Vector Prism: Animating Vector Graphics by Stratifying Semantic Structure
Abstract: Scalable Vector Graphics (SVG) are central to modern web design, and the demand to animate them continues to grow as web environments become increasingly dynamic. Yet automating the animation of vector graphics remains challenging for vision-LLMs (VLMs) despite recent progress in code generation and motion planning. VLMs routinely mis-handle SVGs, since visually coherent parts are often fragmented into low-level shapes that offer little guidance of which elements should move together. In this paper, we introduce a framework that recovers the semantic structure required for reliable SVG animation and reveals the missing layer that current VLM systems overlook. This is achieved through a statistical aggregation of multiple weak part predictions, allowing the system to stably infer semantics from noisy predictions. By reorganizing SVGs into semantic groups, our approach enables VLMs to produce animations with far greater coherence. Our experiments demonstrate substantial gains over existing approaches, suggesting that semantic recovery is the key step that unlocks robust SVG animation and supports more interpretable interactions between VLMs and vector graphics.








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
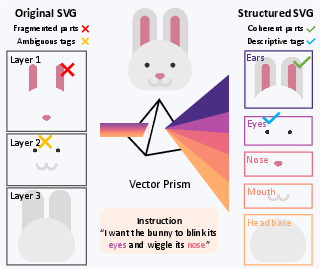
This paper introduces Vector Prism, a new way to help AI automatically animate SVG images (the kinds of graphics used on websites that stay sharp at any size). The main idea is simple: before you can animate something, you need to know what the meaningful parts are (like “eye,” “wheel,” or “leaf”), but SVG files often break objects into many tiny shapes that don’t match how humans think. Vector Prism “rebuilds” that meaning so animation is smooth, logical, and easy to control.
Key Questions
The paper focuses on three easy-to-understand questions:
- Why do current AI models struggle to animate SVGs correctly?
- Can we automatically find and group the meaningful parts inside messy SVG files?
- If we do that grouping, will animations become more coherent, better-looking, and closer to the user’s instructions?
How It Works (Step-by-step, in everyday terms)
Think of an SVG as a puzzle made of many small pieces (paths, circles, rectangles). The challenge is figuring out which pieces belong together (like all the parts of a face, or all the parts of a button) so you can move them as one.
Vector Prism does this in three main stages:
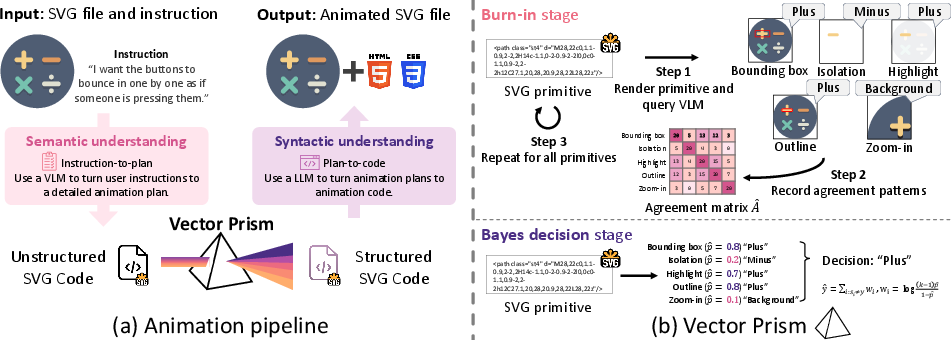
1) Planning the animation
- The system shows the whole image to a vision–LLM (a VLM—an AI that can look at pictures and understand text).
- You give a simple instruction like “make the sun rise.”
- The AI plans what should move (the sun) and how (up) in plain terms.
2) Recovering the parts (the “prism” step)
- Each small SVG shape (a “primitive”) is shown to the AI in several different ways, like:
- highlighted on the full image,
- zoomed in,
- isolated on a blank background,
- outlined with a box.
- For every view, the AI guesses what that piece is (e.g., “left ear,” “cloud,” “button”).
- Not all views are equally helpful—some make the AI guess better than others.
Here’s the clever part:
- The system looks at how often different views agree with each other across many pieces.
- Using a simple statistical idea (like figuring out which judges are more trustworthy by checking their consistency), it estimates which views are usually right and which ones are noisy.
- Then, when deciding the final label for each piece, it gives more weight to the trustworthy views and less weight to the unreliable ones. This is like asking a group of friends for advice, but listening more to the ones who’ve been reliably right in the past.
Result: Every tiny shape gets a strong, reliable “semantic label” (what it actually represents).
3) Restructuring and animating
- With those labels, the SVG file is reorganized into meaningful groups (all parts of the sun together, all parts of the face together, etc.), without changing how it looks.
- Now the AI can attach motion to the right groups using simple CSS animations (the same technology that styles web pages), and generate code step-by-step so it doesn’t run into length limits.
Main Findings and Why They Matter
- Better instruction following: When asked to do things like “make the compass needle spin once” or “fade raindrops in and out,” the animations match the instructions more closely than other methods.
- Higher visual quality: Movements look cleaner and more stable because they act on meaningful parts, not random tiny shapes.
- Smaller files and faster web performance: Vector animations stay compact because they animate shapes, not thousands of pixels like videos. The paper shows big size savings compared to video generators, which is great for websites and mobile users.
- Strong human preference: In user tests, people often preferred animations made with Vector Prism over those from other systems, including popular video models.
- More organized SVGs: A technical measure of “how tidy the groups are” shows huge improvement once the system reorganizes the SVG by meaning, which makes later edits and animations easier.
Implications and Impact
- For designers and developers: You can turn static SVGs into lively animations more reliably, even with simple instructions, speeding up web design and making interfaces more engaging.
- For AI systems: Teaching AI to recover and use real “parts” unlocks better control and less guesswork. This idea can also help in other areas, like 3D scenes or diagrams, where structure matters.
- For users: Pages load faster, animations look smoother, and effects respond well to what you ask.
Limitations (and future directions)
- If an SVG has one huge shape for something that needs to break into pieces (like a lightning bolt that should “shatter”), the system can’t split it automatically yet. It works with the pieces that already exist.
- Future work could add ways to subdivide big shapes or use tools that generate SVGs with more detailed parts.
In short, Vector Prism shows that the key to good SVG animation isn’t just writing more code—it’s recovering the hidden “meaningful parts” inside the art so AI can move the right things, in the right way.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper. Each point is framed to enable concrete follow-up research.
- Statistical modeling assumptions: The Dawid–Skene setup assumes uniform error over incorrect labels and independence across rendering methods; investigate label-dependent confusion matrices, correlated render views, and context-conditional reliabilities (e.g., per category or per primitive type).
- Reliability estimation granularity: Reliabilities are estimated per SVG and treated as constant across all primitives within that file; assess per-class and per-primitive reliability modeling, and adaptive reliabilities that vary with local visual context.
- Prior integration: Bayes decision uses a uniform prior over classes; evaluate using priors derived from the planning stage (e.g., expected part frequencies), class imbalance handling, or learned priors from corpora of SVGs.
- Sample efficiency and stability: Agreement matrices are estimated with a single burn-in pass; quantify sample size requirements, small-sample bias, and propose variance-reduced or regularized estimators for cases with few primitives or many classes.
- View selection and optimization: The set and number of rendering views (highlight, isolation, zoom, outline, bbox) are hand-crafted; study how to systematically design, select, or learn optimal views, and whether fewer views suffice via active or adaptive selection.
- Cross-SVG transfer: Reliabilities are not shared across SVGs; test whether meta-learned reliabilities (global or per-genre/style) can reduce burn-in costs and improve performance on new files.
- Error propagation from planning: Semantic categories are fixed by the VLM’s planning stage; develop feedback loops to refine categories, allow splits/merges, handle uncertain K (unknown number of parts), and reconcile conflicting or ambiguous semantics.
- Multi-label and hierarchy: Elements can belong to multiple semantic roles or hierarchical parts; extend the framework to multi-label assignments and to recover parent–child relationships (e.g., eyelid within eye), not just flat groups.
- Atomic primitive limitation: The method treats primitives as indivisible; design automatic subdivision (path segmentation, stroke splitting, boolean ops) to support instructions that require decomposing coarse shapes (e.g., “shatter into pieces”).
- Complex SVG features: Flattening and regrouping may break or complicate advanced SVG constructs (clipPath, mask, filter, gradient/pattern fills, defs/use symbols, nested transforms); evaluate robustness and propose safe restructuring strategies for these cases.
- Appearance preservation guarantees: Overlap checks and paint-order preservation are described but not formally validated; provide proofs or stress tests ensuring identical rendering post-restructure across diverse SVG features.
- CSS-centric generation limits: Many desired animations need properties not animatable via CSS (e.g., path “d” morphing, filter parameter changes, physics); explore automated JavaScript/Web Animations API/SMIL or GSAP generation with correctness checks.
- Cross-browser compatibility: Animations are advised to be viewed in specific viewers; systematically test and document compatibility across browsers/devices, including reduced-motion preferences and accessibility best practices.
- Scalability and compute: Rendering M views for N primitives scales poorly for large SVGs; measure computational cost, propose pruning, batching, caching, or progressive labeling to keep latency acceptable for real-time workflows.
- Robustness to style diversity: Gradients, strokes with complex dashes, transparency, filters, and dense overlaps may confuse VLM labeling; benchmark failure rates across stylistic axes and augment with geometry/code-level features (path metrics, transform stacks).
- Evaluation validity: CLIP-T2V, GPT-T2V, and DOVER are designed for raster videos; develop or adopt metrics tailored to vector animation fidelity, semantics, and instruction adherence (e.g., part-wise motion correctness, temporal alignment scores).
- Baseline breadth and fairness: Comparisons omit recent vector-LLM systems (e.g., InternSVG, OmniSVG, StarVector as animation planning engines); add these baselines and ensure equivalent planning and code-generation settings for apples-to-apples comparisons.
- Ablations and causality: Provide quantitative ablations isolating contributions of multi-view rendering, reliability estimation, Bayes decision vs majority voting, and restructuring; tie improvements in metrics to specific pipeline components.
- Dataset representativeness: The 114 SVG–instruction set is curated but its diversity, provenance, and biases are unclear; release the dataset, report coverage (primitive counts, feature usage), and include harder, real-world SVGs (logos with filters, maps, UI icons).
- Human study scale and rigor: The user study (19 participants, 760 comparisons) needs statistical significance reporting, inter-rater reliability, and stratified analyses by instruction type and SVG complexity; expand participant diversity and tasks.
- Generalization across VLMs: Results rely on GPT-5-nano for labeling and GPT-5 for code; test across multiple open-source and commercial VLMs, measure sensitivity to model choice, and provide guidance for low-resource or on-device models.
- Safety and privacy: The pipeline likely sends SVG-derived images to external VLMs; assess privacy risks, support local models, and propose anonymization or on-prem alternatives for sensitive assets.
- Reliability theory and proofs: A “probability bound” advantage over majority voting is deferred to the appendix; formalize and empirically validate the bounds under non-ideal conditions (finite samples, correlated views, non-uniform confusions).
- Semantic relationship constraints: Many instructions require coordinated motion across parts (e.g., hinge, orbit, layered parallax); model and recover inter-part constraints (graphs of relations) beyond independent grouping.
- Deployment in production: Measure end-to-end latency, file-size savings vs raster pipelines at scale, caching strategies, and integration into modern web stacks (React/Vue, design systems), including fallbacks when animation support is limited.
- Extension to other symbolic domains: Claims of generalizability to 3D assets and scenes are not demonstrated; design and evaluate analogous stratification for 3D (hierarchies, transform stacks, materials) and test with language-driven animation of CAD/GLTF.
Practical Applications
Immediate Applications
Below are deployable use cases that leverage Vector Prism’s semantic restructuring of SVGs and its VLM-driven animation pipeline today.
- Semantic SVG “repair” and animation-ready conversion for web assets
- Sector: Software/Web, Marketing, E‑commerce, Media
- What: A CLI/service that ingests raw SVGs, infers semantic groups via multi-view VLM + Dawid–Skene, flattens paint order, adds class tags, and outputs animation-ready SVG + CSS.
- Tools/Products:
- npm package/CLI (“vector-prism”) for frontend pipelines
- Figma/Illustrator plugin to export “animation-ready” SVGs
- GitHub Action to auto-lint and restructure SVGs on PRs
- Dependencies/Assumptions:
- Sufficient SVG granularity (primitives exist for target parts)
- VLM access (API or local model) and multi-view rendering
- Browser CSS animation support and safe CSS injection policies
- No‑code animation authoring for CMS and site builders
- Sector: Web/CMS (WordPress, Webflow, Squarespace), SMBs
- What: A widget that lets users upload an SVG, type “make the compass needle spin once,” and get a compressed, resolution‑independent animation.
- Tools/Products:
- CMS plugin with prompt box and preview
- Embeddable web component (Web Animations API/Lottie export)
- Dependencies/Assumptions:
- Prompt quality and instruction clarity
- Token limits handled via iterative generation
- Content security policies for injected CSS/JS
- Design-system automation for icons and micro‑interactions
- Sector: Product Design, UI/UX, Design Ops
- What: Batch process icon libraries (SVGRepo, internal sets) to add semantic classes (e.g., eye, mouth, outline) and attach standard hover/load animations.
- Tools/Products:
- Design tokens + class naming conventions exported with assets
- CI step that validates motion against style guides
- Dependencies/Assumptions:
- Stable style taxonomy across icon sets
- Paint-order preservation during restructuring
- Performance‑first creative for ad tech and marketing
- Sector: Advertising, Marketing Tech
- What: Swap heavy .mp4/.gif creatives for semantically animated SVGs, lowering size by 10–50× while keeping visual fidelity.
- Tools/Products:
- Creative pipeline that outputs CSS animations per placement
- A/B testing harness to compare CTR/viewability with vector vs raster
- Dependencies/Assumptions:
- Platform ad policies allow SVG/CSS animations
- Cross-browser rendering parity
- Data visualization motion cues (storytelling and onboarding)
- Sector: Analytics/BI, Education, Journalism
- What: Animate SVG charts and explanatory diagrams by tagging plot elements (axes, ticks, legends, series) and applying guided transitions.
- Tools/Products:
- Plug-in for D3/Observable/Chart.js SVG exports
- “Explain this chart” onboarding sequences generated from prompts
- Dependencies/Assumptions:
- Chart SVGs with separable primitives (lines, markers, labels)
- Consistent class mapping between chart libraries and restructured SVGs
- Lightweight localization and accessibility enhancements
- Sector: Public Sector, NGOs, Education
- What: Align semantic groups with ARIA roles/class names to ease localization (e.g., focus animation on “legend” or “button” parts).
- Tools/Products:
- Exporter that adds descriptive class names for screen-reader tooling
- Dependencies/Assumptions:
- Coordination with accessibility guidelines (WCAG/ARIA)
- Human review for localized semantics
- Developer QA and linting for vector assets
- Sector: Software Tooling
- What: A “semantic SVG linter” that flags animation-unfriendly structures (deep transforms, mixed group semantics) and suggests fixes.
- Tools/Products:
- VS Code extension with preview and auto-fix
- DBI-like cluster stability score in CI reports
- Dependencies/Assumptions:
- Availability of multi-view renders during CI
- Stable, reproducible VLM predictions under fixed prompts
- Low‑bandwidth delivery for mobile/web in constrained networks
- Sector: Telecom, Emerging Markets, News/Content platforms
- What: Replace raster explainer videos with animated SVGs to reduce data transfer and speed up load times on low-end devices.
- Tools/Products:
- CDN rules to prefer vector assets for specific routes
- Server-side microservice for SVG-to-animation on demand
- Dependencies/Assumptions:
- Client support for SVG/CSS animations
- Fallbacks for legacy browsers
Long-Term Applications
The following applications require further research, scaling, or productization beyond the current paper (e.g., generalization to new modalities, richer tooling, or new standards).
- Generalized semantic restructuring for CAD/3D scenes and robotics
- Sector: Manufacturing, Robotics, AR/VR
- What: Extend the statistical aggregation approach to part-level semantics in CAD/URDF/GLTF, enabling LLMs to plan assembly/disassembly or robot interaction on meaningful parts.
- Tools/Products:
- “3D Prism” that infers part semantics across multiple render views
- Robotics planners that attach actions to semantically grouped parts
- Dependencies/Assumptions:
- Reliable multi-view labeling for 3D (occlusion handling)
- Adaptation of the error model beyond uniform mislabeling
- Semantic code refactoring for UI frameworks (React/Vue) via visual cues
- Sector: Software Engineering, Low-code/No-code
- What: Recover component semantics from rendered UIs (HTML/CSS) and refactor into reusable, animated React components aligned with design intent.
- Tools/Products:
- “UI Prism” that maps DOM nodes to semantic components, autogenerates motion variants
- Dependencies/Assumptions:
- Stable DOM-to-visual mapping and tolerance to CSS complexity
- New datasets/benchmarks for component-level semantics
- Procedural motion design co‑pilots for creative suites
- Sector: Creative Tools (Figma, Adobe), Media
- What: An assistant that proposes coherent motion primitives from semantics (e.g., staggered entrances for labeled subparts) and exports to CSS/Lottie/After Effects.
- Tools/Products:
- In-editor “Animate by Intent” pane with preview and parameter sliders
- Dependencies/Assumptions:
- Tight APIs with design tools and reliable semantic export
- Expanded prompt engineering for fine-grained timing/easing control
- Standards and best practices for semantic SVGs
- Sector: Standards/Policy, W3C, Accessibility
- What: Propose a lightweight metadata schema or class naming conventions for “animation-ready SVG” in web standards and gov procurement guidelines.
- Tools/Products:
- Open specification and validation tools
- Training resources for government/NGO teams
- Dependencies/Assumptions:
- Community and vendor buy‑in; backward compatibility with existing SVGs
- Clear benefits demonstrated across accessibility and performance
- Education and healthcare explainers at scale
- Sector: Education, Healthcare
- What: Libraries of semantically structured SVGs for biology, mechanics, or patient education, enabling consistent, accessible animations across curricula/portals.
- Tools/Products:
- Open repositories of labeled SVG modules with templated motions
- Dependencies/Assumptions:
- Domain-validated semantics and review (safety/accuracy for medical content)
- Authoring tools for educators/clinicians
- Data-storytelling agents that synchronize narrative and motion
- Sector: Analytics, Media, Finance
- What: Agents that turn scripts into animated dashboards by mapping textual highlights to semantically grouped chart parts and timed transitions.
- Tools/Products:
- “Narrate my dashboard” assistant integrated with BI platforms
- Dependencies/Assumptions:
- Robust extraction of semantic roles in complex multi-layer charts
- Guardrails for misinterpretation of data semantics
- Automatic SVG primitive subdivision for coarse assets
- Sector: Design, Web, Open-Source Graphics
- What: When input SVGs lack granularity, auto-split complex paths into subparts aligned with prospective motion plans.
- Tools/Products:
- Path segmentation model integrated into the restructuring pipeline
- Dependencies/Assumptions:
- Reliable heuristics or learned models for perceptual part boundaries
- Avoidance of visual regressions post-split
- On-device, private animation generation for privacy‑sensitive domains
- Sector: Finance, Healthcare, GovTech
- What: Run lightweight VLMs locally to perform semantic recovery and animation without uploading assets to cloud.
- Tools/Products:
- Quantized VLMs and GPU‑less rendering pipelines on client devices
- Dependencies/Assumptions:
- Sufficient on-device compute and memory
- Energy/performance trade-offs acceptable for UX
- Cross‑modal authoring: text-to-vector motion plus fallback raster export
- Sector: Publishing, Social Media, Ad Tech
- What: Author once in vectors; auto-export to MP4/GIF for platforms that disallow SVGs while keeping a single semantic source of truth.
- Tools/Products:
- Exporters targeting WAAPI, Lottie, MP4 with timing fidelity checks
- Dependencies/Assumptions:
- Consistent timing/easing mapping across animation backends
- Regression tests to prevent behavior drift
- Evaluation and benchmarking for symbolic semantic recovery
- Sector: Academia/Research
- What: Datasets and metrics (e.g., DBI-style semantic cohesion, instruction-to-motion faithfulness) for SVG and other symbolic formats.
- Tools/Products:
- Benchmarks combining ground-truth part labels with animation tasks
- Dependencies/Assumptions:
- Community-curated corpora with permissive licenses
- Agreement on task definitions and scoring
Notes on feasibility across applications:
- Core dependencies: reliable multi-view rendering, VLM quality, and SVG granularity. The Dawid–Skene aggregation assumes per-view error independence and near-uniform misclassification among non-true labels; deviations may reduce robustness.
- Operational constraints: API latency/cost for VLM calls, token limits (mitigated by iterative generation), and browser CSS support/security policies.
- Human-in-the-loop: for high-stakes content (healthcare, finance), expert review of semantics and motions is advisable despite automated recovery.
Glossary
- Agreement matrix: A matrix capturing how often different renderings’ labels agree, used to estimate method reliabilities. "The agreement matrix $can be empirically estimated by a burn-in pass, traversing the SVG primitives and collecting the agreement patterns" - **AniClipart**: An optimization-based vector animation approach that uses diffusion priors and SDS to adjust motion parameters. "AniClipart~\cite{aniclipart} represents the optimization-based animation methods, which optimizes animation parameters such as keypoint movements, using the Score Distillation Sampling loss~\cite{sds}." - **Bayes' decision rule**: A rule selecting labels that maximize posterior probability given observed signals and prior assumptions. "A Bayes decision rule then selects labels that minimize expected classification error and recover the most plausible true part structure." - **Burn-in stage**: An initial pass over data to collect statistics (e.g., agreements) for parameter estimation before final inference. "During the burn-in stage, where agreement patterns are collected, a single full pass over all primitives within each SVG provides a good balance between estimation stability and computational efficiency." - **CLIP-T2V**: A text-to-video alignment metric using CLIP to evaluate how well videos follow instructions. "Following InternSVG~\cite{wang2025internsvg}, we measure the correspondence between animation instructions and rendered videos using a video-pretrained CLIP model~\cite{viclip,clip}, referred to as CLIP-T2V." - **Dawid-Skene model**: A probabilistic model for inferring true labels and annotator accuracies from noisy labels. "We assume a Dawid-Skene model~\cite{dawid1979maximum} for each rendering method," - **Davies–Bouldin index (DBI)**: A clustering metric comparing intra-cluster scatter to inter-cluster separation. "We treat each semantic group as a cluster and measure clustering quality using the Davies-Bouldin index (DBI)~\cite{dbi}, a metric that quantifies the ratio of within-cluster scatter to between-cluster separation." - **DINO v3**: A self-supervised vision model used to compute semantically meaningful feature embeddings. "We compute distances in the feature space of DINO v3~\cite{simeoni2025dinov3}, which provides semantically meaningful visual embeddings." - **DOVER**: A video quality assessment model capturing aesthetic and technical fidelity. "Finally, we assess perceptual quality with DOVER~\cite{wu2023dover}, an off-the-shelf video quality assessment model that captures both technical fidelity and visual aesthetics." - **Eigenvalue**: A scalar indicating how a matrix scales an associated eigenvector. "Let and, then" - **Eigenvector**: A vector whose direction is preserved under a linear transformation by a matrix. "Let and, then" - **Majority voting**: A label aggregation method that selects the most frequently predicted class. "Instead of aggregating these predictions using simple majority voting, Vector Prism interprets these predictions through the lens of a statistical inference process~\cite{dawid1979maximum}." - **Outer product**: A matrix formed from two vectors whose result is rank-one under ideal conditions. "which is the outer product of ." - **Paint order**: The sequence in which SVG elements are drawn, affecting visual stacking and overlaps. "Primitives are then regrouped by label while maintaining the original paint order." - **Rasterized renderings**: Pixel-based images produced from vector graphics for processing by vision models. "Since the SDS objective acts on rasterized renderings rather than vector structure, it encourages appearance preserving changes and resists large part rearrangements that animation often needs." - **Rank one**: A matrix whose rows (or columns) are scalar multiples of a single vector. "Matrix$ is rank one on the off-diagonals"</li> <li><strong>Score Distillation Sampling (SDS)</strong>: An optimization objective that transfers guidance from diffusion models to target parameters. "via score distillation sampling (SDS)~\cite{sds,ldm,svd}."</li> <li><strong>Semantic wrangling</strong>: The process of reorganizing SVGs into semantically coherent, animatable structures. "It then proceeds to semantic wrangling (\ref{sec:method-vp}), where the SVG is restructured into a semantically meaningful and animatable form through a statistical inference, and finally to animation generation (\ref{sec:method-animate}), which produces executable animation code."</li> <li><strong>Semantic–syntactic divide</strong>: The mismatch between human-understandable visual parts and the code-level SVG structure. "Bridging this semanticâsyntactic divide is precisely the role of the restructuring stage."</li> <li><strong>Semantic–syntactic gap</strong>: A broader formulation of the divide that hinders VLMs from effective SVG animation. "we introduced Vector Prism, a novel framework designed to overcome the critical semantic-syntactic gap that prevents modern vision-LLMs (VLMs) from successfully animating Scalable Vector Graphics (SVGs)."</li> <li><strong>SVG primitives</strong>: The basic shape elements (e.g., path, rect) that compose SVG graphics. "All SVG primitives are rendered at $512\times512$ resolution when given as a VLM input for analysis."
- Uniform prior: An assumption giving equal prior probability to all labels in Bayesian inference. "Bayes' decision rule with a uniform prior"
- Vision–LLM (VLM): A multimodal model that jointly understands visual inputs and text. "Recent advances in vision-LLMs (VLMs)~\cite{llava, gpt5, qwen3} offer a tempting possibility, which is generating animations simply by instructing a VLM given the SVG file."
- Weighted vote: A voting scheme where each signal’s contribution is scaled by its reliability. "This is equivalent to a weighted vote with"
Collections
Sign up for free to add this paper to one or more collections.