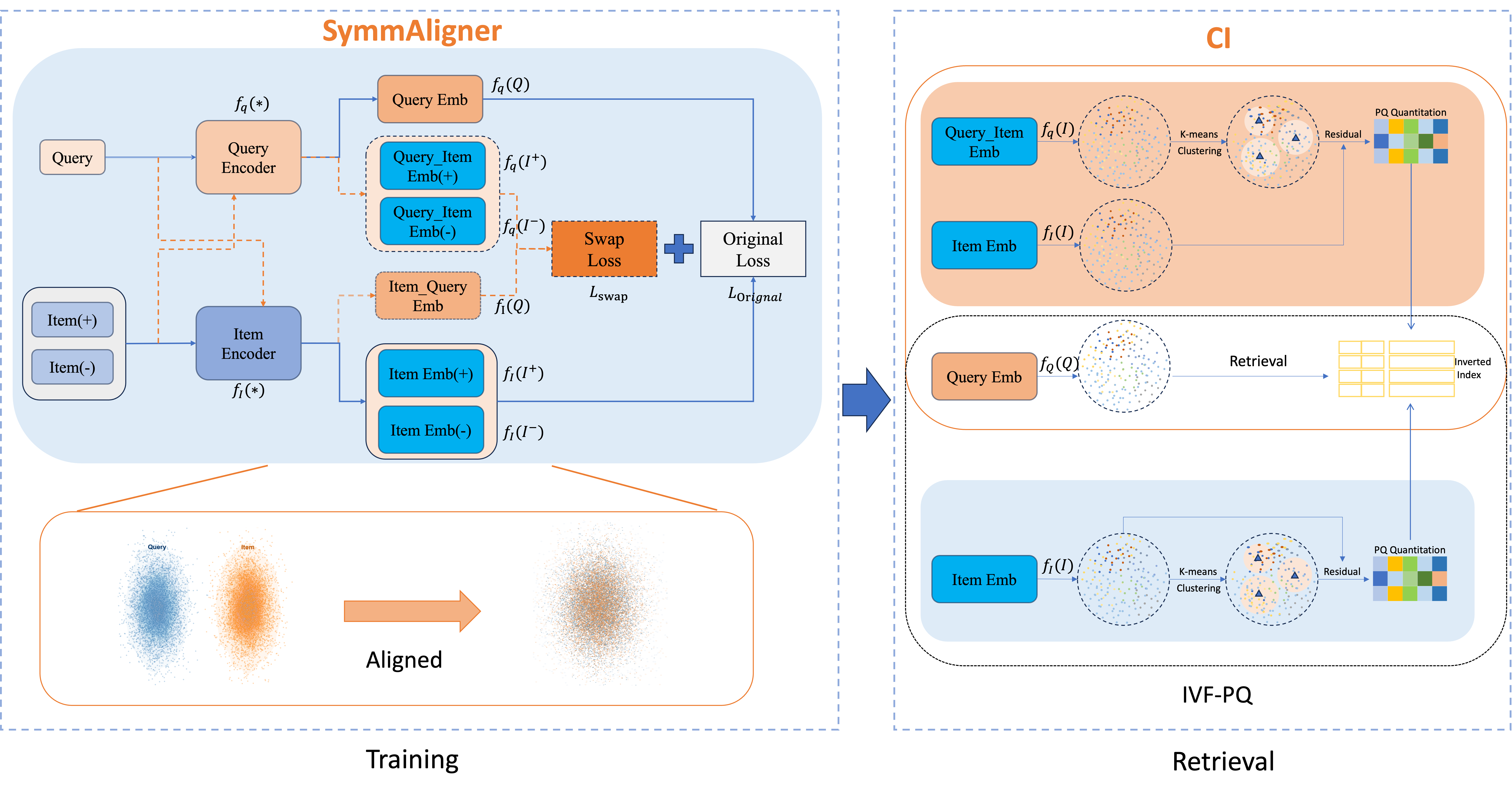
- The paper introduces SCI to address representation misalignment by enforcing symmetric joint optimization in dual-tower dense retrieval systems.
- It proposes two core modules, SymmAligner and CI, which respectively align embeddings and unify indexing for improved ANN retrieval consistency.
- Experimental results demonstrate significant gains in metrics like MRR and NDCG on benchmarks such as MS MARCO and industrial datasets, while reducing compute overhead.
Symmetric Consistent Indexing for Large-Scale Dense Retrieval: SCI Framework Analysis
Introduction and Motivation
Large-scale dense retrieval systems are foundational in information retrieval and recommendation, providing millisecond-level response across billion-scale corpora. Coarse-to-fine architectures—typically built on dual-tower encoders enabling Approximate Nearest Neighbor (ANN) search—form the backbone of these systems. However, the standard dual-tower design systematically induces representation space misalignment between queries and items, resulting in retrieval index inconsistency. These structural failures degrade matching precision, reduce retrieval stability, and enforce a notable performance ceiling, especially evident in long-tail query resolution and semantic ID generation for generative recommenders.
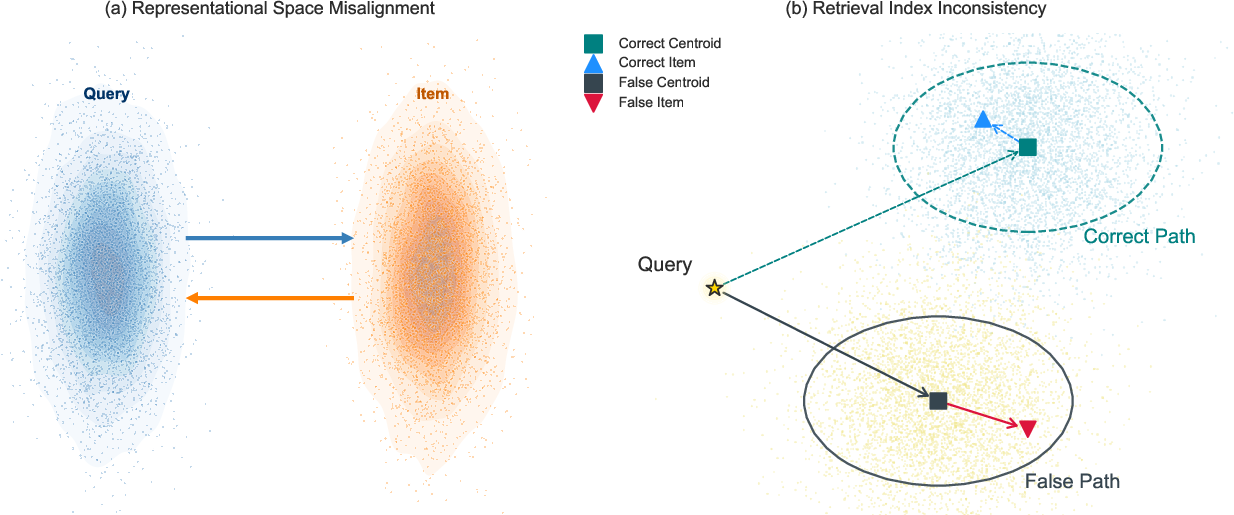
Figure 1: Space misalignment and index inconsistency induced by classic dual-tower retrieval pipelines.
In response, this work introduces Symmetric Consistent Indexing (SCI), a systematic and practical framework that directly targets end-to-end representation and indexing incompatibility without architectural entanglement or expensive model coupling. SCI consists of Symmetric Representation Alignment (SymmAligner) and Consistent Indexing with Dual-Tower Synergy (CI), jointly mediating vector space alignment and consistent ANN indexing.
Core Methodology
Symmetric Representation Alignment (SymmAligner)
The central limitation of dual-tower architectures is the statistical and geometric drift between the independently optimized query encoder fq and item encoder fi. Existing mitigation strategies (e.g., hard negative mining, cross-tower distillation, late interaction) do not systematically correct this foundational misalignment.
SymmAligner introduces an input-swapping mechanism, enforcing a symmetric constraint:
- For a sample (Q,I+,I−), compute embeddings of Q using both towers and likewise for I±.
- Define a swap loss Lswap mirroring the triplet loss, swapping tower roles on each input.
- Jointly optimize the standard and swap losses with a tunable hyperparameter λ:
Ltotal=(1−λ)Loriginal+λLswap
Theoretical analysis demonstrates that the gradients from the two objectives are linearly independent under realistic assumptions, ensuring robust bidirectional alignment signals. This symmetric regularization:
Consistent Indexing with Dual-Tower Synergy (CI)
Beyond learning, misalignment between towers corrupts the ANN index construction and query path, as indices are built on item-tower vectors but queried with query-tower embeddings. CI corrects this by:
- Using the query encoder fq to generate all item embeddings for coarse clustering (e.g., IVF centroids).
- Within each cluster, residual quantization leverages item-tower representations fi to encode fine-grained details.
- During retrieval, queries are encoded solely by fq and search proceeds in this unified structure, maintaining full compatibility from encoding to inference.
This approach can be generalized beyond IVF-PQ to other ANN families (OPQ, HNSW), as coarse routing always occurs in the query-tower-aligned space, guaranteeing consistency with learned semantics.
Experimental Findings
SCI substantially and consistently outperforms standard dual-tower models and competitive sparse/dense retrieval baselines on both public benchmarks (e.g., MS MARCO) and industrial-scale (10M+ samples) e-commerce datasets.
Key quantitative highlights:
- On MS MARCO, SCI (λ=0.3) achieves an MRR@10 of 0.448 with IVF-PQ, a relative improvement of 9.9% over the matched dual-tower baseline.
- Mean cosine similarity for annotated query-item pairs increases by 9.3% (and minimum similarity by >50%), demonstrating robust alignment throughout the space.
- In large-scale industrial settings, SCI recovers much of the performance lost in classic indexation (e.g., Recall@100 from 0.5984 to 0.6222) and yields a 9.3% increase in NDCG@100.
- Substantial gains are observed across probe counts, with SCI achieving competitive recall or MRR at smaller nprobe, thus reducing real-time compute requirements.
Implications and Discussion
SCI provides theoretical and empirical evidence for decoupled, symmetric regularization as a practically deployable enhancement for dense retrieval systems. By mitigating geometric drift between encoders and enforcing end-to-end pipeline consistency, SCI unlocks the true retrieval potential of dual-tower architectures. Its design is model-agnostic (supporting arbitrarily deep/complex encoders or multimodal inputs), has minimal engineering overhead (no architectural change, negligible training/indexing cost), and maintains full compatibility with high-performance ANN libraries.
For next-generation generative recommendation paradigms, especially those leveraging semantic ID tokenization, SCI offers a robust mechanism to maximize the expressivity and accuracy of upstream dense representations—critical as semantic ID drift is a key remaining bottleneck in model-based retrievers.
The relaxation parameter λ governs the trade-off between raw retrieval accuracy and space unification, with empirical results confirming a robust optimization regime (λ in [0.1,0.3] avoids both over-regularization and space collapse).
Future Directions
SCI naturally invites further development:
- Extending symmetric alignment to higher-order (e.g., multimodal) alignment or hierarchical index structure.
- Exploring end-to-end differentiable indexing with hybridization to unsupervised clustering or discrete representation learning (“semantic ID” optimization).
- Investigating hybrid late-interaction or adaptive dual-tower selection at inference for improved out-of-distribution robustness.
Conclusion
SCI is a systematic and principled framework that eliminates a core structural bottleneck in dual-tower dense retrieval for both classic and generative tasks. By symmetrically aligning representations and enforcing consistent coarse-to-fine ANN indexing, SCI leads to large, robust improvements in industrial and academic settings with minimal deployment friction. This work provides a direct solution for space and index misalignment, establishing a new standard practice for large-scale dense retrieval deployment.
Reference: "A Simple and Effective Framework for Symmetric Consistent Indexing in Large-Scale Dense Retrieval" (2512.13074)