- The paper introduces the CH-MVGL model that decomposes each graph Laplacian into a shared co-hub component and view-specific sparse parts to enhance interpretability.
- It employs a customized multi-block ADMM with an ℓ₂,₁ penalty to enforce group sparsity and ensure smooth signal recovery across multiple views.
- Theoretical analyses provide identifiability and error bounds, and experiments on synthetic and fMRI data confirm the model’s robustness and scalability.
Co-Hub Node Based Multiview Graph Learning with Theoretical Guarantees
Introduction and Motivation
The paper "Co-Hub Node Based Multiview Graph Learning with Theoretical Guarantees" (2512.12435) systematically addresses the multiview graph learning (MVGL) problem under the structural prior that certain vertices serve as hubs—co-hubs—shared across all views. Instead of the prevailing trend of enforcing edge-level similarity for exploiting inter-view dependencies, the authors propose a node-centric approach, leveraging a co-hub structure for improved interpretability and empirical performance in heterogeneous, multi-view settings. Practical examples arise in domains such as neuroimaging, where covarying brain regions act as functional integrators across individuals or experimental sessions.
Methodological Framework
The paper’s principal contribution is the CH-MVGL (Co-Hub Node based MultiView Graph Learning) model, which extends graph signal processing (GSP) techniques to the multiview regime. Each view-specific graph Laplacian is decomposed into a sum of a view-specific sparse Laplacian and a shared, low-rank co-hub-induced Laplacian. The joint learning objective enforces signal smoothness within each view while imposing group sparsity on the shared component using an ℓ2,1 penalty, promoting a parsimonious set of co-hubs.
Optimization is performed using a customized multi-block ADMM with theoretically justified convergence guarantees. The algorithm is computationally efficient, with per-iteration complexity O(Kn3), where K is the number of views and n the graph order.
Theoretical Results
The work rigorously formalizes the identifiability of the co-hub decomposition and provides a nonasymptotic upper bound on the estimation error of the learned Laplacians under a sub-Gaussian noise model. The error decays at O(d−1/2) in the number of signal observations per view, with a bias term depending on the true number of co-hubs and regularization weights. The identifiability analysis demonstrates that, except for edges incident to the co-hubs, the decomposition of each Laplacian into shared and specific components is unique.
Empirical Results
Experiments encompass both synthetic datasets (Erdős-Rényi, Barabási-Albert, random geometric graphs with varying signal filters), demonstrating the superiority of CH-MVGL over edge-based and precision-matrix-based baseline methods, especially as the true number of co-hubs increases or data deviates from Gaussianity. The model’s scalability is evaluated, confirming that complexity grows linearly in the number of views and cubically in the number of nodes.
For neuroscientific validation, the CH-MVGL model is applied to resting-state fMRI data from the Human Connectome Project across multiple sessions and subjects. The model successfully identifies co-hubs in canonical default mode and dorsal attention networks, and replication analysis confirms the robustness of the selected hubs.
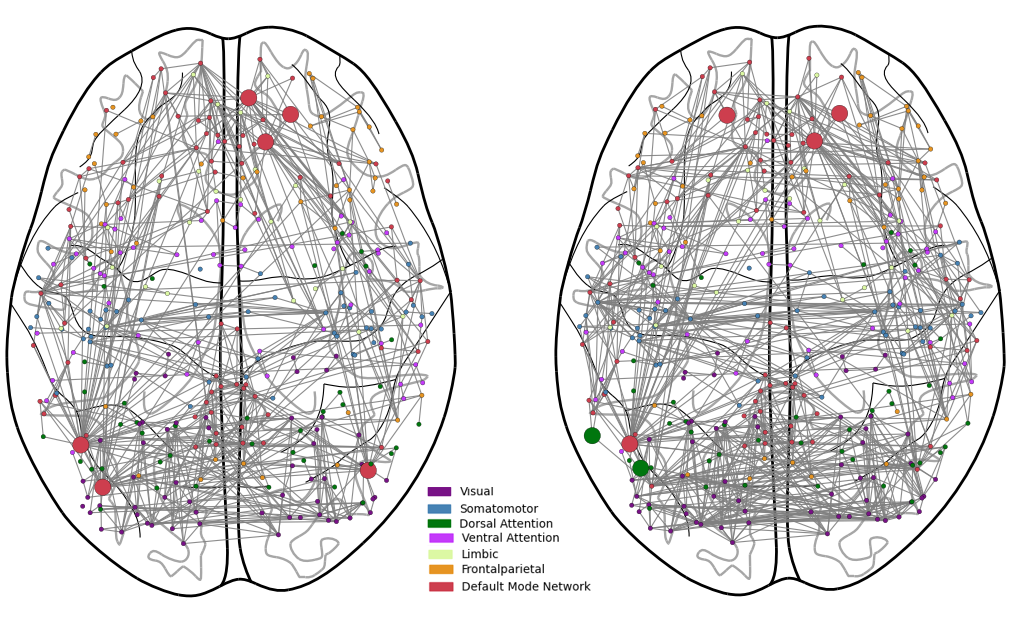
Figure 1: Connectivity of co-hub nodes identified by the CH-MVGL model on the HCP dataset for sessions 1 and 2. The larger nodes denote co-hubs.
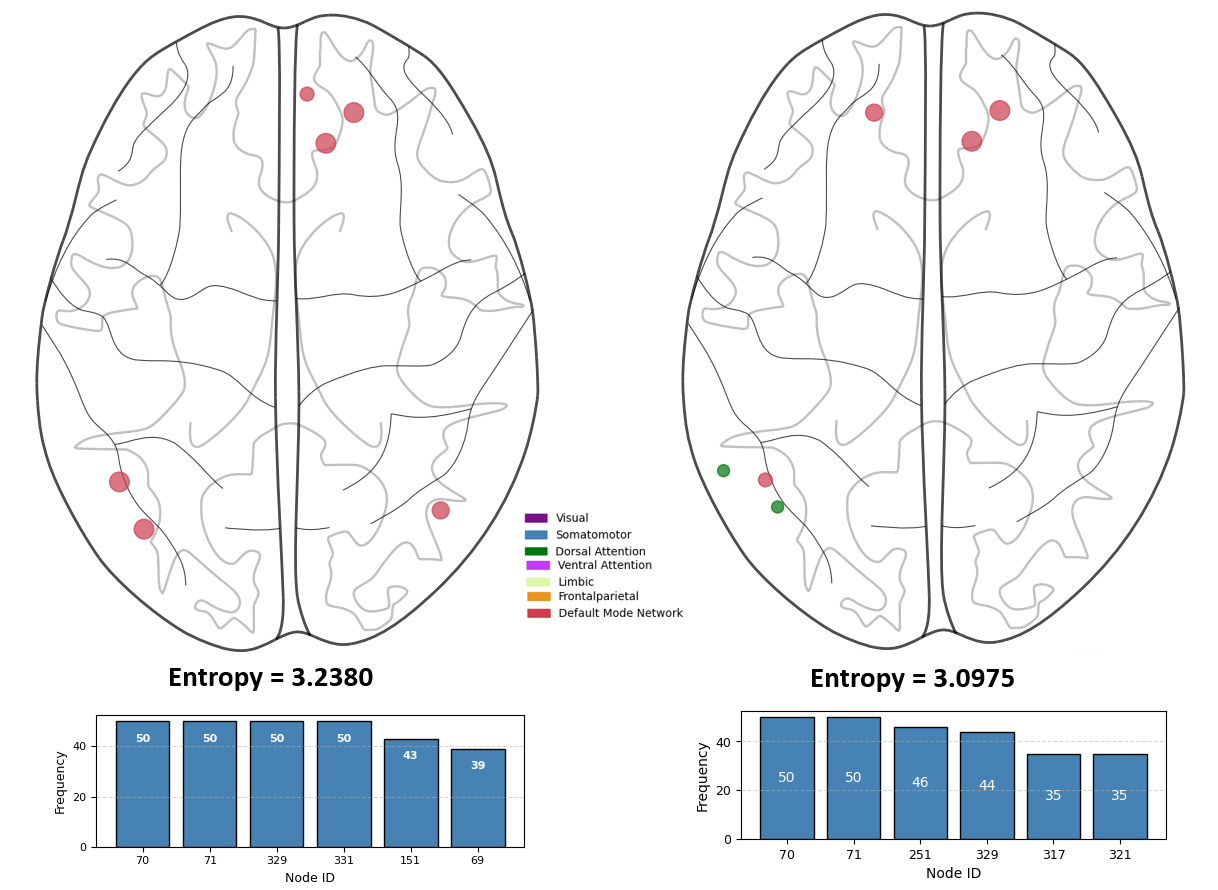
Figure 2: Replicability of co-hubs discovered by CH-MVGL across HCP sessions 1 and 2. Node size indicates selection frequency as a co-hub.
Implications and Future Directions
CH-MVGL establishes a flexible framework with theoretical backing for multiview graph learning centered on node-level commonality. The results have significant implications for functional connectivity analysis, social network inference, and any domain where multiview data share a sparse set of high-degree integrators. Since the method is nonparametric regarding the signal distribution, it demonstrates robustness in non-Gaussian and noisy settings where classical GGM-based approaches fail.
From a methodological perspective, the co-hub formalism encourages further exploration of hybrid structures—allowing for both common and private hubs or incorporating community detection priors. Extensions could target dynamic setting with temporally-evolving co-hub structures, or integration with deep graph learning architectures for feature-augmented scenarios.
Conclusion
This paper introduces and thoroughly analyzes the CH-MVGL model for multiview graph learning, documenting both strong empirical results on synthetic and neural data and comprehensive theoretical support regarding identifiability and error rates. The node-centric co-hub regularizer, in contrast to edge-based similarity, provides a substantial advance in interpretable, scalable, and robust joint graph inference. The framework is broadly applicable and promises utility across diverse applications wherever heterogeneous but structurally connected multilayer graphs must be learned.