- The paper introduces a cooperative encoder that synergizes CNN and transformer layers for enhanced global-local feature integration.
- It leverages multi-kernel feature modulation and an uncertainty-aggregated decoder to refine pixel-level building segmentation.
- Empirical results demonstrate improved IoU and F1 scores across key datasets, confirming its efficiency and robustness.
Introduction
The presented work introduces UAGLNet, an advanced deep learning architecture targeting building extraction from high-resolution remote sensing (RS) imagery. The challenge in building extraction stems from complex structure variations, occlusion, and inherent ambiguity in RS images. UAGLNet addresses deficiencies in prior CNN/ViT and hybrid approaches related to the feature pyramid gap and inadequate global-local feature integration by synergizing hybrid CNN and transformer layers, guided by uncertainty modeling. The proposal consists of three core innovations: (a) a Cooperative Encoder architecture employing hybrid CNN-transformer operators; (b) a Global-Local Fusion module facilitating hierarchical integration; and (c) an Uncertainty-Aggregated Decoder providing pixel-wise uncertainty-aware refinement.
Methodological Framework
Cooperative Encoder Architecture
UAGLNet's backbone employs a four-stage cooperative encoder (CE) that hierarchically partitions feature learning between CNN blocks (early stages) and transformer blocks (deep stages). This partitioning exploits multi-kernel feature modulation (MKFM) for spatially diverse local feature extraction. In intermediate stages, the Cooperative Interaction Block (CIB) enables global-local interaction, featuring stacked hybrid convolutional operations interleaved with multi-head self-attention mechanisms. Residual connections and depth-wise separable convolutions maintain computational tractability.
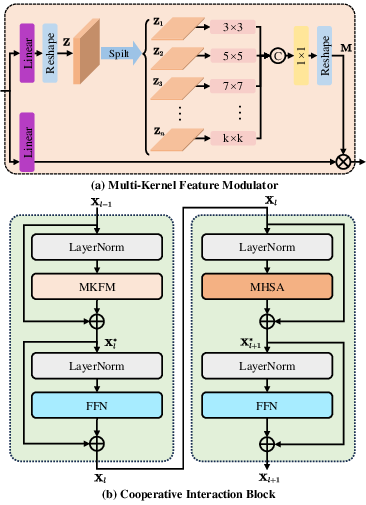
Figure 1: (a) Multi-kernel feature modulation for local information; (b) CIB structure, stacking CNN and transformer layers for global-local information interaction.
The pipeline refines feature pyramids, balancing fine-scale localization and broad contextual semantics, and narrows the global-local gap by dynamically merging multi-scale receptive fields.
Global-Local Fusion (GLF)
GLF constructs complementary global and local representations, leveraging both CIB outputs and terminal MHSA features. Hierarchical features are upsampled, convolved, and concatenated to enforce rich propagation pathways. This stratified fusion mitigates detail loss, sustains object boundary integrity, and provides the encoder-decoder bridge with maximally expressive features for subsequent uncertainty modeling.
Uncertainty-Aggregated Decoder (UAD)
UAD introduces explicit pixel-wise uncertainty estimation, decomposing outputs into local (UL) and global (UG) uncertainty maps. Through Gaussian variational sampling and reparameterization, the model quantifies prediction turbulence at the pixel level. These uncertainty maps act as attenuation weights for feature integration, effectively suppressing ambiguous foreground predictions and enhancing segmentation robustness in challenging regions. The loss function is a weighted sum of dice, binary cross-entropy, boundary, and Kullback-Leibler divergence terms, ensuring tight supervision over both segmentation and uncertainty fidelity.
Empirical Results and Analysis
UAGLNet demonstrates superior numerical results across Massachusetts, Inria, and WHU building datasets, outperforming contemporary CNN, transformer, and hybrid models. On the Massachusetts dataset, it delivers an IoU of 76.97%, F1 score of 86.99%, precision of 88.28%, and recall of 85.73%, surpassing BuildFormer and UANet by measurable margins. On the Inria Aerial dataset, it achieves 83.74% IoU and 91.15% F1, requiring only 28.90G FLOPs and 15.34M parameters—marked reductions in computational demand relative to previous architectures.
Qualitative Improvements
Visualizations reveal that UAGLNet retains superior building boundary integrity, correctly segments occluded or ambiguous structures, and is less prone to false positives in noisy or low-resolution contexts. The integration of local features preserves granularity, while the uncertainty-guided fusion suppresses erroneous activations.
(Figure 2)
Figure 2: UAGLNet overview illustrating complementary local and global representations guided by uncertainty modeling.
Ablation and Architectural Analysis
Ablation studies confirm the contributions of MKFM, CIB, GLF, and UAD. Incorporation of CIB and GLF yields consistent gains in IoU and F1 metrics, with further improvements obtained via uncertainty aggregation in the decoder. Comparative analysis with parallel, sequential, and alternative hybrid architectures demonstrates that the proposed cooperative design offers the best global-local balancing, improving semantic gap closure.
Efficiency, Generalization, and Robustness
UAGLNet achieves real-time inference (27.53 FPS) and demonstrates robust generalization in cross-domain settings (e.g., training on Inria, testing on WHU, experiencing minimal performance degradation relative to baselines). High-resolution testing evidences substantial computational saving while maintaining accuracy. UAD enhances resilience to synthetic noise and resolution degradation, a critical property for deployment on diverse RS platforms.
Implications and Future Directions
Practically, UAGLNet sets a new standard for building extraction pipelines, providing more reliable, uncertainty-aware segmentation suited for urban planning, mapping, and GIS. Theoretically, the cooperative encoder-decoder paradigm and uncertainty aggregation could be generalized to other RS segmentation tasks, and adapted for joint learning in multi-modal, multi-task settings. Prospective advancements include integration with super-resolution modules, further model compression, and extension to semantic tasks beyond building extraction.
Conclusion
UAGLNet advances building extraction by integrating hybrid CNN-transformer operators for balanced global-local semantics, hierarchical fusion, and explicit uncertainty attenuation. The cooperation between multi-scale feature modulation and transformer attention, coupled with pixel-wise uncertainty refinement, yields state-of-the-art performance with efficiency and generalization, and establishes a scalable paradigm for robust RS image analysis.