- The paper introduces T3-Video, a plug-and-play Transformer modification that replaces standard self-attention with a multi-scale, shared window algorithm to drastically reduce computational costs.
- The method achieves up to 43× MAC reduction and 21.4× measured latency speedup at 4K resolution, while preserving spatial and temporal consistency.
- Empirical evaluations show that T3-Video outperforms prior native 4K methods in quality metrics and enables efficient finetuning with pre-trained DiT-style models.
Motivation and Challenges of Native 4K Video Synthesis
Native 4K video generation presents an extreme computational bottleneck due to the quadratic scaling of full self-attention with respect to token count. Standard approaches circumvent this by low-resolution synthesis followed by super-resolution upscaling, yet these pipelines introduce semantic discrepancies and fail to guarantee spatial or temporal consistency at 4K. Prior attempts at native 4K generation, such as UltraWan and UltraGen, have faced limitations related to computational efficiency and qualitative performance, frequently demanding prohibitive hardware and lacking extensibility to multi-modal tasks.
The need for a Transformer-based solution that preserves architectural compatibility with the massive, pre-trained DiT-style video models, while curbing compute explosion, is therefore paramount. The T3-Video approach directly addresses this by introducing a multi-scale, weight-sharing window-attention regime that can be deployed as a drop-in replacement, enabling efficient 4K generation and maximal reuse of all pre-trained weights.
Methodology: Multi-Scale Shared Window Attention in T3-Video
The T3-Video module redefines Transformer self-attention in a manner that avoids any modification to the core backbone or weight structure, focusing solely on the attention computation pattern. The workflow comprises:
- Multi-scale window partitioning: The spatiotemporal input tensor is fragmented into non-overlapping windows at several scales, from fine local blocks to global windows that span the full sequence. For each scale, every block applies the same shared attention parameters.
- Shared-parameter attention: All scales and blocks use identical projection weights, enforcing structure-aware inductive bias while regularizing the solution space and constraining effective model capacity. This drastically reduces the computational burden per attention operation from O(L2) to O(L⋅Lb), where Lb is the window size and L the total number of tokens.
- Hierarchical blocking and axis-preserving full-attention: To eliminate artifacts from simple blocking, windowing patterns are hierarchically alternated across layers with selective preservation of full-attention along given axes, contributing to improved transition smoothness and stability during generation.
- Plug-and-play implementation: The attention logic is reparameterized as a single line of code within a standard SelfAttention module, fully compatible with all pretrained DiT-style weights.
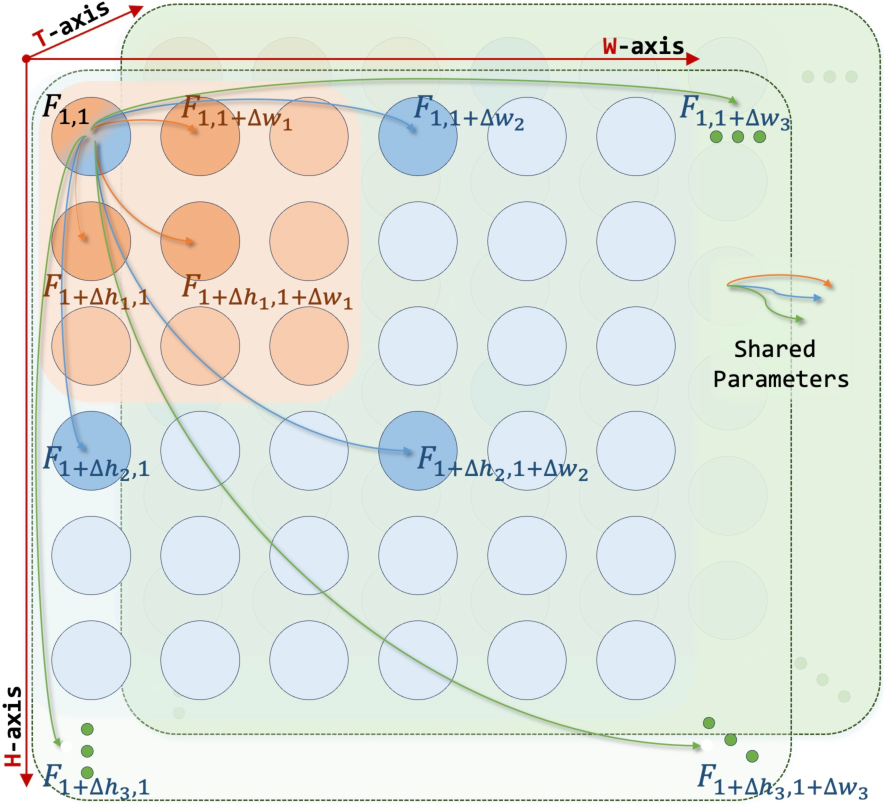
Figure 1: Intuitive diagram for the T3 strategy, illustrating multi-scale shared window attention applied at various granularities over the input token grid.
Theoretical Implications and Regularization Effects
The multi-scale shared window attention mechanism in T3-Video ensures that:
- Full attention and purely local (linear) layers are strict special cases, demonstrating that T3 is a strict superset in terms of expressive scope.
- The structured sparse windowing operates as an implicit regularizer, reducing overfitting risk by enforcing connectivity patterns in the attention matrix analogous to ℓ0-norm sparsity constraints.
- Efficient, structure-preserving finetuning becomes viable, analogous in spirit to the full-parameter efficient transfer methods in LoRA and ControlNet, but with the additional benefit of architectural safety and universal compatibility.
(T3-Video can be reverted back to a naive full-attention regime for transfer or progressive training, further exploiting the synergy between efficient pretraining and high-fidelity fine-tuning.)

Figure 2: T3-Video restores full-attention capability through the re-transform process—a step critical for efficient backbone pretraining and transferability.
Empirical Results: Efficiency and Quality at Scale
Efficiency Analysis
- Theoretical MAC Reduction: T3-Video achieves up to a 43× reduction in attention MACs at 4K resolution relative to the baseline Wan2.1-T2V-1.3B ((2512.13492), Table 1). Deployment achieves single-GPU 4K inference with under 60GB memory and one-hour runtime.
- Measured Latency: Actual inference speedups reach 21.4× at 4K (compared to official Wan2.1-T2V-1.3B), maintaining a consistent, superior acceleration as resolution increases.

Figure 3: 4K inference visualization and resource comparison for major models; T3-Video attains lower latency and higher theoretical FLOPs efficiency than UltraGen, Wan2.1, and HunyuanVideo under equal settings.

Figure 4: Training curves depicting that T3-Video adapts to spatial structure rapidly and refines details across iterative 4K fine-tuning.
Quality and Generalization
Compatibility with Deployment Optimizations
- Step/CFG Distillation: T3-Video integrates acceleration techniques such as step and CFG distillation, producing an additional ∼12.5× inference speedup with minor quality degradation.
- Efficient VAEs: eVAE variants reduce decoder cost by over 26× MACs with LPIPS increases remaining sub-threshold for perceptibility.
Human Evaluation
A professional human study yields preference rates of 71.25% (T3-Video vs. UltraGen) for overall video quality, confirming the practical impact of T3 on visually meaningful 4K video synthesis.
Analysis of Failure Modes and Limitations
Implications and Future Directions
Practical Significance
T3-Video represents a scalable, practical solution to achieving native 4K video synthesis with competitive fidelity and an order of magnitude speedup, all while maintaining seamless compatibility with the preexisting WAN/Hunyuan/Sora Transformer model ecosystem. Its plug-and-play nature and preservation of pre-trained weights maximize resource efficiency for both research and production deployments.
Theoretical Implications
The demonstration that linear-scaling, multi-scale shared window attention can preserve—and in cases, improve—both sample and text-video consistency metrics at extreme resolution is conceptually significant. The structured regularization of T3 may serve as a template for future backbone-efficient video transformers and inform architectural search for high-resolution, long-sequence generation tasks.
Future Prospects
Ongoing work will explore:
- Further software/hardware co-design to fully close the theoretical–practical efficiency gap
- Mixed-resolution training regimes to enhance model robustness and application generality
- Expansion to minute-scale 4K and enhanced temporal modeling, as well as high-resolution-specific perceptual evaluation metrics derived from foundation models.
Conclusion
The T3-Video framework establishes that plug-in full-attention transformation—rooted in multi-scale, shared window attention and hierarchical logic—enables efficient native 4K video generation with superior quality and over 10× acceleration. This approach directly addresses the compute bottleneck of vanilla Transformers at UHD scales without architectural changes, opening new horizons for the deployment and adaptability of large video diffusion models across diverse, high-fidelity media synthesis applications.

