- The paper presents a constrained Gaussian Splatting pipeline that leverages semantic supervision to extract accurate facial geometry and de‐lit textures from only 11 uncalibrated images.
- It integrates landmark detection, depth estimation, and segmentation to establish a one-to-one correspondence between Gaussians and mesh triangles, ensuring robust geometric regularization.
- Results demonstrate that transforming GS into a view-dependent neural texture markedly improves rendering fidelity, supporting relighting, animation, and standard graphics pipeline integration.
High-Fidelity Facial Geometry and Texture via Constrained Gaussian Splatting
Introduction and Motivation
This work presents a significant advance in constructing high-fidelity, semantically consistent, and relightable facial avatars from limited, uncalibrated multi-view image collections. While prior approaches such as NeRFs have demonstrated efficacy in photorealistic scene and facial modeling, their implicit nature often impedes geometric regularization and downstream integration with standard graphics pipelines. Recent 3D Gaussian Splatting (GS) methods, although more explicit, typically decouple geometry and semantics insufficiently, limiting accurate geometry extraction and texture disentanglement. The authors propose a pipeline leveraging GS with explicit, semantically supervised geometric constraints, enabling accurate triangulated surface extraction, and de-lit high-resolution albedo texture generation suitable for relightable avatars within industry-standard pipelines.
Methodology
The pipeline utilizes a compact monocular capture protocol (only 11 uncalibrated images) and integrates landmark detection and depth estimation to initialize a canonical mesh consistent with the MetaHuman topology. A one-to-one correspondence is established between Gaussians and mesh triangles, intentionally fixing GS densification/pruning during training to preserve this correspondence and to regularize geometric derivation.
Segmentation supervision is enforced via synthetic, semantically labeled MetaHuman-derived data and transferred to scene images through a Mask2Former variant. Soft Laplacian-like constraints drive the geometric consistency of Gaussian centers and local normals with their associated mesh triangles and propagate regularization through the mesh topology and texture-space neighborhoods. Specific terms prevent degenerate configurations (such as eyeballs occluding the eye sockets).
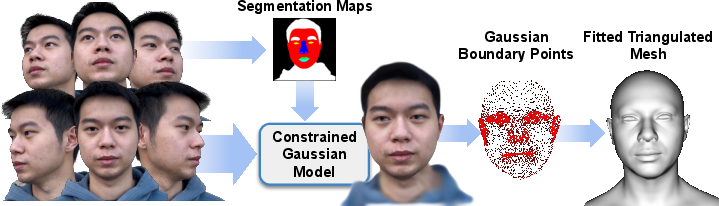
Figure 2: The pipeline combines segmentation, size/shape constraints, and post-process deformation to align triangulated surfaces with the Gaussian reconstruction informed by multi-view images.
Supervision through semantic labels prevents spurious geometric deformation in ambiguous regions and provides direct cues to guide the assignment of image evidence to semantic mesh regions.
Additional innovations include a boundary-aware constraint utilizing UV-space neighborhoods to regularize silhouette regions—critical for facial identity and animation—and capturing outer boundaries of Gaussians for accurate mesh fitting.
Neural Texture and Texture-Space Gaussian Splatting
A central contribution is the demonstration that accurate mesh geometry obtained from the constrained GS pipeline enables the transformation of the GS model into texture space. Parent-triangle-driven transformations push Gaussians from world space into UV(W) texture space, where they function as a view-dependent neural texture.




Figure 4: Comparison of standard world-space GS to the novel view-dependent neural texture (texture-space GS) representation for a novel view, highlighting efficiency and fidelity improvements.
Texture-space rendering blends Gaussians perpendicularly to the surface rather than along view rays, critically reducing spurious blurring and enhancing resolution for novel viewpoints. Fine-tuning in this space yields sharper details and better locality, and the method supports direct summation or alpha blending, facilitating application-dependent tradeoffs.
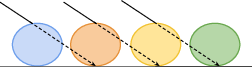
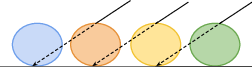
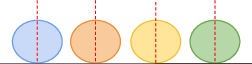
Figure 1: Schematic of color accumulation: world-space GS accumulates colors along rays, introducing view-dependent blending. Texture-space GS accumulates perpendicularly, ensuring consistent locality and preventing artifacts for unseen views.
Lighting Estimation and De-lit Albedo Texture Generation
The pipeline employs SH (spherical harmonics) lighting models with per-pixel normal perturbation and screen-space occlusion maps to approximate illumination, guiding the disentanglement of albedo from lighting.


Figure 7: Example showing de-lit texture recovery improved by occlusion maps, particularly in shadowed and recessed regions.
Texture recovery combines two albedo priors: (a) a PCA-based low-dimensional textured mesh initialized from the MetaHuman framework, and (b) a relightable GS model capturing high-frequency detail and lighting residuals. During optimization, regularization terms encourage the mesh-based component to explain most of the color variation, relegating GS to fill details and unmodeled illumination components. The de-lit albedo texture is finalized by compositing mesh and Gaussian predictions, with high-frequency details restored from reference images via high-pass filtering and robust alignment.
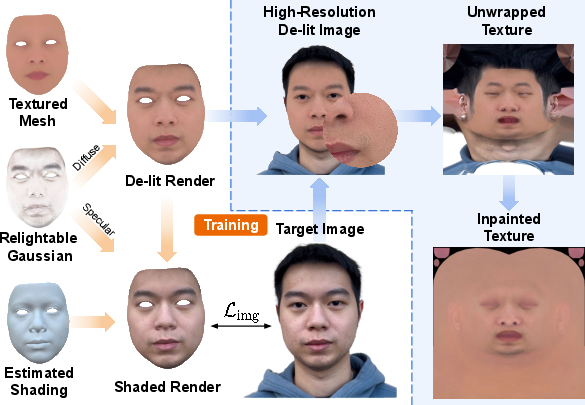
Figure 9: Overview of de-lit texture synthesis combining mesh+GS+lighting, inpainting, and high-frequency detail reintroduction.
Special care is devoted to problematic regions (hairlines, neck, eyebrows), where inpainting with a global PCA-based texture ensures the absence of artifacts and supports downstream in-context editing.
Evaluation and Comparative Analysis
Extensive ablation studies demonstrate the necessity of both semantic supervision and soft constraints for robust geometry. Removing either results in disconnected, semantically inconsistent, or spurious facial surfaces. The edge-case handling of eyeball/eyelid interactions is shown to be critical for accurate periorbital modeling.
The method is systematically compared to state-of-the-art baselines including NextFace [dib2021practical], Neural Head Avatars (NHA) [grassal2022neural], and CoRA [han2024high]. The surface geometry extracted by this pipeline maintains sharper and anatomically plausible contours, especially in side views and silhouette features—a region where implicit-only methods degrade. Importantly, baseline methods often obscure geometric errors by overfitting textures, an artifact avoided by the strong semantic coupling in this work.

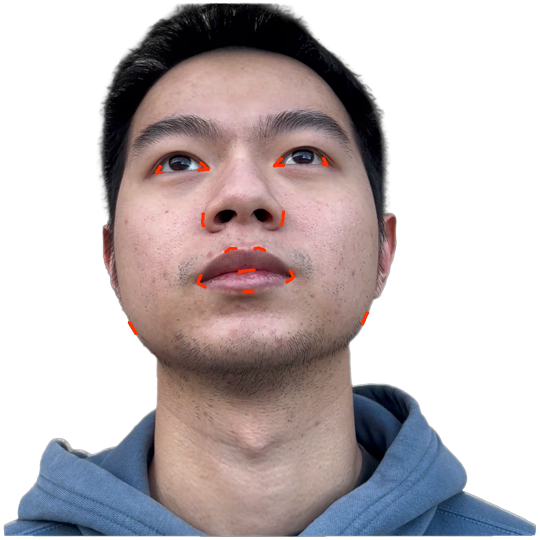


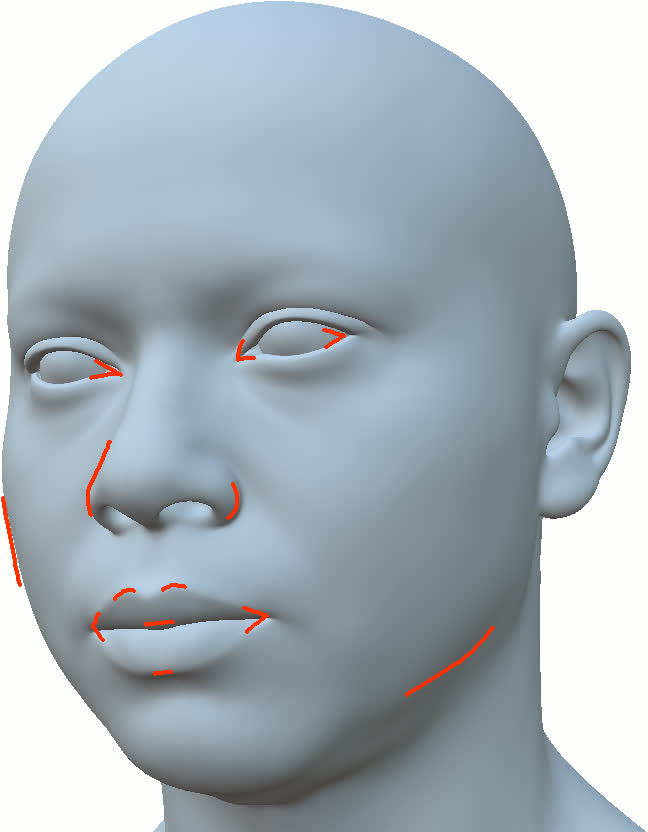

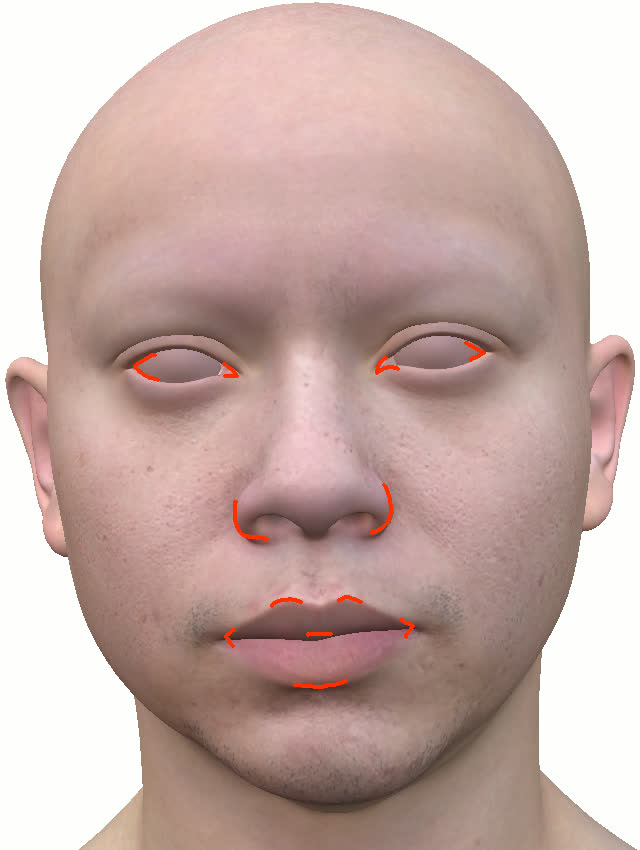
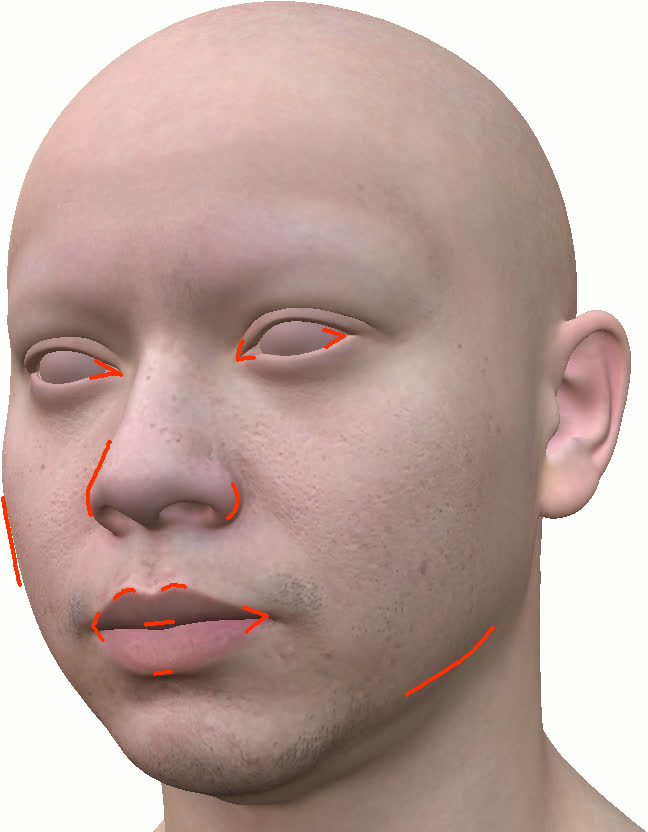
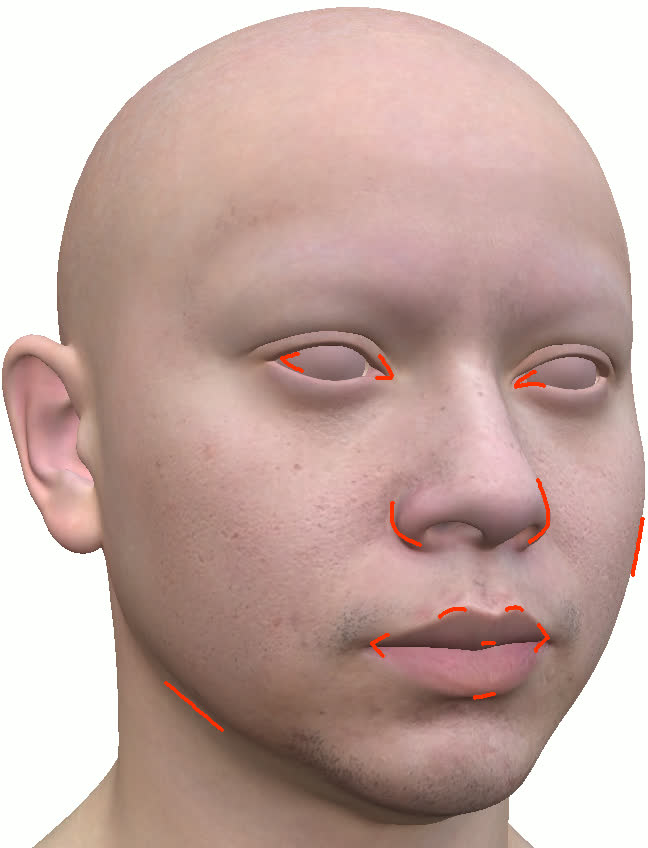
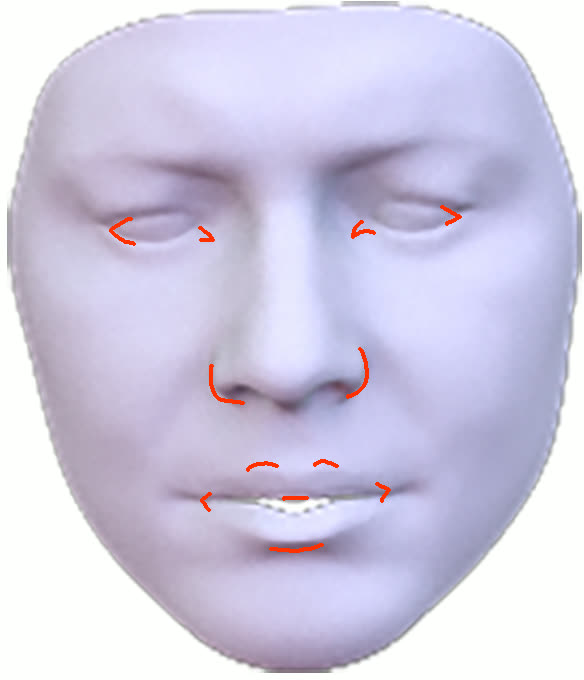
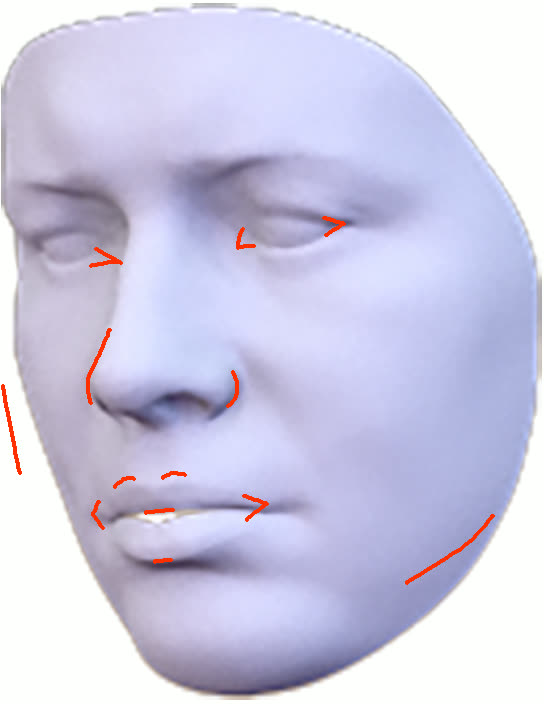

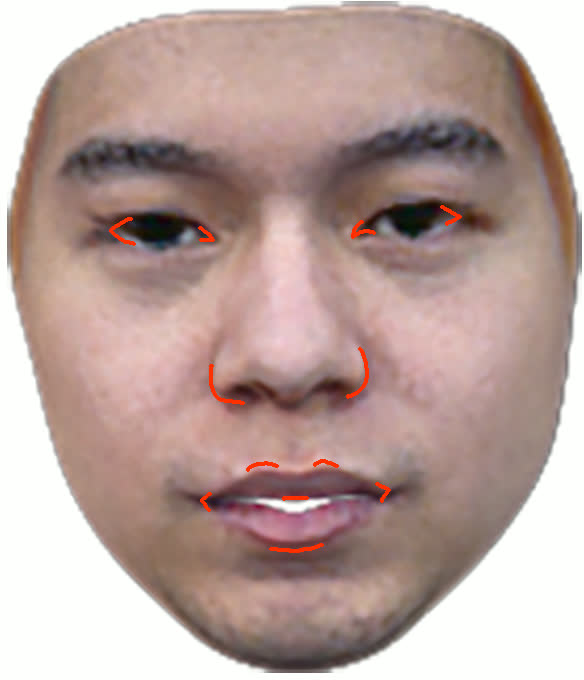
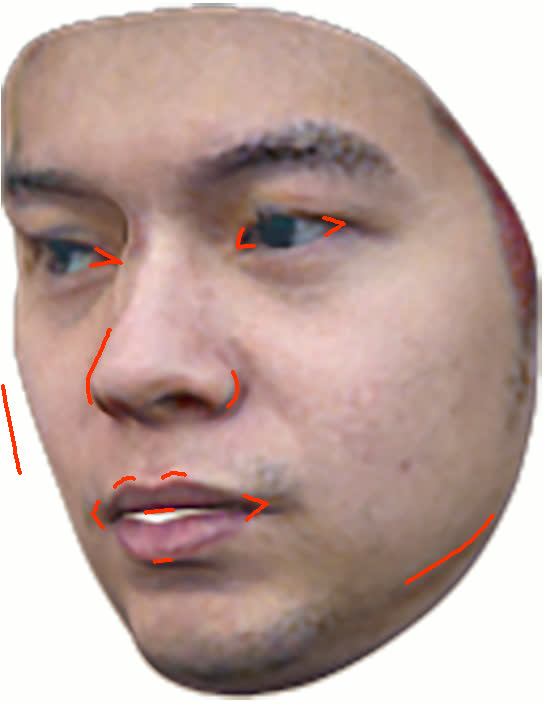

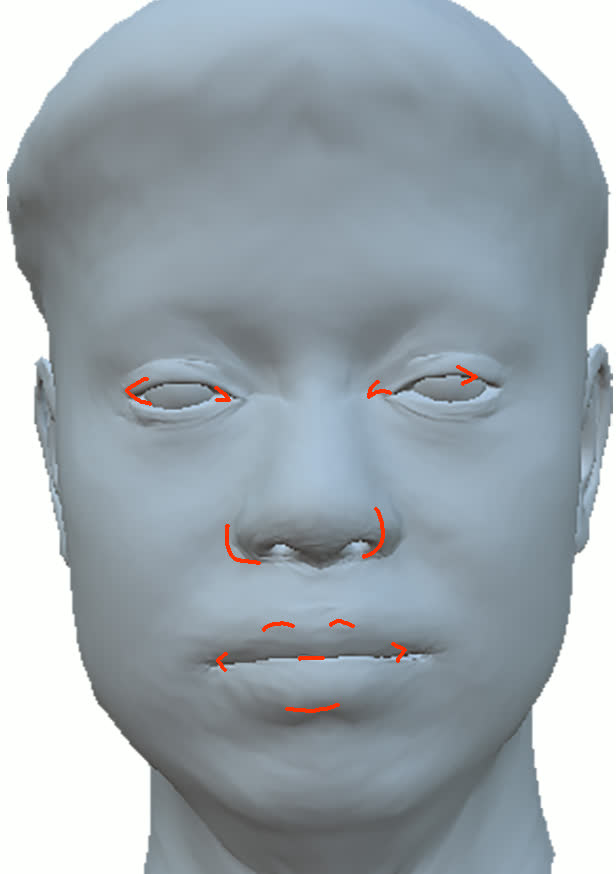
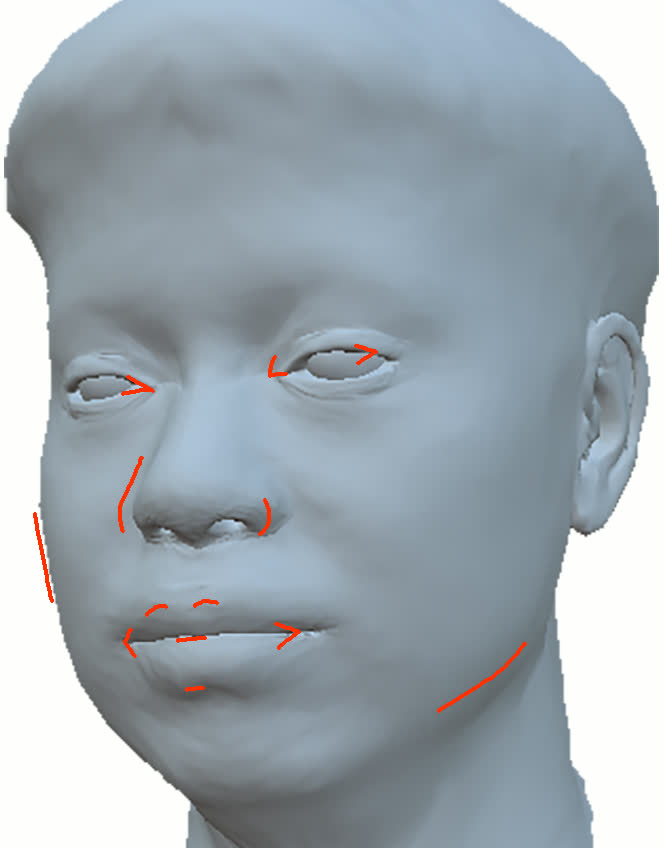
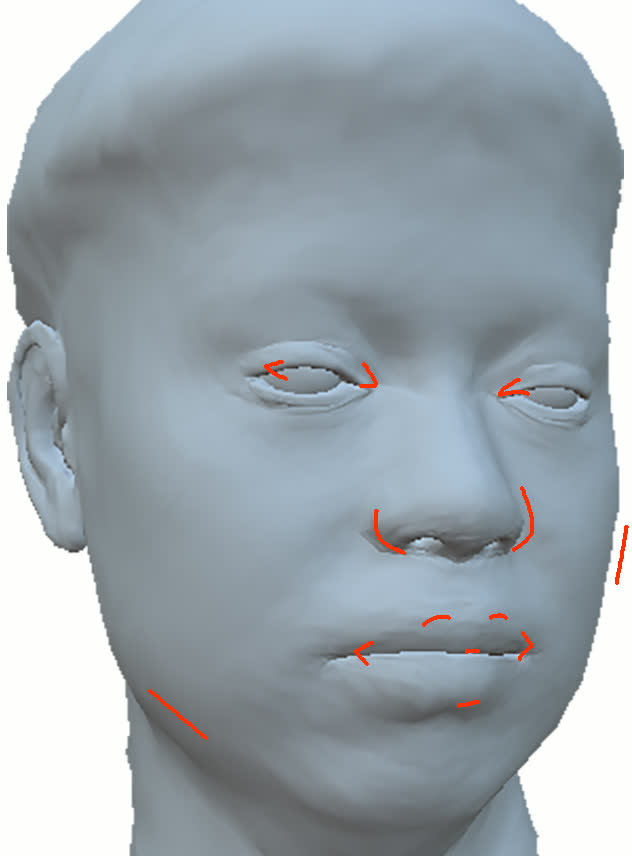

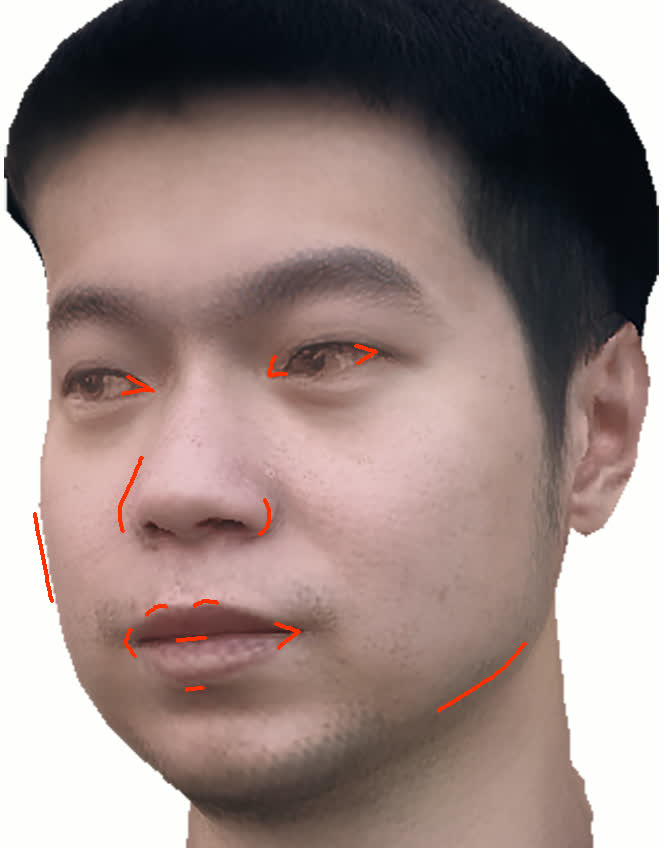

Figure 11: Geometry reconstruction comparison: method (ours) recovers more accurate contours and geometry than NextFace and NHA.
Texture-wise, the pipeline recovers de-lit, relightable albedos with minimal baked-in illumination, outperforming CoRA in both artifact removal and lighting-agnostic consistency. The resulting avatars support plausible relighting and animation, facilitated by compatibility with the MetaHuman basis.
Practical Flexibility and Applications
A salient property of the pipeline is the ability to integrate views from disparate capture conditions (including flashlight-illuminated and naturally lit frames), combining disparate data sources through appropriate view-dependent GS parameters. This regularizes geometry and helps mitigate capture-specific artifacts or minor misalignments. The system also supports upstream integration with portrait de-lighting models such as SwitchLight [kim2024switchlight], unifying robust preprocessing with detailed 3D recovery.
The paper also demonstrates full compatibility with text-driven asset pipelines: conditioned on a foundation image generated from ChatGPT, video sequences are synthesized (e.g., with Veo-3) and processed as input for GS-based reconstruction, supporting creative semantic asset authoring.





Figure 13: Example where a ChatGPT-generated image and Veo video drive high-fidelity 3D avatar synthesis through the proposed pipeline.
Limitations
Despite its strengths, accurate de-lighting without controlled capture (light stage) remains an inherently ill-posed problem, especially for fine-scale features such as wrinkles or area-specific shading. The system’s geometric cues are less reliable around eyes and eyelids, and non-face regions (hair, neck) are not regularized structurally, resulting in lower-quality reconstructions in these cases.
Theoretical and Practical Implications
This paper provides strong evidence that explicit coupling of GS to mesh-based geometry, enforced via semantic segmentation and carefully designed soft constraints, is sufficient for extracting accurate, animation-ready facial geometry from sparse, uncalibrated data. The approach bridges neural rendering and explicit graphics pipeline requirements: it is shown that GS can transition from a capture/editing tool to a canonical texture-space neural representation, supporting efficient deployment and integration in standard content creation workflows.
The proposed pipeline enables democratized avatar generation from commodity hardware, facilitating rapid asset creation for AR/VR, entertainment, and communication. Its flexible integration with pre- and post-processing methods, and compatibility with text-driven asset generation, creates opportunities for high-throughput, relightable, and semantically editable 3D facial content.
Conclusion
By constraining the degrees of freedom of Gaussian Splatting with semantic and geometric priors, this method yields accurate surface reconstructions and lighting-disentangled textures from highly accessible data. The resulting avatars support standard relighting, animation, and integration into graphics pipelines. The ability to transform GS into a view-dependent neural texture further generalizes GS from a neural rendering tool to a drop-in neural primitive for photorealistic asset representation and editing. Remaining challenges include highly detailed de-lighting and robust capture of non-face semantic regions, but the work establishes a practical, extensible foundation for next-generation digital humans.


Figure 3: Direct comparison of a target image and the MetaHuman reconstructed using the complete GS-based pipeline; note the high-fidelity reproduction of identity and appearance.