Olmo 3
Abstract: We introduce Olmo 3, a family of state-of-the-art, fully-open LLMs at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Olmo 3, a family of powerful “open” AI LLMs. “Open” here means the authors aren’t just sharing the final models—you also get the full recipe: the data used, the code, and checkpoints from every step. The models come in two sizes (7B and 32B parameters) and are designed to:
- Reason through problems (step by step)
- Call tools or functions
- Write and understand code
- Follow instructions
- Chat and answer questions
- Handle very long documents
The main idea is to make AI research more transparent and customizable by releasing the entire “model flow,” not just the end result.
Key Questions
The paper focuses on a few big questions:
- How can we build strong, useful LLMs while making the whole process open and reproducible?
- How do we teach models to think step by step, not just guess answers?
- How can we make models faster and more direct when users just want a clear response?
- How do we give models a longer “memory” so they can handle very long documents?
- How can we make AI training more reliable and fair by avoiding test contamination (when training data accidentally contains test questions)?
Methods and Approach
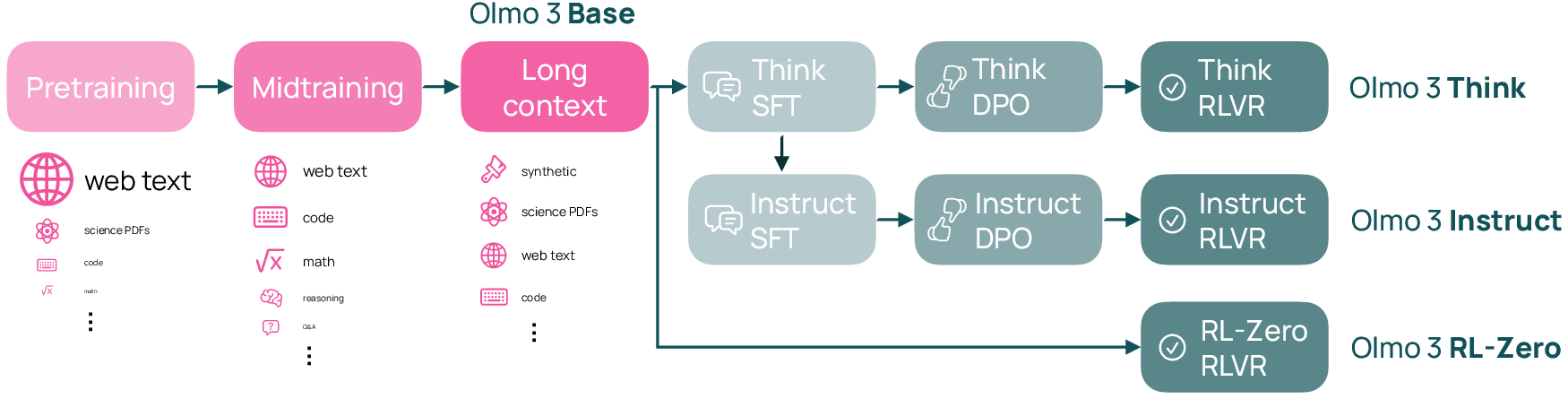
Think of Olmo 3 like building a car in stages, but the team publishes every blueprint, test log, and part list along the way. The process has two major phases:
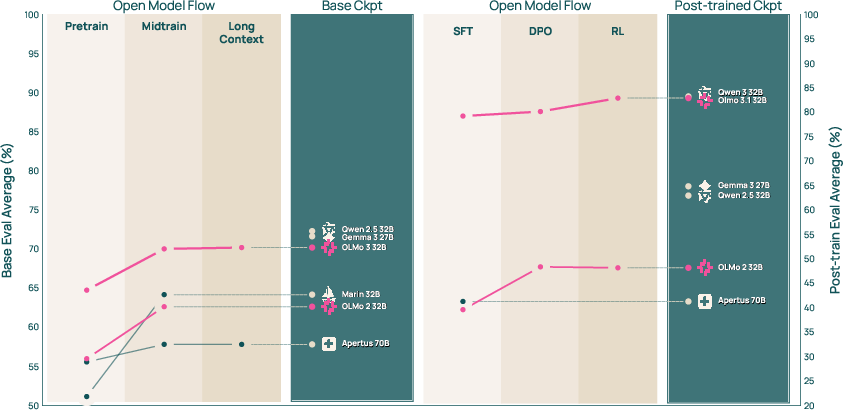
Base Model Training (building the foundation)
This phase teaches general skills. It happens in three stages:
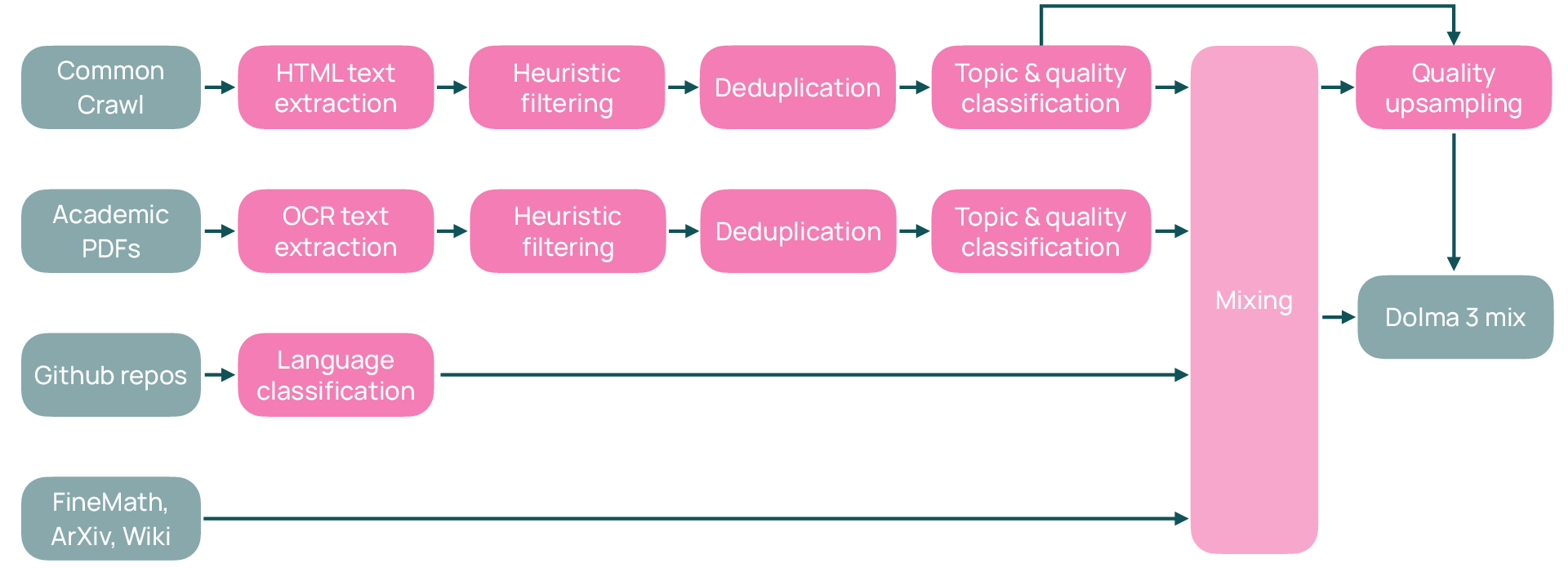
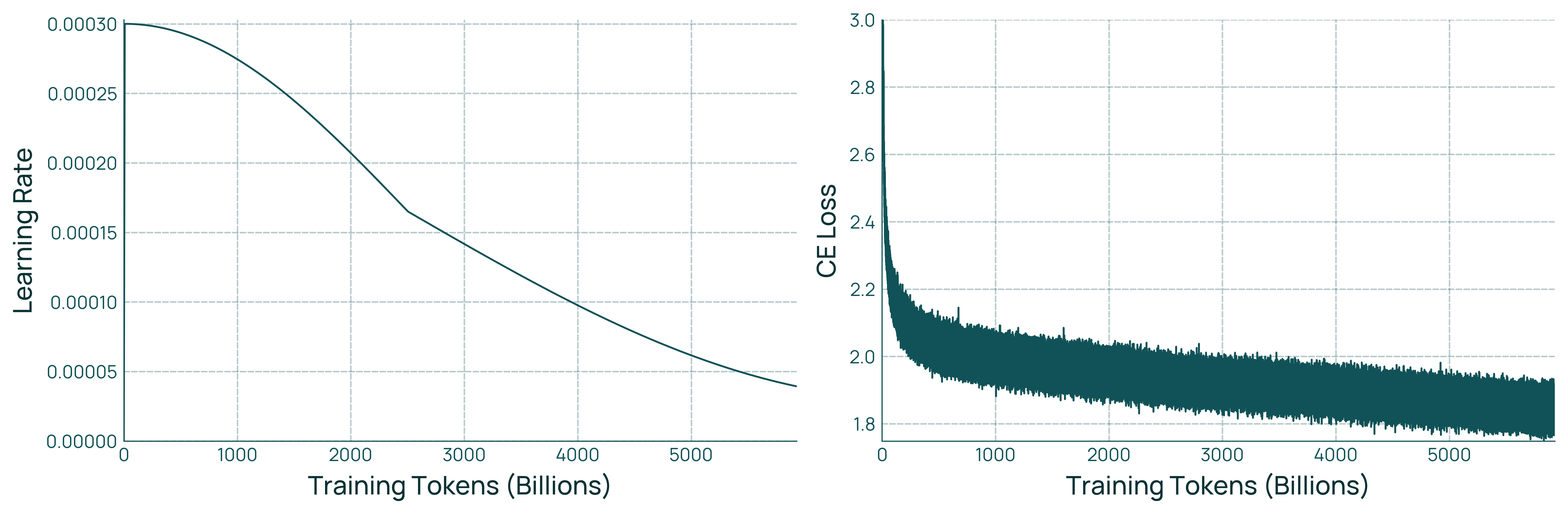
- Pretraining: The model reads a huge variety of text (web pages, academic PDFs converted with OCR, code, etc.). A “token” is a small piece of text (like part of a word). Trillions of tokens help the model learn patterns in language.
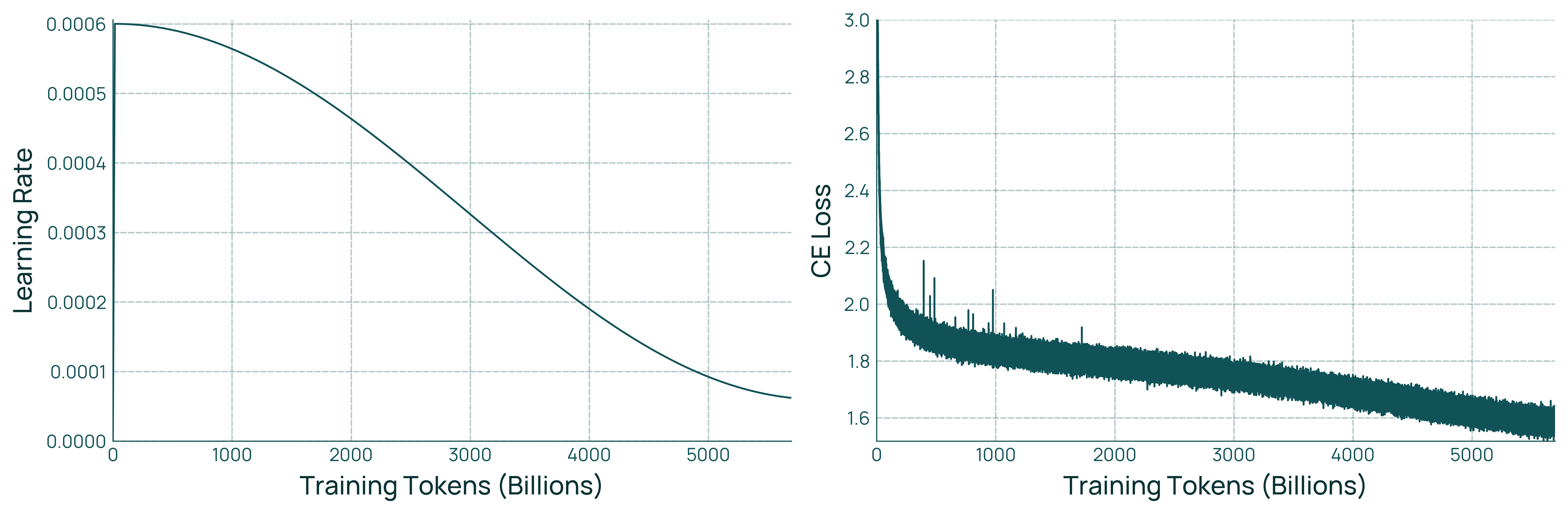
- Midtraining: The model practices targeted skills—math, coding, question answering, and instruction following—using carefully chosen datasets.
- Long-context extension: The model learns to handle very long inputs (up to about 65,000 tokens), useful for reading big documents and doing complex reasoning.
To keep training clean and efficient, they:
- Deduplicated data (removed repeated text) at massive scale.
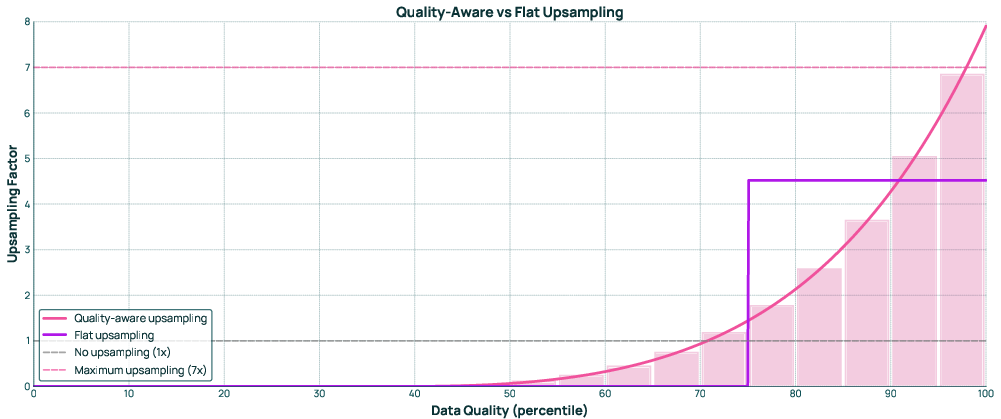
- Used quality-aware sampling (more good data, less noisy data).
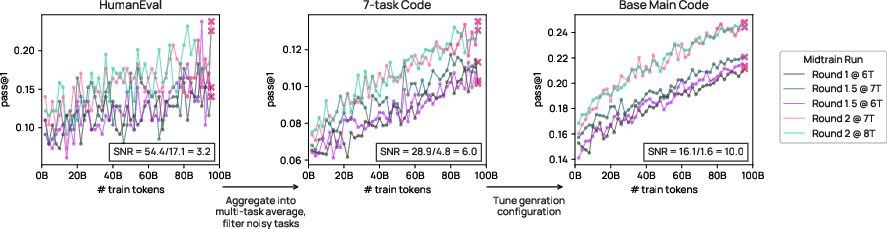
- Designed an evaluation suite (OlmoBaseEval) so small test models give reliable signals before scaling up.
Post-training (specializing the models)
This phase fine-tunes the base models for different goals:
- Olmo 3 Think: Trained to “show its work” by generating a reasoning trace before the final answer. It uses:
- SFT (Supervised Fine-Tuning): learning from examples of good step-by-step solutions.
- DPO (Direct Preference Optimization): learning from pairs of “good vs. better” answers.
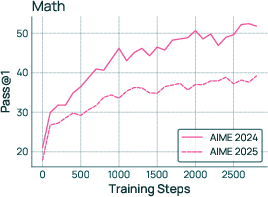
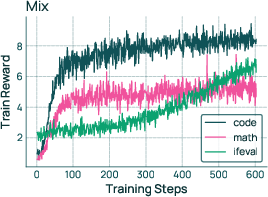
- RLVR (Reinforcement Learning with Verifiable Rewards): practicing in settings where answers can be checked (like math or code), so the model gets clear feedback.
- Olmo 3 Instruct: Tuned to give short, helpful answers without extra “thinking” text. It’s optimized for chat and function calling (asking external tools for info). This makes responses faster and easier to read.
- Olmo 3 RL-Zero: A research setup where they apply RL starting from the base model, using fully open, decontaminated datasets. This helps researchers study the true effect of RL without hidden training data sneaking in test answers.
To support the community, they also released:
- All intermediate checkpoints (snapshots of the model during training)
- Data mixes and data pools (the exact training tokens and the source collections)
- Training, data-processing, and evaluation code
Main Findings and Why They Matter
The authors report several key results:
- Olmo 3 Think 32B is, to their knowledge, the strongest fully-open “thinking” model. It performs very well on math, logic, coding, and reasoning benchmarks and is competitive with top open-weight models like Qwen 3 32B—despite using around 6× fewer training tokens.
- The Instruct models (7B and 32B) are fast and concise, performing strongly in general chat and function calling compared with other models of similar size.
- Long-context support (up to ~65K tokens) lets the models work with large documents. Olmo 3’s long-context performance rivals other leading open models, even though their long-context training stage was relatively short.
- The fully open release—data, code, and checkpoints—makes it possible to trace a model’s reasoning back to the training data. That’s unique and enables deeper scientific study of how models learn.
They also share practical details:
- Training took about 56 days on a cluster of 1024 H100 GPUs for the flagship model, with an estimated cost of ~$2.75M at$2 per GPU-hour.
- Post-training (especially RL) involved multiple runs and careful hyperparameter tuning, and they improved RL efficiency (up to 4× speedup) with better infrastructure.
Implications and Impact
This work pushes AI in two important ways:
- Transparency and Reproducibility: By releasing the whole “model flow,” researchers and developers can see exactly how the model was built, test ideas at any stage, and avoid hidden data problems. It sets a higher standard for openness in AI.
- Practical, Strong Open Models: Olmo 3 provides capable, openly available models for reasoning, code, and chat, plus long-context support. This helps schools, labs, startups, and individuals build on top of a high-quality, well-documented foundation.
In short, Olmo 3 isn’t just a strong model family—it’s a complete, open blueprint for how to build and study advanced LLMs responsibly and effectively.
Knowledge Gaps
Below is a single, consolidated list of concrete knowledge gaps, limitations, and open questions left unresolved by the paper. Each item is phrased to be actionable for future research.
- Quantify the independent impact of each data-mixing innovation. Provide controlled ablations isolating token-constrained mixing vs. quality-aware upsampling vs. global deduplication on downstream capability clusters (math, code, MCQA, long-context).
- Verify decontamination rigor at trillion-token scale. Develop and publish near-duplicate–aware decontamination audits across pretrain, midtrain, long-context, and all eval sets (including fuzzy/semantic matches), with reproducible scripts and leakage estimates.
- Characterize OCR noise and its downstream effects. Measure error profiles from
olmOCRon the PDF corpus and quantify how OCR artifacts affect reasoning, factuality, and long-context abilities. - Long-context fidelity under stress. Systematically evaluate retention and reasoning across increasing input and output lengths (e.g., 8K→65K) with calibrated, length-controlled test suites and report degradation curves and KV-cache/memory tradeoffs.
- Robustness of long-context capabilities to document structure. Test models on diverse long-document formats (tables, equations, footnotes, references) and analyze failure modes introduced by linearization.
- Dynamic “when-to-think” policies. Develop and evaluate mechanisms that decide at inference time whether to invoke chain-of-thought (CoT) vs. concise responses, optimizing for accuracy-latency trade-offs without leaking CoT unless necessary.
- Tool-use evaluation beyond function calling. Benchmark multi-step, multi-tool planning and error recovery (e.g., tool failure/retry, state tracking), including execution success, correctness, latency, and adherence to structured outputs (e.g., JSON).
- RLVR generalization to non-verifiable domains. Provide concrete reward designs, evaluation protocols, and outcome metrics for RL with unverifiable targets (e.g., multi-turn helpfulness, safety), and quantify reward hacking and spurious-reward susceptibility.
- Stability, variance, and reproducibility of RL. Report seed variance, run-to-run variability, and sensitivity to hyperparameters for SFT→DPO→RL pipelines; release minimal compute recipes to reproduce reported RL gains.
- Interplay between DPO and RL. Provide ablations disentangling DPO and RL contributions, and study sequencing (e.g., DPO-before-RL vs. RL-before-DPO) on different domains (math, code, instruction following).
- Scaling laws for post-training. Establish empirical sample/compute efficiency curves for SFT, DPO, and RL at 7B vs. 32B to forecast cost–benefit trade-offs and guide resource allocation.
- Evidence that “traceability to training data” improves debuggability. Provide case studies linking specific reasoning failures to training examples and demonstrate correction via targeted data edits or counterfactual augmentation.
- Safety and alignment coverage is under-specified. Evaluate on standardized safety/jailbreak suites (prompt injection, biological/chemical misuse, bias/toxicity metrics) and quantify trade-offs with capability gains across training stages.
- Privacy and PII risk in fully-open data pools. Conduct and publish audits for personal and sensitive data in pretraining/midtraining/long-context pools; validate PII filtering efficacy and residual risk post-release.
- Legal status and licensing clarity for PDFs and web crawl. Provide explicit license/rights analysis for released datasets and clarify permissible downstream uses; quantify portion of content under various licenses.
- Multilingual and cross-cultural generalization. Measure capabilities and safety in non-English settings, including long-context and tool-use in other languages; investigate data-mix interventions for multilingual performance.
- Catastrophic forgetting across stages. Assess whether midtraining and long-context extension degrade earlier capabilities; study recipes (e.g., rehearsal, interleaving) to preserve pretraining strengths.
- Short-context performance after long-context extension. Provide controlled comparisons showing impact on latency, throughput, and accuracy for typical short inputs after extension.
- Model merging methodology and effects. Specify and ablate the merging procedure used between parallel runs; quantify its influence on different capabilities and its stability across random seeds.
- Inference efficiency and latency budgets. Report token-per-second and end-to-end latency comparisons (Think vs. Instruct) under realistic decoding settings, including cost vs. accuracy trade-offs on reasoning-heavy tasks.
- Benchmark selection and overfitting risk. Demonstrate generalization by evaluating on unseen, independently curated, contamination-audited benchmarks; publish criteria for inclusion/exclusion and noise adjustments in OlmoBaseEval.
- Real-world code execution safety. Extend coding evaluations with vulnerability detection, sandboxing outcomes, and safe-execution metrics (e.g., resource abuse, insecure patterns) beyond pass@k correctness.
- RL-Zero scalability and transfer. Investigate whether RL-Zero gains at 7B transfer to 32B, and how differences in pretraining data affect RLVR sample efficiency and final performance.
- Synthetic reasoning trace quality control. Analyze error propagation from synthetic CoT traces, including hallucination rates and factuality drift; compare with human-curated traces and mixed pipelines.
- Decision criteria for tool-use vs. internal reasoning. Develop and assess policies that choose between API/tool calls and internal reasoning based on uncertainty, expected utility, or cost models.
- Environmental and accessibility reporting. Provide energy usage, carbon footprint, and compute-efficiency metrics per stage to enable sustainability comparisons; add guidance for reproducing results with smaller clusters.
- Comprehensive release integrity checks. Publish hash manifests and provenance for all released data mixes, pools, and checkpoints; add dataset cards with documented curation steps, filters, and known limitations.
Glossary
- algorithmic RL zero: A research setup that applies reinforcement learning starting from a base model without prior RL-specific finetuning to study pure RL effects. "an algorithmic RL zero setup"
- base model: The pretrained backbone model before task-specific post-training or instruction tuning. "base model training"
- benchmark noise: Random variability in evaluation results that makes small score differences unreliable. "hard to distinguish from benchmark noise."
- centralized evaluation: A coordinated evaluation process run in a single framework or team to ensure consistent comparisons across experiments. "blends distributed experimentation with centralized evaluation"
- checkpoint: A saved snapshot of model parameters at a particular training step. "training data, code and intermediate checkpoints"
- contrastive data: Pairs of preferred and non-preferred responses used to teach preference distinctions. "high-quality contrastive data for preference tuning"
- context window: The maximum number of tokens a model can attend to in its input (and sometimes output). "a larger context window."
- data leakage: Unintended overlap between training and evaluation data that artificially inflates performance. "without data leakage confounding our conclusions."
- data mix: The specific composition and proportions of datasets actually used for training tokens in a stage. "our 6T-token pretraining data mix."
- data pool: The broader collection of cleaned source data from which training mixes are sampled. "full source data pools"
- decontamination: The process of removing evaluation or target overlap from training data to prevent leakage. "we further decontaminate Dolci RL-Zero from pretraining and midtraining data"
- deduplication: Removing near-duplicate or identical text to avoid overfitting and data redundancy. "global deduplication at the trillion-token scale"
- Delta Learning: A preference-learning approach focusing on differences between candidate responses to guide improvement. "following the insights from Delta Learning"
- DPO: Direct Preference Optimization; a method that optimizes models directly against preference comparisons instead of an explicit reward model. "SFT, DPO, and RLVR"
- distributed experimentation: Running many smaller, parallel experiments across teams or nodes to explore design choices quickly. "distributed experimentation"
- function calling: A capability where a model outputs structured calls to tools or APIs in response to prompts. "function calling"
- inference-time scaling: Techniques that improve performance by allocating more compute during generation rather than changing model weights. "inference-time efficiency matters more than inference-time scaling."
- integration tests: End-to-end checks ensuring that combined data and training recipes produce the intended capabilities. "centralized integration tests"
- long-context extension: A training stage that increases the maximum supported context length for inputs/outputs. "Long-context extension was executed as a single run"
- midtraining: A targeted training phase after pretraining, using curated data to boost specific capabilities (e.g., code, math). "midtraining for 100 billion tokens"
- model flow: The complete, transparent lifecycle of model development, including data, code, and checkpoints. "The model flow encompasses training data, code and intermediate checkpoints for all stages of development."
- model merging: Combining parameters or checkpoints from multiple runs to integrate strengths or stabilize training. "model merging and evaluations"
- open-weight: Models that release only final weights (not full data/code/checkpoints) for use and fine-tuning. "open-weight models"
- preference tuning: Training methods that adjust a model to prefer higher-quality responses over weaker ones. "for preference tuning"
- pretraining: The large-scale initial training on broad, general-purpose text before any task-specific tuning. "pretraining for up to 5.9T tokens"
- proxy metrics: Indirect measurements used to predict performance when direct evaluation is noisy or impractical. "develop proxy metrics for evaluating small-scale models"
- quality-aware upsampling: Increasing sampling frequency of higher-quality data sources during training to improve learning efficiency. "quality-aware upsampling."
- reinforcement learning (RL): Training that optimizes a policy (the model) to maximize a reward signal through trial and feedback. "reinforcement learning"
- reinforcement learning with verifiable rewards (RLVR): RL where rewards are computed by automatic verifiers (e.g., program checks, unit tests) rather than human labels. "reinforcement learning with verifiable rewards"
- RL Zero: A fully open RL setup starting from a disclosed base model and datasets to isolate RL effects and avoid contamination. "RL Zero"
- signal-to-noise ratio: The proportion of true performance signal relative to random variation in evaluation results. "improve overall signal-to-noise ratio"
- step-by-step reasoning: Producing intermediate reasoning steps before final answers to improve correctness and transparency. "step-by-step reasoning"
- supervised finetuning (SFT): Training on input–output pairs to imitate high-quality examples or instructions. "supervised finetuning"
- thinking traces: The model’s intermediate, structured chains of thought generated prior to final answers. "thinking traces"
- tool-use: The ability of a model to invoke external tools (e.g., search, code execution) to complete tasks. "tool-use capabilities"
- verifiable rewards: Automatically computed rewards based on objective checks (e.g., tests pass/fail) used during RL. "verifiable rewards"
Practical Applications
Immediate Applications
The paper’s fully-open models, datasets, evaluation suites, and training code unlock a number of concrete, deployable applications across sectors. Below are actionable use cases that can be implemented now, with sector tags and feasibility notes.
- [Software/Developer Tools] Concise coding copilot and PR reviewer powered by Olmo 3 Instruct (7B/32B)
- Use cases: inline code completion, multi-file refactoring suggestions, test generation, bug localization, and PR critique grounded in repo context.
- Tools/workflows: integrate Olmo 3 Instruct with a local vector store for repo RAG; function calling to run tests/lint; gate changes via verifiable checks.
- Dependencies/assumptions: code security sandboxing; repository indexing; model license compliance; GPU/CPU sizing (7B for laptops/edge, 32B for servers).
- [Software/DevOps] Production on-call assistant with function calling
- Use cases: parse incident tickets, summarize logs, triage alerts, propose runbooks; call diagnostic tools via function APIs.
- Tools/workflows: log→context window loader (long-context up to ~65k tokens), function calling to observability APIs, incident timeline summarization.
- Dependencies/assumptions: strict tool permissioning; audit logging; latency budgets (prefer Instruct for speed).
- [Education] Step-by-step math and CS tutoring with Olmo 3 Think
- Use cases: scaffolded problem solving (GSM8k/MATH style), code tracing, rubric-aligned feedback with intermediate reasoning traces.
- Tools/workflows: Think mode for worked solutions; verifiable checks (unit tests, answer keys) for instant feedback.
- Dependencies/assumptions: content controls for grade level; teacher-in-the-loop for assessment; accessibility requirements.
- [Legal/Compliance] Long-document contract and policy analysis
- Use cases: clause extraction, risk flags, cross-document consistency checks, redline suggestions across contracts and policy manuals.
- Tools/workflows: Long-context extension (65k) for full-document reads; retrieval-augmented cross-referencing; concise summaries with Olmo 3 Instruct.
- Dependencies/assumptions: human oversight; citation grounding; data privacy controls; domain-tuned prompts.
- [Healthcare] Administrative summarization and guideline retrieval (non-diagnostic)
- Use cases: visit note summarization, discharge instruction simplification, policy/guideline lookup across long PDFs.
- Tools/workflows: olmOCR + Longmino documents for high-fidelity PDF → text; RAG with citations; brevity-optimized Instruct responses.
- Dependencies/assumptions: not for diagnostic use; HIPAA/PHI handling; human-in-the-loop validation.
- [Finance] 10-K/10-Q and research memo summarization with calculations checked via verifiable steps
- Use cases: risk/segment summaries, KPI extraction, scenario analyses with explicit calc steps via Think; function calls to pricing/query services.
- Tools/workflows: long-context filings ingestion; spreadsheet/API calls via function calling; numeric verification routines.
- Dependencies/assumptions: data freshness; regulatory disclaimers; guardrails against advice.
- [Customer Support] Multi-turn, concise chat agent with tool-use
- Use cases: intent classification, policy-aware responses, knowledge base lookup, ticket deflection with minimal verbosity.
- Tools/workflows: Dolci Instruct for brevity; function calling to CRM/KB; multi-turn DPO data for preference-consistent dialogue.
- Dependencies/assumptions: redaction of PII; escalation protocols; latency SLOs (prefer Instruct variant).
- [Research/Academia] Reproducible LLM experiments using the complete model flow
- Use cases: teaching labs replicating pretrain→midtrain→long-context→post-train; ablations on data mixes; scaling studies with sample mixes (150B/10B).
- Tools/workflows: olmo-core (training), Open Instruct (post-train), OLMES/decon (eval/decontamination), Dolma3 sample mixes.
- Dependencies/assumptions: modest GPU access for reduced mixes; adherence to dataset licenses; experiment tracking (W&B logs released).
- [Data Engineering] Trillion-token deduplication and contamination checks in enterprise corpora
- Use cases: large-scale dedup, token-constrained mixing, quality-aware upsampling for internal pretraining/fine-tuning.
- Tools/workflows: duplodocus, datamap-rs, dolma3 recipes; decon for eval decontamination.
- Dependencies/assumptions: data governance approvals; storage/throughput for global dedup; objective quality signals.
- [Public Sector/Policy] Audit-ready procurement and AI evaluation using OlmoBaseEval
- Use cases: compute-efficient, small-scale proxy evaluations for tenders; transparent benchmarking clusters (math/code/MCQA/IF).
- Tools/workflows: OlmoBaseEval suite and clustering; noisy-task pruning; proxy metrics for small models.
- Dependencies/assumptions: policy alignment on metrics; documentation of evaluation data provenance.
- [RL Research] Clean RL-from-scratch studies with Dolci RL-Zero and open RLVR code
- Use cases: reproducible RL algorithm comparisons across math, code, instruction following, and general prompts without data leakage.
- Tools/workflows: released RL-Zero datasets; RLVR framework with 4x efficiency improvements; verifiable reward pipelines.
- Dependencies/assumptions: careful seed control; reward function validation; hardware stability for longer runs.
- [Knowledge Management] Organization-wide long-context Q&A with citations
- Use cases: read entire policy handbooks, engineering design docs, and research PDFs; provide grounded answers with citation spans.
- Tools/workflows: Longmino-based long-doc store; Think for chain-of-thought (internal) + Instruct for user-facing brevity; citation extractors.
- Dependencies/assumptions: indexing pipeline health; document access controls; caching to manage latency/cost.
Long-Term Applications
These opportunities are enabled by the paper’s open artifacts but require further research, scaling, or productization.
- [Safety/Governance] Training-data-level provenance tracing for reasoning audits
- Vision: link generated reasoning chains back to specific training datapoints (“traceable thinking”) for audit, red-team triage, and bias/source attribution.
- Dependencies: mature provenance tooling; privacy-preserving lookups; legal frameworks for data lineage access.
- [Regulated Sectors] Audit-first foundation models for government and healthcare
- Vision: sector-specific models trained end-to-end from open data pools/mixes with documented decontamination/dedup; procurement-ready transparency.
- Dependencies: curated, compliant data pools; safety tuning and external audits; deployment certifications.
- [Agentic Systems] Verifiable multi-tool agents trained with generalized RLVR
- Vision: agents that plan, call tools, write code/tests, and self-verify steps across domains (math, code, data workflows, analytics).
- Dependencies: broader verifiable reward coverage; robust tool permissioning; sandboxed execution and cost controls.
- [Evaluation Science] Standardized, compute-efficient model development playbooks
- Vision: industry/academic standard for small-scale proxies, task clustering, and noise reduction to accelerate R&D without massive GPU budgets.
- Dependencies: community adoption; benchmark maintenance against contamination and drift.
- [Enterprise Data Platforms] Turnkey trillion-token data preparation stacks
- Vision: productized duplodocus/datamap-rs/dolma3 pipelines for global dedup, token-constrained mixing, and quality-aware upsampling on private corpora.
- Dependencies: connectors to enterprise data lakes; monitoring of quality signals; privacy/security certifications.
- [Long-Context Frontier] Reading-room AI for million-token contexts
- Vision: scale long-context extension beyond 65k to support book-length analyses, multi-year EHR timelines, and large codebases without chunking.
- Dependencies: architectural advances (memory/compressive attention); hardware and KV-caching innovations; latency amortization strategies.
- [Education at Scale] Open curricula for training and aligning LLMs
- Vision: universities and edtechs teach end-to-end LLM development using released model flow, enabling “hands-on model building” programs.
- Dependencies: managed GPU classrooms; simplified orchestration; assessment rubrics for ethical/safety modules.
- [Financial Analytics] Verifiably correct, tool-augmented decision notebooks
- Vision: research notebooks where the model’s numeric reasoning is transparently step-checked and tied to source filings/data pulls via function calls.
- Dependencies: robust data vendor integrations; strict separation of analysis vs. advice; model liability frameworks.
- [Legal Tech] Provenance-grounded citation drafting and contract co-authoring
- Vision: drafting tools that cite paragraph-level provenance, flag potential leakage/conflicts, and learn via RLVR on verifiable drafting tasks.
- Dependencies: domain-specific reward functions; acceptance testing; client data governance.
- [Security] Contamination-resistant RL benchmarks and red-team harnesses
- Vision: community-standard RL testbeds that are demonstrably free of pretrain/midtrain leakage; spurious-reward detection at scale.
- Dependencies: ongoing dataset hygiene; independent hosting; challenge design with writeups.
- [On-Device/Edge AI] High-quality, privacy-preserving assistants with 7B models
- Vision: offline personal assistants for scheduling, study aid, and code snippets using Instruct 7B with compressed long-context techniques.
- Dependencies: memory-efficient attention; quantization and hardware acceleration; local tool integration.
- [MLOps/Productivity] Audit-ready LLM DevKit for enterprises
- Vision: packaged workflows combining model flow artifacts, evals, decontamination, and RLVR to meet internal risk and compliance checklists.
- Dependencies: integration with enterprise IAM, observability, and approval workflows; versioning and SBOMs for models/data.
- [Science/Knowledge Graphs] Automated extraction from PDFs to structured knowledge
- Vision: large-scale literature mining (via olmOCR + Longmino) to build up-to-date, queryable knowledge graphs with provenance.
- Dependencies: high-quality PDF parsing; entity/linking accuracy; community curation and licensing.
Notes on Feasibility and Dependencies Across Applications
- Licensing and usage rights: confirm model, code, and dataset licenses for commercial use and redistribution.
- Compute and latency: 7B is suitable for edge/small servers; 32B for higher-accuracy server deployments. Long-context increases memory/latency costs.
- Safety and compliance: add domain guardrails, redaction, and human oversight in regulated contexts.
- Data governance: ensure deduplication, decontamination, and provenance tracking, especially when mixing public and private corpora.
- Tool-use security: restrict and log function calls; sandbox code execution; enforce least privilege.
- Evaluation drift: maintain clean benchmarks and monitor contamination; adopt clustered/proxy metrics for small-scale model iterations.
Collections
Sign up for free to add this paper to one or more collections.