- The paper introduces Error-Free Linear Attention (EFLA) to eliminate discretization errors in linear-time attention via an exact continuous-time framework.
- The methodology leverages a continuous-time dynamical system and rank-1 matrix properties to achieve linear time complexity with high numerical stability.
- Empirical results on tasks like sMNIST, WikiText, and LAMBADA demonstrate enhanced convergence, robustness against noise, and improved accuracy.
Error-Free Linear Attention: Theoretical Foundations and Empirical Validation
Introduction
The paper "Error-Free Linear Attention is a Free Lunch: Exact Solution from Continuous-Time Dynamics" (2512.12602) introduces Error-Free Linear Attention (EFLA), a novel attention mechanism designed to eliminate discretization errors commonly encountered in linear-time attention methods. Linear-time attention mechanisms are crucial as they address the computational inefficiencies inherent in the quadratic time complexity of traditional softmax attention, especially for long-context processing and reinforcement learning scenarios. Prior approaches such as DeltaNet and Mamba have attempted to approximate attention operations through connections with continuous-time systems and control theory, yet these methods often succumb to truncation errors and stability issues due to their reliance on low-order numerical integration schemes like Euler discretization.
EFLA employs a continuous-time dynamical system framework to derive an exact closed-form solution for linear attention, effectively corresponding to the infinite-order Runge-Kutta method. This approach ensures numerical stability by eliminating error accumulation and maintaining linear-time complexity. The paper's contributions are threefold: identifying error sources in existing methods, reformulating linear attention as a continuous-time dynamical system, and deriving an exact closed-form solution with linear-time complexity.
Derivation of Error-Free Linear Attention
The authors revisit DeltaNet's formulation of linear attention as a continuous-time dynamical system, highlighting its connection to online gradient descent on a reconstruction loss objective. The numerical approximation given by first-order Euler integration introduces truncation errors, leading to instability under long sequences. Unlike previous methods, EFLA circumvents these errors by providing an exact solution to the underlying ordinary differential equation (ODE) with full parallelism.
The formulation rests on the rank-1 structure of the dynamics matrix. By leveraging this property, EFLA computes the matrix exponential e−βtAt in linear time, bypassing the typical O(d3) complexity. The derived update rule maintains linear time complexity O(Ld2), perfectly capturing continuous-time dynamics.
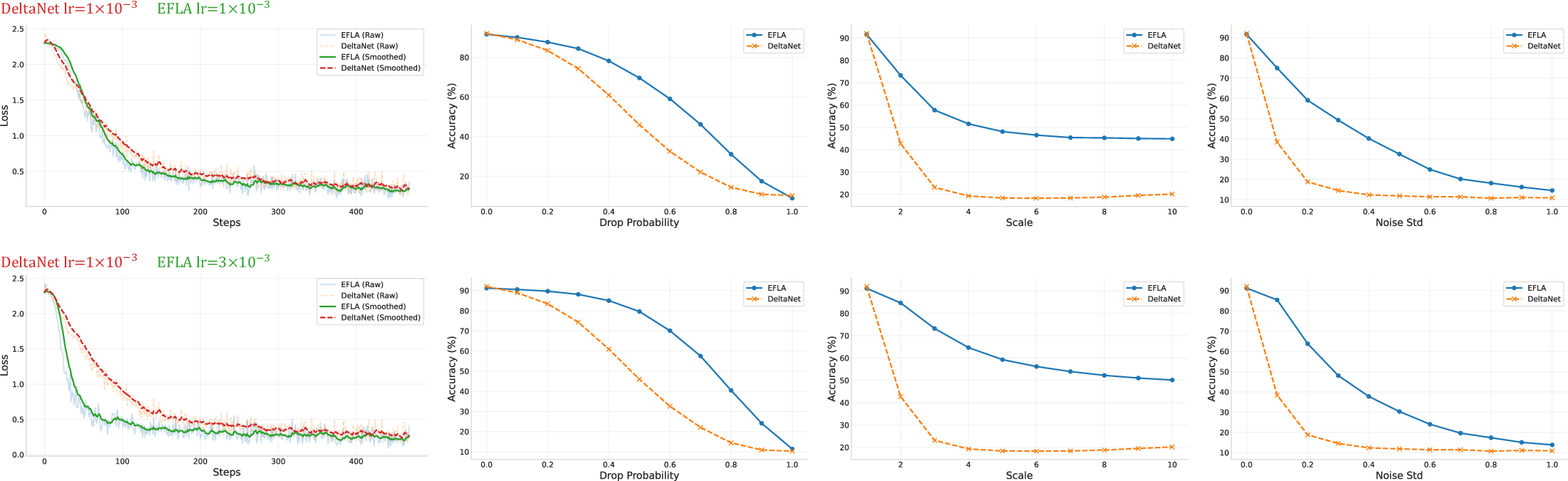
Figure 1: EFLA outperforms DeltaNet in both convergence speed and robustness on sMNIST. The plots illustrate training dynamics and robustness against dropout, scale intensity, and additive noise. Notably, EFLA maintains significantly higher accuracy as interference intensity increases.
Empirical Studies
The empirical assessment of EFLA encompasses numerical stability tests and language modeling benchmarks. The sMNIST task demonstrates EFLA's superior robustness against dropout, out-of-distribution (OOD) intensity scaling, and additive Gaussian noise. Figure 1 illustrates EFLA's ability to maintain higher accuracy under increased interference, showcasing its robustness in noisy environments compared to DeltaNet.
In language modeling tasks such as WikiText and LAMBADA, EFLA consistently exhibits lower perplexity and higher accuracy across diverse benchmarks, signifying the effectiveness of error-free solutions for complex reasoning tasks. These findings underscore that EFLA maintains higher fidelity of historical information over long sequences, offering superior scalability and robustness.
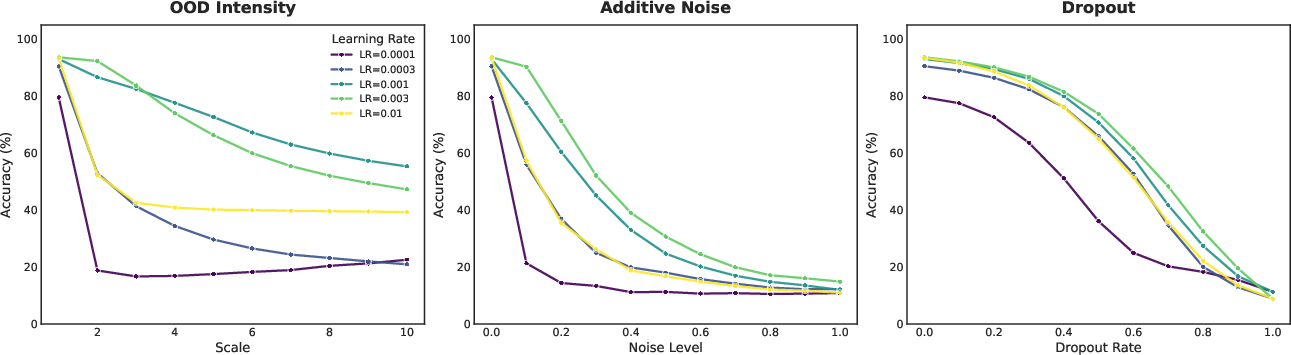
Figure 2: Impact of learning rate scaling on EFLA robustness. Test accuracy of EFLA on sMNIST under various interference settings, demonstrating correlation between learning rate magnitude and model robustness.
Theoretical Implications and Future Directions
The paper establishes a theoretical foundation for building high-fidelity, scalable linear-time attention models. By demonstrating that exact integration is attainable without sacrificing scalability, EFLA paves the way for advancements in stable sequence modeling. The introduction of mathematically precise attention mechanisms could lead to significant improvements in real-time interactivity and throughput, especially for LLMs operating in complex environments.
Future research may explore further optimization of continuous-time dynamics and exact solvers for broader attention frameworks. Such advancements could enhance model robustness against high-energy inputs and boost performance across varied tasks. Additionally, integrating EFLA into existing architectures could lead to novel algorithmic improvements, fostering the development of next-generation AI systems.
Conclusion
Error-Free Linear Attention (EFLA) represents a critical advancement in attention mechanisms, challenging the limitations posed by traditional discretization techniques. The exact analytical solution provided by EFLA offers a clear path toward high-fidelity, efficient sequence models. Empirical studies validate its robust performance, supporting theoretical claims of stability and efficiency. As a foundational work, EFLA will likely influence the design of future scalable AI architectures, thereby opening avenues for substantial breakthroughs in language modeling and beyond.
