- The paper introduces a dynamic, query-adaptive context selection framework that uses a RoBERTa classifier and LLM reranking to mitigate distractors and positional bias in multi-hop QA.
- It demonstrates that optimal context size and ordering significantly boost generation accuracy, with improvements quantified using EM and F1 metrics on the MuSiQue-Ans dataset.
- The work underscores the importance of balancing recall and precision by dynamically adjusting retrieved evidence, offering a flexible, architecture-agnostic enhancement for RAG systems.
Dynamic Context Selection for Retrieval-Augmented Generation: Mitigating Distractors and Positional Bias
Motivation and Problem Statement
Retrieval-Augmented Generation (RAG) architectures leverage external retrieved knowledge to enhance LLM performance on information-seeking tasks, such as multi-hop question answering (QA). Despite their efficacy, these systems routinely suffer from two critical deficiencies: (i) the introduction of distractor documents during retrieval, which degrade answer quality, and (ii) positional biases, notably the "lost in the middle" phenomenon, where models undervalue context not near the beginning or end of their input. The interplay between context relevance, the number of passages retrieved (k), and their order is especially consequential in multi-hop QA, where both under- and over-retrieval can be detrimental.
This work undertakes a comprehensive empirical analysis of these issues, formulates a dynamic context selection approach for RAG via a query-adaptive classifier and LLM-based reranker, and demonstrates that dynamically adapting both the quantity and position of retrieved evidence can yield statistically significant gains in multi-hop QA.
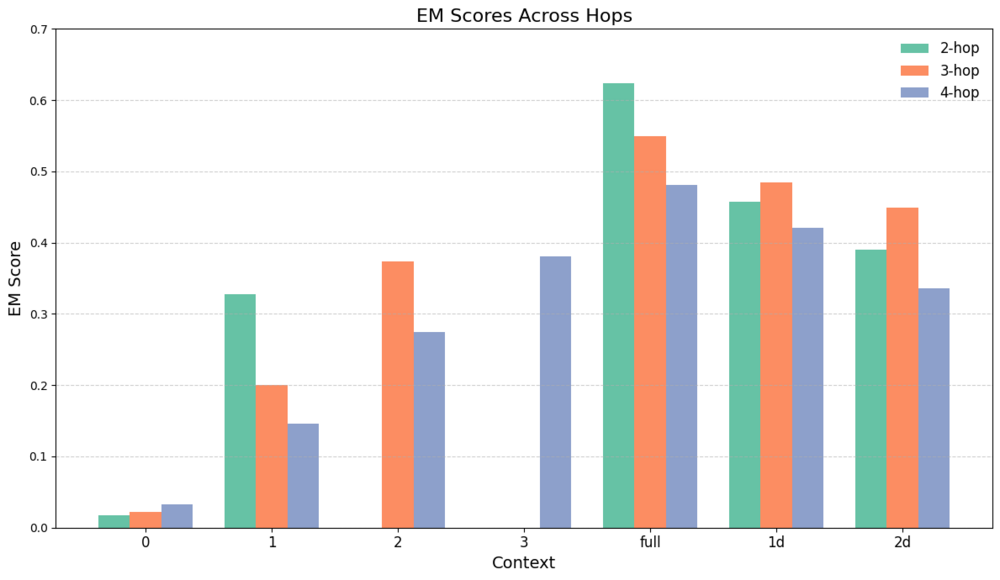
Empirical Analysis: The Effects of Context Size, Distractors, and Positional Bias
An in-depth evaluation is performed on the MuSiQue-Ans dataset, which features 2- to 4-hop questions, quantifying the sensitivity of generation performance to the amount and placement of relevant context, as well as the destructive effect of distractors.
The core findings from this analysis are:
The results strongly suggest that both context size and order are critical hyperparameters for RAG pipelines, particularly in noisy retrieval environments.
Dynamic Context Selection Framework
Building on these diagnostic observations, the authors propose a two-component augmentation to the standard RAG pipeline:
- Query-Specific Classifier (Classifier-k Pipeline): Utilizes a RoBERTa classifier, trained as a multi-class predictor on question complexity (2-, 3-, or 4-hop), to estimate query-specific optimal
k. This enables dynamic adjustment of retrieved context size.
- Classifier + LLM Reranker (Classifier-LLM Pipeline): Introduces an LLM (Mistral Nemo Instruct) to rerank and filter fixed-k retrieval candidates to the classifier-predicted
k, selecting the most relevant passages. Optionally, selected passages are reordered such that the highest-relevance ones appear at the end, harnessing positional bias.
The interaction of these modules is depicted in the architectural flowchart below.
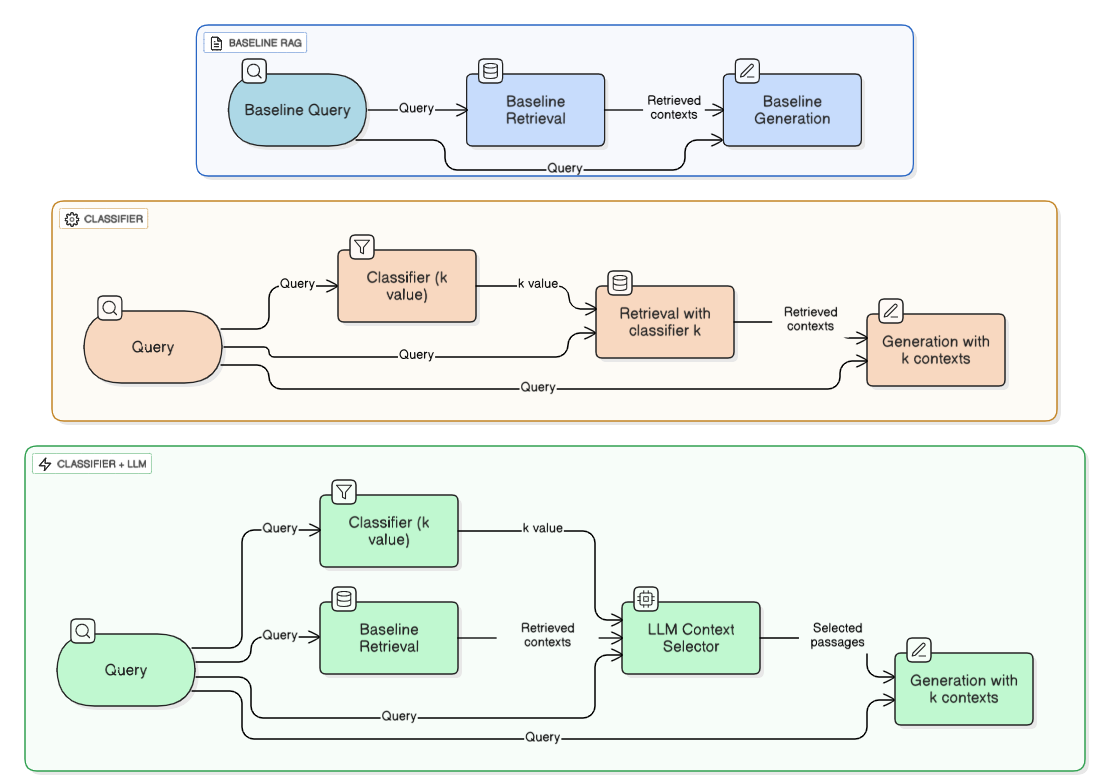
Figure 2: Diagram of Baseline Pipeline, Classifier-k Pipeline, and Classifier-k+LLM pipeline.
Notably, the classifier achieves 87.3% accuracy (exact match) when trained on all datasets, revealing effective transferability across multi-hop QA benchmarks.
Experimental Results
A comprehensive suite of experiments compares the baseline (fixed-k), classifier-k, and classifier-LLM pipelines, using BM25, dense (MiniLM), and hybrid ColBERT + reranker retrieval.
Key quantitative outcomes:
- Classifier-k pipeline alone: Improved precision but decreased recall, occasionally underperforming the baseline due to missed relevant evidence in lower ranks—especially with imperfect retrieval.
- Oracle Analysis: With an ideal retriever, classifier-k surpasses any fixed-k strategy. Similarly, an oracle reranker + classifier-k setup achieves maximal gains.
- Classifier-LLM pipeline: Statistically significant improvements on all datasets, all retrieval regimes. With reranked and appropriately positioned context, maximum F1 and EM is obtained. For example, BGE retriever with Classifier+LLM attains 0.199 EM and 0.283 F1 on MuSiQue, both superior to all other pipelines.
Explicitly, positioning the most relevant texts at the end offers additional, reproducible improvement, directly mitigating LLM position bias.
Theoretical and Practical Implications
The principal theoretical implication is a formal dissociation between retrieval precision and optimal context size: increasing k enhances recall but rapidly escalates distractor risk, requiring context-sensitive adaptation on a per-query basis. The findings confirm and quantify the destructiveness of distractors in RAG and identify input ordering as a second-order, yet potent, modulator of RAG performance.
Practically, integrating a query-adaptive selection mechanism with LLM-based reranking is shown to robustly outperform fixed-k baselines, especially in multi-hop settings where reasoning requirements vary substantially by question. The proposed method is architecture-agnostic and compatible with a range of retrieval and generation models.
Future research directions include joint training of classifier and retriever, more sophisticated modeling of interaction effects between passage semantics and LLM attention, and application to other generative domains with long-context requirements.
Conclusion
This work systematically diagnoses and addresses two persistent failure modes in RAG—distractor susceptibility and positional bias—using specialized empirical analysis and a two-stage dynamic context selection framework. Classifier-driven k selection, complemented by LLM reranking and relevance-sensitive ordering, delivers consistent, statistically significant improvements on challenging multi-hop benchmarks. The study delineates clear avenues for further refinement in context-aware retrieval and presents new benchmarks for RAG system design.