- The paper reveals that Mamba SSMs exhibit pronounced selective memory, with reconstruction fidelity sharply declining as sequence length increases.
- It uses an auto-encoder methodology with natural data and linguistic metadata to quantify token-level omission rates and sequence-level ROUGE F1 scores.
- Empirical results show that rare tokens, such as numbers and organization names, are disproportionately forgotten, highlighting key design and pretraining challenges.
Characterizing Selective Memory in Mamba State Space LLMs
Introduction
This paper presents a comprehensive empirical analysis of selective memory and information retention in Mamba, a state space model (SSM) LLM family, using an auto-encoder framework to probe and characterize the types of information preferentially retained and forgotten as a function of pretraining, sequence length, model size, and token characteristics (2512.15653). The methodology avoids synthetic memorization cues, instead leveraging natural data and annotated linguistic metadata (such as POS and NER labels) to quantify information loss via text reconstruction from frozen Mamba hidden states.
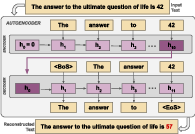
Figure 1: Auto-encoders are trained to reconstruct inputs from Mamba's hidden states, measuring information retention by comparing original and reconstructed sequences.
Methodology: Auto-Encoder Probing of Mamba's Latent Space
The approach is an unsupervised reconstruction framework in which input texts are encoded by frozen, pretrained Mamba models into latent (state-space and convolutional) hidden states. A decoder, initialized with the same architecture, is then trained to autoregressively reconstruct the original text, bootstrapping from the encoder’s internal state. Informational fidelity is measured using both token-level omission rates and sequence-level ROUGE F1-score. By restricting encoder updates and using natural (in-distribution) data, this protocol precisely interrogates the inherent representational bottlenecks of the pretrained SSM, disentangled from possible adaptive capacity of the decoder.
The framework is systematically validated by replicating known SSM memory phenomena—including steep reconstruction quality decline with increasing sequence length, recency bias in error position, and model size effects—establishing parity with theoretical predictions and prior empirical work.
Empirical Findings: Global Sequence Trends
A primary empirical finding is the severe decline in reconstruction fidelity as sequence length grows, confirming that SSM memory is capacity-limited. For the 130M parameter model, ROUGE F1-score decreases from 98.6 for length-4 sequences to 66.6 at length 256, with the decline becoming non-linear for longer sequences.
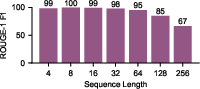
Figure 2: ROUGE F1-score as a function of input sequence length, showing a sharp drop as sequence length increases, especially past 16 tokens.
Model scaling—up to 1.4B parameters—partially mitigates this loss, particularly for longer sequences, indicating that both sequence length and model capacity explicitly determine retention. Notably, some non-monotonic effects appear, e.g., the 790M model outperforming the 1.4B model at specific lengths, echoing trends observed in prompt-tuning settings.
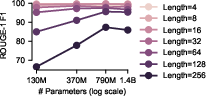
Figure 3: ROUGE F1 by model size and sequence length; improvements saturate for short contexts but grow sharply for longer ones.
A pronounced recency bias is observed: the earliest positions in sequences are omitted at rates up to 6x those of terminal tokens for sequences of length 256, consistent with exponential decay predictions from recent theory.
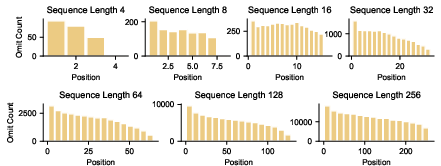
Figure 4: Omission error by token position reveals strong recency bias; later tokens are much better retained.
Token-Level Analysis: Parts-of-Speech and Named Entities
Reconstruction/omission error rates, dissected by linguistic annotation, reveal robust selectivity. Numbers (POS=NUM) are significantly more likely to be omitted (50.8% for 130M, 22.7% for 1.4B) than any other category, with statistical significance confirmed (Bonferroni-corrected t-tests, p≪0.05).
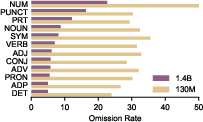
Figure 5: Numbers are the most frequently omitted POS category by a large margin, even for the largest model.
Among named entities, organizations are most frequently omitted (35.8% for 130M, 12.3% for 1.4B), while locations are best preserved. This aligns with findings on frequency/rarity in pretraining data.
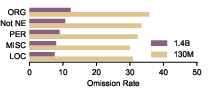
Figure 6: Among NE types, organizations exhibit the highest omission rates; locations and persons are retained better.
Disaggregation by input domain (using Pile Uncopyrighted’s document source metadata) demonstrates that mathematical data (e.g., DM Mathematics) is most prone to catastrophic forgetting at long sequence lengths, with ROUGE F1 plummeting from 99.9 at length 4 to 41.6 at length 256, while other domains maintain scores above 60.
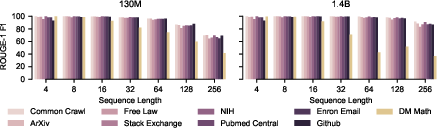
Figure 7: Mathematical text sequences show much steeper degradation in reconstruction as length increases, relative to other domains.
Dialectal effects are established by comparing SAE and AAVE reconstructions: the fidelity gap increases with sequence length, with AAVE dropping to 59.7 F1 (vs 65.3 for SAE) at 256 tokens.
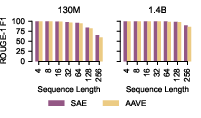
Figure 8: Reconstruction degrades more for AAVE dialectal inputs compared to SAE as context length increases.
Fully synthetic numerical sequences effectively “break” the representational memory: for random numeric strings, the 130M model achieves only 0.5 F1 at length 256.
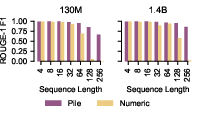
Figure 9: Random numeric sequences are almost entirely forgotten for long contexts compared to natural text.
Further, the likelihood (perplexity) of the reference sequence correlates directly with omission: higher perplexity sequences are much more likely to suffer information loss.
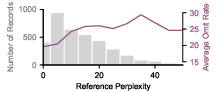
Figure 10: As Mamba’s reference perplexity increases, omission rates grow, pointing to weak retention for out-of-distribution or rare patterns.
Training Corpus Analysis: Memory and Pretraining Statistics
Analysis of pretraining token frequency data reveals that the categories most susceptible to omission (e.g., numbers, organization names) are also the least frequent/least repeated per unique token in the training corpus. This suggests that information bottlenecks in SSMs are not only architectural but also reflect pretraining corpus statistics, interacting with the fixed capacity of the SSM hidden state.
Discussion and Implications
The data robustly demonstrate that Mamba’s information retention is highly selective and capacity-constrained, with non-uniform memory allocation across token and sequence types. Notably, there is a systematic and statistically significant tendency for numeric tokens, organization entities, and out-of-domain language to be irretrievably lost in long contexts, even when overall sequence recall remains high.
The observed selectivity of memory in SSM LMs arises from (1) the fixed-size hidden state, (2) the recency-favoring update dynamics, and (3) the distributional skew of pretraining data. This implies that SSMs, without architectural or training objective interventions, are systematically unreliable for tasks requiring accurate long-range recall of rare or out-of-domain details (numeric reasoning, precise information retrieval, open-domain dialog).
This research further suggests remedial avenues: tokenization choices (byte-level or digit-wise for math), explicit reconstruction-aware or memory-augmenting objectives, and training regime modifications may be needed to align SSM memory utilization with the requirements of complex applications. Recent work supports the notion that alternative tokenization schemes or hybrid objectives can recover some performance on tasks that SSMs are otherwise ill-equipped to solve.
Conclusion
This paper establishes, with precise and validated empirical methodology, the existence and contours of selective memory in state-of-the-art SSM LMs exemplified by Mamba. The SSM architectural bottleneck and interaction with pretraining distribution induce a marked inability to retain certain types of semantically and practically critical information, especially as context length increases. These insights delineate theoretical limits but also highlight key directions—tokenization, auxiliary objectives, data design—for future research to enable SSM LMs to achieve high reliability in real-world NLP settings where robust memory for all token types is necessary.