DriverGaze360: OmniDirectional Driver Attention with Object-Level Guidance
Abstract: Predicting driver attention is a critical problem for developing explainable autonomous driving systems and understanding driver behavior in mixed human-autonomous vehicle traffic scenarios. Although significant progress has been made through large-scale driver attention datasets and deep learning architectures, existing works are constrained by narrow frontal field-of-view and limited driving diversity. Consequently, they fail to capture the full spatial context of driving environments, especially during lane changes, turns, and interactions involving peripheral objects such as pedestrians or cyclists. In this paper, we introduce DriverGaze360, a large-scale 360$\circ$ field of view driver attention dataset, containing $\sim$1 million gaze-labeled frames collected from 19 human drivers, enabling comprehensive omnidirectional modeling of driver gaze behavior. Moreover, our panoramic attention prediction approach, DriverGaze360-Net, jointly learns attention maps and attended objects by employing an auxiliary semantic segmentation head. This improves spatial awareness and attention prediction across wide panoramic inputs. Extensive experiments demonstrate that DriverGaze360-Net achieves state-of-the-art attention prediction performance on multiple metrics on panoramic driving images. Dataset and method available at https://av.dfki.de/drivergaze360.








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching computers to understand where drivers look while they drive, not just straight ahead but all around the car. The authors built a new “wrap‑around” dataset called DriverGaze360 that shows the full 360° view around a driver and records where their eyes focus. They also created a new AI model, DriverGaze360‑Net, that predicts both:
- an attention map (where the driver is likely looking), and
- which objects the driver is paying attention to (like cars, pedestrians, cyclists, signs, and lights).
The goal is to help make driving systems safer and more explainable by understanding human attention in realistic, all‑around driving situations.
What questions does the paper try to answer?
The paper focuses on three simple questions:
- Can we collect high‑quality data of where drivers look in a full 360° view, not just out the front windshield?
- Can an AI model learn to predict where drivers look across this panoramic view?
- Will predicting “what” the driver is looking at (objects) alongside “where” they look improve the accuracy and usefulness of attention predictions?
How did the researchers do it?
The team created both a dataset and a model.
The dataset: DriverGaze360
- They used a driving simulator (think of a super realistic video game) called CARLA.
- Real people wore eye‑tracking glasses that recorded their gaze (like a “where are you looking?” tracker) while they drove in the simulator.
- The setup showed the drivers a full 360° scene: wide front screens plus screens acting as rear‑view mirrors.
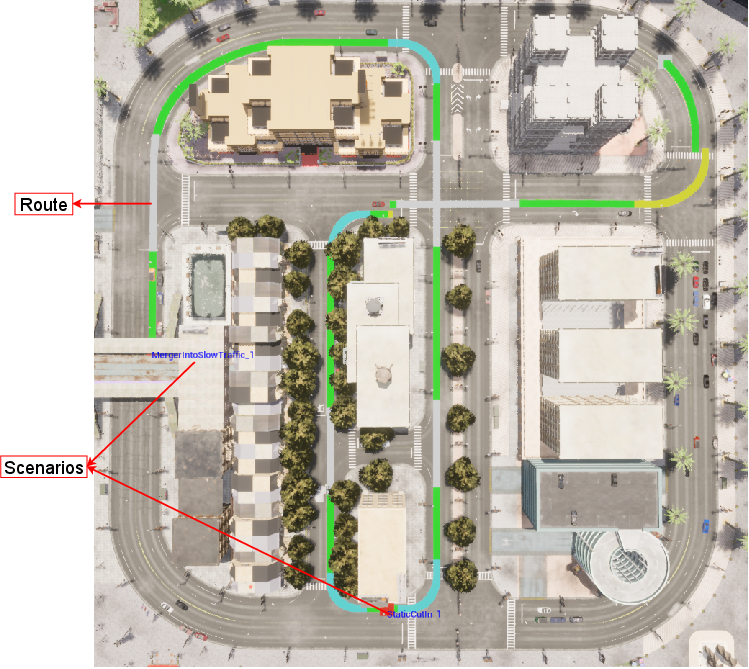
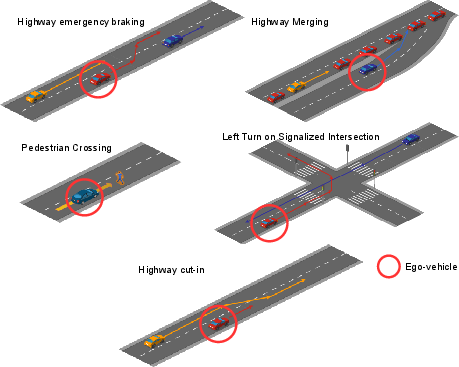
- They ran many scenarios: everyday driving, guided routes, and tricky, safety‑critical moments (like a sudden stop on the highway or a pedestrian stepping out).
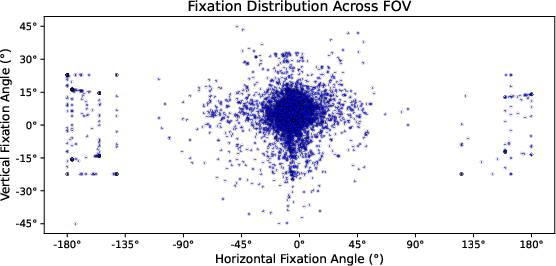
- Result: About 1 million frames (images) with gaze labels from 19 drivers, covering 9 hours of driving with day/night and different weather. It includes rear‑view glances (about 6% of gazes), which most forward‑only datasets miss.
Think of the dataset like a giant photo album of driving scenes stitched into a wrap‑around panorama, with a “heat map” showing where the driver was looking in each moment.
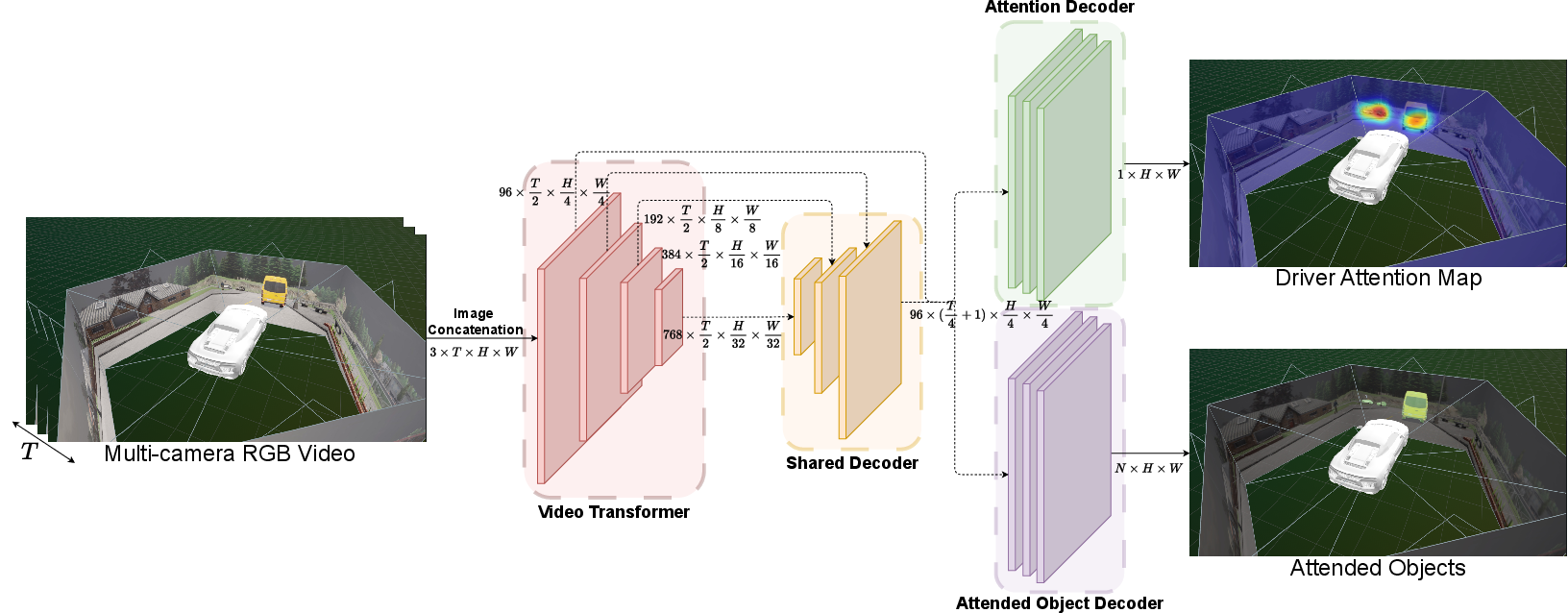
The model: DriverGaze360‑Net
- The model watches short video clips (about half a second) of the panoramic driving view.
- It uses a transformer (a type of AI good at focusing on the most important parts), adapted for video. You can think of a transformer like a smart reader that scans a page and naturally pays more attention to the parts that matter.
- The model has two heads:
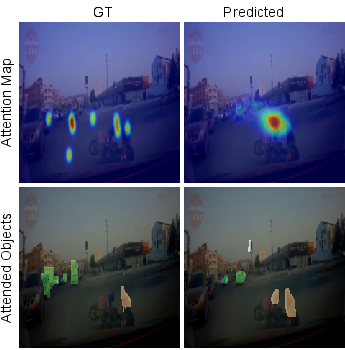
- Attention head: predicts the “heat map” of where a driver looks.
- Object head: predicts which objects are being attended (like coloring only the cars or pedestrians the driver seems to care about).
- To train the object head, they built attended‑object labels by overlapping the gaze heat map with object masks. If a gaze overlaps an object (e.g., a car), that object is marked as “attended.” This is like saying, “If the driver’s focus touches this object, highlight it.”
Why add the object head? When the scene is huge (360°) and the driver is only looking at tiny areas, teaching the model to also identify the specific objects helps it learn smarter attention.
What did they find, and why does it matter?
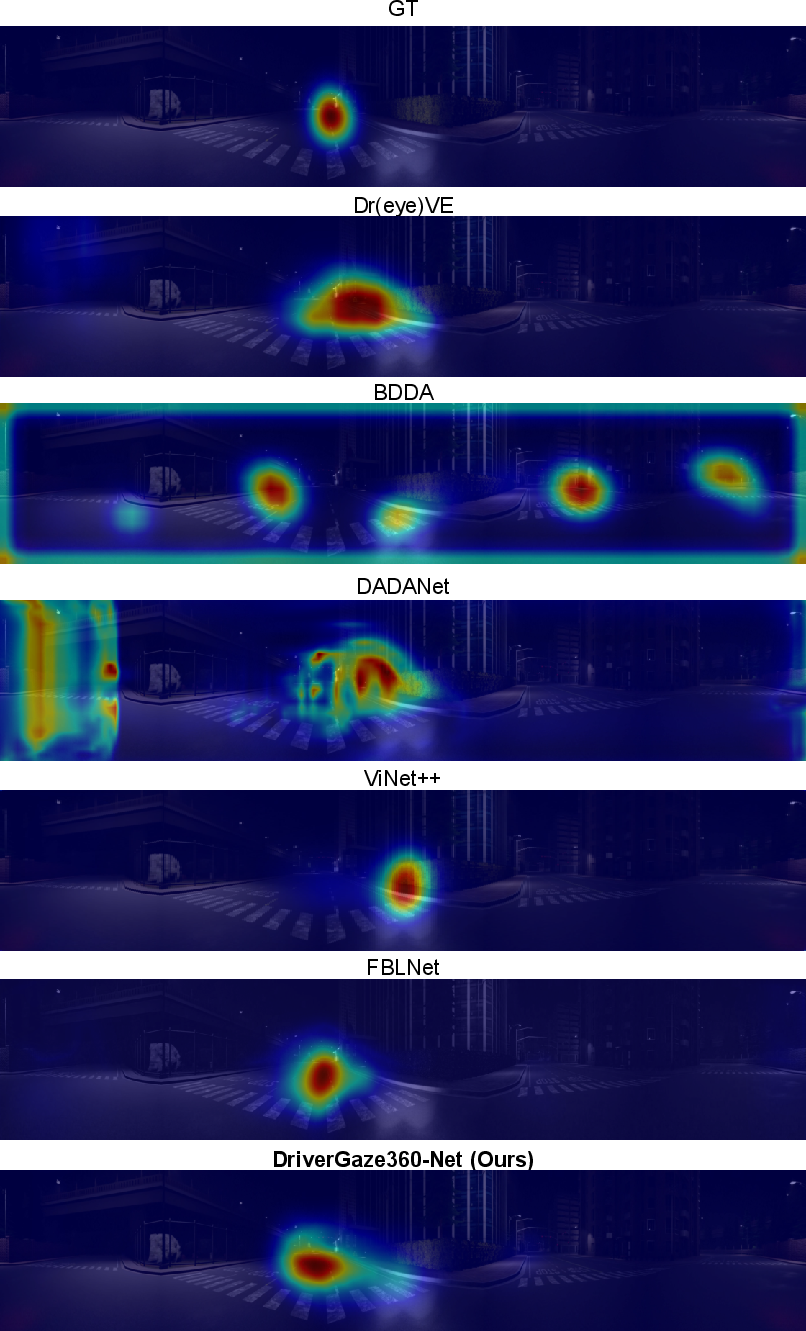
- Their model outperformed several strong existing methods on the new panoramic dataset. In simple terms, it was better at matching where humans actually looked.
- It also worked well on a real‑world dataset (DADA‑2000), showing it’s not just good in simulation.
- Adding the “attended objects” head improved attention prediction more than just adding a regular full‑scene segmentation head. In other words, teaching the model both “where” and “what” sharpened its predictions.
- The dataset itself is a big step forward: it captures the full wrap‑around view and continuous driving behavior, not just short clips or only the front view.
Why it matters:
- Drivers don’t only look forward. They check mirrors, watch the sides, and react to things behind them. Understanding this makes driver‑assistance systems smarter and safer.
- For autonomous cars, knowing human attention helps the AI explain its decisions and better predict what a human driver might do.
What’s the impact and what comes next?
- Safer assistance: Systems can alert drivers based on attention—for example, “You missed that cyclist to your left.”
- More explainable AI: Autonomous cars can say, “I prioritized this vehicle because human drivers tend to focus there during merges.”
- Better training data: DriverGaze360 enables future research to explore all‑around attention, difficult maneuvers, and realistic peripheral interactions.
Going forward, the authors plan to use this dataset and model to build more transparent, trustworthy driving systems that integrate human attention into how AI makes decisions.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes what remains missing, uncertain, or unexplored in the paper, with concrete items future researchers can act on:
- Real-world 360° validation: The dataset is entirely simulated; there is no evaluation on real-world panoramic driver attention data. Collect and benchmark a true 360° real-driving dataset (e.g., multi-camera rig or equirectangular panorama) to quantify sim-to-real performance gaps.
- Panoramic geometry handling: Inputs are horizontally concatenated planar views; spherical topology, seam artifacts, and view boundary discontinuities are not modeled. Compare concatenation against cubemap/equirectangular projections and spherical CNN/Transformer architectures; measure seam-induced errors.
- Gaze calibration accuracy: The AprilTag-based homography alignment lacks quantitative accuracy/error analysis (per camera, across FoV, over time). Report calibration residuals, drift under head motion, and re-calibration frequency; provide calibration protocols and error bounds.
- Head pose integration: The pipeline does not estimate or use head pose, which is critical for mapping eye gaze to world coordinates, especially during mirror checks. Incorporate head pose tracking and evaluate its effect on gaze localization and attended-object assignment.
- Fixation detection methodology: Raw gaze points are aggregated and converted to Gaussians with fixed variance without fixation/saccade segmentation or adaptive spread. Evaluate fixation-detection algorithms and distance/scale-aware Gaussian kernels; run sensitivity analyses on temporal window size (30 frames) and variance.
- Attended-object thresholding: The binarization threshold τ for saliency-to-instance overlap is unspecified and unvalidated. Perform a sensitivity study on τ, and consider probabilistic/soft overlap weighting to reduce brittleness.
- Object class coverage: Attended objects are limited to vehicles, pedestrians, cyclists, traffic lights/signs; other salient entities (construction cones, emergency vehicles, lane markings, road edges, crosswalks, work zones) are excluded. Expand classes and quantify impact on attention prediction.
- Instance segmentation dependence: In simulation, ground-truth instances are available; in real data (DADA-2000), YOLO-v11 outputs are used without quality assessment. Measure how segmentation precision/recall affects attended-object supervision and attention metrics; compare detectors/segmentors and uncertainty-aware supervision.
- Long-horizon temporal modeling: The model uses only ~0.5 s (16 frames). Study attention dynamics at longer horizons (≥2–5 s), including anticipation and task-driven gaze shifts; ablate sequence length and temporal architectures (e.g., memory modules).
- Generalization beyond narrow FoV: Real-world generalization is shown only for a front-view dataset (DADA-2000). Test on additional datasets and settings with lateral/rear-context (e.g., multi-camera non-panoramic rigs) to isolate what transfers.
- Baseline fairness on panoramic inputs: Compared baselines were designed for frontal imagery and may be disadvantaged on panoramic concatenations. Re-implement baselines with 360-aware encoders or projection strategies to establish fair comparisons.
- Weather/lighting robustness: Beyond a qualitative nighttime example, there is no systematic robustness study across rain, wind, night, glare, fog, snow, or low sun conditions. Stratify evaluation by environment and quantify failure modes.
- Driver diversity and personalization: Participants are 19 drivers aged 21–40, lacking demographic and skill diversity (e.g., older drivers, novice vs. expert, cultural differences). Analyze inter-driver variability and evaluate personalized vs. universal models.
- Mirror realism and rear-view behavior: Rear views are picture-in-picture displays with fixed 72° FoV, which may not mirror real-world mirrors and head-eye strategies. Compare PiP mirrors against physical mirror setups; quantify effects on rear-view fixations and model performance.
- Attention-object causality and intent: The model predicts “where” and “what” but not “why” (task intent or hazard relevance). Add task/intent labels (e.g., lane change, hazard monitoring) and evaluate multi-task models that predict where/what/why jointly.
- Multi-sensor fusion: Although the simulator supports multi-sensor outputs, the model uses only RGB. Integrate depth, LiDAR, vehicle CAN-bus, or map priors (e.g., BEV geometry) and assess gains for attention and attended-object prediction.
- 3D spatial reasoning: Attended-object mapping is purely 2D; depth, occlusions, and peripheral vision are not modeled. Incorporate 3D geometry and peripheral acuity models to more accurately infer attention in cluttered omnidirectional scenes.
- Loss weighting and objective design: The joint loss uses equal weights (λsal=λseg=1) without justification. Conduct a hyperparameter sweep on loss weights and explore additional terms (e.g., NSS/SIM in loss, focal loss for sparse saliency, uncertainty calibration).
- Class imbalance in attended segmentation: No analysis or mitigation of class imbalance (e.g., pedestrians vs. vehicles). Report per-class metrics and apply class-aware weighting or re-sampling to improve minority classes.
- Inference efficiency and deployment: Training details are provided, but real-time inference latency, memory footprint, and energy usage are not reported. Benchmark on edge hardware typical for ADAS and assess viability for onboard deployment.
- Annotation noise and reliability: Eye-tracker noise, glasses slippage, and missing data handling are not discussed. Quantify gaze noise, confidence intervals, and implement robust filtering; release quality metadata per frame.
- Scenario breadth and rare hazards: Only five safety-critical scenarios are scripted; many edge cases (e.g., emergency vehicles, cyclists overtaking from behind, complex work zones, snow/ice) are not included. Expand scenario library and measure coverage.
- Evaluation metrics for 360° saliency: Standard 2D metrics (KLD, CC, SIM, NSS) are used without 360-specific considerations (e.g., geodesic distances, seam-aware metrics). Develop evaluation protocols tailored to spherical/panoramic saliency.
- Data splits and potential leakage: Town-based splits may still share visual style or assets across CARLA towns. Validate split independence (textures, assets, traffic behaviors) and perform cross-town/cross-city generalization tests.
- Public reproducibility details: Full scenario specifications (Scenic scripts, seeds), calibration procedures, and synchronization details are not fully documented. Release protocols, scripts, and calibration datasets to enable exact replication.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging the DriverGaze360 dataset, the DriverGaze360-Net model, and the attended-object extraction pipeline described in the paper.
- Omnidirectional driver attention benchmark and training resource (Academia, Automotive/Software) What it enables: A standard 360° gaze benchmark to train and compare panoramic attention models under routine and safety-critical scenarios, including rear/side attention that frontal datasets miss. Potential tools/products/workflows: Public dataset API, evaluation scripts/leaderboard, model zoo with DriverGaze360-Net checkpoints. Assumptions/dependencies: Compliance with dataset license; compute to train ViT/VST backbones; awareness of sim-to-real bias when reporting real-world claims.
- Attention-guided perception debugging and explainability overlays (Automotive software, AV/ADAS R&D) What it enables: Overlay of predicted panoramic attention maps and “attended objects” on recorded logs to audit why an AV/ADAS stack focused (or failed to focus) on specific entities during maneuvers. Potential tools/products/workflows: “Gaze Overlay” plugin for AV log players (ROS/Autoware/Apollo), CARLA-based replay with attention layers, Jupyter dashboards for CC/KLD/SIM/NSS metrics over routes. Assumptions/dependencies: Calibrated multi-camera rigs or stitched panoramas; some sim-to-real domain gap remains; model weights and inference runtime integrated into log tooling.
- Simulator-based driver training feedback on scanning/mirror usage (Education, Fleet safety, Driver schools) What it enables: Real-time or post-session heatmap feedback to trainees on glance coverage (front/lateral/rear) and attention to vulnerable road users in simulators. Potential tools/products/workflows: CARLA/SCENIC lesson modules with DriverGaze360-Net; Pupil Labs/Pupil Core or similar eye tracking; coached debriefs using gaze distribution KPIs. Assumptions/dependencies: Access to simulator and eye-tracking; adaptation for novice drivers; instructional design to avoid over-alerting.
- Auto-labeling of attended objects for perception training (Software/ML Ops) What it enables: Cheap generation of “attended-object” segmentation masks from simulation (fixation–semantic fusion) to supervise detectors/segmenters with task-relevant labels. Potential tools/products/workflows: Data-engineering pipeline that runs Algorithm 1 on CARLA rollouts; weak supervision for hazard detectors; prioritization of “attended” instances during training. Assumptions/dependencies: Quality of instance segmentation in sim; threshold tuning (τ) for saliency binarization; domain shift for real images.
- Scenario coverage analytics for testing and validation (Automotive QA/Validation) What it enables: Quantifying whether test suites include adequate rear/side attention-demanding events (merges, cut-ins, occluded crossings) using panoramic gaze distributions. Potential tools/products/workflows: KPI dashboards of angular gaze histograms and event-conditioned attention; gap analysis to plan additional test drives. Assumptions/dependencies: 360° logs or stitched multi-cam feeds; mapping between scenarios and gaze segments.
- Human factors and distraction research at scale (Academia, Human factors, Healthcare/rehab) What it enables: Controlled, reproducible studies of gaze behavior under weather, night, and near-miss scenarios; baseline comparisons across drivers and tasks. Potential tools/products/workflows: Experiment scripts, statistical notebooks for gaze metrics, replication packages for safety-critical episodes. Assumptions/dependencies: IRB/ethics for new user studies; the dataset is simulation-based (interpretation caution for clinical claims).
- Attention-aware resource scheduling in AV perception (Automotive software) What it enables: Dynamically prioritizing compute on ROIs and object classes likely to be driver-relevant (vehicles, pedestrians, cyclists, traffic lights/signs) to reduce latency or energy. Potential tools/products/workflows: Scheduling policies that weight detector/segmenter proposals by attended-object maps; early-exit decoders for low-saliency regions. Assumptions/dependencies: Real-time inference constraints; thorough regression testing to prevent missed detections.
- Cross-dataset transfer and pretraining for real-world saliency (Academia, Automotive) What it enables: Pretraining on DriverGaze360 and fine-tuning on real datasets (e.g., DADA-2000) to boost saliency performance and generalization. Potential tools/products/workflows: Release of pretrained DriverGaze360-Net backbones; standardized finetuning protocols; ablations with/without attended-object head. Assumptions/dependencies: Careful data curation to mitigate overfitting to sim artifacts; evaluation on geographically diverse conditions.
Long-Term Applications
These opportunities require additional research, real-world data collection, productization, safety validation, or policy development before broad deployment.
- Real-time 360° attention module in production vehicles (Automotive/ADAS, Robotics) What it enables: On-vehicle panoramic attention and attended-object predictions to inform planning, hazard anticipation, and driver coaching. Potential tools/products/workflows: “DriverGaze360-RT” embedded module running on surround-view cameras; integration with planning stack and HMI. Assumptions/dependencies: Surround camera hardware and clock-precise calibration; low-latency inference on automotive-grade compute; rigorous safety cases and functional safety (ISO 26262) compliance.
- Shared autonomy via human–AI attention alignment (Automotive HMI/UX) What it enables: Monitoring divergences between human glance behavior and AV attention; driver alerts or adaptive assistance during lane changes/merges and occluded crossings. Potential tools/products/workflows: Fusion of in-cabin gaze estimation with external panoramic saliency; explainability UI indicating “what the car attends vs. what you attend.” Assumptions/dependencies: Reliable in-cabin eye tracking across lighting/occlusions; robust multimodal fusion; distraction/overreliance risk management.
- Insurance and fleet risk scoring from attention coverage (Finance/Insurance, Fleet ops) What it enables: Behavioral risk indices based on rear/lateral scanning frequency, time-to-attention for hazards, and attention to vulnerable road users. Potential tools/products/workflows: Telematics analytics that convert saliency timelines to risk features; coaching reports for fleets. Assumptions/dependencies: Privacy/GDPR compliance; need for validated links between attention metrics and claim outcomes; bias audits.
- Regulatory test protocols for omnidirectional situational awareness (Policy/Standards) What it enables: Certification scenarios and metrics that go beyond frontal FoV, including mirror checks and blind-spot attention for ADAS/AV. Potential tools/products/workflows: Open scenario suites (CARLA/SCENIC) with attention-grounded pass/fail criteria; conformance tests using saliency/attended-object metrics. Assumptions/dependencies: Multi-stakeholder consensus (OEMs, suppliers, regulators); standardized camera rigs and evaluation tools.
- Urban design and road safety interventions guided by gaze hotspots (Public sector, Transportation planning) What it enables: Identifying intersections or signage configurations that consistently draw insufficient attention; redesigns to improve conspicuity. Potential tools/products/workflows: City-scale aggregation of real-world panoramic gaze; hotspot maps overlaid with crash data; A/B tests of infrastructure changes in sim. Assumptions/dependencies: Access to representative real-world 360° gaze data; ethical data collection; robust transfer from sim-derived insights.
- Multimodal “attention-supervised” foundation models for driving (AI research, Software) What it enables: Training large video-language-action models with gaze/attended-object as auxiliary signals to improve explainability and data efficiency. Potential tools/products/workflows: Pretraining pipelines where attention serves as a consistency or alignment loss; promptable agents that justify focus of perception. Assumptions/dependencies: Scale of compute and data; curated real-world attention labels; careful evaluation of causal utility vs. correlation.
- Cross-domain adaptation: aviation, maritime, and heavy machinery (Aerospace, Marine, Construction/Mining Robotics) What it enables: 360° attention modeling for pilots, captains, and operators of large vehicles with rich peripheral demands; hazard prioritization in clutter. Potential tools/products/workflows: Domain-specific datasets and attended-object taxonomies; cockpit/bridge HMI prototypes with attention overlays. Assumptions/dependencies: New data collection with domain-appropriate sensors; task-specific validation; safety certification hurdles.
- Consumer dashcam coaching for situational awareness (Consumer electronics, Mobility apps) What it enables: Aftermarket surround-view dashcams that provide feedback on mirror checks and hazard scanning, with trip debriefs. Potential tools/products/workflows: Mobile/edge app with panoramic saliency inference; “attention score” summaries and targeted micro-lessons. Assumptions/dependencies: Surround camera hardware availability; on-device efficiency; legal acceptance of in-cabin or external monitoring; avoiding driver distraction.
- Teleoperation/remote assistance with attention priors (Mobility/Teleops) What it enables: Highlighting likely critical objects in 360° teleoperation feeds to reduce operator workload and improve reaction time. Potential tools/products/workflows: Saliency overlays in teleop UIs; operator-in-the-loop feedback to refine attention models. Assumptions/dependencies: Network latency and reliability constraints; robust confidence calibration to prevent overtrust.
- V2X attention-aware coordination (Transportation, Smart infrastructure) What it enables: Infrastructure and vehicles that modulate messaging (e.g., smart crosswalk beacons, in-vehicle alerts) based on predicted attention gaps for pedestrians and drivers. Potential tools/products/workflows: Edge models at intersections; broadcast of attention-relevant cues via C-V2X/DSRC. Assumptions/dependencies: Standards and interoperability; privacy; fail-safe designs to avoid unintended behaviors.
Notes on key dependencies tied to this paper’s contributions
- 360° data and modeling: Many applications depend on surround-view camera setups or panoramic stitching comparable to DriverGaze360’s five-camera concatenation and proper temporal synchronization.
- Sim-to-real transfer: Although the paper shows generalization to DADA-2000, robust deployment requires additional real-world training/validation, domain adaptation, and bias analysis.
- Attended-object head and fixation–semantic fusion: Applications that need object-level explainability or supervision (e.g., auto-labeling, compute prioritization) rely on instance segmentation quality and the attended-object extraction thresholding.
- Real-time constraints: Production uses need optimized backbones (e.g., smaller Swin variants, pruning/quantization) and hardware acceleration to meet automotive latency/energy budgets.
- Privacy/ethics: In-cabin gaze capture and attention-based analytics must comply with privacy regulations and include fairness/bias audits.
Glossary
- AdamW optimizer: Variant of Adam with decoupled weight decay for better generalization in deep learning. "with the AdamW optimizer~\cite{loshchilov2017decoupled} (betas: $0.9$, $0.999$; weight decay: $0.01$)"
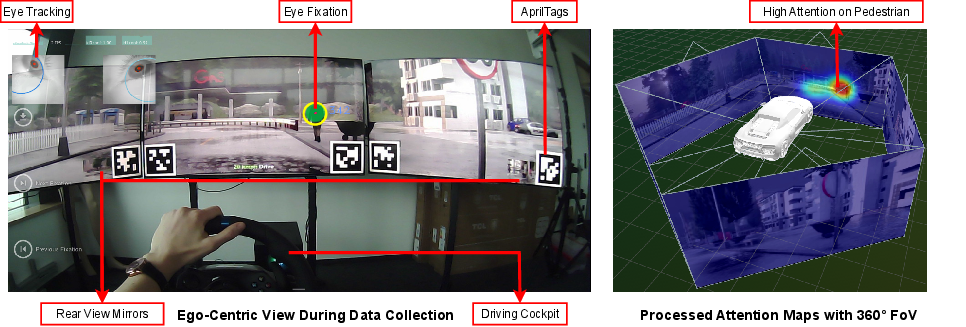
- AprilTags: Visual fiducial markers used for camera calibration and pose estimation. "AprilTags~\cite{olson2011tags} rendered in the simulated scene enable calibration between eye-tracker coordinates and simulator space."
- Attention decoder: Network module that produces a spatial attention (saliency) map from encoded features. "an attention decoder for driver attention prediction"
- Attended-object segmentation head: Decoder that segments only the objects currently attended by the driver. "Introducing the attended-object segmentation head (AttObjSeg) further boosts all attention metrics"
- Auxiliary semantic segmentation head: Additional decoder trained to predict semantic categories to improve the main task. "by employing an auxiliary semantic segmentation head."
- Bird’s-eye-view (BEV): Top-down representation of the road scene used for context-aware perception. "SCOUT+~\cite{scout_map} encodes bird'sâeyeâview road geometry via a map encoder"
- CARLA simulator: Open-source autonomous driving simulator for generating controllable driving scenarios and sensor data. "We use the CARLA simulator~\cite{dosovitskiy2017carla} due to its open-source support, reproducibility, and broad use in autonomous-driving research."
- Conv3D: 3D convolutional layers that process spatio-temporal volumes (video). "using Conv3D layers and ReLU activations"
- ConvLSTM: Recurrent convolutional network unit for modeling spatio-temporal dependencies. "BDDA~\cite{bdda} leveraged AlexNet~\cite{alexnet} features with ConvLSTMs to capture short-term temporal cues from front-facing video."
- Correlation Coefficient (CC): Metric quantifying the linear correlation between predicted and ground-truth saliency maps. "Correlation Coefficient (CC) which calculates the linear relationship between the ground truth and prediction,"
- Cross-entropy: Standard classification loss measuring the divergence between predicted and true label distributions. "minimizing the cross-entropy between the ground-truth and predicted segmentation maps"
- Dice coefficient: Overlap metric for segmentation accuracy emphasizing the harmonic mean of precision and recall. "For semantic segmentation, we use two common metrics, Dice coefficient and Intersection-over-Union (IoU)"
- Egocentric perspective: First-person viewpoint aligned with the driver’s field of view. "Egocentric perspective during a data collection with rainy weather and a pedestrian."
- Field of view (FoV): Angular extent of the observable scene captured by sensors or displays. "Resulting attention maps with a 360 FoV."
- Fixation map: Aggregated gaze distribution over time, represented as a probabilistic heatmap. "we build a fixation map by aggregating gaze within a 30-frame temporal window centered at time "
- Fixation–semantic fusion pipeline: Procedure combining gaze maps with instance masks to identify attended objects. "Attended Object Extraction: a fixation-semantic fusion pipeline that maps gaze distributions to object instances"
- Homography: Planar projective transformation mapping points between image planes. "Each gaze point is mapped to the CARLA image plane via a homography."
- Indicator function: Function returning 1 if a condition holds and 0 otherwise, used for binarization/mask creation. "where is element-wise multiplication and $\mathds{1}[\cdot]$ is an indicator function."
- Instance segmentation: Pixel-level labeling of distinct object instances and their classes. "Instance segmentation masks are extracted directly from CARLA."
- Intersection-over-Union (IoU): Segmentation accuracy metric measuring the ratio of overlap to union between prediction and ground truth. "For semantic segmentation, we use two common metrics, Dice coefficient and Intersection-over-Union (IoU)"
- Kullback–Leibler Divergence (KLD): Measure of dissimilarity between two probability distributions. "Kullback-Leibler Divergence (KLD) that measure distance between two probability distributions,"
- LiDAR: Light detection and ranging sensor providing 3D spatial measurements. "CARLA provides configurable camera, LiDAR, and control interfaces, and supports flexible scenario generation."
- Maximum entropy deep inverse reinforcement learning: IRL approach inferring reward functions under maximum entropy assumptions. "MEDIRL~\cite{medirl} used maximum entropy depth inverse reinforcement learning."
- Normalized Scanpath Saliency (NSS): Saliency metric evaluating standardized scores at fixation locations. "Normalized Scanpath Saliency (NSS) which measures the difference,"
- Omnidirectional modeling: Learning across the full 360° surround view to capture comprehensive spatial context. "enabling comprehensive omnidirectional modeling of driver gaze behavior."
- Panoramic attention prediction: Estimating attention over wide, stitched panoramic inputs. "our panoramic attention prediction approach, DriverGaze360-Net,"
- Pupil Core: Head-mounted eye-tracking device providing synchronized gaze and video streams. "We capture the eye gaze and the driver's egocentric perspective through the Pupil Core~\cite{pupilcore} eye-tracking glasses."
- SCENIC: Scenario specification language for generating diverse simulation scenes. "and SCENIC~\cite{fremont2023scenic} to produce varied traffic, agent behaviors, and weather conditions."
- Self-attention (shifted window): Attention mechanism computed within local windows that are shifted between layers to capture global context efficiently. "shifted window-based self-attention mechanism~\cite{liu2021swin}."
- Sim-to-real bias: Distributional gap between simulated data and real-world conditions affecting generalization. "To mitigate sim-to-real bias and ensure broad attention variability,"
- Swin Transformer (Swin-S): Hierarchical transformer architecture with shifted windows; “S” denotes a small model variant. "We use the Swin-S backbone pretrained on Kinetics-400~\cite{kay2017kinetics}."
- Video Swin Transformer (VST): Swin Transformer adapted for video to extract multi-scale spatio-temporal features. "We adopt the Video Swin Transformer (VST)~\cite{videoswintransformer} as the backbone"
- Vision Transformer (ViT): Transformer architecture for images that treats patches as tokens. "a vision transformer (ViT) based attention prediction model"
- YOLO-v11: Real-time object detection model used here to obtain instance masks. "and YOLO-v11~\cite{yolov11} is used for instance segmentation."
Collections
Sign up for free to add this paper to one or more collections.