- The paper demonstrates that employing semantic-guided token pruning alongside block- and vector-level concentration can achieve over 80% computation reduction with minimal accuracy loss.
- It introduces a streaming, hardware-efficient mechanism integrated into systolic arrays for localized processing and lossless output reconstruction.
- Empirical results reveal up to 4.47× speedup over vanilla systolic arrays and significant energy savings, underscoring the architecture’s scalability for diverse VLM applications.
Focus: Streaming Multilevel Concentration for Efficient Vision-LLM Acceleration
Introduction and Motivation
This work introduces Focus, a hardware-software co-designed architecture specifically engineered for efficient Vision-LLM (VLM) inference via progressive and fine-grained elimination of redundancy in vision-language input sequences. The authors identify that state-of-the-art VLMs used for tasks such as video captioning and VQA exhibit massive computational and memory demands driven by dense tokenization of high-redundancy visual streams. Existing algorithmic token pruning and merging techniques typically operate at token-level granularity, largely decoupled from underlying hardware topology, resulting in limited sparsity utilization and suboptimal energy-compute trade-offs. Furthermore, VLMs manifest redundancy not only along the visual axis but across modalities in a context-dependent manner, which most prior approaches fail to exploit.
The proposed Focus architecture targets this gap by introducing a multilevel, fully-streaming concentration paradigm that hierarchically compresses joint vision-language sequences using: (1) semantic-guided token pruning, (2) spatial-temporal block-level similarity, and (3) vector-level motion-aware matching. All concentration stages are realized as low-overhead, modular, and on-chip hardware units positioned to intercept tiles between GEMM stages within systolic-array accelerators, maximizing on-chip data locality and reducing DRAM bandwidth.
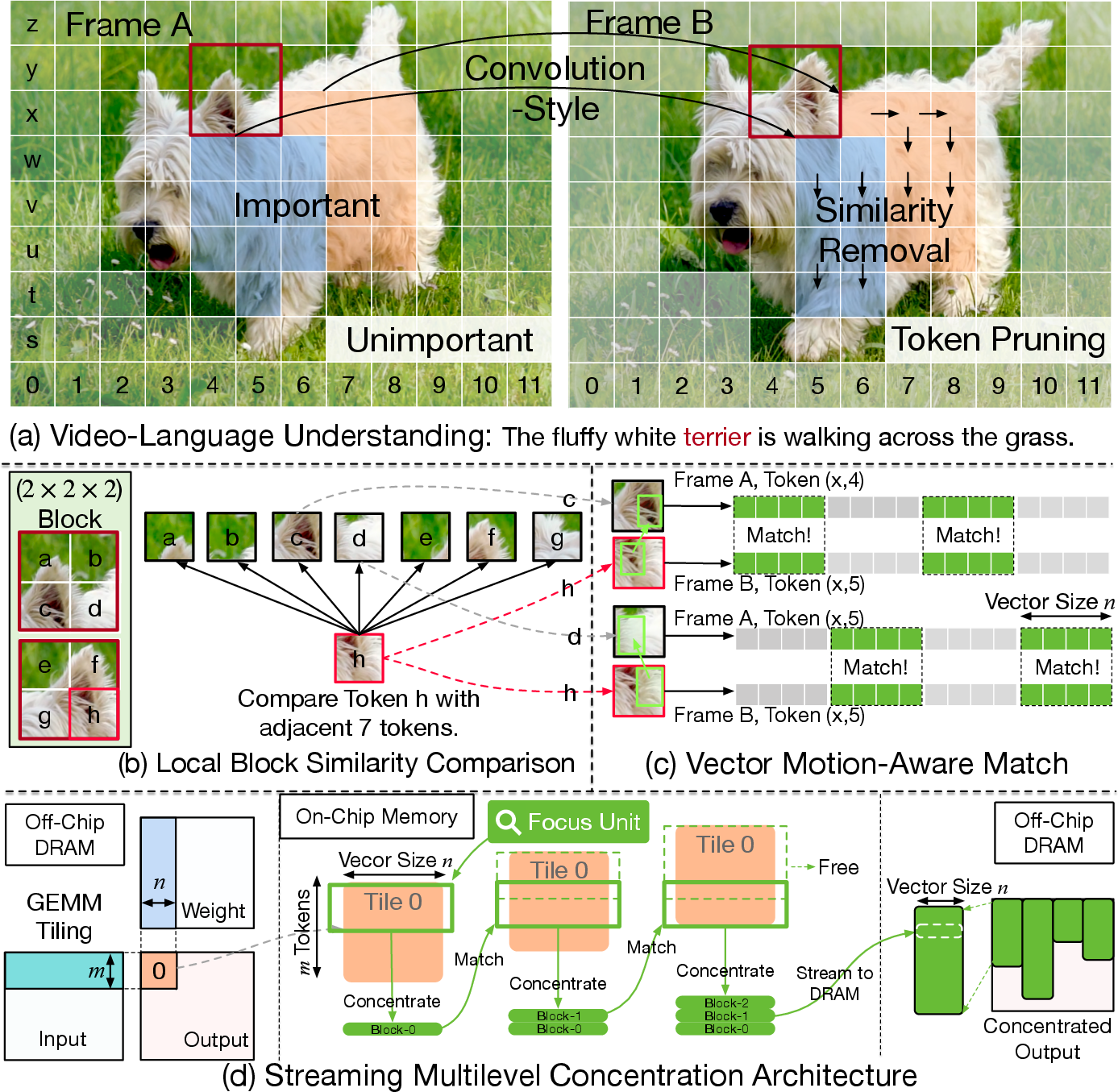
Figure 1: Overview of the streaming multilevel concentration architecture.
Detailed Methodology
Multilevel Concentration: Semantic, Block, and Vector-Level Redundancy
Focus implements three interlocked redundancy-removal strategies that target distinct sources of excess computation:
- Semantic-guided Token Pruning: Unlike prior methods based on static saliency or magnitude, Focus' semantic concentration uses prompt-aware cross-modal attention to identify and retain only those visual tokens that are contextually relevant to the input text, which is critical for tasks with rapidly shifting attention across scenes or objects.
- Block-Level Concentration: Using a sliding window over spatiotemporal neighborhoods, Focus performs localized redundancy checks wherein each block key is compared with neighbors, analogous to a 3D convolution. This facilitates efficient exploitation of redundancy in temporally-adjacent video frames without engaging global token matching or requiring large buffers.
- Vector-Level Redundancy Removal: Within each block, Focus performs fine-grained vector-wise similarity computation, matching sub-token vector partitions across adjacent tokens. This design exploits partial spatial correlation and motion, unlocking sparsity not accessible to token-level matching and offering >80% compute reduction while preserving semantic content.
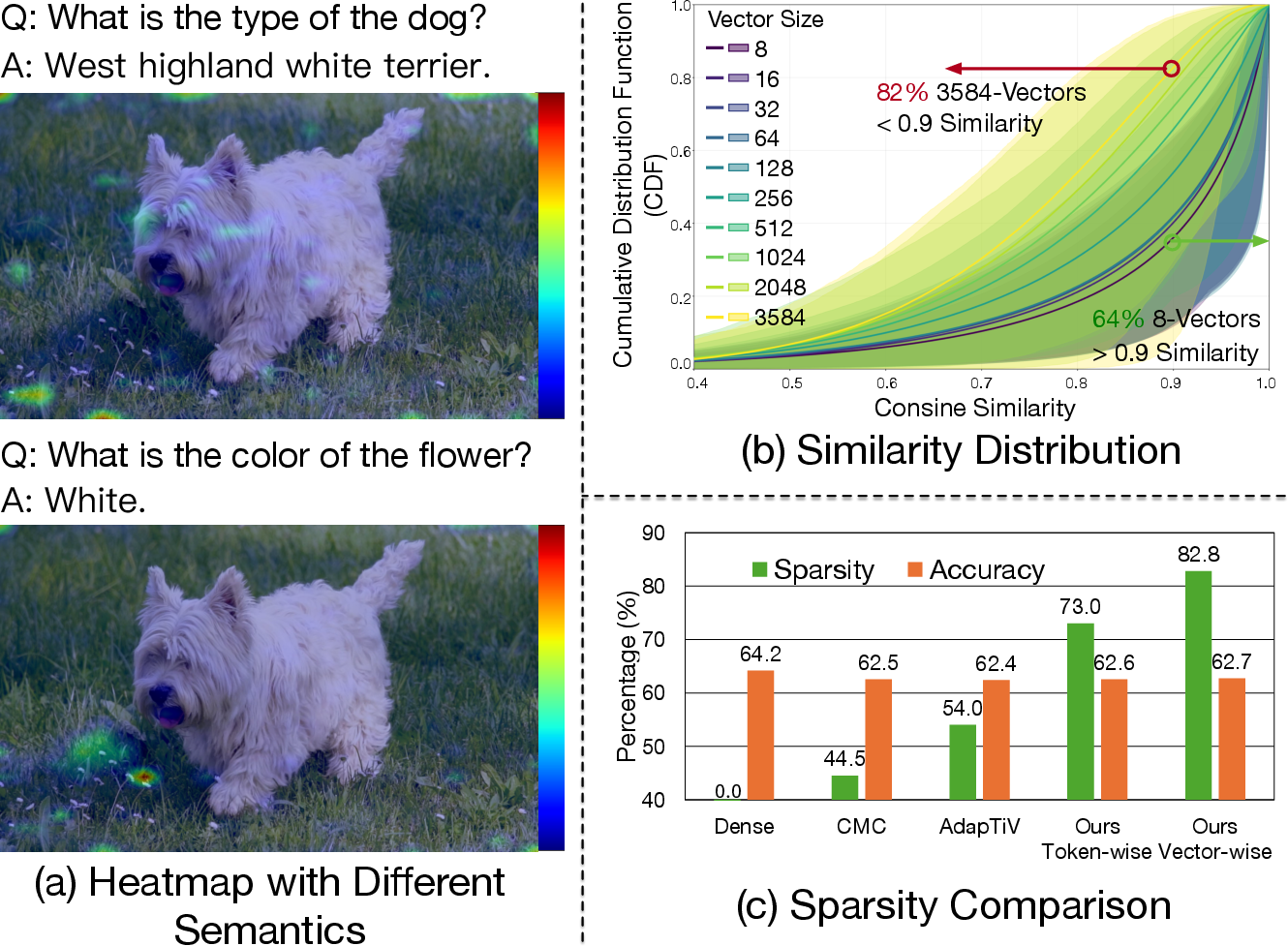
Figure 2: Motivation for multilevel concentration with prompt-aware attention heatmaps and redundancy analysis showcasing the index sensitivity of VLM attention.
A central design attribute is that each removal phase is streaming and fully localized (i.e., does not require waiting for full token sequences or complete frames), which aligns well with pipelined, tiling-based GEMM computation.
Hardware-Algorithm Co-Design
Streaming Focus Unit
Focus integrates two key hardware modules within the accelerator pipeline:
- Semantic Concentrator (SEC): Embedded in the attention layer compute flow, the SEC uses on-the-fly importance analysis and top-k sorting logic to retain relevant tokens based on cross-modal attention matrices, with offset encoding to track pruned token indices for downstream alignment.
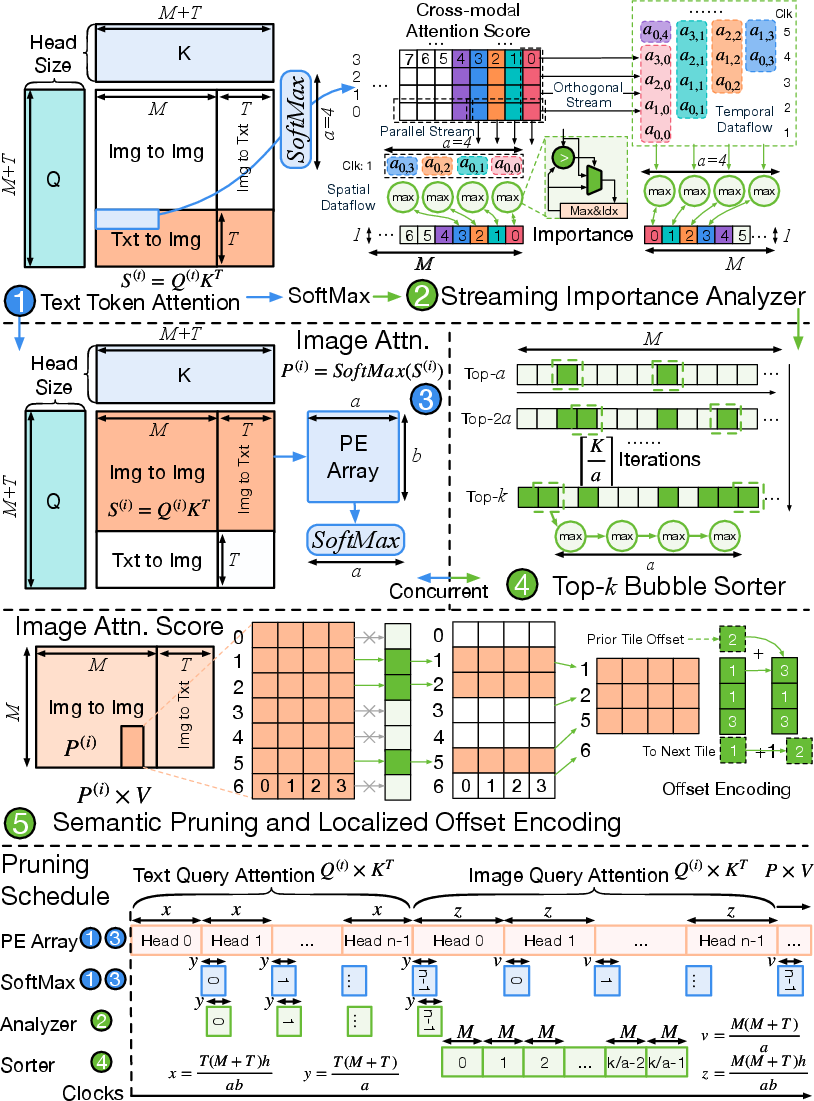
Figure 3: Overview of the Semantic Concentrator detailing the importance analyzer, top-k sorter, and offset encoder with full streaming support.
- Similarity Concentrator (SIC): Post-GEMM, SIC applies convolution-style tiling to reorganize outputs into spatiotemporal blocks for localized, vector-wise redundancy elimination using cosine similarity calculation with pre-computed norms. Unique-vectors are stored, with a similarity map persisting reconstructive indices for lossless recovery in subsequent layers.
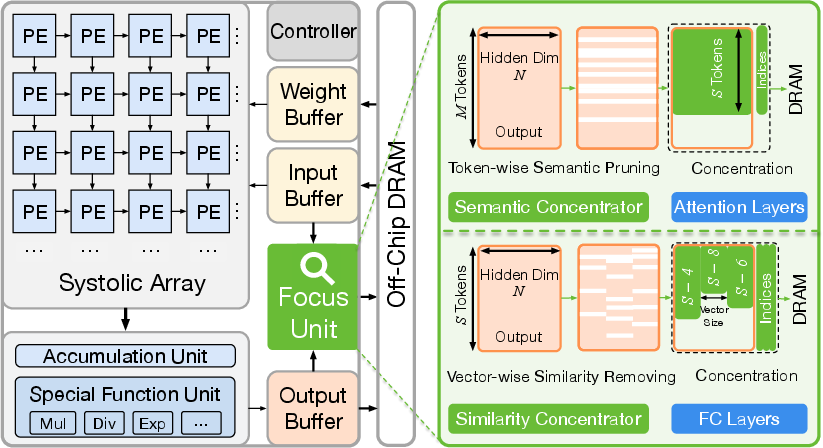
Figure 4: Focus architecture schematic showing the modular integration of SEC and SIC within the accelerator pipeline.
To preserve locality and minimize bank conflicts, the layouter deterministically maps each token to distinct memory banks based on spatial and temporal indices, supporting parallel access and processing.
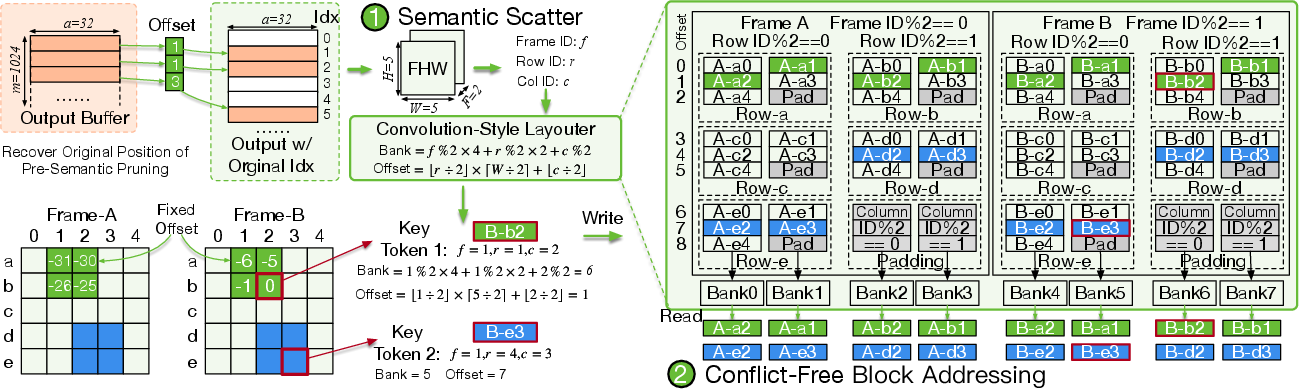
Figure 5: The convolution-style layouter enables accurate token positioning and conflict-free parallel memory access for block-level similarity operations.
Gather-Scatter Pipeline
Focus employs a scatter-gather mechanism. The gather stage deduplicates vectors and constructs the similarity map, while the scatter stage utilizes this map during subsequent GEMM accumulation to reconstruct the full output layout. This pipelined approach achieves lossless block-wise reconstruction with marginal hardware cost and preserves pipeline throughput.
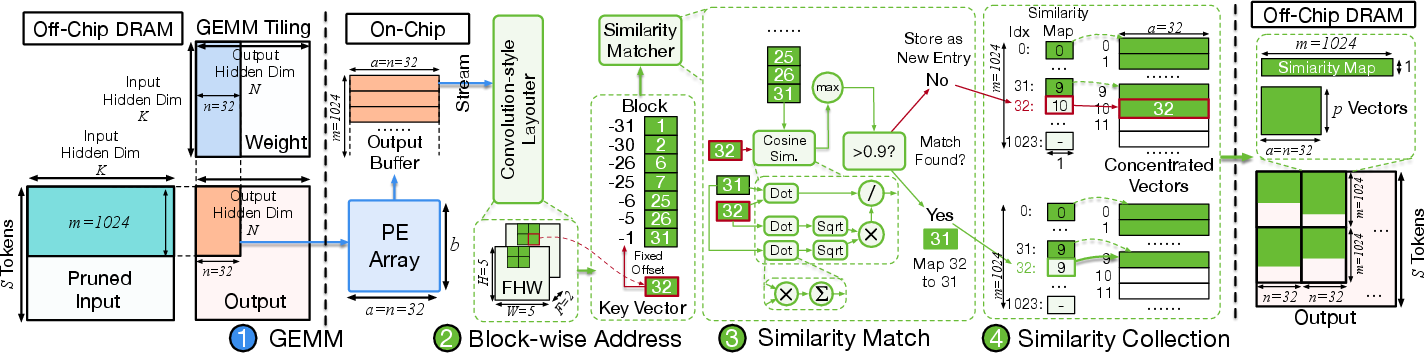
Figure 6: Overview of the Similarity Gather module for block formation and vector-level deduplication with index mapping.
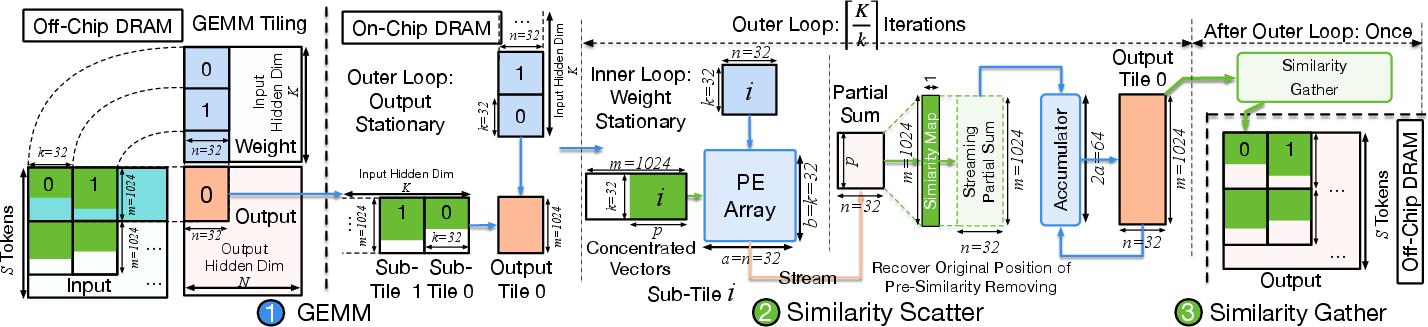
Figure 7: GEMM tiling and Similarity Scatter accumulator pipeline for efficient computation and output alignment.
Evaluation and Empirical Results
Focus is evaluated on three representative VLMs, including Llava-OneVision-7B and MiniCPM-V, across diverse benchmarks (VideoMME, MVBench, MLVU), and compared to top hardware (AdapTiV, CMC) and algorithmic (FrameFusion) baselines. The core findings are as follows:
- Sparsity: The multilevel scheme attains 80.2% operation reduction on average, a >30% gain over AdapTiV and CMC, and surpasses FrameFusion by over 10% in achievable sparsity while yielding only 1.2% accuracy loss, a strong demonstration of semantic fidelity.
- Performance: The architecture achieves a 2.60× speedup over AdapTiV, 2.35× speedup over CMC, and up to 4.47× over vanilla systolic arrays. Against GPU baselines, the improvement is up to 7.9× (or 2.37× when GPU runs with FrameFusion).
- Energy Efficiency: Energy is reduced by factors of 2.98× (vs. AdapTiV), 3.29× (vs. CMC), and 4.67× over the dense baseline. These efficiency gains originate from on-chip streaming sparsification before DRAM traffic.
- Hardware Overhead: Focus incurs less than 2.7% area and 0.9% power growth relative to the core systolic array. The SEC and SIC account for only 1.9% and 0.8% of overall chip area, respectively.
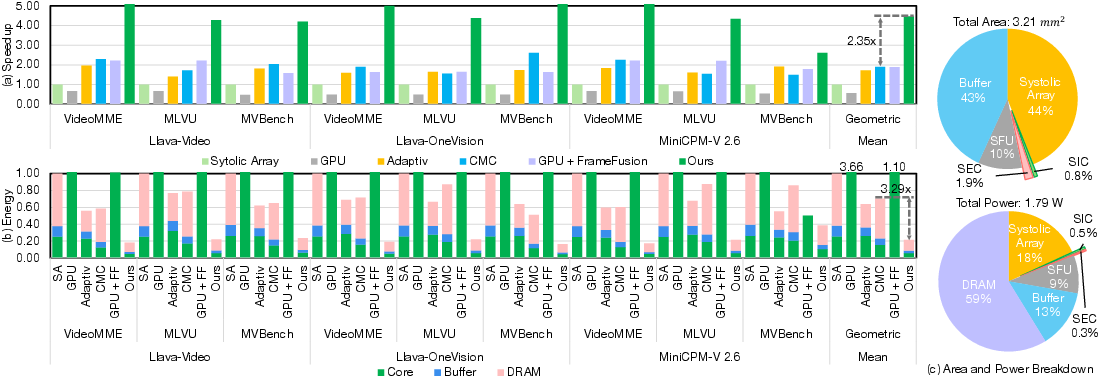
Figure 8: Speedup and energy efficiency improvement—Focus exhibits dominant empirical gains with negligible area/power growth compared to token-level and off-chip alternatives.
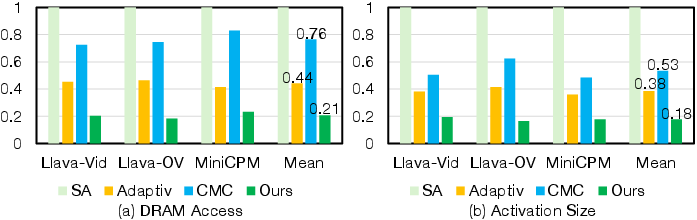
Figure 9: Memory access analysis showing superior DRAM access reduction and compressed activation size for Focus relative to baseline architectures.
Design Insights, Ablation, and Generality
Extensive design space exploration indicates the optimality of moderate tile (m=1024) and vector (len=32) sizes for balancing area, buffer constraints, and sparsity realization. Ablation confirms the orthogonality and synergy of semantic and similarity concentration, yielding multiplicative speedup benefits.
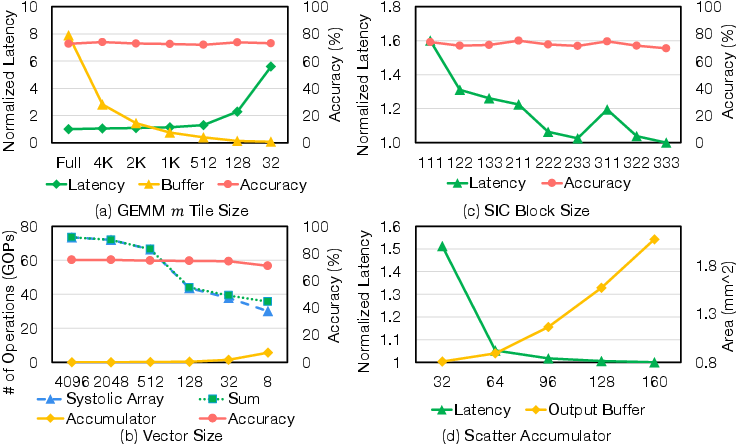
Figure 10: Exploration of Focus hyperparameters, including tile size, vector partition, block size, and accumulator allocation.
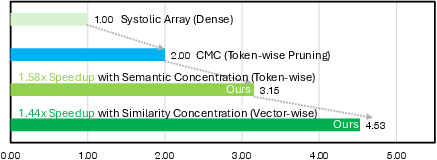
Figure 11: Ablation quantifying the contribution of individual SEC and SIC units to total speedup.
Focus retains its efficacy under quantization (INT8), incurring only ~0.5% additional accuracy loss. It further generalizes to image-based VLMs, maintaining robust speedup and accuracy preservation, and can be naturally extended to Vision-Language-Action (VLA) settings due to its modality-agnostic concentration pipeline.
Implications and Future Directions
Focus demonstrates that direct, modular hardware support for semantic and fine-grained redundancy elimination in VLMs is feasible, effective, and scalable. The removal of global, token-level bottlenecks in favor of block- and vector-level, context-aware streaming enables high utilization with minimal power and area overhead. This methodology effectively bridges the gap between algorithmic sparsity and practical hardware efficiency, allowing for deployment of large VLMs on both cloud and edge configurations.
Potential directions include dynamic adaptation of concentration parameters based on run-time input characteristics, further integration with structured pruning and quantization, and cross-modal sparsity exploitation in future multimodal foundation models. The modular gather-scatter pipeline and bank-conflict-free layouter are especially relevant for next-generation heterogenous accelerators and memory subsystems targeting multi-modal AI workloads.
Conclusion
Focus represents a principled step toward hardware-aware, high-granularity acceleration of multimodal deep models. By aligning algorithmic concentration at multiple levels with streaming, tile-local hardware execution, Focus achieves state-of-the-art compute and energy efficiency, scalable deployment, and robust accuracy preservation for diverse VLM applications (2512.14661).

