- The paper introduces a unified 4D MLLM that fuses 3D perception with language reasoning to achieve superior occupancy estimation and trajectory planning.
- It employs a spatial projector with cross-attention to extract high-resolution BEV features from multi-view images and LiDAR data, ensuring detailed 3D understanding.
- Experimental results on benchmarks like nuScenes and OpenOcc show reduced L2 error and collision rates, validating the model’s efficiency and compact design.
DrivePI: A Unified Spatial-aware 4D MLLM for Autonomous Driving
Introduction
DrivePI introduces a spatial-aware 4D multimodal LLM (MLLM) that unifies vision, language, and action for autonomous driving by integrating perception, prediction, and planning in an end-to-end manner (2512.12799). Unlike prior VA and VLA paradigms, DrivePI merges the precise 3D geometric understanding of VA models with the interactive, reasoning-driven capabilities of VLA systems by incorporating LiDAR, multi-view images, and natural language instructions. The architecture features joint optimization across scene understanding, 3D occupancy estimation, occupancy flow prediction, and trajectory planning, with all modalities processed within a single MLLM backbone (Qwen2.5-0.5B).
DrivePI achieves state-of-the-art results across vision-language-action benchmarks, matching or surpassing both specialized VA approaches and leading VLA models, evidenced by substantial reductions in planning L2 error, collision rates, and marked improvements in spatial QA and occupancy metrics. Notably, these results are attained with a compact (0.5B parameter) MLLM, demonstrating efficiency and scalability.
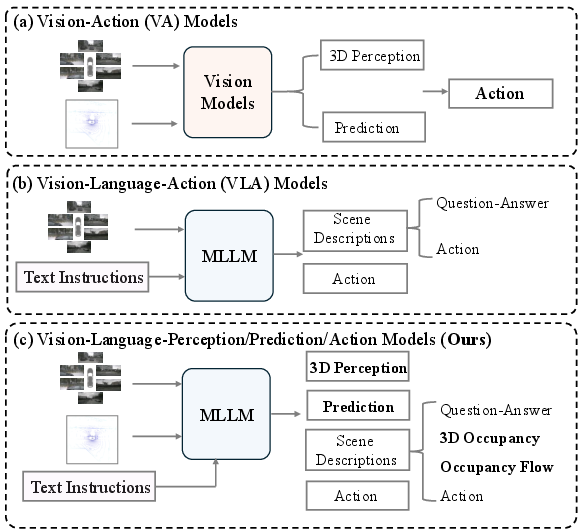
Figure 1: Comparative overview: (a) mainstream VA pipeline, (b) mainstream VLA pipeline, (c) unified DrivePI integrating linguistic understanding with fine-grained 3D perception.
Architectural Overview
DrivePI’s architecture consists of a multi-modal vision encoder extracting BEV features from synchronized multi-view images and LiDAR point clouds. These features are patchified and projected to the language space using a spatial projector, generating vision tokens. Both vision and text tokens are input to the MLLM, which outputs through four dedicated heads: text head (scene/QA reasoning), 3D occupancy head (perceptual estimation), occupancy flow head (dynamic prediction), and action diffusion head (trajectory generation).
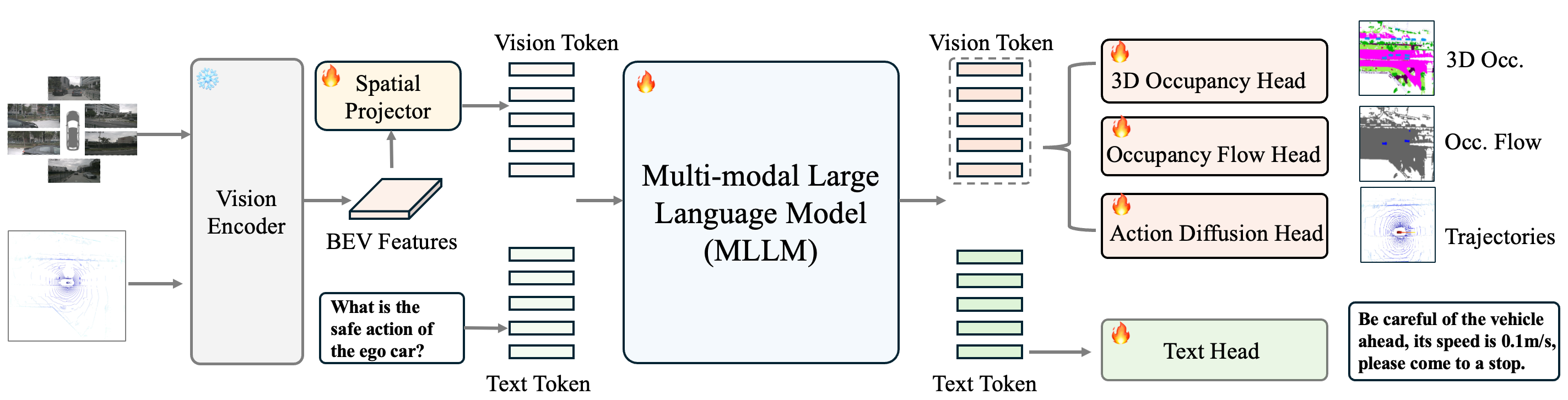
Figure 2: DrivePI pipeline: vision encoder, spatial projector, MLLM, and four specialized output heads for complete scene interpretation and planning.
The spatial projector utilizes a cross-attention mechanism for high-resolution BEV features, enhancing the information density of the vision tokens and circumventing the loss of spatial detail typically incurred by aggressive pooling.
Data Annotation and Multi-stage QA Pipeline
DrivePI’s multi-stage data engine produces large-scale, diverse QA pairs for multi-task instruction tuning, including:
- Caption annotation for front/back views, merged via InternVL3-78B for global scene descriptions.
- Synthetic QA for 3D occupancy and flow, leveraging occupancy/flow ground-truth to probe spatial reasoning.
- Planning-centric QA using true ego-vehicle trajectories for high-level intention and trajectory instruction.
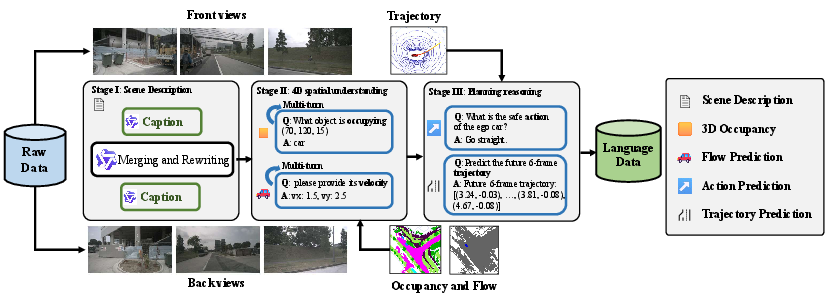
Figure 3: Multi-stage data pipeline for DrivePI: captioning, spatial QA (occupancy/flow), and action/planning QA, ensuring broad coverage of spatial-temporal reasoning.
This combination yields over 1M high-quality, task-diverse QA pairs, supporting the simultaneous emergence of coarse and fine-grained linguistic and perceptual abilities.
Coarse-grained and Fine-grained Spatial Reasoning
DrivePI is capable of both compressed, language-based scene comprehension (coarse) and explicit, metric 3D spatial outputs (fine-grained):
- Coarse: Natural language answers to scene queries, object existence, scene context, and high-level planning.
- Fine-grained: Dense 3D occupancy maps, velocity-aware occupancy flow (spatial-temporal), and continuous ego-trajectory outputs.
Qualitative visualizations indicate strong alignment: linguistic descriptions correspond closely to precise spatial predictions, bolstering interpretability and explainability.
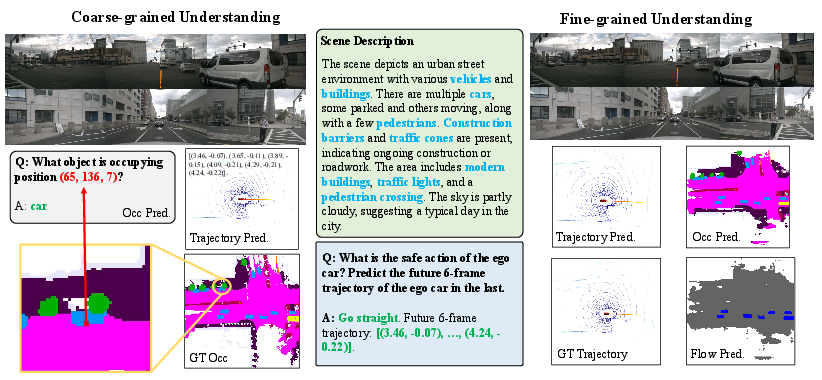
Figure 4: Visualization of DrivePI’s hybrid understanding: scene descriptions, 3D occupancy, and predicted trajectories confirm alignment between language and spatial outputs.
Experimental Validation
3D Occupancy and Flow
On the OpenOcc and Occ3D-nuScenes benchmarks, DrivePI sets new performance highs:
- RayIoU (3D occupancy, OpenOcc): 49.3 (+10.3 over FB-OCC).
- OccScore: 49.3 (highest among all methods).
- mAVE (Occupancy Flow): 0.509 (lower is better, surpassing FB-OCC and ALOcc-Flow-3D).
- On Occ3D (task-specific), RayIoU 46.0, exceeding OPUS by 4.8%.
These values are obtained with joint training and do not require task-specific design or specialized submodules.
Planning
On nuScenes, DrivePI delivers:
- L2 error: 0.40 (w/ego status), beating VAD and OpenDriveVLA-7B by 0.32 and 0.26, respectively.
- Collision rate: 0.11% (vs ORION’s 0.37%, a 70% reduction).
- Without ego status: 32% lower L2 error than VAD.
Notably, DrivePI achieves these metrics using unified parameter weights (no ensemble) and remains competitive with models 10x larger in parameter count.
Textual Spatial Reasoning
On nuScenes-QA:
- Overall accuracy: 60.7% (Qwen2.5-0.5B), outperforming OpenDriveVLA-7B by 2.5%.
- Category-specific: 57.5% for object-related QA.
This validates the model’s capacity for spatial language reasoning and contextual command interpretation.
Ablations
Ablations on text/vision head synergy reveal:
- Joint text and vision head usage yields 1.8% higher RayIoU, 0.18 lower mAVE (flow), and 0.52 reduction in planning L2 vs. vision-only.
- Scaling text QA data enhances all coarse/fine task performance, illustrating clear data-perf scaling.
- Balancing loss weights is non-trivial; task weights influence planning and QA accuracy in expected directions.
Implications and Future Directions
DrivePI demonstrates that with a unified MLLM, it is possible to merge the strengths of VA (geometric precision, interpretability) with VLA (scenario understanding, language interaction) for autonomous driving. The results indicate that massive MLLM backbones are not strictly necessary: efficient, carefully designed architectures and multimodal data curation play a dominant role in end-to-end system capability.
This suggests further research directions:
- Structured loss scheduling and curriculum, addressing balance among perception, prediction, and reasoning.
- Incorporation of RL fine-tuning for closed-loop, interactive planning under feedback.
- Scaling to open-vocabulary, uncurated real-world scenarios for deeper robustness and generalization.
- Extension of the “4D MLLM” paradigm to multi-agent and collaborative autonomy with shared linguistic and geometric protocols.
Conclusion
DrivePI provides a comprehensive, spatially unified MLLM-based approach to autonomous driving, achieving high interpretability, strong real-world performance in fine-grained perception and planning, and robust language interaction. With its moderate model scaling, data-driven dense supervision and joint coarse/fine head optimization, DrivePI represents a significant advancement in fused multimodal understanding for autonomous systems.
(2512.12799)