Improved Concentration for Mean Estimators via Shrinkage
Published 14 Dec 2025 in math.ST | (2512.12750v2)
Abstract: We study a class of robust mean estimators $\widehatμ$ obtained by adaptively shrinking the weights of sample points far from a base estimator $\widehatκ$. Given a data-dependent scaling factor $\widehatα$ and a weighting function $w:[0, \infty) \to [0,1]$, we let $\widehatμ = \widehatκ + \frac{1}{n}\sum_{i=1}n(X_i - \widehatκ)w(\widehatα|X_i-\widehatκ|) $. We prove that, under mild assumptions over $w$, these estimators achieve stronger concentration bounds than the base estimate $\widehatκ$, including sub-Gaussian guarantees. This framework unifies and extends several existing approaches to robust mean estimation in $\mathbb{R}$. Through numerical experiments, we show that our shrinking approach translates to faster concentration, even for small sample sizes.
The paper introduces a unified shrinkage framework that adaptively downweights outlier observations to achieve optimal high-probability concentration bounds.
It generalizes robust estimators like the trimmed mean, Winsorized mean, and median-of-means with provable non-asymptotic guarantees.
Empirical results demonstrate that shrinkage-based estimators enhance finite-sample accuracy while maintaining robustness under heavy-tailed and contaminated models.
Improved Concentration for Mean Estimators via Shrinkage
Introduction and Motivation
This paper rigorously investigates robust mean estimation through an adaptive shrinkage framework, providing a general unification of a wide spectrum of robust mean estimators. The central problem considered is the estimation of the mean μ=EX1 from i.i.d. observations X1:n sampled from a possibly heavy-tailed or contaminated distribution P. While the empirical mean is asymptotically efficient and minimax in classical light-tailed regimes, it is suboptimal and highly sensitive to distributional outliers. Consequently, robust alternatives such as the trimmed mean, Winsorized mean, and median-of-means (MoM) have been extensively studied, but each present limitations in either robustness, finite sample properties, or variance control.
The paper's key contribution is a general shrinkage approach which, by adaptively downweighting points far from a central estimate κ via a non-increasing weight function w and data-dependent scale α, delivers mean estimators that achieve optimal non-asymptotic high-probability concentration bounds under minimal moment assumptions—even in the presence of arbitrary adversarial contamination.
Shrinkage Framework: Definition and Scope
The proposed shrinkage estimator is defined as
μ=κ+n1i=1∑n(Xi−κ)w(α∣Xi−κ∣),
where w:[0,∞)→[0,1] is non-increasing and α is chosen so that the total weight mass fulfills i=1∑nw(α∣Xi−κ∣)=n−η for a user-specified η (interpreted as a shrinkage or trimming level). This construction subsumes and generalizes classic robust mean estimators:
Median-of-means and related constructions with suitable bucketing.
Remarkably, the framework accommodates arbitrary base estimators κ (median, quantile, empirical mean, etc.)—only requiring its contamination behavior is quantifiable—and places no substantial restrictions on w beyond basic regularity (Assumptions 2–3).
Main Theoretical Results
The paper delivers non-asymptotic, high-probability concentration inequalities for the shrinkage estimator under the most adversarial contamination model. The main result states:
Let X1:nε be an ε-contaminated sample and κ a base estimator. Under minimal regularity, with probability at least 1−4δ,
where νp denotes the pth centered moment of P, and C depends on w, κ, and ε. This rate matches known minimax lower bounds and achieves sub-Gaussian deviation in regimes where ν2<∞ [devroye2016sub].
Importantly, even when the base estimator κ is poor (e.g., much less robust or imprecise), shrinkage can yield substantial improvement—established via explicit bounds quantifying the dependence on the concentration quality of κ (see Theorem 2 and related corollaries). In the limit, if κ is chosen as a robust quantile (median), optimal breakdown point and robustness properties are inherited.
Practical Implications and Empirical Analysis
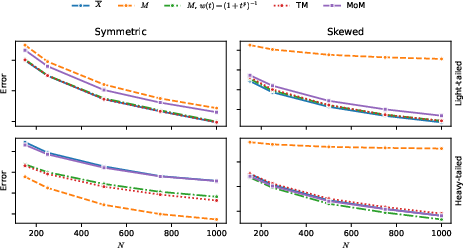
Practical use of the shrinkage estimator is demonstrated through extensive simulations. Empirically, the shrinkage versions of median, MoM, trimmed mean, and Winsorized mean retain their robustness and often outperform their traditional counterparts, in both symmetric and asymmetric heavy-tailed or contaminated distributions. Notable findings include:
Shrinkage improves the finite-sample error of base estimators (empirical mean, median, MoM) in high-confidence intervals, even for small n.
Shrinkage versions based on the median achieve uniformly competitive performance across all scenarios.
The effect of sample splitting (required for theoretical independence of κ and the main sample) is minor; marginal performance gains are possible with very small splits to the base, supporting resource-efficient implementations.
Figure 1: Empirical 1−δ confidence interval errors for various mean estimators and distributions. Shrinkage with the sample median as base achieves high accuracy uniformly, outperforming MoM and closely tracking trimmed mean performance.
Furthermore, the authors verify that robust choices of w (e.g., rapid decay for large t) are critical for resistance to contamination. Shrinkage estimators with slower-decaying weights (e.g., Winsorized mean) are more susceptible to outliers, supporting the theory's emphasis on w's decay and threshold properties.
The shrinkage class preserves or improves major properties desirable in robust statistical estimation:
Affine Equivariance: If κ is affine equivariant, so is μ.
Asymptotic Normality and Efficiency: The shrinkage estimator converges in distribution to the normal law at the same rate as the empirical mean under minimal moment assumptions.
Breakdown Point: For robust choices (e.g., median as base and suitable w), the breakdown point is maximized (up to $1/2$), matching the strongest possible in classical robust statistics.
Computational Tractability: Given the simplicity of computing w and α adaptively, the framework remains suited to practical moderate-/large-scale applications.
Broader Implications and Future Directions
The theoretical guarantees within this shrinkage framework strengthen the understanding and practical adoption of robust mean estimation in both classical and modern large-scale regimes. Potential future directions include:
Extension to multivariate mean estimation, possibly leveraging notions of depth and equivariant trimming.
Data-driven adaptive selection of w and η for optimal trade-offs between robustness and efficiency.
Application and analysis in stochastic optimization, bandits, and machine learning settings involving heavy-tailed data.
Investigation into computational enhancements and tuning methods, especially for high-dimensional and low-resource settings.
Conclusion
The paper establishes a unified, adaptive approach to robust mean estimation via shrinkage, achieving optimal, high-probability concentration rates under minimal conditions and encompassing many popular estimators as special cases. The theoretical and empirical analysis confirms that adaptive shrinkage fundamentally enhances robustness and statistical efficiency, provides optimal control of adversarial contamination, and admits efficiency and breakdown properties crucial for practical applications.
For robust statistics, stochastic optimization, high-dimensional inference, and adversarial machine learning, the shrinkage estimator's framework and analysis presented is a versatile and foundational advancement.
Reference:
"Improved Concentration for Mean Estimators via Shrinkage" (2512.12750)
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.