- The paper demonstrates that LLM-supervised TEMs consistently outperform LLM rerankers in accuracy and scalability for cold-start recommendations.
- It systematically compares both methods across narrow and broad cold-start scenarios using multiple real-world datasets and statistical metrics.
- The study highlights practical benefits of TEMs including lower inference cost, robust cross-domain performance, and effective semantic generalization.
Comparative Analysis of LLMs and TEMs for Training-Free Cold-Start Recommendation
The study addresses one of the most challenging scenarios in recommender systems: the training-free cold-start recommendation (TFCSR) problem, where the system must generate recommendations for users with no prior interaction data and without any task-specific supervised training. This setting is crucial for deployment in practical environments such as new platform launches or user onboarding phases. The research specifically contrasts two paradigms: (1) direct use of LLMs as rerankers via zero-shot prompting, and (2) dense retrieval through text embedding models (TEMs), where textual user and item representations are encoded into an embedding space and similarity-based ranking is performed.
The novelty of this work lies in its controlled, systematic comparison of state-of-the-art LLM reranking and LLM-supervised TEM methodologies under identical TFCSR and broader cold-start conditions, using real-world datasets and rigorous statistical benchmarks.
Experimental Design
Three datasets were curated for comprehensive evaluation: MovieLens-1M, the Job Recommendation dataset (with variations based on profile richness), and the Amazon Review dataset (split into Music, Movie, and Book domains). The study defined narrow cold-start (profile-only, m=0) and broad cold-start (m>0, a small set of interactions available) conditions. Metrics such as Recall@10 and nDCG@10 were measured using fixed candidate pools (typically 50 items) and rigorous user-level statistical testing.
The evaluated methods span:
- Sparse baselines: BM25 for non-neural reference.
- Dense TEMs: Both generalist and LLM-supervised, including multilingual-e5-large, bge-m3, gte-modernbert-base, gte-Qwen2 models, and Qwen3-Embedding (0.6B/8B).
- LLM rerankers: OpenAI’s gpt-4.1, gpt-4.1-mini, and Qwen3-8B, all in inference-only settings with standardized prompts.
The LLM models were required to process the entire candidate set and output top-k rankings, introducing explicit stress on scalability and practical deployment settings.
Main Results
The primary findings can be summarized as follows:
- TEMs, especially those trained with LLM supervision, consistently outperformed LLM rerankers in both narrow and broad cold-start settings. In many cases, TEMs such as gte-Qwen2-7B-Instruct and Qwen3-Embedding-8B produced significantly higher Recall@10 and nDCG@10 than LLMs, even as m increased (past work had focused on much higher m or small candidate sets).
- LLM reranking was not competitive with strong TEMs. While gpt-4.1 sometimes surpassed sparse retrieval baselines for certain recall values when interactions were available, it was consistently outperformed on normalized DCG and failed to realize gains on realistic candidate set sizes.
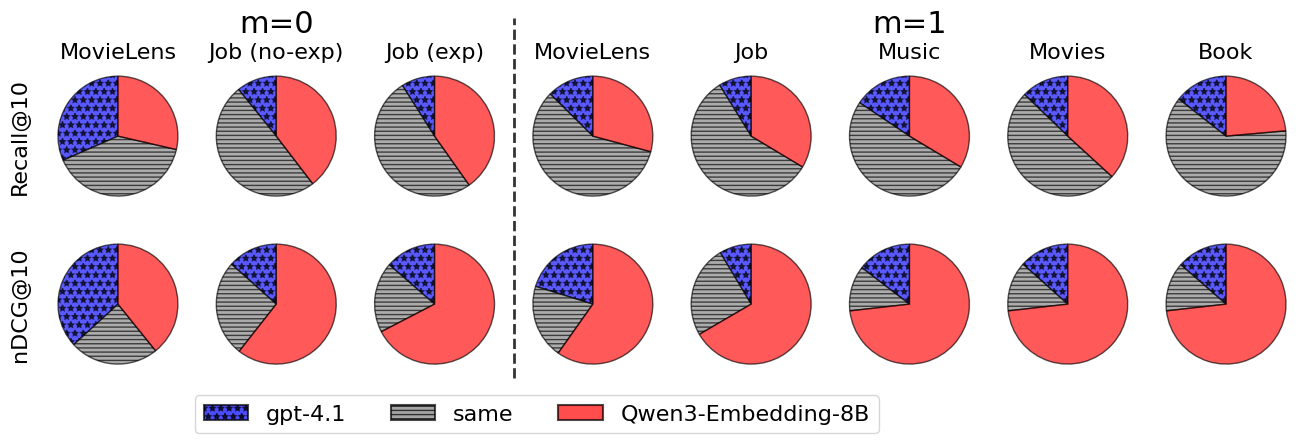
Figure 1: Per-user win/loss distributions reveal that TEMs exceeded LLMs for the majority of the population; only a small minority of users exhibited improved LLM performance.
- The error analysis at the user granularity indicated that advantages of LLM reranking were restricted to a small segment of the population, with TEMs dominating on both median and aggregate metrics.
- When varying the number of user interactions or reducing candidate pool size (from 50 to 10), the superiority of TEMs persisted. LLM rerankers did not demonstrate a crossover point where they exceeded TEMs, meaning context length or interaction sparsity were not primary limiting factors.
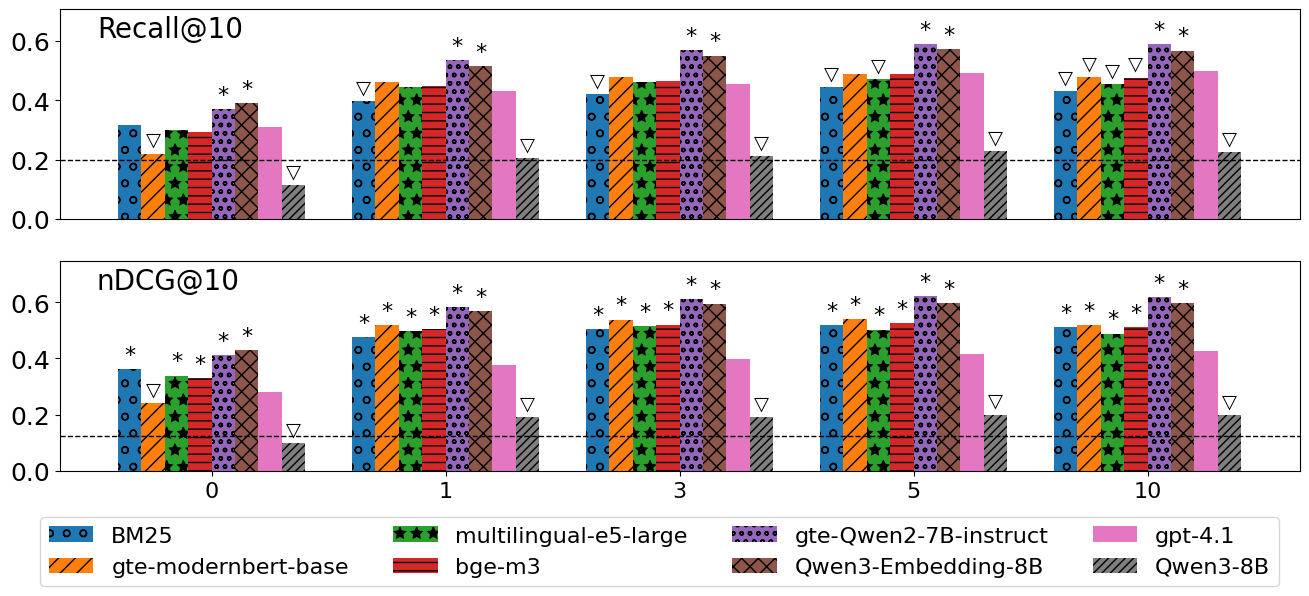
Figure 2: Mean Recall@10/nDCG@10 vs. interaction count m confirms that higher m boosts all models, with TEMs achieving and maintaining the leading accuracy.
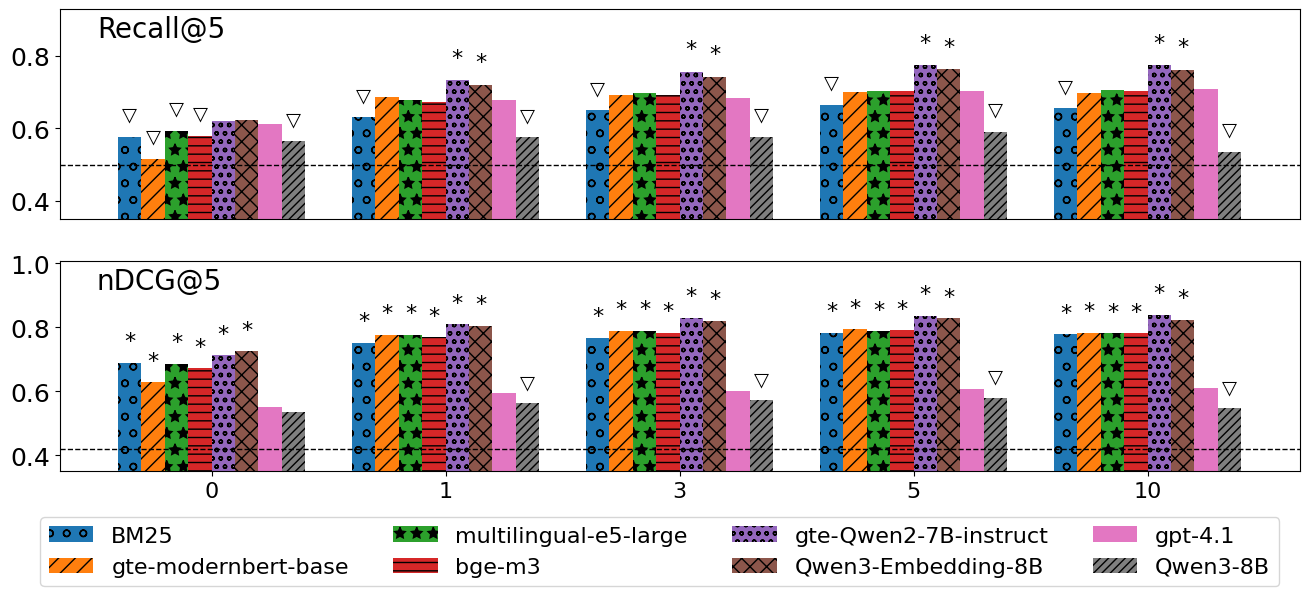
Figure 3: On reduced candidate sets (∣L∣=10), LLMs and TEMs narrow in recall under extreme sparsity, but overall trends remain unchanged.
- In cross-domain cold-start scenarios, where user behaviors stem from a different domain than the target, TEMs maintained their edge over LLM rerankers (see Figure 4).
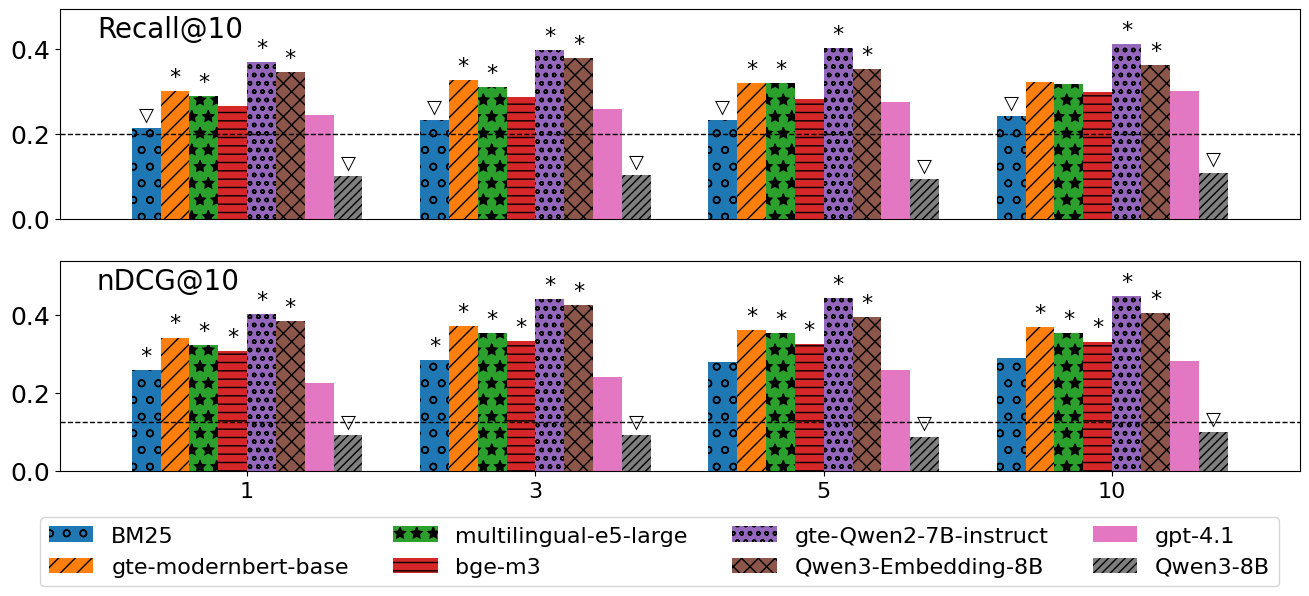
Figure 4: In cross-domain TFCSR, TEMs again outperform LLM-based reranking across Music-Movie, Movie-Book, and variant settings.
- Hybrid user/item representation strategies, such as generative query expansion with LLMs at inference (i.e., creating synthetic queries per user/item and aggregating embeddings), yielded only minor improvements for weak base models and did not challenge the top-line performance of LLM-supervised TEMs.
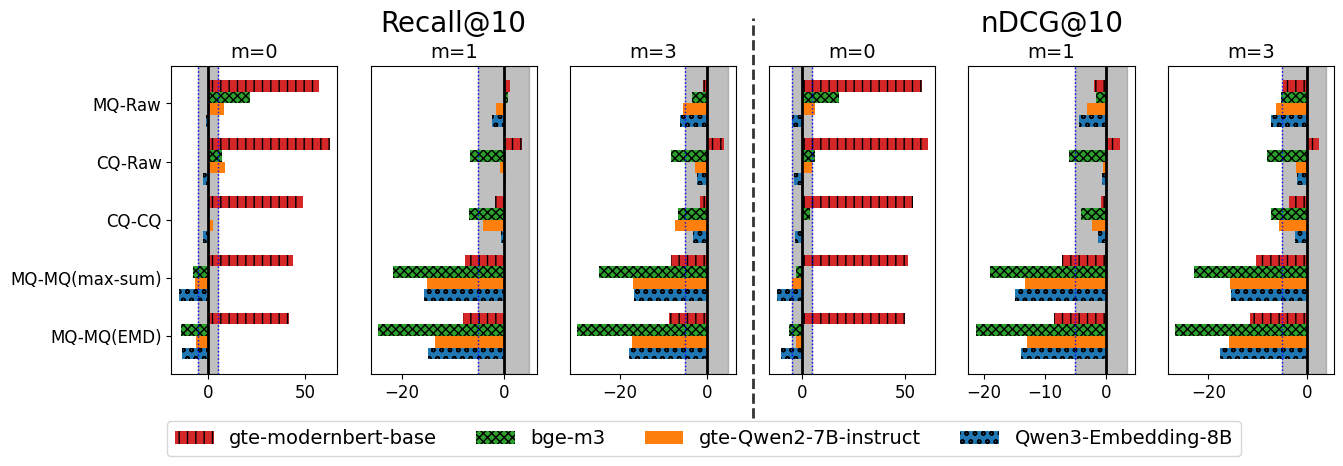
Figure 5: Relative gains from hybrid or expansion methods over vanilla TEMs are generally minor and sometimes negative for strong base models.
Implications and Limitations
The empirical results yield several authoritative conclusions:
- TFCSR requires semantic generalization well beyond what LLM reranking offers, especially when strong domain-agnostic embeddings are available.
- Even the most advanced LLMs, when used solely as inference-time rerankers without fine-tuning or large-scale context optimization, do not provide a practical alternative to modern TEMs for cold-start recommendation.
- LLM-supervised embedding models (e.g., Qwen3-Embedding-8B) harness the knowledge and reasoning capacity of LLMs more effectively by distilling it into scalable vector spaces, providing both efficiency and accuracy at deployment time.
- Query expansion and hybrid approaches offer marginal gains primarily for non-LLM-supervised embedding models and have an upper bound imposed by the quality of the base representations.
From a practical standpoint, TEMs offer lower inference cost, greater scalability (as candidate sets grow), and more favorable hardware throughput compared to LLMs, especially under realistic latency constraints (e.g., user-facing deployments).
On the other hand, there are cautionary notes regarding:
- The use of synthetic pretraining data for LLM-supervised TEMs, which may induce domain bias or hallucination artifacts, particularly in niche or long-tail settings.
- The need for further research into integration of structured side information (e.g., attribute-value profiles, hierarchical taxonomies) within LLM/TEM architectures to enhance their robustness and interpretability for enterprise-grade cold-start recommendation.
Theoretical and Future Directions
The findings call for a nuanced reassessment of LLMs’ role in TFCSR. Rather than direct reranking, LLMs are best leveraged as teachers in supervision pipelines, where their inductive biases can be distilled for downstream, scalable model variants. This paradigm may extend to reinforcement learning from LLM-based reward signals, dynamic user modelling, or continual learning scenarios where base embeddings are periodically refreshed with supervision from evolving LLMs (domain adaptation).
Furthermore, the extrapolation to supervised and hybrid recommendation architectures is promising. Many older collaborative–content fusion models used classic, non-LLM-based embeddings as initialization for cold-start, then layered in behavioral context as it accumulated. Plugging in powerful, LLM-supervised TEMs as the initialization layer in such architectures could provide a step-function increase in cold-start recommendation quality, both in zero-shot and warm-start phases.
Conclusion
The comparative evaluation unequivocally establishes that TEMs trained with LLM supervision are more effective and more scalable than direct LLM reranking for training-free cold-start recommendation, across both in-domain and cross-domain use cases. While LLMs offer compelling few-shot and reasoning abilities, their utility is maximized as distillers of semantic information into embedding models, rather than as inference-time core recommenders. Future improvements should focus on integrating structured user/item information, addressing possible biases in synthetic supervision, and deploying TEMs as foundational layers within larger, multi-stage recommender pipelines.