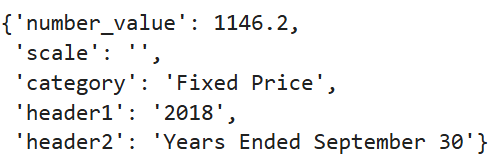
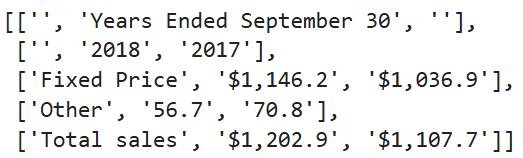- The paper introduces an error-driven prompt optimization method that uses code generation to improve arithmetic reasoning for sensitive tabular QA.
- It employs a semi-automated rule induction process, achieving an exact-match accuracy increase from 59.96% to 70.82% on the TAT-QA dataset.
- This approach ensures robust, privacy-compliant operation in regulated sectors, enabling on-premises small language models to outperform larger LLMs.
Error-Driven Prompt Optimization for Arithmetic Reasoning: A Code Generation Approach for On-Premises Small LLMs
Introduction
The paper "Error-Driven Prompt Optimization for Arithmetic Reasoning" (2512.13323) presents a rigorous framework targeting the persistent challenge of accurate arithmetic reasoning in QA over tabular data, especially in privacy-sensitive domains such as finance. Recognizing the inadequacy of both API-dependent LLMs (which are impractical in regulated sectors) and the out-of-the-box capabilities of on-premises SLMs for numeric tasks, the authors propose a hybrid solution. This approach leverages a Code Generation Agent (CGA) paradigm, paired with a semi-automated, error-driven rule induction method, enabling SLMs—specifically, Qwen3 4B—to attain and surpass the numerical accuracy of significantly larger LLMs like GPT-3.5 Turbo for tabular arithmetic.
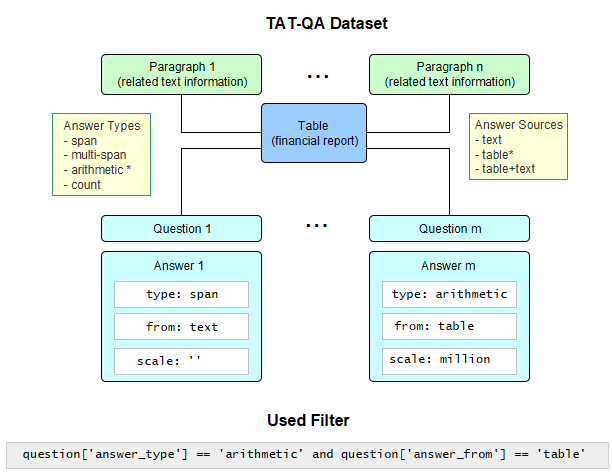
Figure 1: Structure of the TAT-QA dataset and the applied filter.
Dataset and Preprocessing
The paper utilizes the TAT-QA dataset due to its detailed arithmetic derivations in financial QA tasks, supporting fine-grained error analysis. The dataset is first filtered to include only purely arithmetic questions on tabular content, reducing complexity by excluding hybrid text-table reasoning. Further, the authors apply a sequence of table restructuring steps:
This preprocessing is foundational to the CGA pipeline, ensuring all input to the LLM is contextually aligned and machine-consumable.
Methodology: Code Generation Agent and Error-Driven Prompt Extension
The CGA approach reframes QA as code synthesis: the model is prompted to generate executable Python functions that extract and compute answers from the restructured tables. The execution of generated code is deterministic, offloading arithmetic computation from the SLM to an interpreter, thus circumnavigating internal numerical instability issues of LLMs/SLMs.
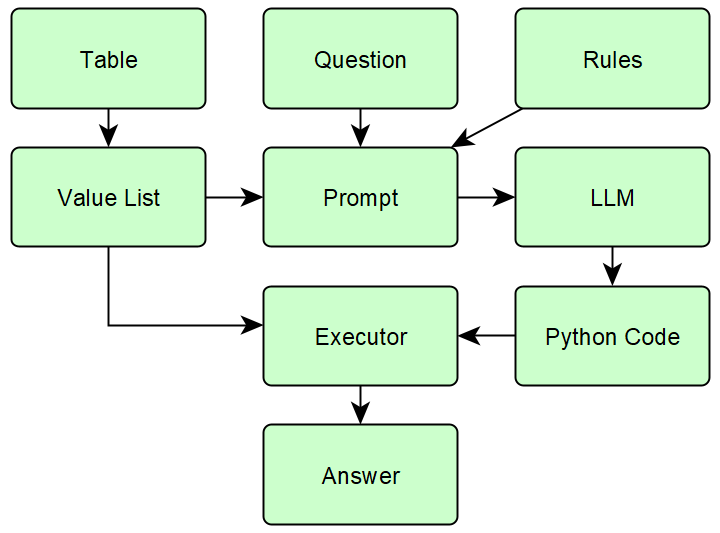
Figure 4: Overview of the process in Code Generation Agent.
To enhance reasoning accuracy, particularly in the context of underpowered SLMs, the authors introduce an iterative, error-driven prompt optimization framework:
- Error clustering: After inference, erroneous model predictions are clustered using HDBSCAN on featurized error vectors, including operation types, value and scale mismatches, and error codes (e.g., calculation, scale, sign, selection, syntax, runtime).
- Rule extraction and validation: The most populous error clusters are repeatedly converted into natural language domain-specific prompt rules (DSPR) via expert-in-the-loop interventions.
- Quantitative gatekeeping: New rules are accepted only if they achieve a significant error reduction (ΔEM ≥ 50%) in their cluster and pass a McNemar test (p ≤ 0.0625).
- Prompt compactness: Optimization seeks the minimal effective rule set, sublinear in the number of error modes, to avoid overloading the SLM with cognitive burden or conflicting directives.
This yields a globally optimized prompt, robust to error patterns and tailored to the arithmetic demands of the dataset.
Experimental Results
Empirical evaluation clearly demonstrates the efficacy of this methodology. Using the filtered TAT-QA set, SLM performance—measured in exact-match (EM) and value-only accuracy—is benchmarked before and after each prompt optimization iteration:
- Base SLM performance (no prompt rules): Qwen3 4B achieves EM 59.96%.
- After error-driven prompt extension (final): EM rises to 70.82%, exceeding GPT-3.5 Turbo (66.27%).
- Key rules identified: e.g., enforcing 'percent' scale for 'percentage change', handling 'change in percentage' as subtraction, and specific instructions for 'year average' computation.
Visualization of error transition matrices after each rule addition (cross-tab heatmaps) confirms the redirection and substantial reduction of failure modes.

Figure 5: Cross-tab heatmap of the calculation pattern on error type, when no rules are present in the prompt.

Figure 6: Cross-tab heatmap of the calculation pattern on error type, when one rule is added into the prompt that forces a percent scale for percentage change calculations.

Figure 7: Cross-tab heatmap of the calculation pattern on error type, when a rule is added to calculate the change in percentage as subtraction.

Figure 8: Cross-tab heatmap of the calculation pattern on error type, when a rule is added to calculate the year average into the prompt.
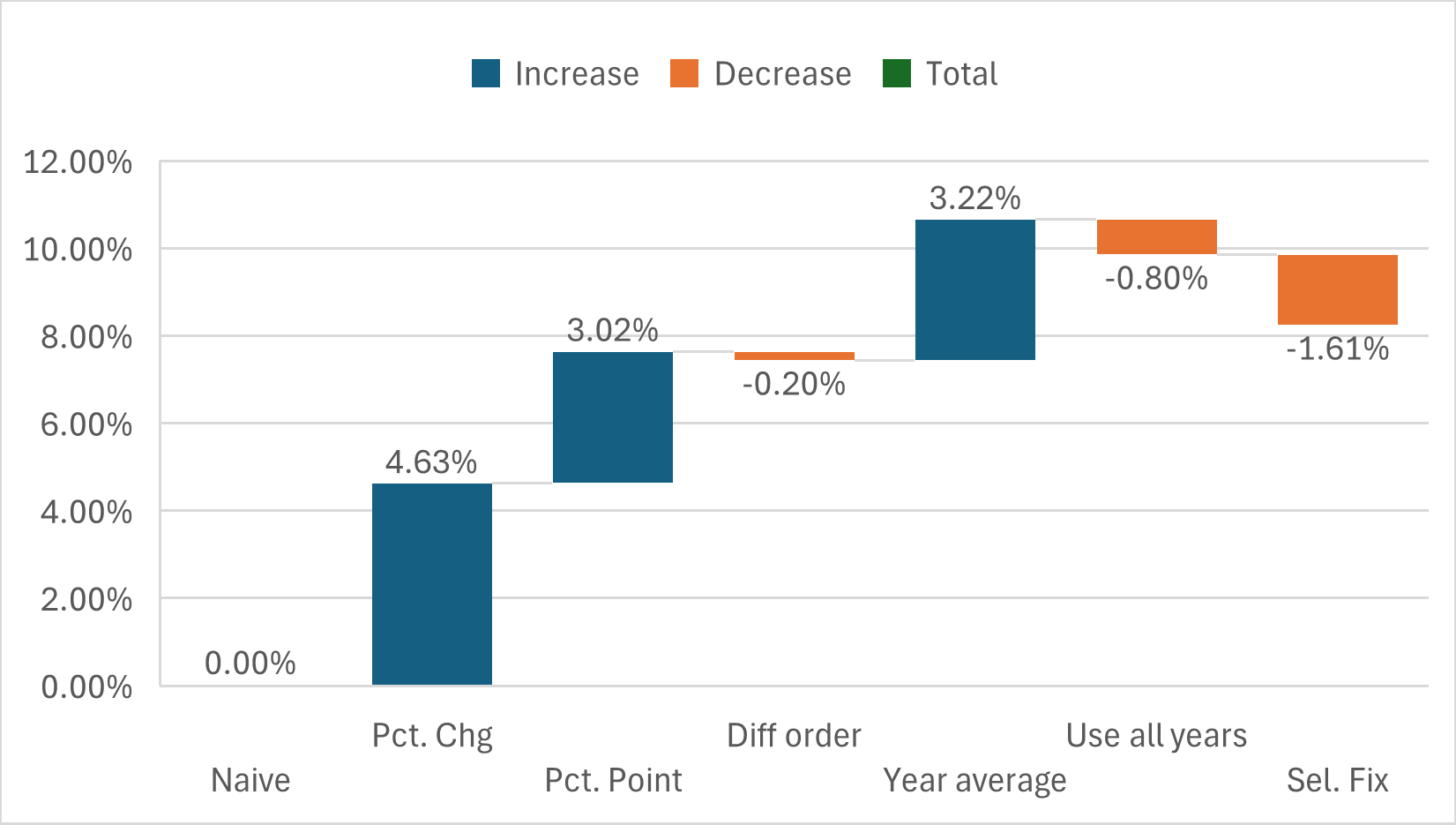
Figure 9: Prompt Extending Algorithm iterations with rules. Impact of rules on global performance
A salient discovery is the existence of an empirically optimal prompt rule count Kopt, where further rules lead to diminishing return or worsen performance due to cognitive overload and internal conflicts.
Implications and Future Directions
The work establishes a powerful paradigm for deploying privacy-compliant, auditable, and efficient arithmetic reasoning agents completely on-premises without resorting to large, opaque, API-dependent models. The integration of error-driven prompt optimization with code-generation decomposition bridges the gap between model interpretability, accuracy, and regulatory suitability.
Practical Impact:
- Deployment: Enables practical AI agents for financial analytics or healthcare, with strong auditability trails and no data leakage.
- Sustainability: SLMs require dramatically less hardware and energy than LLMs, reducing operational costs.
Theoretical Implications:
- Prompt engineering as regularization: Imposes a new optimality constraint balancing informativeness with cognitive load—analogous to model complexity control in statistical learning.
- Task factorization: Decoupling semantic parsing from arithmetic computation appears essential when model scale or in-domain fine-tuning is constrained.
Directions for Future Research:
- Automation: While rule induction is partly expert-driven, further research could target end-to-end automation using explainable AI techniques.
- Domain transfer: Generalization to domains beyond finance or to more complex (multi-modal, hybrid) datasets remains open.
- Comparative benchmarking: Integration with alternative reasoning frameworks, such as tool-augmented LLMs or neural-symbolic systems, could further clarify the boundaries of prompt optimization versus model finetuning.
Conclusion
This work decisively demonstrates that prompt-based, iterative, error-driven rule induction—when paired with programmatic reasoning via code generation—can unlock the arithmetic abilities of small LMs for tabular QA, achieving and exceeding the accuracy of much larger models while maintaining privacy and interpretability. The findings underscore that SLM optimization requires a discipline distinct from that developed for LLMs, informed by systematic error analysis and prompt minimalism. Future advances are anticipated in automated rule discovery and cross-domain generalization, extending the utility of this approach to even broader AI applications.