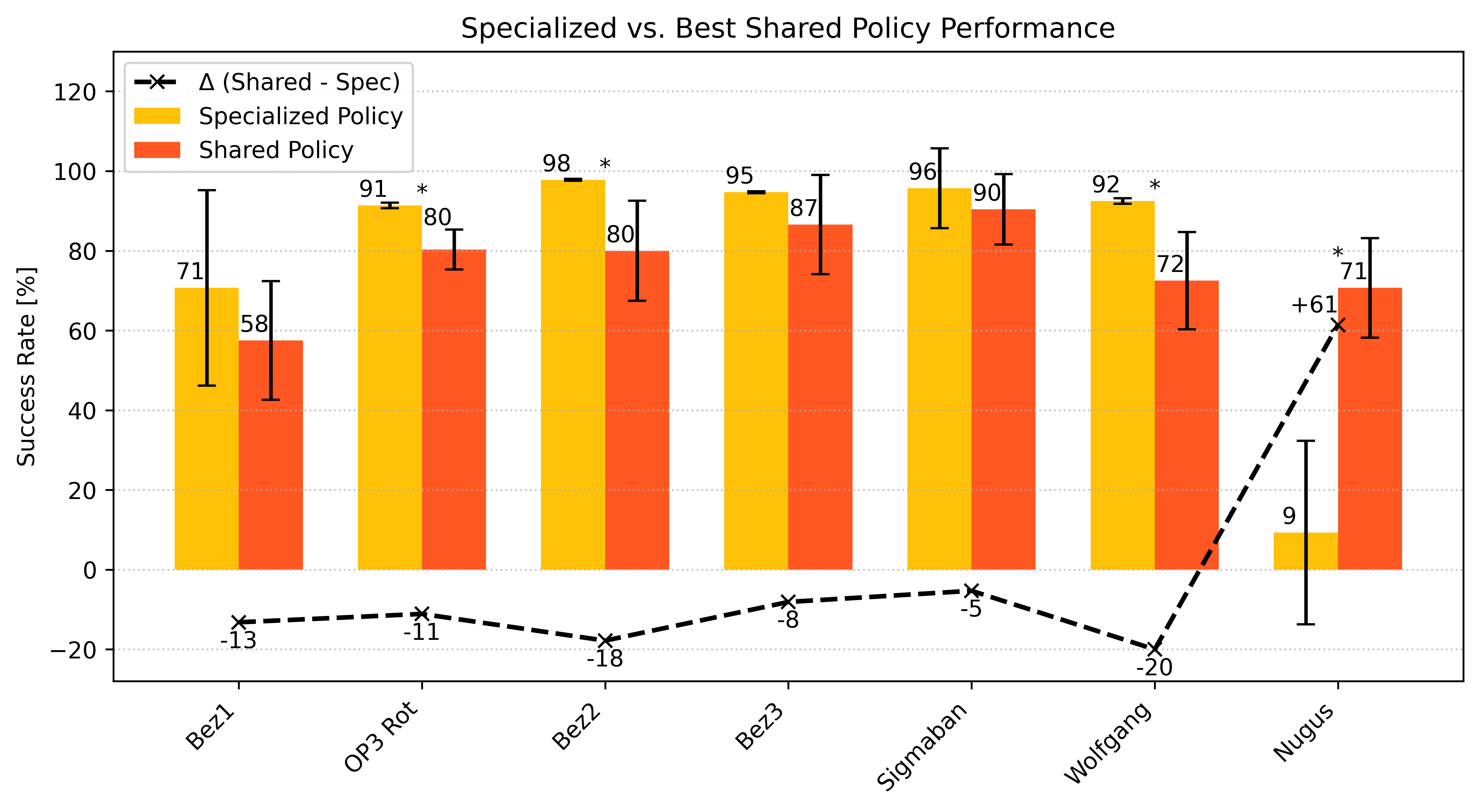
Figure 3: Comparative success rates of specialist (yellow) and shared (orange) policies across all morphologies, including statistically significant performance differentials.
The unified policy achieves near-parity with specialist policies for most morphologies (≤ 15% deficit), occasionally surpassing them. The most striking effect occurs on NUGUS, where the shared policy outperforms the specialist by 61% (95% CI [38, 85], p<0.001); in isolation, NUGUS is too dynamically challenging, but cross-morphology sharing supplies the required inductive bias and robustness. On average, the shared policy exceeds 58% success for every robot, with four morphologies surpassing 80%.
Morphological Scaling and Coverage
To dissect the relationship between training set diversity and generalization, the study systematically varies the number and composition of morphologies in the training set and tracks zero-shot performance.
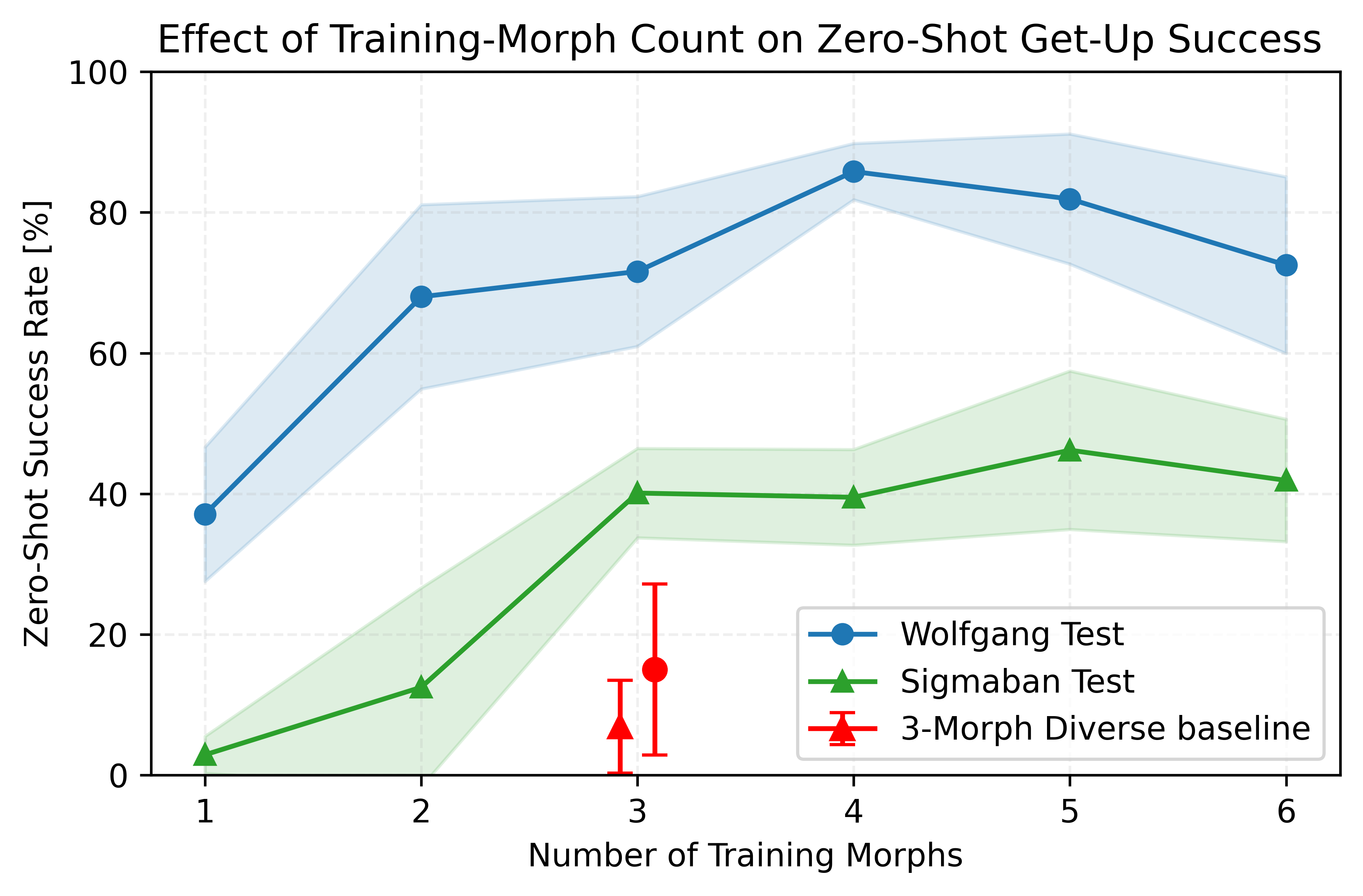
Figure 4: Zero-shot success rates for Wolfgang (blue) and Sigmaban (green) as a function of the number and selection of training morphologies k.
Results indicate that mere addition of morphologies is insufficient; continuous, overlapping coverage in morphology feature space is required. For Wolfgang, performance scales steadily with inclusion of similar morphologies, plateauing when diversity becomes excessive or key intermediates are lacking. For Sigmaban, a lack of compatible training robots stagnates improvement, confirming that "arbitrary diversity" is not equivalent to "effective coverage." The ablation with only outlier morphologies yields near-zero transfer.
Behavior Trajectory Visualization
Policy rollouts confirm qualitatively plausible and efficient get-up behaviors across morphologies, such as the successful sequence depicted for the Bez2 robot.

Figure 5: Recovery trajectory of the Bez2 robot controlled by the unified policy over a two-second window in Mujoco.
Practical and Theoretical Implications
This work establishes the viability of morphology-agnostic policies for complex whole-body tasks beyond locomotion, such as get-up, that traditionally require morphology-specific encoding or large engineering effort. From a practical standpoint, the reduced marginal cost for deploying new robots with diverse designs is significant, particularly for applications such as RoboCup, heterogeneous robot fleets, or rapid prototyping environments. Notably, cross-morphology learning effectively provides curriculum for otherwise intrinsically hard morphologies (e.g., NUGUS).
Theoretically, the findings suggest that high-dimensional dynamics cues---absent explicit morphology graphs/vectors---can suffice for nontrivial transfer within bounded morphology classes (kid-size bipeds). However, generalization is tightly linked to morphological continuity and curriculum design. Results also underscore that transferability is not symmetric: some morphologies (outliers or hard cases) disproportionately benefit from diversity, while others serve mainly as knowledge sources.
Limitations and Future Work
There is an absence of direct comparison to GNN-based or morphology-conditioned policies: the baseline here relies on independent specialist policies, as porting graph-conditioned approaches to seven morphologies is nontrivial and remains future work. All evaluations occur in simulation; sim-to-real deployment is an open avenue, although domain randomization and prior work suggest strong transferability. Extending coverage to adult-size robots or more articulated morphologies will require curriculum learning or explicit morphology encoding. Integration of adversarial motion priors (AMP) could enhance motion naturalness.
Conclusion
A single RL policy can learn to perform robust fall recovery across a range of humanoid morphologies without explicit knowledge of the underlying structure, achieving strong zero-shot transfer and in some cases exceeding the efficacy of specialist policies. The quantity and continuity of the morphology coverage are critical to generalization. This paradigm reduces per-robot engineering and points toward scalable, morphology-agnostic generalist controllers for future multi-robot systems.