- The paper presents FrontierCS, a novel benchmark with 156 expert-curated tasks that blend algorithmic and research challenges.
- The methodology uses deterministic evaluators and parameterized instance generation to ensure reproducible scoring and fair evaluation.
- Key findings reveal significant LLM limitations in creative algorithmic reasoning compared to near-optimal human expert performance.
FrontierCS: A Benchmark for Open-Ended Reasoning in Computer Science
Motivation and Positioning
FrontierCS addresses the evaluation gap in open-ended and unsolved computer science tasks, targeting scenarios where optimal solutions are unknown but the quality of proposed solutions is objectively measurable through deterministic evaluators. Unlike traditional benchmarks—where problems are closed-form, unit-test driven, and typically admit single optimal solutions—FrontierCS focuses on tasks reflecting authentic research and engineering practice. The benchmark serves both for model evaluation and as a platform for agentic learning paradigms leveraging continuous reward signals.
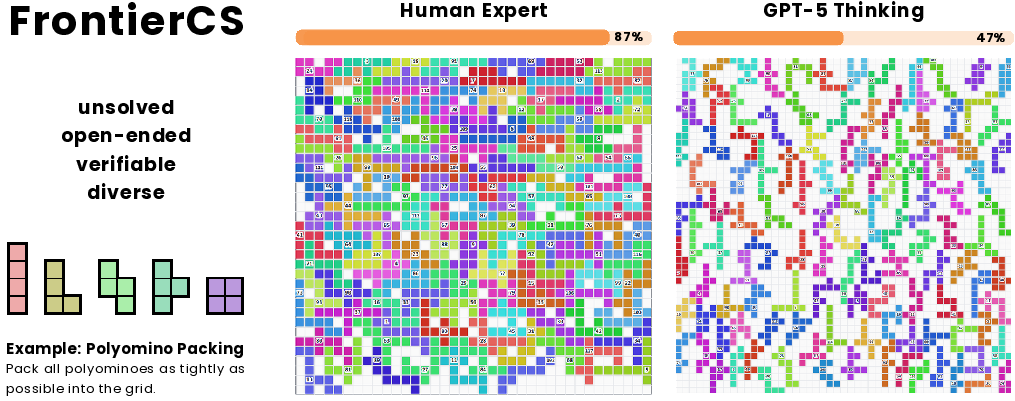
Figure 1: FrontierCS, an unsolved, open-ended, verifiable, and diverse benchmark for computer science tasks. Illustration: Polyomino Packing.
The benchmark comprises 156 rigorously curated and expert-reviewed problems, spanning both reimagined competitive programming tasks and genuine CS research challenges. The tasks in FrontierCS are unsolved, vary substantially in solution strategy space, and leverage quantitative, task-specific, and continuous scoring. Models must implement executable programs, with solutions validated and scored via deterministic scripts rather than binary correctness.
Benchmark Structure and Curation Pipeline
The collection is partitioned into two primary tracks: Algorithmic Problems (107 tasks) and CS Research Problems (49 tasks). The algorithmic track reworks classic contest and combinatorial optimization problems to remove known optima and focus on open-endedness, covering constructive, optimization, and interactive categories. The research track is grounded in domains such as operating systems, high-performance computing, artificial intelligence, database systems, programming languages, and cybersecurity.
Each problem is subject to a multi-stage curation pipeline: expert-sourced proposals, conversion to open-ended format, deterministic evaluator implementation, and peer expert review. Problems incorporate parametrized generators for diverse instances, prohibiting overfitting and contamination. Solutions must adhere to resource constraints; runtime and memory overages result in invalidation.

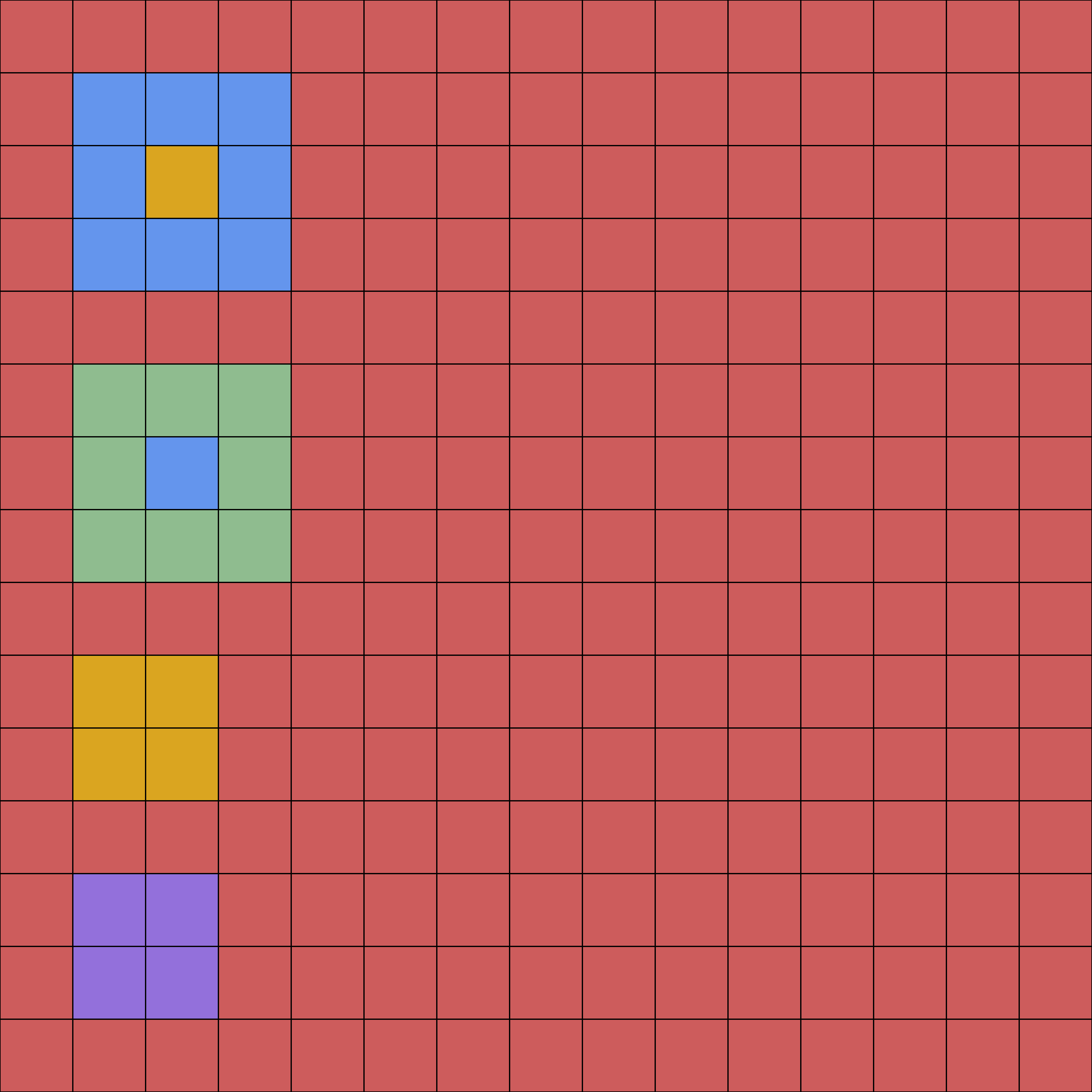
Figure 2: Adjacency graph E for an example algorithmic problem; illustrates structured instance generation and the nature of constraints imposed in open-ended settings.
Empirical reference solutions are provided by human experts (e.g., IOI, ICPC medalists, domain specialists), and the scoring scheme is parametrized between a trivial baseline and the best-known human reference.
Evaluation Infrastructure
The research track employs containerized, explicitly versioned environments with deterministic evaluation, integrating SkyPilot for highly scalable and cost-effective compute orchestration. This permits evaluation over heterogenous hardware clusters and facilitates continuous-time scalable benchmarking, reproducibility, and ablation protocols.
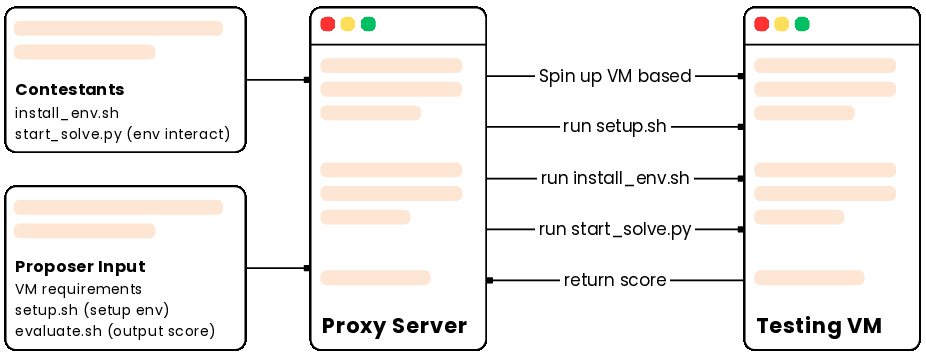
Figure 3: Evaluation pipeline of a FrontierCS research problem using SkyPilot.
The infrastructure is optimized for verifiability and fairness: no agentic or inner-loop feedback (e.g., code execution, test inspection) is allowed during model evaluation, and API contracts are strictly enforced.
Evaluation Protocol and Results
Assessment is conducted on the basis of graded score relative to trivial and expert reference solutions, using metrics tailored to each task. The main reported metrics are Score@1, Score@5, Avg@5, Pass@1, and Pass@5, reflecting best/average attempt performance and raw success counts, respectively.
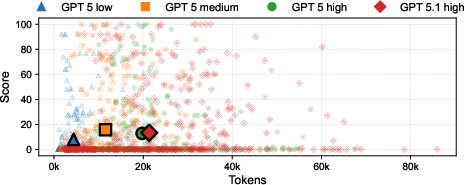
On both problem tracks, leading LLMs (GPT-5 Thinking, Gemini 3.0 Pro, Claude Opus 4.5, Grok 4, DeepSeek 3.2) consistently underperform human experts by large margins. Frontier models typically produce solutions that are valid and functional but suboptimal, often plateauing at local optima and failing to discover deeper algorithmic innovations.
Algorithmic Track
Human expert performance approaches the theoretical maximum (Score@1 ≈ 95), while top LLMs average between 11–29 and only approach 50 in their best attempts (Score@5). The gap persists across optimization, constructive, and interactive subtasks, even after multiple stochastic code generations.
Research Track
Similar gaps are evident in tasks based on symbolic regression, vector database design, kernel optimization, and vulnerability analysis, with model scores (Score@1 in the low 20s to 40s) far below human expert levels, despite increased reasoning or context budgets. Models frequently default to composing code using existing libraries or overly generic scripts rather than synthesizing competitive strategies.
Observed Failure Modes
Several systemic deficiencies are identified in the current state of reasoning models:
Implications for LLM and Agentic AI Development
FrontierCS exposes the current inability of even state-of-the-art LLMs to perform at or near-human levels on open-ended, verifiable tasks where exploration, creative reasoning, and continuous improvement are required. This suggests that improvements in model size, context length, or even sampling are by themselves insufficient to achieve parity with expert performance in these settings.
The benchmark’s structure makes it well-suited for future directions such as:
- Agentic and Self-Play Learning: The availability of continuous reward signals and deterministic evaluators facilitates reinforcement learning and prompt- or policy-evolution protocols.
- Ablation and Transfer Studies: FrontierCS enables the measurement of transfer effects and progressive agent skill acquisition across unrelated but structurally analogous tasks.
- Lifelong and Continual Benchmarking: Parametric instance generation and scalable difficulty allow for dynamic updating and ongoing relevance as capabilities of models advance.
Future Directions and Open Questions
- Algorithmic Creativity: How can models be endowed with higher-level algorithmic insight, structural innovation, and exploratory drive, beyond optimizing known decompositions?
- Human-Like Iterative Improvement: Integrating dynamics such as iterative solution refinement (currently disallowed in the protocol) or feedback-informed search could inform next-generation system architectures.
- Benchmark Evolution: The separation of task statement from testbed instance allows for progressive hardening (e.g., adding adversarial cases, stricter thresholds) to prevent overfitting and ensure enduring challenge.
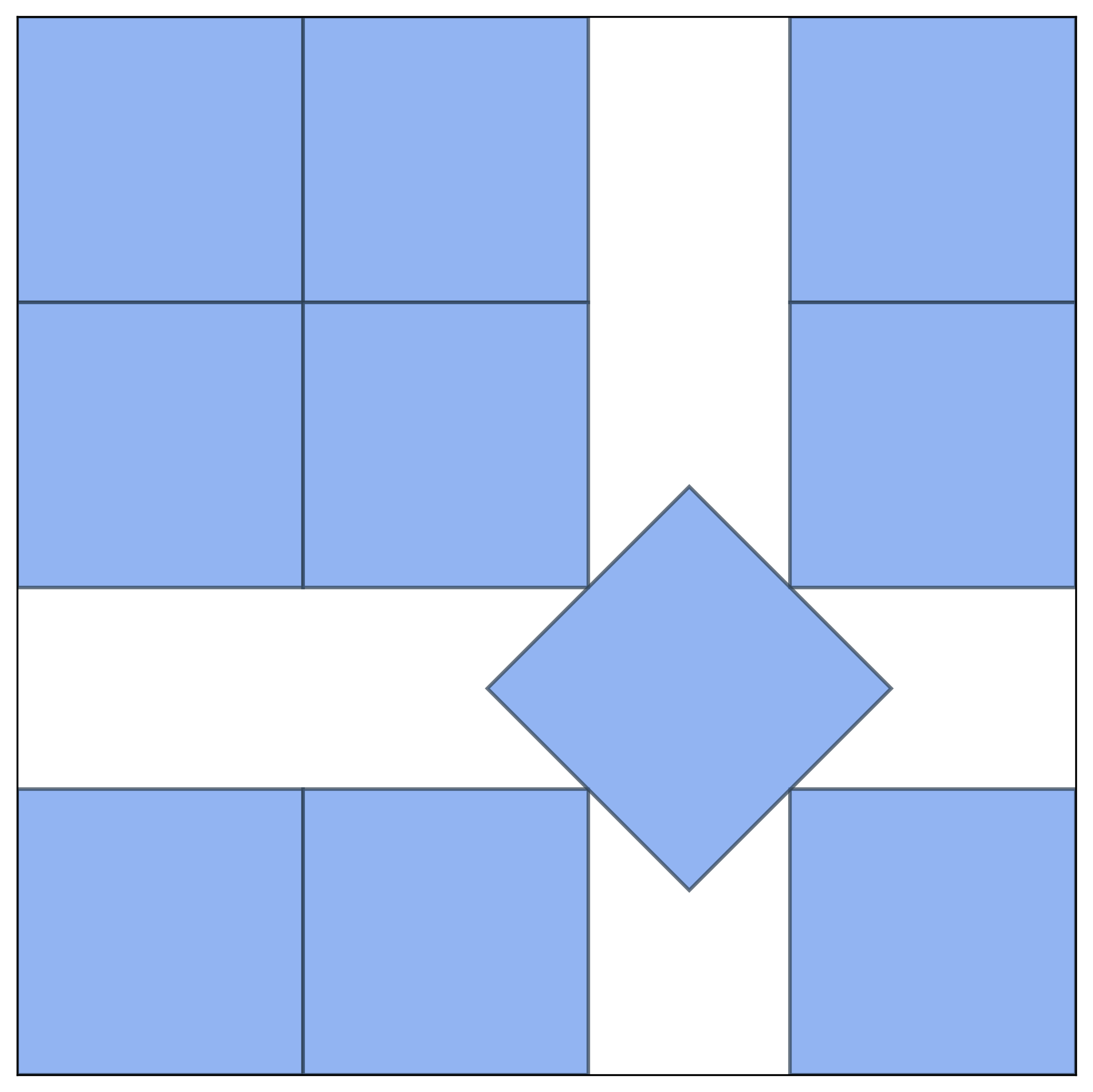
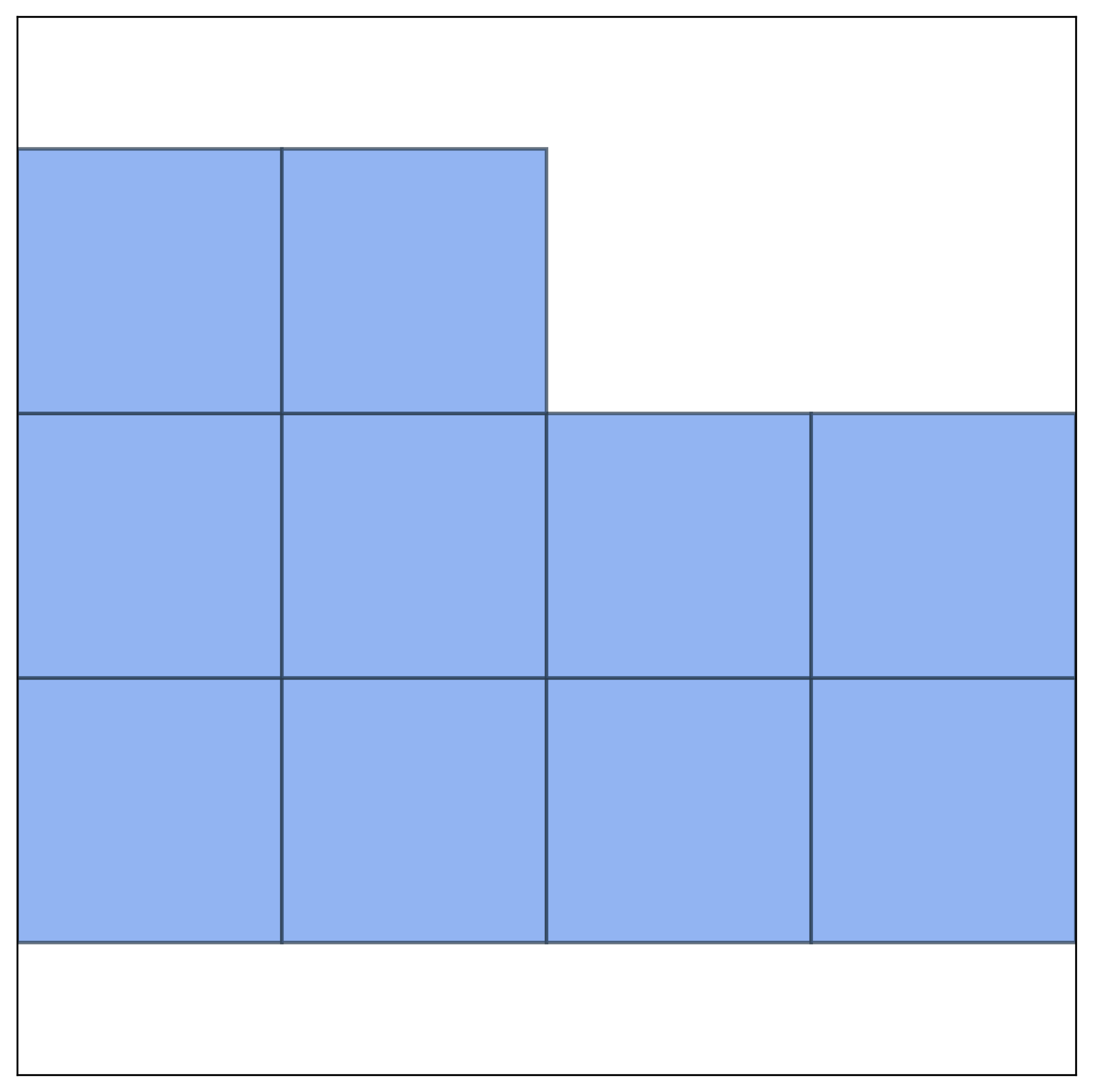
Figure 5: Example of a human expert solution—highlighting structural features that frontier LLMs consistently miss.


Figure 6: Human expert achieves 87% density in Polyomino Packing; LLM solutions typically reach only 47%.
Conclusion
FrontierCS establishes a new standard for benchmarking and driving progress in open-ended computer science reasoning. The findings presented demonstrate a substantial unsolved gap: LLMs excel at workable code but are fundamentally limited in algorithmic inventiveness, solution optimality, and systematic exploration capabilities when removed from closed-form, single-solution tasks. The framework’s extensibility, rigorous curation, and dynamic scoring make it an essential tool for the next phase of both model evaluation and reward-based training paradigms.
(2512.15699)