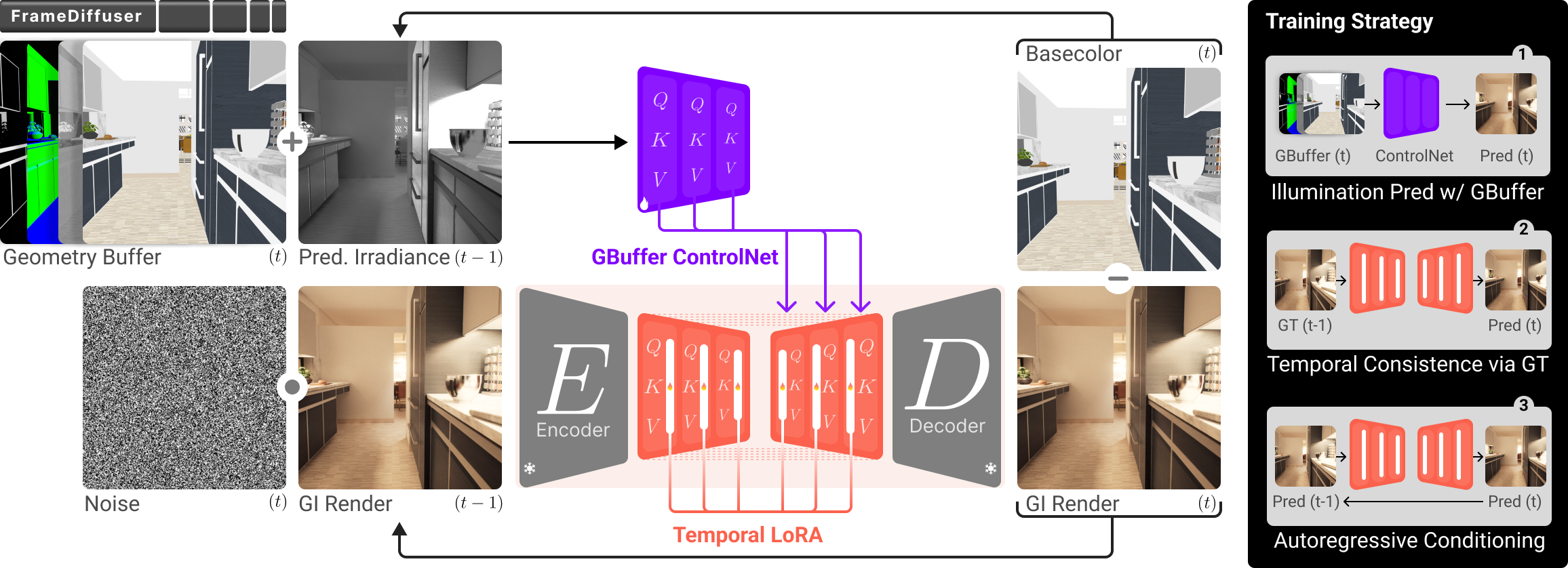
FrameDiffuser: G-Buffer-Conditioned Diffusion for Neural Forward Frame Rendering
Abstract: Neural rendering for interactive applications requires translating geometric and material properties (G-buffer) to photorealistic images with realistic lighting on a frame-by-frame basis. While recent diffusion-based approaches show promise for G-buffer-conditioned image synthesis, they face critical limitations: single-image models like RGBX generate frames independently without temporal consistency, while video models like DiffusionRenderer are too computationally expensive for most consumer gaming sets ups and require complete sequences upfront, making them unsuitable for interactive applications where future frames depend on user input. We introduce FrameDiffuser, an autoregressive neural rendering framework that generates temporally consistent, photorealistic frames by conditioning on G-buffer data and the models own previous output. After an initial frame, FrameDiffuser operates purely on incoming G-buffer data, comprising geometry, materials, and surface properties, while using its previously generated frame for temporal guidance, maintaining stable, temporal consistent generation over hundreds to thousands of frames. Our dual-conditioning architecture combines ControlNet for structural guidance with ControlLoRA for temporal coherence. A three-stage training strategy enables stable autoregressive generation. We specialize our model to individual environments, prioritizing consistency and inference speed over broad generalization, demonstrating that environment-specific training achieves superior photorealistic quality with accurate lighting, shadows, and reflections compared to generalized approaches.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces FrameDiffuser, an AI tool that turns simple game engine data into realistic images, one frame at a time, while keeping things consistent like a real video. It’s designed for interactive uses (like video games), where the next frame depends on what the player does, so you can’t pre-generate a whole video in advance.
What questions were they trying to answer?
The researchers wanted to solve a few problems that current AI image/video tools struggle with:
- How can we create photorealistic frames from game engine data (called a G-buffer) while keeping the look consistent over time?
- How can we do this frame-by-frame (like in a game), instead of needing an entire video sequence up front?
- Can focusing on specific environments (like one city scene or one building) make the results more stable and realistic than using a “one-size-fits-all” model?
How did they do it?
They combined a game engine’s helpful data with an AI model that “remembers” what it made last frame. Here’s how it works in everyday terms:
Key idea 1: What is a G-buffer?
Think of the G-buffer like a super detailed coloring book page for a 3D scene—no final lighting, just the scene’s structure and material properties:
- Depth: how far each pixel is from the camera.
- Normals: the direction each surface is facing (used to know how light should hit it).
- Basecolor: the color of the raw materials (like brick red or metal gray).
- Roughness and Metallic: how shiny or matte surfaces are.
This data tells the AI where things are and what materials they’re made of—but not the final lighting, shadows, or reflections.
Key idea 2: Diffusion models with “guidance”
A diffusion model is like an artist starting with a noisy, blurry picture and refining it step by step until it looks real. FrameDiffuser uses two “guides” to help the artist:
- ControlNet (structural guidance): makes sure the image respects the scene’s geometry and materials from the G-buffer. Think of this as tracing the outlines and textures correctly.
- ControlLoRA (temporal guidance): helps keep the new frame similar to the previous frame—like remembering what the last scene looked like so things don’t flicker or jump.
Key idea 3: Irradiance (lighting hint)
Because the model doesn’t get the true lighting from the game engine, it estimates a simple lighting map (called irradiance) from the previous frame. Imagine looking at the last frame and figuring out which areas were bright or dark, then using that as a gentle hint for where shadows and highlights should be in the next frame.
Key idea 4: Autoregressive generation (frame-by-frame with memory)
“Autoregressive” means the model generates frame t using:
- The G-buffer for frame t (what’s in the scene now).
- The image it made for frame t–1 (to keep things consistent).
It keeps going like a chain, using each new output to help guide the next one.
Key idea 5: Training in three stages (practicing with increasing difficulty)
To make this process stable over long sequences, they trained the model in three steps:
- Stage 1: Learn the basics. Use only the G-buffer (no lighting hints), like practicing how to color correctly from outlines and materials.
- Stage 2: Add memory. Include the previous frame and the irradiance hint to start learning temporal consistency (keeping things steady between frames).
- Stage 3: Practice with your own mistakes. Train the model using its own generated frames as inputs, so it gets used to imperfect data and doesn’t spiral into errors over time.
What did they find?
The model works well for interactive, frame-by-frame rendering and produces realistic lighting effects such as global illumination, shadows, and reflections.
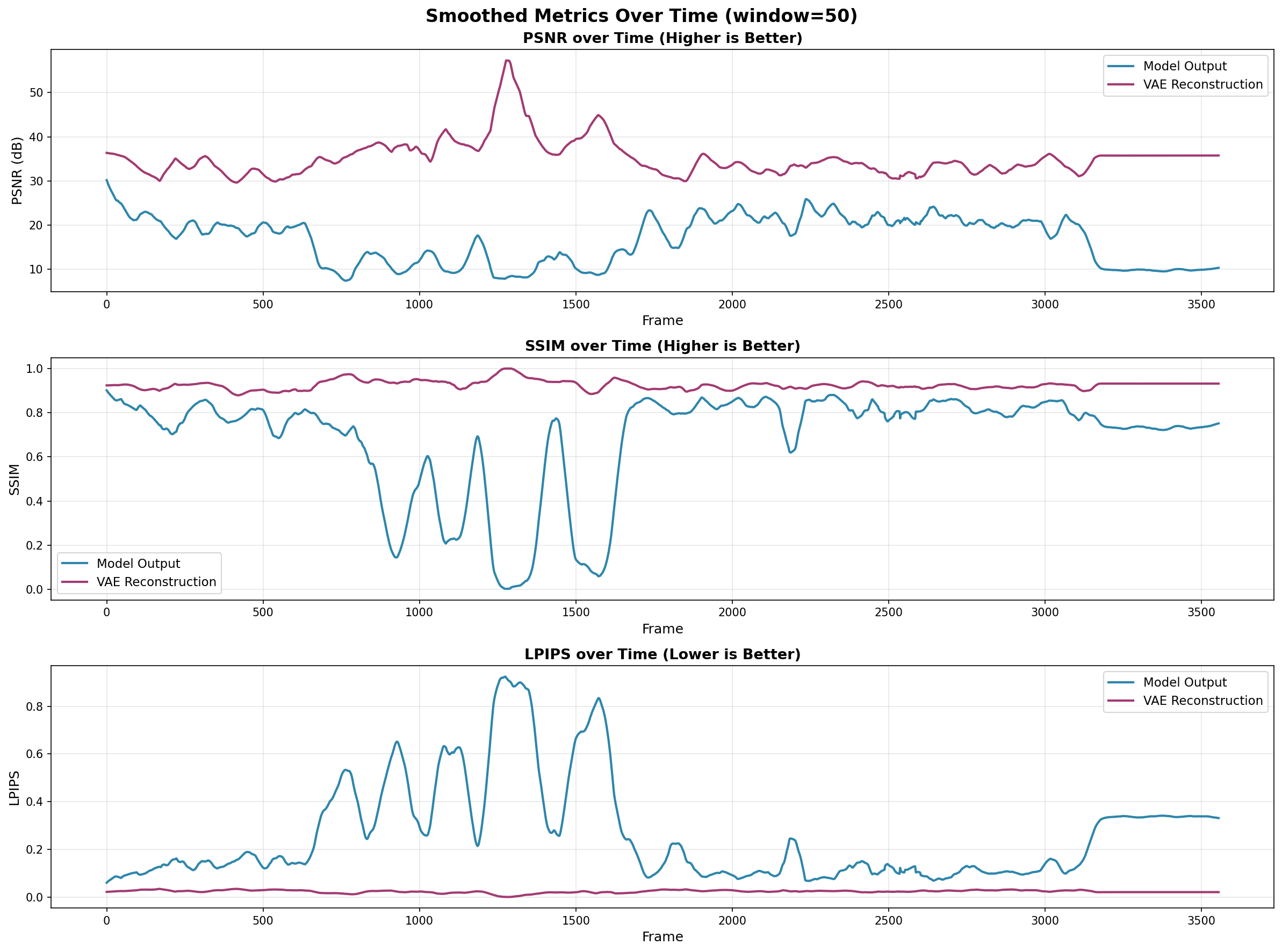
- Temporal stability: It stays consistent over hundreds to thousands of frames and avoids flickering or sudden changes.
- Better than a baseline: Compared to a strong single-image method (RGB↔X), FrameDiffuser had much better scores for structure and visual quality (higher SSIM and PSNR; lower LPIPS).
- Works in multiple environments: They trained separate models for six different Unreal Engine scenes (like city blocks, parks, and indoor spaces). Specializing per environment improved consistency and appearance.
- Handles scene edits: If you add an object (like a barrel or statue) to the scene, the model can generate the correct shadows and lighting for it automatically.
- Speed: On a high-end consumer GPU, it runs at about 1 frame per second—usable for demos and research, but not yet real-time gaming.
Why this is important
This research moves AI rendering closer to being useful in games and interactive tools:
- It bridges a gap: Single-image AI models don’t keep frames consistent; full video models need the whole sequence in advance. FrameDiffuser does it frame-by-frame, with memory, which fits how games work.
- It complements game engines: Artists keep control of the world’s geometry and materials. AI adds realistic lighting and effects that would normally require more expensive rendering methods (like ray tracing).
- Reliable look within one style: Training per environment (city, corridor, building) trades generality for consistent, high-quality visuals right where you need them.
Limitations and future directions (in simple terms)
- Speed: It’s not yet fast enough for real-time gaming on typical hardware, but future optimizations could help.
- Specialization: Each environment needs its own trained model. A more general model would be more flexible, but may lose consistency.
- Tough lighting cases: Very dark scenes cause some quality drops; they plan to improve handling of extreme lighting.
Overall, FrameDiffuser shows a practical path for blending traditional game data with AI-generated realism, especially when you need smooth, consistent frames that respond to player actions.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concise list of concrete gaps and unresolved questions that future work could directly address.
- Real-time performance: The model runs at ~1 fps on an RTX 4090 with 10 denoising steps; no systematic study of latency budgets, throughput targets (e.g., ≥30 fps), or the effectiveness of distillation, quantization, reduced step counts, caching, or streaming pipelines to reach interactive frame rates.
- Interactive engine integration: No end-to-end evaluation within a real game loop (e.g., UE5/Unity) covering asynchronous frame generation, buffer handoff, scheduling, frame drops, input latency, and fallback/recovery when generation lags.
- Initial frame bootstrapping: The method requires a starting frame and irradiance but does not specify how to obtain them without ground-truth (e.g., cold-start from G-buffer alone, low-cost raster baseline, or text/style priors) nor the impact of different bootstraps on long-horizon stability.
- Temporal drift and reset strategies: Error accumulation is noted in dark scenes and when camera motion is minimal, but no formal analysis of drift rates, maximum stable horizon, periodic re-grounding mechanisms (e.g., hybrid re-render checkpoints), or adaptive reset policies.
- Limited baselines and metrics: Comparisons are only against X→RGB (single-image). Missing evaluations against modern video diffusion renderers (e.g., DiffusionRenderer), autoregressive video baselines, and temporal metrics (e.g., FVD, tOF/tLPIPS, W-SSIM), as well as human perceptual studies.
- Lighting correctness and physical plausibility: Claims of realistic GI, shadows, and reflections are not validated with physically-based metrics (e.g., shadow accuracy, energy conservation, specular BRDF consistency) or comparisons to path-traced ground truth under controlled lighting.
- Irradiance representation: The irradiance is grayscale and computed as a ratio of previous output to basecolor, which ignores spectral/chromatic lighting, specular/diffuse separation, and emissive contributions. It is unclear how well it handles colored lights, high dynamic range, fast light motion, and abrupt lighting changes. More physically grounded or learned irradiance/shading representations remain unexplored.
- G-buffer channel set limitations: The method uses basecolor, normals, depth, roughness, and metallic but omits common buffers like ambient occlusion, specular/clearcoat, transmission/opacity, emissive, and anisotropy. The contribution of additional channels to lighting fidelity and temporal stability is not studied.
- Sky handling: The adaptive masking that injects sky information into basecolor is heuristic and unquantified. Robust handling of skyboxes, volumetric clouds, dynamic skies, and environment maps (cubemaps) without G-buffer support remains an open problem.
- Motion-aware conditioning: Prior-frame conditioning is not motion-compensated. Warping previous frame latents using camera transforms and depth, explicit occlusion masking, or flow-based alignment could reduce ghosting and drift; these are not explored.
- Variable time steps and frame-rate robustness: Training uses small temporal offsets (−2…2 frames). Handling larger inter-frame gaps, variable frame rates, and irregular update intervals typical of interactive systems is not investigated.
- Robustness in extreme darkness and high dynamic range: Metrics degrade in very dark rooms, indicating a bias toward lit regions. The training/inference treatment of HDR, tone mapping, exposure control, and sensor noise is unspecified.
- Dynamic and emissive content: Behavior with highly dynamic lights, emissive materials, translucent/transparent surfaces, subsurface scattering, and complex participating media (fog, smoke) is not evaluated or supported in the conditioning.
- Scene edits and lighting correctness: While qualitative edits (barrel, statue) are shown, there is no quantitative evaluation of shadow placement, penumbra softness, contact shadow correctness, reflective interplay, or GI changes after edits.
- Long-horizon consistency: Stability is claimed over “hundreds to thousands” of frames, but there is no systematic measurement of horizon length before quality collapse under diverse motion/light scenarios, nor strategies for online correction.
- Self-conditioning schedule: The 50% generated-frame ratio and noise injection parameters are not ablated. Optimal schedules, adaptive sampling, and curriculum policies for different environments and motion regimes remain unknown.
- ControlLoRA design: The LoRA rank (64), target layers, and conditioning concatenation choices are not analyzed. Alternative parameter-efficient temporal controls (e.g., adapters, FiLM, cross-attention) may improve stability or efficiency.
- ControlNet conditioning choices: The benefit of ControlNet vs channel concatenation or other conditioning schemes is asserted but not compared across consistent setups. Ablations on conditioning strength, zero-initialization, and multi-scale fusion are missing.
- Generalization vs specialization: The approach is environment-specific, requiring separate models per style. Data requirements, few-shot adaptation, online finetuning, mixture-of-experts routing, and cross-environment transferability are not evaluated.
- Text/style control: Built on a text-to-image backbone, but the paper does not assess whether text prompts or style tokens can modulate appearance at runtime without breaking temporal stability or geometry-faithfulness.
- Resource footprint: VRAM usage, memory bandwidth, and compute costs are not reported for training/inference. Practical constraints for consumer GPUs and mobile hardware, including batching strategies and model slimming, are unaddressed.
- Dataset transparency and reproducibility: The exact dataset sizes, frame counts, camera paths, light configurations, and data-release plans are unspecified. Reproducible benchmarks for UE environments and standardized splits would enable fair comparison.
- Hybrid rendering integration: Strategies to blend fast traditional raster outputs (e.g., shadow maps, SSR) with neural augmentation for stability and correctness (especially for reflections and contact shadows) are not explored.
- Temporal regularization and losses: There is no use of explicit temporal consistency losses (e.g., flow-consistent reconstruction or cycle consistency), nor an analysis of their impact versus pure conditioning.
- Handling newly revealed/occluded surfaces: No explicit occlusion reasoning when geometry changes between frames. Methods to avoid propagating appearance from previously occluded regions (e.g., depth-aware masks) are absent.
- Step count vs stability trade-offs: The impact of denoising step count on temporal consistency, image quality, and speed is not characterized, hindering principled design for interactive constraints.
- Engine-agnostic portability: Porting beyond UE5 (e.g., Unity, custom engines) with different G-buffer conventions and material models is not demonstrated, nor are normalization and calibration procedures across pipelines.
Practical Applications
Immediate Applications
The following applications can be deployed now, primarily in offline or near‑interactive workflows where 1 fps inference and environment‑specific training are acceptable.
- Bold: AI lighting preview and look‑dev inside game engines — Sectors: gaming, VFX/animation, AEC
- Description: Use G‑buffers from Unreal/Unity playblasts to synthesize photorealistic frames with realistic GI, shadows, and reflections for rapid lighting iteration and look‑dev without path tracing or full Lumen bakes.
- Potential tools/products/workflows: “Neural Lighting Preview” UE5/Unity editor plugin; viewport “AI render” toggle for playblasts; batch render queue for dailies.
- Assumptions/dependencies: Environment‑specific training per level/style; access to deferred G‑buffer (basecolor, normals, depth, roughness, metallic); GPU (e.g., RTX 4090); starting frame setup; acceptance of ~1 fps; Stable Diffusion licensing.
- Bold: Cinematics and marketing still/video generation (offline) — Sectors: gaming, VFX/animation
- Description: Replace expensive path‑traced previews for cutscenes and trailers with FrameDiffuser renders, maintaining temporal consistency over long shots.
- Potential tools/products/workflows: Command‑line batch renderer ingesting camera paths and G‑buffer sequences; shot review pipeline integration.
- Assumptions/dependencies: Offline rendering acceptable; per‑scene/per‑environment fine‑tuning; tone‑mapping/grade alignment to studio color pipeline.
- Bold: Scene editing with automatic shadows and reflections — Sectors: gaming, AEC, VFX/animation
- Description: While kitbashing or set‑dressing, the model infers cast shadows and specular behavior for newly added geometry directly from updated G‑buffers.
- Potential tools/products/workflows: “Auto‑shade new objects” tool in DCC/engine; asset approval review renders.
- Assumptions/dependencies: Accurate G‑buffer updates; consistent material authoring (basecolor/roughness/metallic); sky handling masks configured.
- Bold: Synthetic, photorealistic data generation from simulators — Sectors: robotics, autonomous driving, digital twins
- Description: Convert simulator G‑buffers (Unreal, CARLA, Isaac Sim) into photoreal images with temporal consistency to reduce sim‑to‑real gap for perception training.
- Potential tools/products/workflows: Dataset generator that pairs photoreal frames with perfect labels (depth, normals, segmentation) from the sim.
- Assumptions/dependencies: Offline batch acceptable; per‑domain specialization; careful lighting distribution to avoid bias (noted dark‑scene drift).
- Bold: Architectural walkthrough previews — Sectors: AEC, real estate
- Description: Produce photorealistic walkthrough videos from design models with realistic GI for client reviews without long path‑trace times.
- Potential tools/products/workflows: “Neural Walkthrough” exporter from UE5/Revit‑to‑UE; automatic camera path generation for design options.
- Assumptions/dependencies: Project‑specific training; consistent materials; client acceptance of preview quality.
- Bold: QA and content review at near‑final visual fidelity — Sectors: gaming
- Description: Overnight batch renders of playthroughs to catch lighting/shadowing issues otherwise visible only in final renders.
- Potential tools/products/workflows: CI/CD job that records playthroughs, exports G‑buffers, and renders photoreal sequences for QA dashboards.
- Assumptions/dependencies: Repeatable camera/input capture; storage for G‑buffers and outputs; non‑interactive batch time.
- Bold: Educational visualization of deferred pipelines and neural rendering — Sectors: education, academia
- Description: Demonstrate how G‑buffer channels map to final frames and how temporal conditioning stabilizes sequences.
- Potential tools/products/workflows: Teaching notebooks; side‑by‑side viewer showing G‑buffers, irradiance, and outputs.
- Assumptions/dependencies: Access to example datasets and trained weights; classroom GPUs.
- Bold: Research testbed for autoregressive stability — Sectors: academia, graphics research
- Description: Use the three‑stage training procedure (black‑irradiance pretraining → temporal conditioning → self‑conditioning) to study drift, noise injection, and temporal offsets.
- Potential tools/products/workflows: Ablation harness; benchmark suites for long‑horizon temporal metrics.
- Assumptions/dependencies: Experimental compute; reproducible training data; controlled environments.
- Bold: Cost‑reduction for offline render farms — Sectors: VFX/animation, gaming
- Description: Substitute path‑traced previews with FrameDiffuser for large shot queues; escalate to path‑tracing only for finals.
- Potential tools/products/workflows: Render farm adaptor connecting DCC exports (AOVs/G‑buffers) to neural renderer.
- Assumptions/dependencies: Visual sign‑off criteria defined; acceptance that sky and extreme darkness edge cases may need patch renders.
- Bold: Modding/UGC lighting helper — Sectors: gaming, creator economy
- Description: Help modders preview realistic lighting for new meshes/materials without mastering engine lighting workflows.
- Potential tools/products/workflows: Lightweight “Neural Relight” desktop tool reading G‑buffers from editor captures.
- Assumptions/dependencies: Access to G‑buffers through mod tools; per‑game tuned model distribution/licensing.
Long‑Term Applications
These require further research, distillation, and engineering (e.g., real‑time speed, broader generalization, deployment packaging).
- Bold: Real‑time neural rendering path in game engines — Sectors: gaming, graphics hardware
- Description: Integrate an optimized, distilled FrameDiffuser variant as a rendering stage replacing parts of GI/shadows/reflections at 30–120 fps.
- Potential tools/products/workflows: Engine render path plugin; TensorRT/XLA/DirectML backends; hybrid raster + neural GI with DLSS‑like integration.
- Assumptions/dependencies: Aggressive model distillation/architectural pruning; vendor NPU/GPU support; deterministic latency; robust handling of dark scenes and skyboxes.
- Bold: Cloud gaming and remote rendering bandwidth optimization — Sectors: cloud gaming, edge computing
- Description: Transmit compact scene buffers or parameterized G‑buffers and render photoreal frames at the edge/client with a specialized model to reduce bandwidth.
- Potential tools/products/workflows: “G‑buffer streaming” protocol; client‑side neural renderer; adaptive bitrate tied to G‑buffer complexity.
- Assumptions/dependencies: Proven bandwidth gains vs. cost of client inference; standardization of buffer formats; security of asset/material IP.
- Bold: In‑camera VFX for virtual production — Sectors: film/TV, virtual production
- Description: Real‑time photoreal synthesis on LED walls using per‑set trained models to approximate final lighting interactively.
- Potential tools/products/workflows: Stage‑calibrated models per set/environment; tight color pipeline integration; on‑set controls for look direction.
- Assumptions/dependencies: Low‑latency inference on stage hardware; stable temporal behavior under fast camera moves; union/guild acceptance and auditability.
- Bold: Photoreal AR/VR rendering on mobile and headsets — Sectors: AR/VR, mobile
- Description: Use lightweight G‑buffer from rasterization and device depth sensors to synthesize GI/shadows for immersive experiences.
- Potential tools/products/workflows: On‑device NPU acceleration; foveated neural rendering; mixed‑reality relighting of virtual inserts.
- Assumptions/dependencies: Mobile‑grade model distillation; power/thermal limits; robust sky/outdoor handling; privacy of on‑device assets.
- Bold: Sim‑to‑real training loops with interactive photoreal sim — Sectors: robotics, autonomous driving
- Description: Real‑time photoreal views from physics simulators conditioned on G‑buffers for on‑policy learning and closed‑loop RL.
- Potential tools/products/workflows: Simulator plugins (Isaac/Unreal) that emit buffers and render frames via accelerated neural renderer; domain randomization over materials/lighting.
- Assumptions/dependencies: Real‑time throughput; stability over very long horizons; coverage of edge conditions (night, rain, glare).
- Bold: City‑scale digital twins visualization — Sectors: smart cities, AEC, urban planning
- Description: Photoreal rendering of large‑scale urban twins with environment‑specific models to support planning, public engagement, and incident training.
- Potential tools/products/workflows: Twin platforms exporting G‑buffers; scheduled re‑renders for time‑of‑day or weather scenarios.
- Assumptions/dependencies: Scalable multi‑region training; standardization of material semantics; compute orchestration.
- Bold: Product staging and interactive commerce — Sectors: e‑commerce, retail
- Description: Insert products into scanned environments with scene‑aware shadows and reflections using coarse proxies/G‑buffers.
- Potential tools/products/workflows: Consumer app using room scans to derive normals/depth/material proxies; instant photoreal previews.
- Assumptions/dependencies: Reliable capture of G‑buffer proxies on consumer devices; per‑category style specialization; IP and branding approvals.
- Bold: Hybrid codecs for 3D/graphics streams — Sectors: media/streaming, software
- Description: New codecs that encode G‑buffers/material parameters and reconstruct photoreal video via a learned renderer on the client.
- Potential tools/products/workflows: Standards efforts for “neural graphics streams”; reference encoder/decoder implementations.
- Assumptions/dependencies: Interop standards; content protection; hardware decode assists; quality/latency proofs.
- Bold: Energy‑aware rendering and sustainability — Sectors: energy, policy, gaming
- Description: Reduce power draw vs. heavy ray tracing by offloading GI to efficient neural renderers with acceptable fidelity.
- Potential tools/products/workflows: Energy benchmarking suite; “green rendering” profiles in engines; eco‑labels for interactive products.
- Assumptions/dependencies: Verified energy/performance tradeoffs; certification frameworks; vendor cooperation.
- Bold: Content provenance and governance for AI‑augmented rendering — Sectors: policy, standards
- Description: Guidelines for disclosure, watermarking, and archival metadata when frames are AI‑augmented from G‑buffers; IP policies for training on proprietary scenes.
- Potential tools/products/workflows: C2PA‑style metadata embedding for neural renders; audit tools in pipelines.
- Assumptions/dependencies: Industry consensus; legal clarity on asset‑based training; robust watermarking resistant to postprocessing.
Notes on Feasibility and Dependencies (cross‑cutting)
- Environment specialization: Today’s approach favors per‑environment/per‑project models for stability and quality; generalization reduces fidelity.
- Performance: Current throughput ≈1 fps on RTX 4090 (10 denoising steps); real‑time requires distillation, architectural optimization, and hardware acceleration.
- Inputs: Requires reliable deferred G‑buffers (basecolor, normals, depth, roughness, metallic) and handling for sky regions; initial frame available.
- Stability: Self‑conditioning and noise injection mitigate drift; failure modes include very dark scenes and minimal motion leading to error accumulation.
- Integration: Best suited as an augmentation to, not a replacement for, existing raster pipelines; artist control over geometry/materials is preserved.
- Licensing/IP: Use of Stable Diffusion derivatives and training on proprietary assets must align with license terms and internal policies.
- Evaluation: Temporal metrics and perceptual QA should be part of acceptance criteria; compare to VAE reconstructions and path‑traced references where possible.
Glossary
- AdamW optimizer: A variant of the Adam optimizer with decoupled weight decay for better generalization in deep learning. "Training uses batch size 2 with gradient accumulation of 4, AdamW optimizer (weight decay ), and cosine learning rate scheduling."
- Adaptive masking: A technique to handle missing or unreliable regions by selectively injecting information, improving consistency. "We address this through adaptive masking that injects sky information into the basecolor channel:"
- Autoregressive drift: The accumulation of errors over time in sequential generation, leading to output degradation. "The autoregressive drift problem has motivated research into robustness techniques."
- Autoregressive generation: Producing each new frame conditioned on previous outputs, enabling sequential, interactive rendering. "We evaluate FrameDiffuser on autoregressive frame generation, comparing against baseline methods and analyzing our three-stage training strategy on temporal stability and generation quality."
- Base UNet: The primary UNet model in a diffusion pipeline, often kept frozen during certain training stages. "Only ControlNet trains while the base UNet remains frozen."
- Basecolor: The albedo or diffuse color input in physically based rendering, representing inherent material color without lighting. "The first nine channels represent common G-buffer data: basecolor (3 channels), Normals (3 channels), Depth, Roughness, and Metallic."
- Channel dropout training: A training strategy that randomly drops input channels to improve robustness to incomplete conditioning signals. "Their intrinsic switch mechanism and channel dropout training enable generation with incomplete G-buffer sets, achieving high-quality single-image synthesis."
- ControlLoRA: A parameter-efficient conditioning method using low-rank adapters to inject temporal information into diffusion models. "We use ControlLoRA~\cite{wu2024} to maintain temporal consistency by conditioning on the previous frame."
- ControlNet: An auxiliary network that provides spatial/structural conditioning to a diffusion model without disturbing its pretrained weights. "We employ ControlNet~\cite{zhang2023} to process 10-channel input comprising basecolor, Normals, Depth, Roughness, Metallic, and an additional irradiance channel."
- Cosine learning rate scheduling: A training schedule that adjusts the learning rate following a cosine curve to improve convergence. "Training uses batch size 2 with gradient accumulation of 4, AdamW optimizer (weight decay ), and cosine learning rate scheduling."
- Deferred rendering: A graphics pipeline where shading is computed after geometry data is assembled into buffers, enabling complex lighting. "Modern games employ deferred rendering pipelines that generate geometry buffers (G-buffer) storing per-pixel surface properties"
- Denoising steps: Iterative steps in diffusion sampling that progressively remove noise to synthesize the final image. "Inference employs 10 denoising steps with DPMSolver, achieving approximately 1 frame per second on an RTX 4090."
- DPMSolver: A fast sampler for diffusion models that accelerates generation with fewer steps. "Inference employs 10 denoising steps with DPMSolver, achieving approximately 1 frame per second on an RTX 4090."
- Environment-specific training: Specializing a model to a single domain/environment for improved consistency and speed over generalization. "We specialize our model to individual environments, prioritizing consistency and inference speed over broad generalization, demonstrating that environment-specific training achieves superior photorealistic quality with accurate lighting, shadows, and reflections compared to generalized approaches."
- Forward render task: The mapping from scene descriptors (e.g., G-buffer) to RGB images, as opposed to inverse rendering. "For the forward render task, they trained Stable Diffusion 2.1 with increased input channels to accommodate G-buffer data."
- G-buffer: A set of per-pixel geometry and material properties (e.g., depth, normals, albedo) produced by deferred rendering. "Modern games employ deferred rendering pipelines that generate geometry buffers (G-buffer) storing per-pixel surface properties"
- GANs: Generative Adversarial Networks that synthesize images via adversarial training of generator and discriminator. "Generative Adversarial Networks (GANs)~\cite{goodfellow2014} pioneered high-quality neural image synthesis through adversarial training between generator and discriminator networks."
- Global illumination (GI): Indirect lighting effects from light bouncing in a scene, producing realistic illumination. "FrameDiffuser transforms geometric and material data from G-buffer into photorealistic rendered images with realistic global illumination (GI), shadows, and reflections."
- Gradient accumulation: Technique to simulate larger batch sizes by accumulating gradients over multiple steps before updating weights. "Training uses batch size 2 with gradient accumulation of 4, AdamW optimizer (weight decay ), and cosine learning rate scheduling."
- Intrinsic switch mechanism: A control strategy in RGB↔X enabling flexible conditioning by switching among available input channels. "Their intrinsic switch mechanism and channel dropout training enable generation with incomplete G-buffer sets, achieving high-quality single-image synthesis."
- Irradiance: The intensity of light received at a surface, used here as a temporal lighting cue derived from previous frames. "We introduce an irradiance map that encodes temporal lighting information."
- Latent space: A compressed representation space (e.g., via VAE) where diffusion operates efficiently. "The encoder and decoder represent the VAE components operating in latent space."
- Lightmaps: Precomputed lighting textures baked into scenes to approximate illumination without runtime computation. "Beyond the geometric and material information in G-buffer, FrameDiffuser synthesizes photorealistic lighting including global illumination, shadows, reflections, and atmospheric effects that would traditionally require expensive ray tracing or pre-baked lightmaps."
- Logarithmic intensity encoding: A lighting representation using log-scaled intensities to handle high dynamic range in diffusion rendering. "Their lighting representation combines tone mapping, logarithmic intensity encoding, and directional information, achieving impressive visual quality for complete video sequences."
- LoRA: Low-Rank Adaptation; a method to fine-tune large models efficiently by adding small trainable matrices. "LoRA~\cite{hu2022} provided efficient adaptation through low-rank matrices, reducing trainable parameters while maintaining performance."
- LPIPS: Learned Perceptual Image Patch Similarity; a metric assessing perceptual similarity between images. "We employ standard image quality metrics: SSIM (Structural Similarity Index) for structural preservation, PSNR (Peak Signal-to-Noise Ratio) for pixel-level accuracy, and LPIPS (Learned Perceptual Image Patch Similarity) for perceptual alignment."
- Metallic: A PBR material property indicating how metal-like a surface is, affecting reflectance. "The first nine channels represent common G-buffer data: basecolor (3 channels), Normals (3 channels), Depth, Roughness, and Metallic."
- Mode collapse: A failure mode in GANs where the generator produces limited diversity, collapsing to a few outputs. "However, GANs suffer from training instability and mode collapse, limiting their practical deployment."
- Normals: Per-pixel surface normal vectors used to determine orientation and shading in rendering. "The first nine channels represent common G-buffer data: basecolor (3 channels), Normals (3 channels), Depth, Roughness, and Metallic."
- Noise injection: Adding noise to conditioning inputs during training to improve robustness and reliance on primary signals. "Noise Injection. We apply noise to the previous RGB frame before irradiance computation (Equation~\ref{eq:irradiance}):"
- Parameter-efficient fine-tuning: Adapting large models using a small number of additional parameters (e.g., via LoRA). "Low-rank adaptation matrices applied to convolutional and linear layers throughout the UNet enable parameter-efficient fine-tuning."
- PSNR: Peak Signal-to-Noise Ratio; a metric measuring pixel-level reconstruction fidelity. "We employ standard image quality metrics: SSIM (Structural Similarity Index) for structural preservation, PSNR (Peak Signal-to-Noise Ratio) for pixel-level accuracy, and LPIPS (Learned Perceptual Image Patch Similarity) for perceptual alignment."
- Ray tracing: Rendering technique that simulates rays of light for accurate reflections and shadows, but is computationally heavy. "Beyond the geometric and material information in G-buffer, FrameDiffuser synthesizes photorealistic lighting including global illumination, shadows, reflections, and atmospheric effects that would traditionally require expensive ray tracing or pre-baked lightmaps."
- Roughness: A PBR material property controlling microfacet distribution and specular blur. "The first nine channels represent common G-buffer data: basecolor (3 channels), Normals (3 channels), Depth, Roughness, and Metallic."
- Self-conditioning: Training a model on its own generated outputs to reduce train-test distribution mismatch for stable autoregression. "We now introduce self-conditioning by periodically injecting generated frames into the training that are produced using the current model weights."
- Skyboxes: Large environment textures used to render skies/backgrounds, often lacking geometric data in deferred pipelines. "Sky regions present a challenge as deferred rendering provides no geometric data for skyboxes, resulting in empty G-buffer regions."
- SSIM: Structural Similarity Index; a metric evaluating structural similarity between images. "We employ standard image quality metrics: SSIM (Structural Similarity Index) for structural preservation, PSNR (Peak Signal-to-Noise Ratio) for pixel-level accuracy, and LPIPS (Learned Perceptual Image Patch Similarity) for perceptual alignment."
- Stable Diffusion: A latent diffusion model used as the backbone for image synthesis in this framework. "FrameDiffuser builds on Stable Diffusion 1.5, which is a pure text-to-image diffusion model, augmenting it with two complementary conditioning mechanisms that enable autoregressive frame generation."
- Stable Video Diffusion: A video diffusion model that generates sequences simultaneously, learning spatio-temporal patterns. "Video diffusion models like Stable Video Diffusion~\cite{blattmann2023} and earlier work by Ho et al.~\cite{ho2022video} generate entire sequences simultaneously, learning spatio-temporal patterns across complete videos."
- Temporal coherence: Consistency of appearance across consecutive frames in a video sequence. "Our dual-conditioning architecture separates structural guidance from temporal coherence, enabling stable frame-by-frame generation for interactive applications."
- Temporal consistency: Maintaining stable content and appearance across frames without flicker or abrupt changes. "Our autoregressive approach maintains temporal consistency for long sequences, enabling neural rendering for interactive applications."
- Temporal offset sampling: Sampling previous frames at varying time offsets during training to improve robustness across transitions. "Temporal Offset Sampling. We sample temporal offsets with higher weights for adjacent frames to prevent overfitting to single-frame transitions."
- Tone mapping: Mapping HDR lighting data to displayable ranges, often used in rendering pipelines. "Their lighting representation combines tone mapping, logarithmic intensity encoding, and directional information, achieving impressive visual quality for complete video sequences."
- UNet: A convolutional encoder-decoder architecture commonly used in diffusion models for denoising. "ControlNet creates a trainable copy of the UNet encoder with zero-initialized connections, ensuring that training starts from the pre-trained state without disruption."
- VAE: Variational Autoencoder used to encode/decode images into a latent space for efficient diffusion. "The encoder and decoder represent the VAE components operating in latent space."
- VAE reconstruction: Reconstructed image from the VAE decoder to assess encoding fidelity and degradation. "We compare our model output against pure VAE reconstruction to measure encoder degradation."
- Video diffusion models: Generative models that synthesize entire video sequences by modeling spatio-temporal dependencies. "Video diffusion models like Stable Video Diffusion~\cite{blattmann2023} and earlier work by Ho et al.~\cite{ho2022video} generate entire sequences simultaneously, learning spatio-temporal patterns across complete videos."
- Weight decay: Regularization technique that penalizes large weights to improve generalization. "AdamW optimizer (weight decay ), and cosine learning rate scheduling."
Collections
Sign up for free to add this paper to one or more collections.