- The paper introduces a diffusion-based framework that disentangles bone lengths and directions to explicitly control error propagation in 3D human pose estimation.
- It presents the Fast3DHPE toolkit, a standardized, config-driven platform that enables fair benchmarking and rapid development across multiple datasets.
- The KHSTDenoiser, employing dual-branch spatial and temporal transformers, achieves state-of-the-art results with reduced hierarchical error accumulation (e.g., 39.6 mm MPJPE on Human3.6M).
FastDDHPose: Unified, Efficient, and Disentangled 3D Human Pose Estimation
Motivation and Contributions
FastDDHPose proposes a unified, efficient, and disentangled framework for 3D human pose estimation based on denoising diffusion models. The paper systematically addresses discrepancies in evaluation and development pipelines by introducing the Fast3DHPE toolkit—an extensible, standardized platform for fair benchmarking, rapid method development, and training efficiency. Within this framework, the authors introduce FastDDHPose, a diffusion-based architecture with structural disentanglement, explicitly modeling the distributions of bone lengths and directions. Hierarchical error accumulation is mitigated via the proposed Kinematic-Hierarchical Spatial and Temporal Denoiser (KHSTDenoiser), enabling effective and scalable incorporation of the kinematic tree structure.
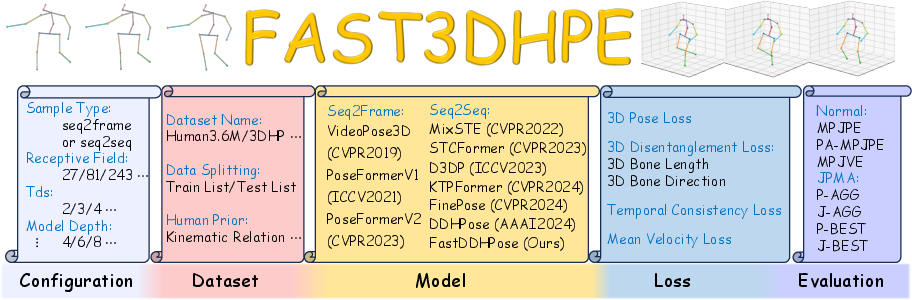
Figure 1: The Fast3DHPE framework architecture with five functional modules for unified 3D HPE research and development.
Unified Architecture and Benchmarking with Fast3DHPE
Fast3DHPE provides a reproducible, config-driven platform supporting multiple dataset standards and competitive models, both deterministic and probabilistic. The modular pipeline encompasses:
- Standardized experiment configurations (input paradigms, receptive field, temporal downsampling).
- Normalized dataset loaders for benchmarks like Human3.6M and MPI-INF-3DHP.
- Model abstraction for integrating a rich model zoo, with controlled evaluation metrics.
- Multi-loss training protocols incorporating MPJPE, P-MPJPE, temporal smoothness, velocity, and disentanglement objectives.
- Distributed and mixed precision execution yielding significant efficiency gains (up to 10× faster epoch times).
This backbone ensures robust cross-comparison and rapid ablation cycles, facilitating reproducibility and downstream research utility.
Disentangled Diffusion for 3D Pose: FastDDHPose Design
A principal limitation of direct pose-space diffusion approaches is their inefficacy in leveraging explicit low-dimensional human pose priors, like bone length or direction, leading to suboptimal generalization and heightened hierarchical errors. FastDDHPose circumvents this by separating the 3D pose input into bone length and direction components, injecting Gaussian noise in the forward process for each, then fusing the noisy components with 2D pose cues for denoising.
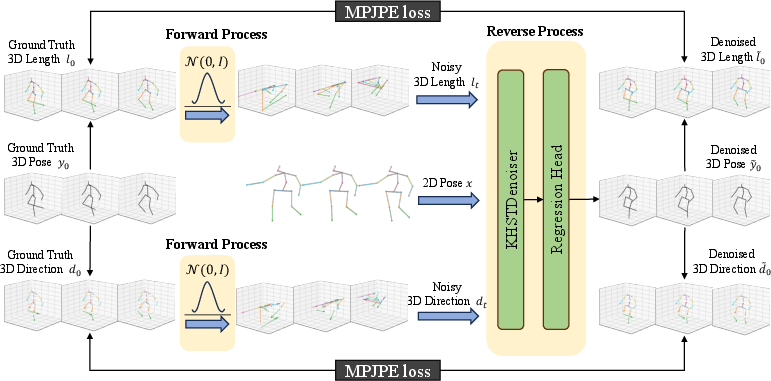
Figure 2: FastDDHPose training pipeline. Noisy bone length, noisy bone direction, and 2D keypoints are embedded for the denoising diffusion process.
Disentanglement is applied solely at the input to control error propagation; joint regression is performed in the reverse process, not via recursive composition, yielding a favorable trade-off between explicit prior encoding and error amplification.
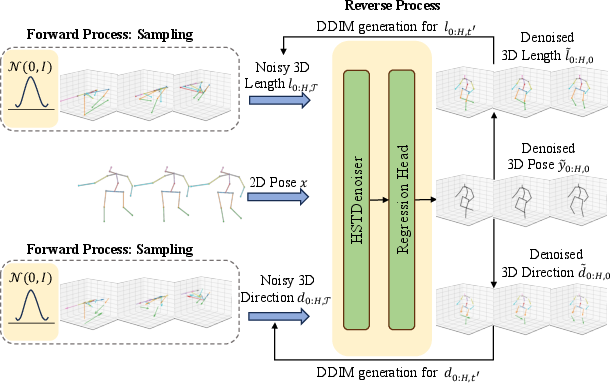
Figure 3: Inference pipeline showing joint denoising of noisy bone length/direction and 2D pose.
The KHSTDenoiser comprises a dual-branch transformer: the Kinematic-Hierarchical Spatial Transformer (KHST), which explicitly encodes hierarchical adjacency in the kinematic skeleton, and the Kinematic-Hierarchical Temporal Transformer (KHTT), which enforces temporal consistency. KHST incorporates spatial attention priors based on kinematic hierarchy levels, while HiE (Hierarchical Embedding) augments joint representations with hierarchy-depth-aware position encoding.
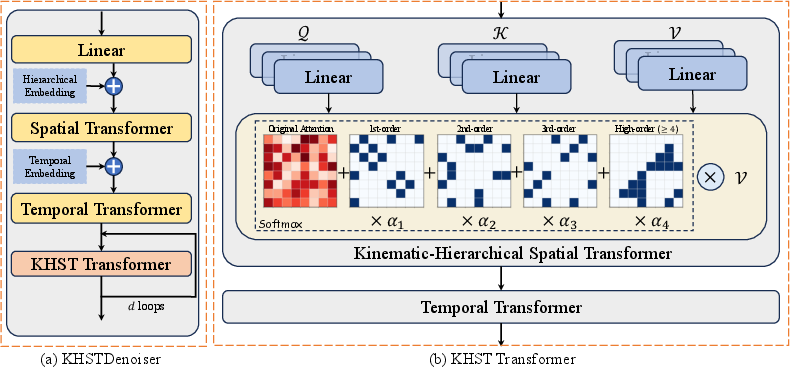
Figure 4: (a) KHSTDenoiser overview with hierarchical and temporal embedding layers. (b) Full architecture with alternating KHST/KHTT modules for enhanced relational modeling.
This architectural prior has a demonstrable effect in reducing error escalation in higher-depth hierarchy joints—a documented weakness of previous works.
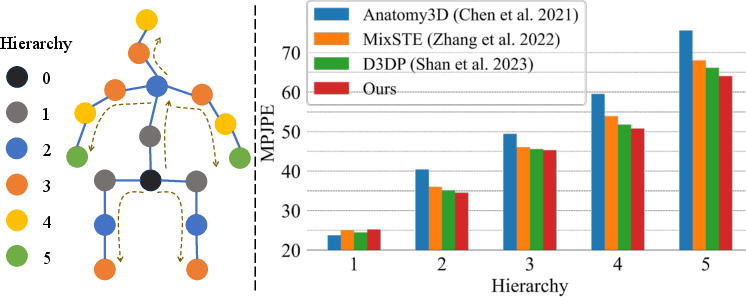
Figure 5: (Left) Human3.6M skeleton with kinematic hierarchy; (Right) MPJPE across hierarchy groups, highlighting lower accumulation error for FastDDHPose.
Quantitative Results and Efficiency
FastDDHPose achieves SOTA or competitive results across deterministic and probabilistic protocols:
- On Human3.6M, FastDDHPose yields MPJPE of 39.6 mm, outperforming previous disentangled baselines by over 10% and outperforming leading non-disentangle and probabilistic models by 3.4% and 2.0%, respectively.
- On MPI-INF-3DHP, superior performance is reported on PCK, AUC, and MPJPE metrics.
- Comparison with methods incorporating auxiliary heatmaps or depth distributions in their initialization (e.g., DiffPose) still demonstrates superior or competitive accuracy for the disentangle-only variant of FastDDHPose.
Ablation studies confirm the critical role of the disentanglement input (without disentangled decoding), HiE, KHST, and the inclusion of disentanglement loss in optimizing data efficiency, hierarchical error distribution, and accuracy.
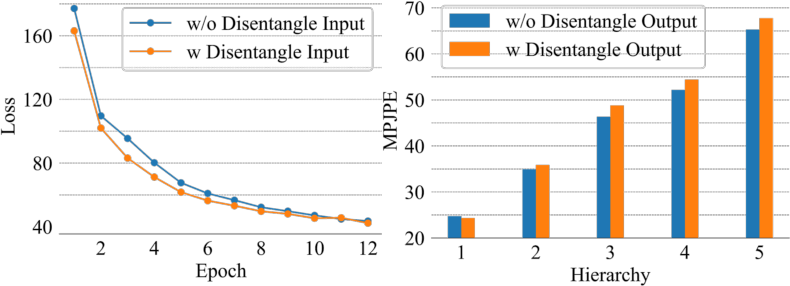
Figure 6: (Left) Training loss convergence with/without disentanglement output. (Right) Hierarchical MPJPE error, showing reduced error accumulation absent output disentanglement.
Qualitative Insights and Robustness
Visualizations on Human3.6M and challenging in-the-wild (YouTube) data affirm the model’s configurational coherence, recovery of realistic human-proportions, and resilience to noisy or low-res 2D inputs.
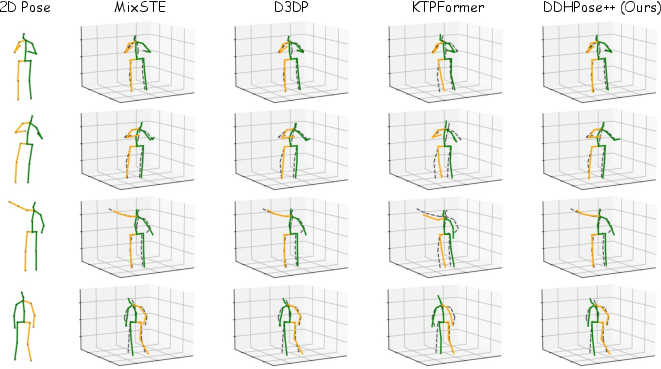
Figure 7: Qualitative Human3.6M comparison—FastDDHPose shows superior alignment to ground truth, especially for high-hierarchy joints.

Figure 8: In-the-wild visual results for videos sourced from YouTube, with strong structure preservation under diverse scene and subject variations.
Theoretical and Practical Implications
FastDDHPose substantiates that explicit low-dimensional diffusion—informed by kinematic priors and hierarchical relational modeling—not only supports sample efficiency and training stability but is also critical for accurate and scalable 3D HPE. The design largely suppresses error accumulation endemic to naive hierarchical regression schemes. The public release of Fast3DHPE is poised to standardize evaluation and accelerate foundational advances in pose estimation, training efficiency, and cross-domain generalization.
Conclusion
FastDDHPose advances 3D human pose estimation on two fronts: (1) the introduction of a unified, extensible benchmarking and development framework, and (2) the first efficient, disentangled, hierarchically structured diffusion model with robust generalization and scalable implementation. The deployment of explicit priors, enforced via disentangled noise injection and transformer-based hierarchical denoising, demonstrates consistent performance improvements and reliability on both controlled and real-world data. This work establishes new benchmarks and offers reusable methodology for future directions in generative scene understanding, temporal reasoning, and robust pose estimation.