- The paper presents a novel DFT architecture that integrates a decorrelation loss and graph transformer layers to explicitly reduce inter-node dependencies.
- It establishes theoretical generalization bounds by linking conditional shifts in node features to local dependency structures using Markov models.
- Empirical results across multiple benchmarks demonstrate state-of-the-art performance, with improvements in intra-class clustering and transferability.
Enhancing Node-Level Graph Domain Adaptation by Alleviating Local Dependency
Unsupervised graph domain adaptation (GDA) for node classification is fundamentally challenged by conditional shifts arising from structural dependencies in graph data. Unlike classic domain adaptation, which assumes i.i.d. samples, GDA’s inherent local dependencies in node features violate this assumption, leading to suboptimal transferability. The paper "Enhancing Node-Level Graph Domain Adaptation by Alleviating Local Dependency" (2512.13149) provides a rigorous analysis bridging conditional shift with node feature interdependencies and derives generalization bounds based on Markovian structures and dependency graphs.
The authors establish that conditional shift, where Ps(y∣G)=Pt(y∣G), necessarily implies that node features are not sampled independently. Specifically, they show under the covariate shift assumption, observing conditional shift is only possible if node representations are interdependent. They derive generalization bounds for GDA in the presence of such dependencies, demonstrating that tighter bounds are achievable when dependencies (quantified via mixing time and forest complexity) are reduced. These results highlight the critical bottleneck introduced by local feature dependencies for GDA generalization capacity.
Impact of Message Passing on Interdependency
The propagation mechanisms of canonical GNNs like GCN inherently exacerbate node representation dependencies through iterative feature mixing. Theoretical analysis in the paper demonstrates that even starting from i.i.d. node features, repeated GCN-like message passing monotonically increases inter-node feature correlations. Empirically, increasing GCN depth yields elevated correlation metrics, confirming that standard architectures intensify the very dependencies that harm domain transfer bounds.
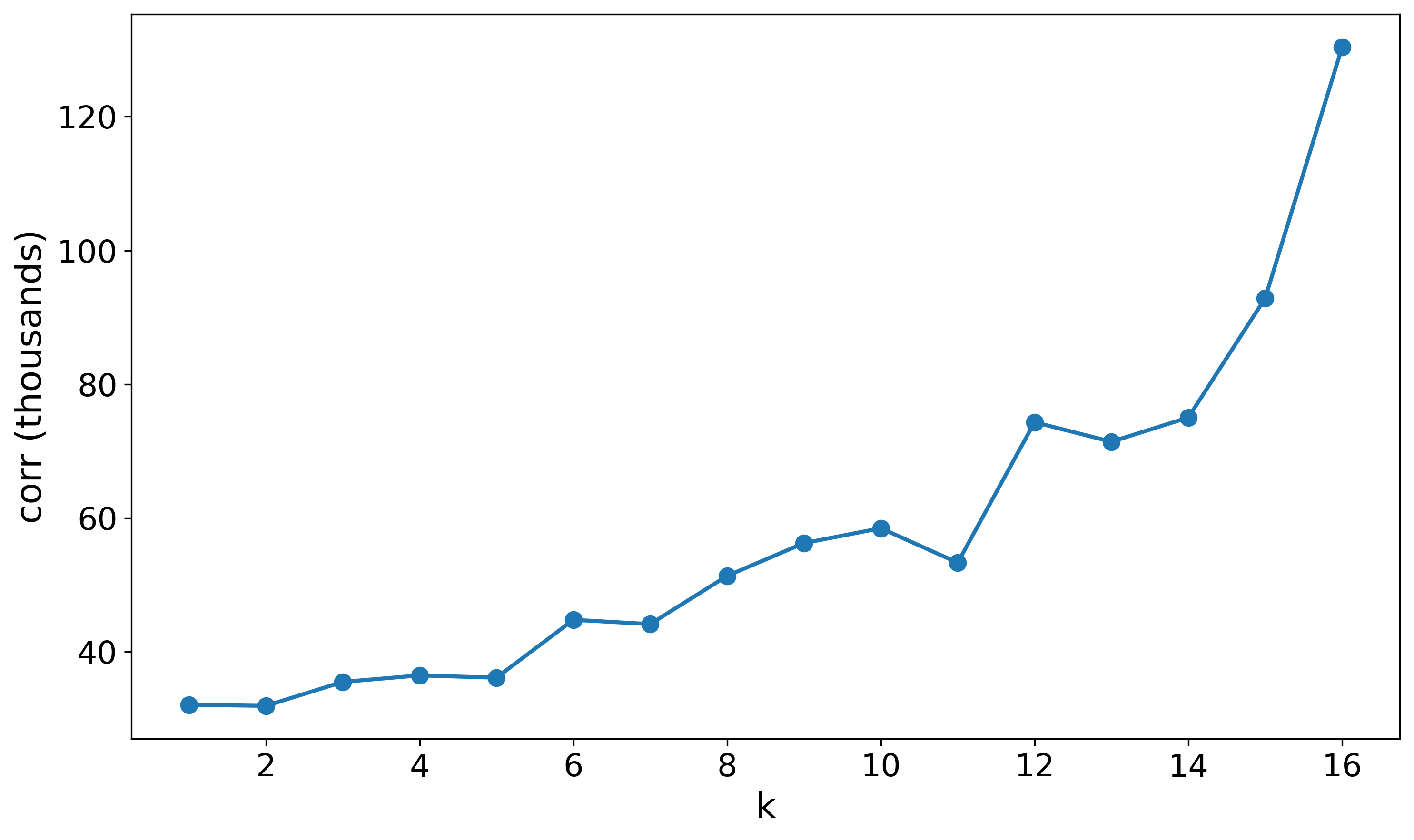
Figure 1: Correlation $E[ \|{^{(k)} {^{(k)}}^\top \|_F^2 ]$ increases monotonically with number of GCN layers k, illustrating accumulation of inter-node dependencies.
This insight motivates the need to design feature extractors that explicitly decorrelate node representations to mitigate generalization degradation in GDA.
Inspired by the theoretical findings, the paper introduces a model named Decorrelated Feature Extraction with Graph Transformer layers (DFT). The key innovation is a feature extraction module for both source and target graphs, which augments standard graph signal denoising with an explicit node-wise decorrelation penalty. This penalty, coupled with a smoothness regularizer, encourages orthogonality between node representations, directly reducing inter-node dependencies at the representation level. The decorrelated features are further processed by graph transformer layers equipped with sparse attention, enhancing the capture of global graph semantics and further relaxing local inductive biases present in message-passing schemes.
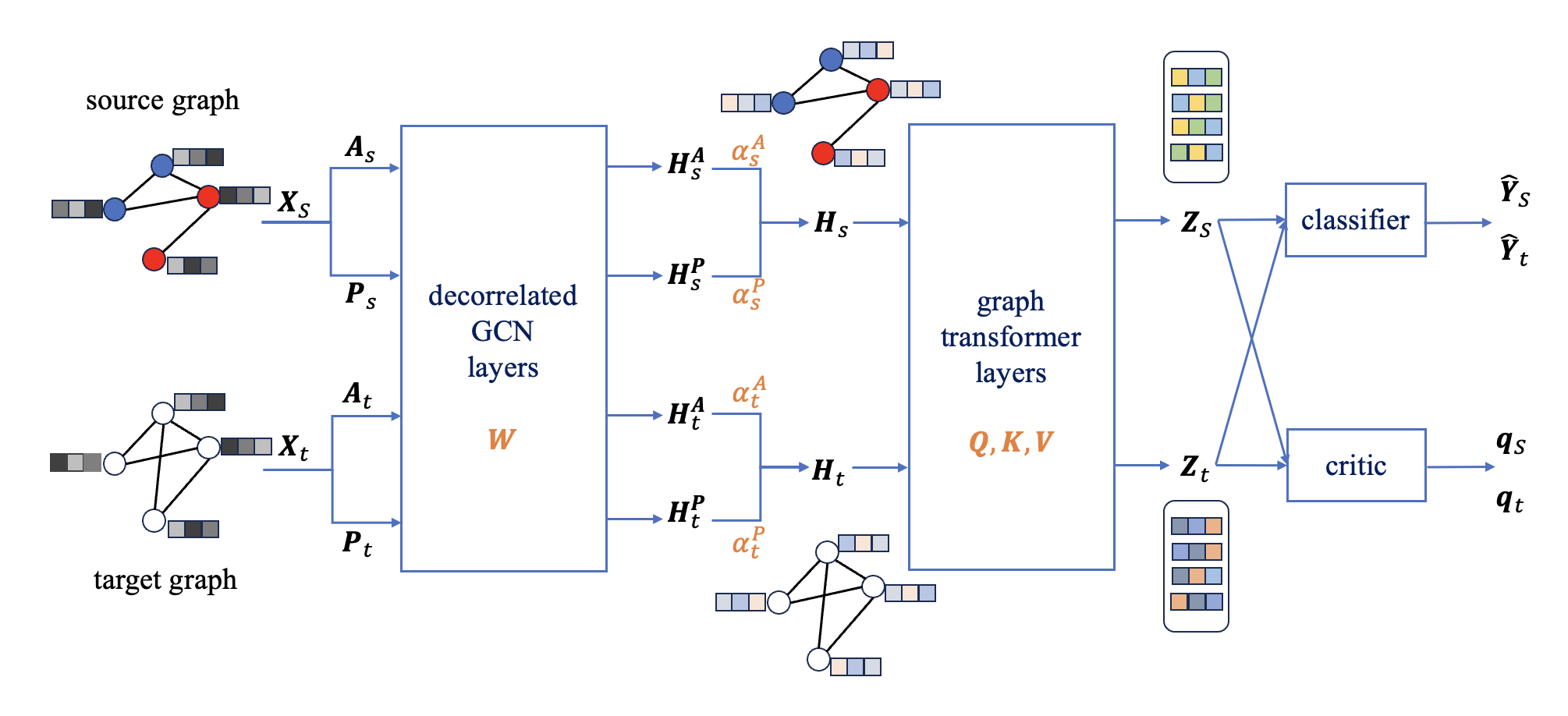
Figure 3: The DFT network architecture combines regularized decorrelated GCN and graph transformer layers for robust GDA.
The full model follows an adversarial domain adaptation framework, where a feature extractor and a classifier, shared across domains, are trained to maximize classification performance on the source while a domain critic aligns the representation distributions via a Wasserstein objective. DFT replaces the GCN layers in the classical UDAGCN backbone with decorrelated propagation layers and incorporates deep transformer modules for additional expressivity.
Empirical Results and Ablation Analysis
Experimental evaluation is conducted across multiple cross-network node classification benchmarks: temporal citation networks (DBLPv7, Citationv1, ACMv9), BlogCatalog-derived social networks, and a customized split of Pubmed. Across all transfer tasks, DFT achieves state-of-the-art results, exhibiting clear margins over prior adversarial GDA methods (DANN, AdaGCN, UDAGCN), spectral regularized GNNs, and recently-proposed structure-aware and label-alignment methods.
Qualitative visualizations via 2D embedding projection (t-SNE) demonstrate that DFT induces notably tighter intra-class clusters and larger inter-class margins in the target domain compared to baselines.
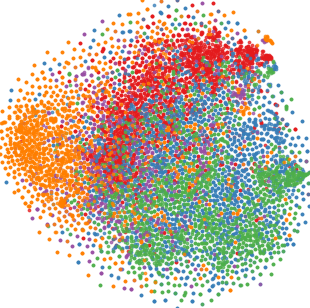
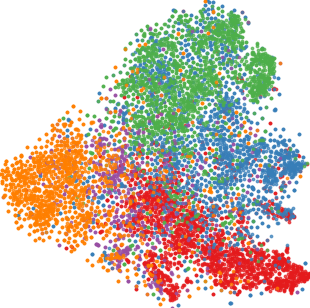
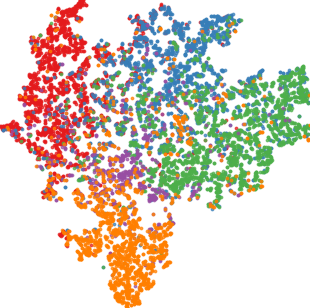



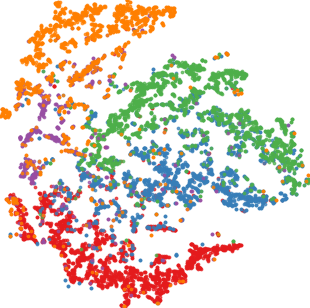


Figure 4: t-SNE representations for all methods on D → C. DFT yields best class separability and compactness.
Quantitative analysis using the intra-class distance ratio (ICDR) corroborates this, with DFT producing the lowest ratios (i.e., tightest intra-class feature packing). Silhouette scores of DFT also dominate, indicating strong unsupervised clusterability aligned with ground-truth classes.
Thorough ablation studies confirm that removing either the decorrelation loss or transformer layers results in significant performance drops, but each component independently improves over the baseline. Feature decorrelation is shown beneficial even when integrated into alternative GDA backbones (e.g., AdaGCN), demonstrating architectural generalizability.
Hyperparameter Sensitivity
The method’s performance is robust to the smoothing and decorrelation penalties and the gradient step size, indicating practical deployability across diverse graph domains.
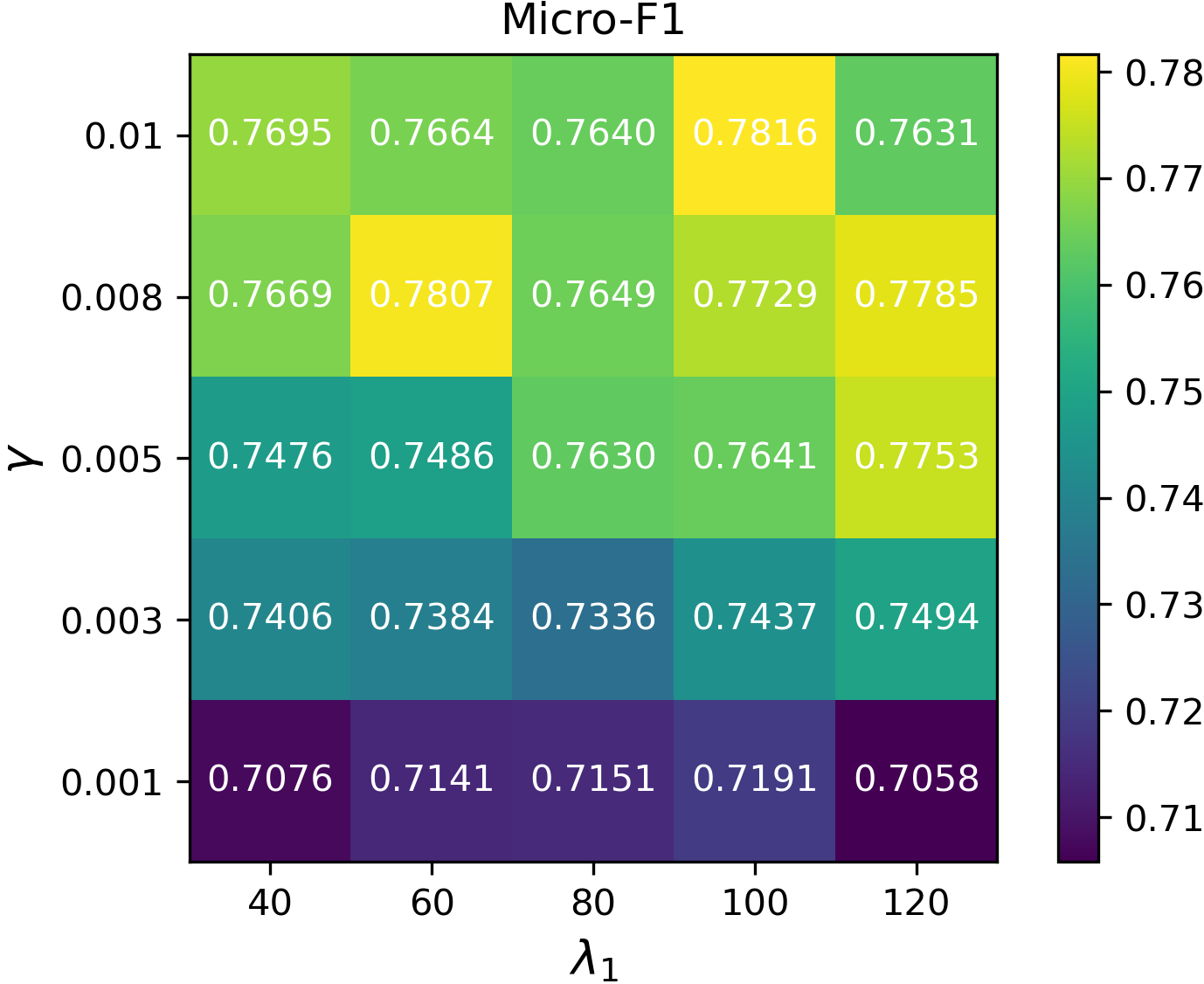
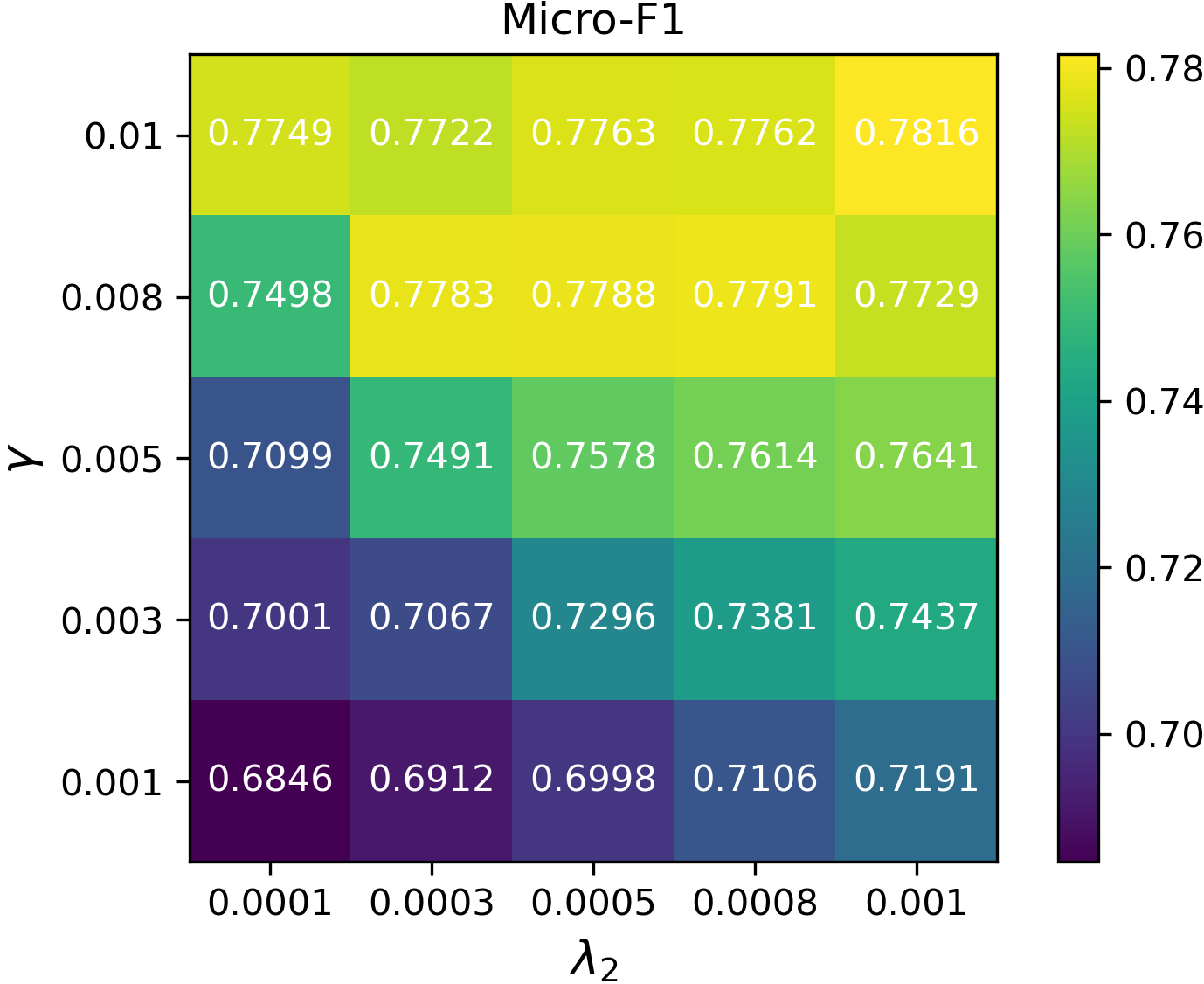
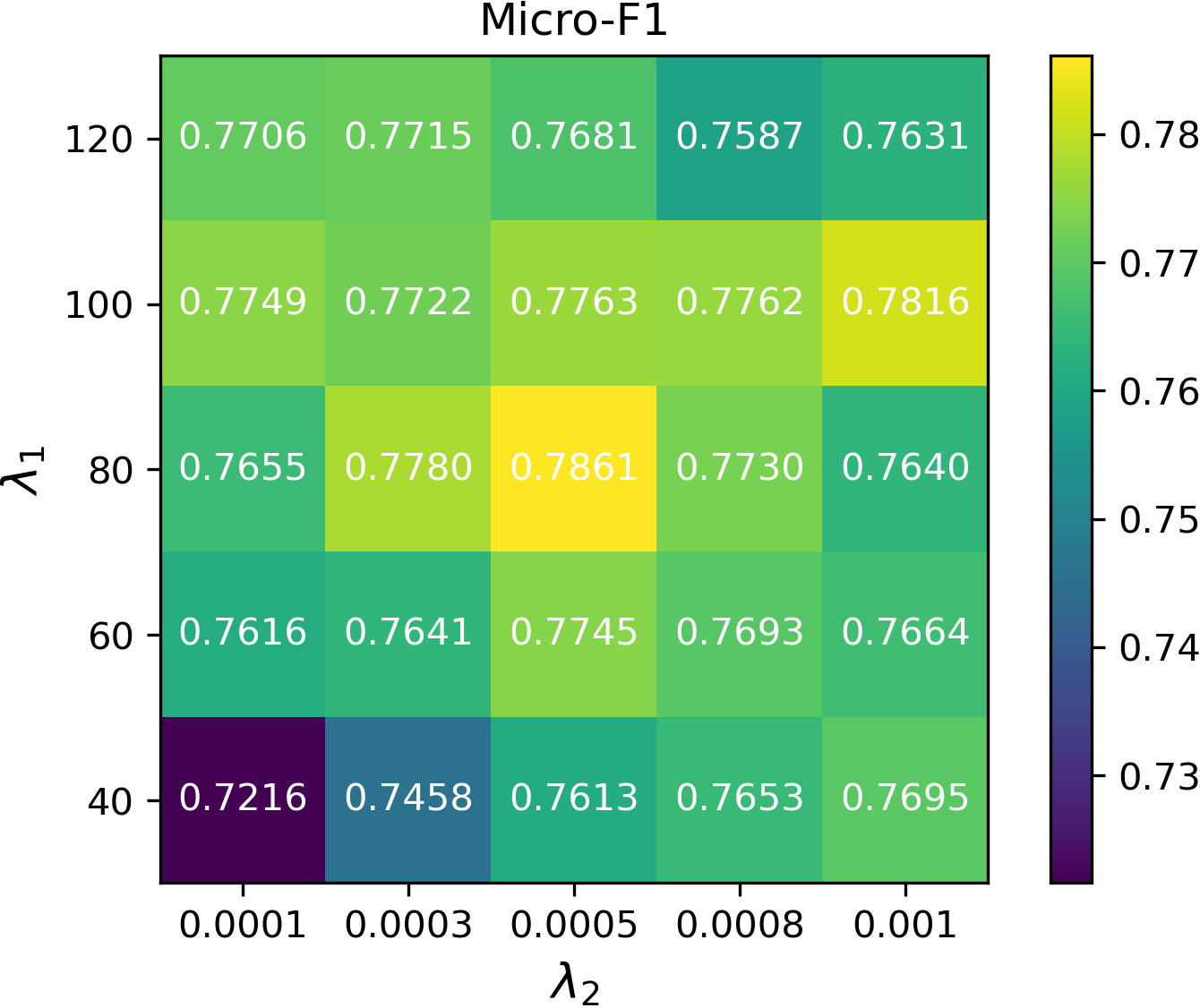
Figure 2: Micro-F1 sensitivity curves for DFT with respect to γ, λ1 (smoothness weight), and λ2 (decorrelation weight).
Practical and Theoretical Implications
These findings have multiple implications:
- Architectural design: Alleviating local dependencies—via explicit decorrelation regularization—is critical for improving GNN-based cross-domain generalization. Architectural modifications targeted at inter-node independence yield stronger transferability.
- Role of graph transformers: Self-attention-based graph transformers effectively incorporate long-range dependencies and alleviate local message-passing bottlenecks, further boosting transfer robustness in heterogeneous graphs.
- Reevaluating backbone choices: Standard message-passing GNNs, when naïvely applied, can amplify conditional shift effects due to dependency propagation, necessitating more decorrelated or globally-attentive backbones for GDA.
The theoretical generalization bounds formalized in the paper provide guidance for future research, suggesting that metrics such as mixing time and dependency graph complexity can inform architecture or pre-processing choices in domain adaptation scenarios.
Future Directions
The approach motivates several future lines:
- Extending decorrelation techniques to graph-level domain adaptation or dynamic graph settings where dependencies evolve.
- Applying similar inter-node decorrelation principles for domain transfer in other structured, non-i.i.d. modalities (e.g., temporal, spatial, or hierarchical data).
- Investigating tighter bounds or adaptive regularization mechanisms based on dependency structure learning.
Conclusion
By establishing the connection between conditional shifts and inter-node dependencies, providing tight generalization bounds under realistic dependency models, and demonstrating that explicit decorrelation in feature extraction and global self-attention yield superior transferability, this work sets a new baseline for node-level graph domain adaptation (2512.13149). The results advocate for dependency-aware GNN architectures as a foundation for robust representation transfer between heterogeneous graph domains.