Generative Refocusing: Flexible Defocus Control from a Single Image
Abstract: Depth-of-field control is essential in photography, but getting the perfect focus often takes several tries or special equipment. Single-image refocusing is still difficult. It involves recovering sharp content and creating realistic bokeh. Current methods have significant drawbacks. They need all-in-focus inputs, depend on synthetic data from simulators, and have limited control over aperture. We introduce Generative Refocusing, a two-step process that uses DeblurNet to recover all-in-focus images from various inputs and BokehNet for creating controllable bokeh. Our main innovation is semi-supervised training. This method combines synthetic paired data with unpaired real bokeh images, using EXIF metadata to capture real optical characteristics beyond what simulators can provide. Our experiments show we achieve top performance in defocus deblurring, bokeh synthesis, and refocusing benchmarks. Additionally, our Generative Refocusing allows text-guided adjustments and custom aperture shapes.



















Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a way to turn any single photo into a “virtual camera” you can control after you’ve already taken the shot. It lets you change what’s in focus, how strong the background blur (bokeh) is, and even the shape of the blur (like circles, hearts, or stars), all from one image—no special hardware or multiple shots needed.
What are the main goals?
In simple terms, the researchers want to:
- Fix blurry parts of a photo so everything can be sharp if you want.
- Add natural-looking blur back in a controlled way (like a real camera lens would).
- Let you control the blur’s strength, where the focus is, and even the blur’s shape.
- Learn not just from computer-made examples, but also from real photos taken with real cameras, so the results look truly realistic.
How does it work?
Think of their method as a two-step process:
- DeblurNet: cleaning up the image
- Problem: Photos often have “defocus blur”—parts are soft because the camera focused at the wrong distance.
- What DeblurNet does: It tries to recover the “all-in-focus” version of your photo, like cleaning a smudged window so you can see everything clearly.
- How it learns: It uses a “diffusion model,” which you can imagine as an artist who repeatedly refines a rough sketch into a detailed picture, step by step. It also looks at a simple pre-deblurred version (a safe-but-soft fix) to keep the overall structure correct while restoring fine details.
- BokehNet: adding controllable blur back
- Once you have a sharp, clean image, BokehNet applies “bokeh”—the stylish blur you see in portraits and night photos.
- You can set:
- Focus plane: the distance where things are sharp (e.g., the person in the middle or the buildings in the back).
- Bokeh level: how strong the blur is (like changing your camera’s aperture).
- Aperture shape: the shape of the blur spots (usually circles, but can be hearts, stars, etc.).
- It uses a “defocus map,” which is basically a plan that tells each part of the image how blurry it should be based on the scene’s depth and the focus distance you choose. Depth is estimated from the image itself, like guessing how far objects are.
How it learns to look real:
- Synthetic pairs: The team uses computer-made training examples where they know exactly what’s in focus and how the blur should look. This teaches the system the rules of depth and blur.
- Real unpaired bokeh photos: They also learn from real photos with blur effects, even if there isn’t a perfect “before and after” pair. They use EXIF metadata (the info your camera stores with a photo, like focal length and f-number) as hints to estimate how the lens actually behaved. This helps the model learn real-world lens characteristics that simulators miss.
Simple analogies for key terms:
- Depth of field: How much of the scene is sharp at once. A small depth of field means just one distance is sharp and the rest is blurred.
- Aperture: The opening in a camera lens. Bigger aperture (small f-number) lets in more light and gives stronger blur; smaller aperture (big f-number) gives more of the scene in focus.
- Bokeh: The quality of the out-of-focus blur, especially how lights look (usually soft circles or shaped highlights).
- Focus plane: The distance in front of the camera where things are sharp.
- EXIF metadata: The “ID card” of the photo—technical settings saved by the camera, like lens and aperture.
- Diffusion model: A method that starts with a noisy or rough image and improves it step by step, like refining a sketch into a finished drawing.
What did they find?
The researchers tested their system on several benchmarks and compared it to well-known methods. Key results:
- Better deblurring: Their DeblurNet recovered sharp details (like tiny text) more accurately and with fewer artifacts than other approaches.
- More realistic bokeh: Their BokehNet produced blur that looks closer to real photos, handling tricky cases like gradual blur and edges between foreground and background better than baselines.
- Strong refocusing performance: As a complete pipeline (deblur then re-bokeh), it outperformed combinations of other deblurring and bokeh methods.
- Extra controls:
- Text-guided help: You can give hints (like the correct spelling of a word) to help the system reconstruct blurred text.
- Custom shapes: You can make point lights in the background turn into hearts, stars, and more, while keeping the scene consistent.
Why this matters:
- It makes single-photo editing far more flexible—like having a camera you can still adjust after you’ve already taken the shot.
- It learns from real photos and camera settings, so the blur looks “lens-real,” not just computer-faked.
Why is this important, and what could it lead to?
Implications:
- For everyday photographers: You can fix missed focus or create artistic blur after the fact, no fancy gear required.
- For creators and designers: You gain fine control over blur style, strength, and shape, opening up new visual effects.
- For research and apps: The semi-supervised training approach—mixing simulated data with real unpaired photos and using camera metadata—could improve other image editing tasks.
Limitations and future ideas:
- Depth estimation from a single image can be wrong in hard scenes, which can misplace the focus. Improving depth estimation would help.
- Complex aperture shapes need good training examples; creating richer shape datasets (even user-drawn designs) could expand creativity.
In short, this paper shows how to turn one photo into a flexible, realistic, and creative refocusing experience by first making everything sharp, then reapplying blur with full control—just like adjusting a real camera lens, but after the picture is taken.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and concrete opportunities for future research stemming from this work:
- Depth dependence and failure modes
- Reliance on monocular depth without uncertainty modeling; no mechanism to propagate depth uncertainty into defocus maps or modulate bokeh strength accordingly.
- Lack of systematic analysis of depth errors around thin structures and occlusion boundaries (e.g., foreground/background halos), and no explicit occlusion-aware loss or constraint.
- No support for non-planar or user-defined focal surfaces (e.g., curved/segmented focal regions); control is limited to a single global plane S1.
- Physical accuracy and camera realism
- Approximate EXIF-based bokeh level estimation K lacks validation against ground-truth physical measurements; no per-lens calibration for aberrations or lens-specific PSFs.
- Key optical phenomena are not modeled/controlled: exposure changes with f-number, focus breathing, field curvature, vignetting, cat’s-eye bokeh near the image edges, swirl/coma/spherical aberration, onion-ring artifacts on highlights.
- Absolute blur size calibration across cameras (sensor size, crop factor, ISP pipelines) is not standardized; the “pixel_ratio” heuristic and depth scale alignment are unverified across devices.
- Aperture shape control
- Shape-aware synthesis is learned primarily from simulated point-light data; generalization to real images with sparse highlights or extended sources remains untested.
- PSF shape is treated as globally uniform; real lenses exhibit field- and depth-dependent PSF anisotropy and clipping that are not modeled.
- No protocol to ingest free-form/user-drawn shapes with physically plausible scaling and field-dependent deformation.
- Robustness and generality
- Behavior under mixed degradations (defocus + motion blur, rolling shutter, noise, compression artifacts) is unexplored; DeblurNet is specialized for defocus blur only.
- Failure cases in extreme regimes (macro shots with very large CoC, low light/high ISO noise, HDR specular highlights, transparent/refractive surfaces) are not quantified.
- Generalization across camera domains (smartphones vs. DSLRs, RAW vs. sRGB, different ISPs) is not evaluated; cross-device calibration remains open.
- Pipeline assumptions and artifacts
- The two-stage design assumes accurate AIF recovery; hallucinations from DeblurNet can propagate into BokehNet, yet content faithfulness vs. perceptual quality is not measured (e.g., no identity/text fidelity metrics or uncertainty maps).
- Inference-time tiling can break global coherence for large CoC or shape effects; seam/consistency artifacts and their mitigation are not analyzed.
- The approach does not simulate exposure coupling when changing aperture; brightness and DoF are decoupled, potentially yielding physically inconsistent edits.
- Data and supervision gaps
- Semi-supervised learning depends on EXIF completeness and manual expert filtering of in-focus masks; the scalability, reproducibility, and potential bias of this human-in-the-loop step are not addressed.
- K estimation for real pairs without EXIF uses simulator-in-the-loop SSIM sweeping, which risks circular bias toward the simulator and may not reflect true optics.
- No ablation on different depth estimators or depth-quality improvements (e.g., ensembles, priors, consistency from multi-cues) and their impact on refocusing accuracy.
- Evaluation limitations
- Benchmarks (LF-Bokeh, LF-Refocus) are partly synthesized from light-field data; the extent to which this biases results toward methods aligned with the simulator is not examined.
- No user study assessing perceptual realism, preference, and control predictability; reliance on automated IQA metrics may not capture photographic plausibility.
- Reported NR-IQA gains “beyond GT” suggest perceptual enhancement but not necessarily truthfulness; fidelity–hallucination trade-offs are not quantified.
- Efficiency and deployment
- Computational cost, latency, and memory footprint (diffusion steps, tiling overhead) are not reported; feasibility for interactive, on-device, or real-time editing remains unclear.
- Sensitivity to the choice and quality of the pre-deblur model is not studied; robustness when the auxiliary input is absent or unreliable is not quantitatively evaluated.
- Extensions and broader impacts
- No treatment of temporal consistency for video refocusing; extension to sequences and stabilization across frames is open.
- Lack of mechanisms to communicate uncertainty or confidence to users during editing, which could prevent overtrust in hallucinated details.
- Ethical/forensic considerations (e.g., reconstructing unseen details, authenticity disclosure, content provenance) are unaddressed.
Practical Applications
Immediate Applications
The following applications can be deployed today using the paper’s two-stage Generative Refocusing pipeline (DeblurNet + BokehNet), semi-supervised training strategy (synthetic + unpaired real bokeh with EXIF), and explicit controls (focus plane, bokeh intensity, aperture shape).
- [Software/Consumer Photography] Post-capture refocusing in photo editors
- Use case: Add “Virtual Camera” controls in Photoshop/Lightroom, Capture One, Affinity, and mobile editors to adjust focus plane, depth-of-field strength, and creative aperture shapes after capture.
- Tools/workflow:
- Tap-to-focus plane selection; slider for bokeh intensity K (mapped to f-number); aperture-shape gallery (circle, triangle, heart, star).
- Pipeline: DeblurNet (recover AIF) → monocular depth → defocus map → BokehNet (render bokeh).
- Assumptions/dependencies:
- GPU/NN accelerator recommended for acceptable latency; model tiling for high-resolution images.
- Depth quality impacts focus-plane accuracy; performance is best on photographic content.
- Aperture shape effects are most visible when point lights or specular highlights are present.
- [Smartphones/Imaging OEMs] “Refocus after capture” mode (offline/on-device)
- Use case: Let users fix focus mistakes and artistically reframe phone photos without reshooting.
- Tools/workflow: Integrate models as an optional post-capture enhancement in gallery apps; reuse device EXIF and ToF/depth (if available).
- Assumptions/dependencies:
- Needs model optimization (quantization/distillation) for mobile NPUs; non-real-time initially.
- Privacy-safe, on-device processing preferred.
- [Social Media/Creative Apps] Creative bokeh filters with custom aperture shapes
- Use case: Heart/star-shaped bokeh for holiday lights or concerts; interactive refocus for portrait posts.
- Tools/workflow: In-app “Aperture Studio” filter; tap subject to refocus; choose shape overlay for bokeh highlights.
- Assumptions/dependencies: Shape visibility depends on scene content (point lights); ensure latency is acceptable for user experience.
- [E-commerce/Marketing] Product-focus enhancement and salvage of slightly defocused shots
- Use case: Emphasize products by narrowing DoF or rescuing soft images for catalogs and marketplaces.
- Tools/workflow: Batch pipeline for studios and DAM systems; QA tool to compare before/after and mask artifacts.
- Assumptions/dependencies:
- Generative deblurring may hallucinate fine text or patterns—human QA recommended.
- Use for aesthetic enhancement, not for measurement or scientific imaging.
- [OCR/Enterprise/Finance] Text-focused deblurring pre-processing
- Use case: Improve OCR success on receipts, checks, labels, and ID photos; optional text-prompt guidance to resolve ambiguous characters.
- Tools/workflow: DeblurNet + text prompt; confidence scoring; fall back to conservative sharpening if ambiguity is high.
- Assumptions/dependencies:
- Risk of hallucinated characters; include human-in-the-loop for compliance-critical workflows (KYC, legal docs).
- Keep immutable originals and change logs.
- [VFX/Photography Studios] Still-image refocusing and stylized bokeh in post
- Use case: Adjust focus and aperture style on plates or hero stills without re-shooting; match lens signatures.
- Tools/workflow: Plugin for Nuke/Photoshop; align with color pipeline; shape-conditioned bokeh for specific lens looks.
- Assumptions/dependencies: Monocular depth errors may require manual depth masks for critical shots.
- [Education] Interactive optics labs and photography courses
- Use case: Teach the relationship between focus plane, f-number, and aperture shape in an interactive app.
- Tools/workflow: Map bokeh level K to approximate f-number and focal length; show live previews with sliders.
- Assumptions/dependencies: Use curated images with reliable depth to ensure pedagogical clarity.
- [Research/Academia] Semi-supervised learning template for photographic effects
- Use case: Reuse the paper’s EXIF-conditioned semi-supervised recipe (synthetic pairs + unpaired real images) to train other optics-aware editors (exposure, vignetting, flare).
- Tools/workflow: Adopt the provided LF-Bokeh/LF-Refocus evaluation settings; extend shape-aware rendering for PSF studies.
- Assumptions/dependencies: Requires access to EXIF fields (focal length, f-number, sensor size) or simulator-in-the-loop calibration.
- [Policy/Newsrooms/Forensics Ops] Disclosure and labeling of refocus edits
- Use case: Add “focus-edited” tags in editorial pipelines; preserve provenance to mitigate misrepresentation.
- Tools/workflow: Embed C2PA provenance; export edit logs (focus plane, K, shape, model version).
- Assumptions/dependencies: Organizational policy adoption and staff training; standards compliance.
Long-Term Applications
These applications require further research, scaling, optimization, or ecosystem integration (e.g., real-time performance, temporal consistency, regulatory approval).
- [Smartphones/Video Conferencing] Real-time refocusing and bokeh (photos and video)
- Opportunity: Live “shoot first, focus later” capture and cinematic background blur with accurate occlusion and creative aperture shapes.
- Needed advances:
- Model compression/distillation for on-device real-time; temporal consistency for video; robust depth via multi-sensor fusion (ToF/SLAM).
- ISP co-design and energy-aware scheduling.
- Dependencies/risks: Power, thermal budgets; privacy; scene diversity and failure handling.
- [AR/VR/XR] Gaze-aware dynamic DoF for immersion
- Opportunity: Adjust synthetic DoF continuously based on eye tracking to mimic human accommodation.
- Needed advances: Ultra-low-latency depth, gaze-conditioned refocus, foveated rendering integrations, temporal stability.
- Dependencies/risks: Tight latency constraints (<10–20 ms), comfort, and simulator sickness considerations.
- [Healthcare/Scientific Imaging] Assistive refocus and deblurring (non-diagnostic initially)
- Opportunity: Pre-screening or triage for endoscopy frames, dermatology images, or pathology slide thumbnails to flag out-of-focus regions.
- Needed advances: Clinical validation against gold standards, uncertainty quantification, conservative reconstruction modes (non-hallucinatory).
- Dependencies/risks: Regulatory approvals (FDA/CE), auditability, prohibition of use for definitive diagnosis unless validated.
- [Security/Forensics] Detection and provenance of focus manipulations
- Opportunity: Classifiers and metadata standards to identify post-capture refocusing and distinguish from optical DoF.
- Needed advances: Large-scale datasets of refocus edits; standardized EXIF/C2PA fields capturing focus edits; cross-model generalization.
- Dependencies/risks: Adversarial counter-forensics; need for international coordination.
- [Autonomy/Robotics/AV] Dataset augmentation with realistic lens blur
- Opportunity: Improve robustness of perception models to lens blur by augmenting training data with physically grounded bokeh and defocus.
- Needed advances: Label-preserving augmentations; analytical control over blur fields; integration with simulation stacks.
- Dependencies/risks: Avoid label corruption; ensure augmentations reflect real-world optics.
- [Drones/Surveillance/Industrial Inspection] Real-time salvage of defocused frames
- Opportunity: On-edge deblurring to maintain readability of serial numbers or signage when re-acquisition is costly.
- Needed advances: Low-latency inference on edge accelerators; reliability gating with uncertainty scores; operator-in-the-loop UIs.
- Dependencies/risks: Hallucination risk; strict audit trails.
- [Commerce/Web] Interactive product pages with user-controlled focus
- Opportunity: Let customers adjust focus plane and DoF on product images to examine details vs. overall look.
- Needed advances: WebGPU/WebNN deployment, serverless acceleration, caching of AIF/depth assets, accessible UI.
- Dependencies/risks: Browser compatibility; bandwidth/latency; IP/licensing for model weights.
- [Cinematography/Virtual Production] On-set virtual aperture control
- Opportunity: Preview different apertures and focus pulls on captured plates without lens swaps.
- Needed advances: High-res, near-real-time operation; integration with on-set monitoring and lens metadata; planar and volumetric depth corrections.
- Dependencies/risks: Artistic control requires manual overrides; need for robust depth under complex lighting.
- [Photo Labs/Printing] Virtual lens selection at order time
- Opportunity: Offer customers selectable DoF and bokeh style before printing archival photos.
- Needed advances: Scalable cloud “Refocus-as-a-Service” with QC; consistent color management and soft-proofing.
- Dependencies/risks: User consent and provenance; handling of edge cases (motion blur, extreme OOF).
- [Open Ecosystem/Standards] Aperture-shape vocabularies and PSF libraries
- Opportunity: Community-driven libraries of real lens PSFs (cat’s eye, onion rings, anamorphic) for shape-aware synthesis.
- Needed advances: Standardized shape descriptors/PSFs; capture protocols; licensing frameworks.
- Dependencies/risks: IP concerns; dataset bias.
Cross-cutting assumptions and dependencies
- Depth estimation is a critical dependency; severe failures can misplace the focal plane and degrade realism.
- Realistic bokeh level estimation depends on accurate EXIF (focal length, f-number, sensor size) or simulator-in-the-loop calibration.
- Generative deblurring can hallucinate fine details (e.g., text); high-stakes use requires human oversight, provenance, and uncertainty indicators.
- Performance constraints: diffusion backbones typically require GPU/NPUs; mobile and real-time scenarios need compression/distillation and temporal models.
- Aperture-shape effects are content-dependent; scenes lacking point-light stimuli exhibit subtler shape cues.
- Ethical and policy considerations: disclose focus edits in journalism/forensics; preserve originals and edit logs; comply with provenance standards (e.g., C2PA).
Glossary
- All-in-focus (AIF): An image in which all scene depths are sharp and in focus; often used as a target for deblurring or as input for bokeh synthesis. "BokehNet expects an AIF image, a target bokeh image, and the corresponding defocus map"
- Aperture shape: The geometric shape of the lens opening, which determines the shape of out-of-focus highlights (bokeh). "(c) highlights aperture shape control, synthesizing creative heart-shaped bokeh from point lights in the scene."
- Aperture size: The effective opening of the lens (f-number) controlling depth of field and blur intensity. "(a) demonstrates aperture size control, allowing the user to vary the depth of field from strong bokeh to an all-in-focus image."
- Bokeh: The aesthetic quality of out-of-focus blur in an image. "It involves recovering sharp content and creating realistic bokeh."
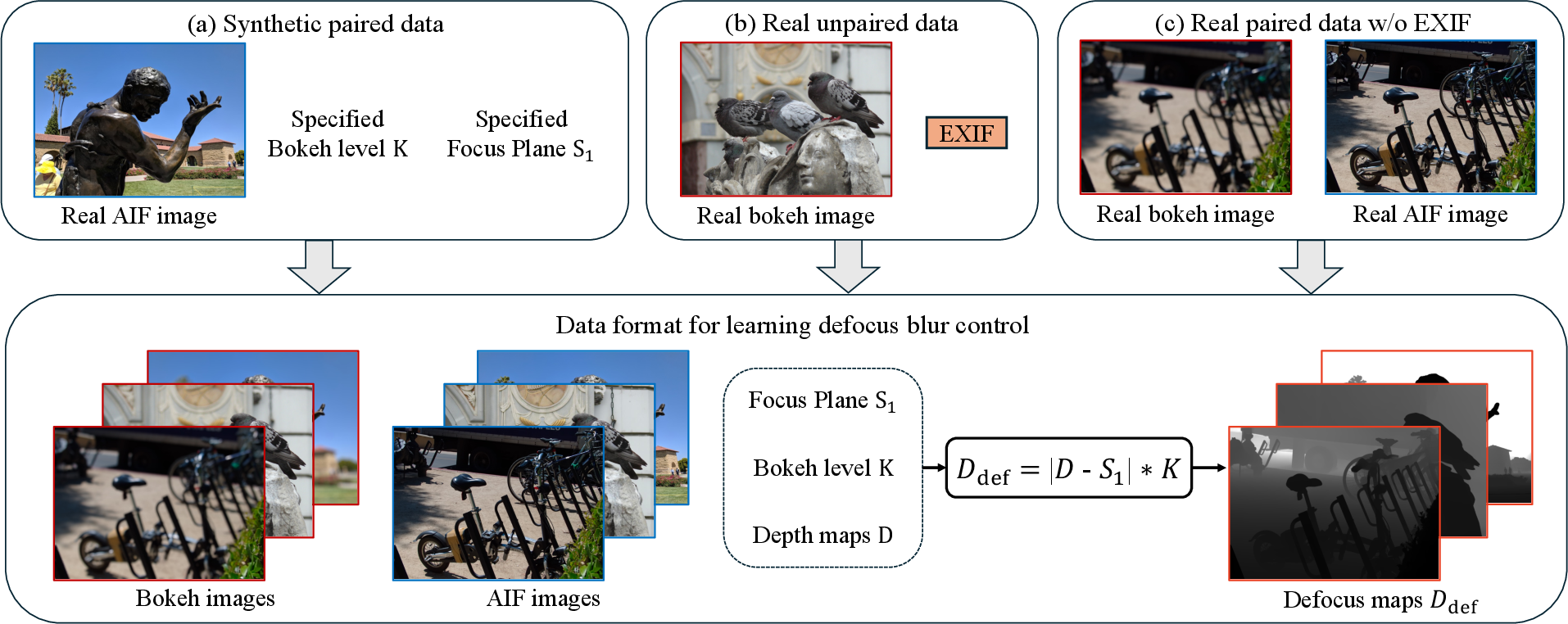
- Bokeh level (K): A scalar parameter controlling the magnitude of the blur based on camera parameters and scene geometry. "We further leverage unpaired real bokeh images with EXIF metadata (see Fig.~\ref{fig:data_generaton}\,(b)) and estimate an approximate bokeh level following \cite{Fortes2025BokehDiffusion}:"
- BokehNet: The paper’s module that synthesizes controllable bokeh from an all-in-focus input and control signals. "Our BokehNet creates fully customizable bokeh, considering user-defined focus planes, bokeh intensity, and aperture shapes (\cref{fig:teaser})."
- CLIP-I: A CLIP-based metric variant for assessing image fidelity or perceptual similarity. "Method & LPIPS~ & DISTS~ & CLIP-I~ \"
- CLIP-IQA: A CLIP-based no-reference image quality assessment metric. "We report both reference-based metrics (LPIPS, FID) and no-reference perceptual quality metrics (CLIP-IQA, MANIQA, MUSIQ)."
- Circle of confusion: The projected blur spot size on the sensor that determines perceived defocus. "This stage quickly trains the network to modulate the circle of confusion based on the defocus map"
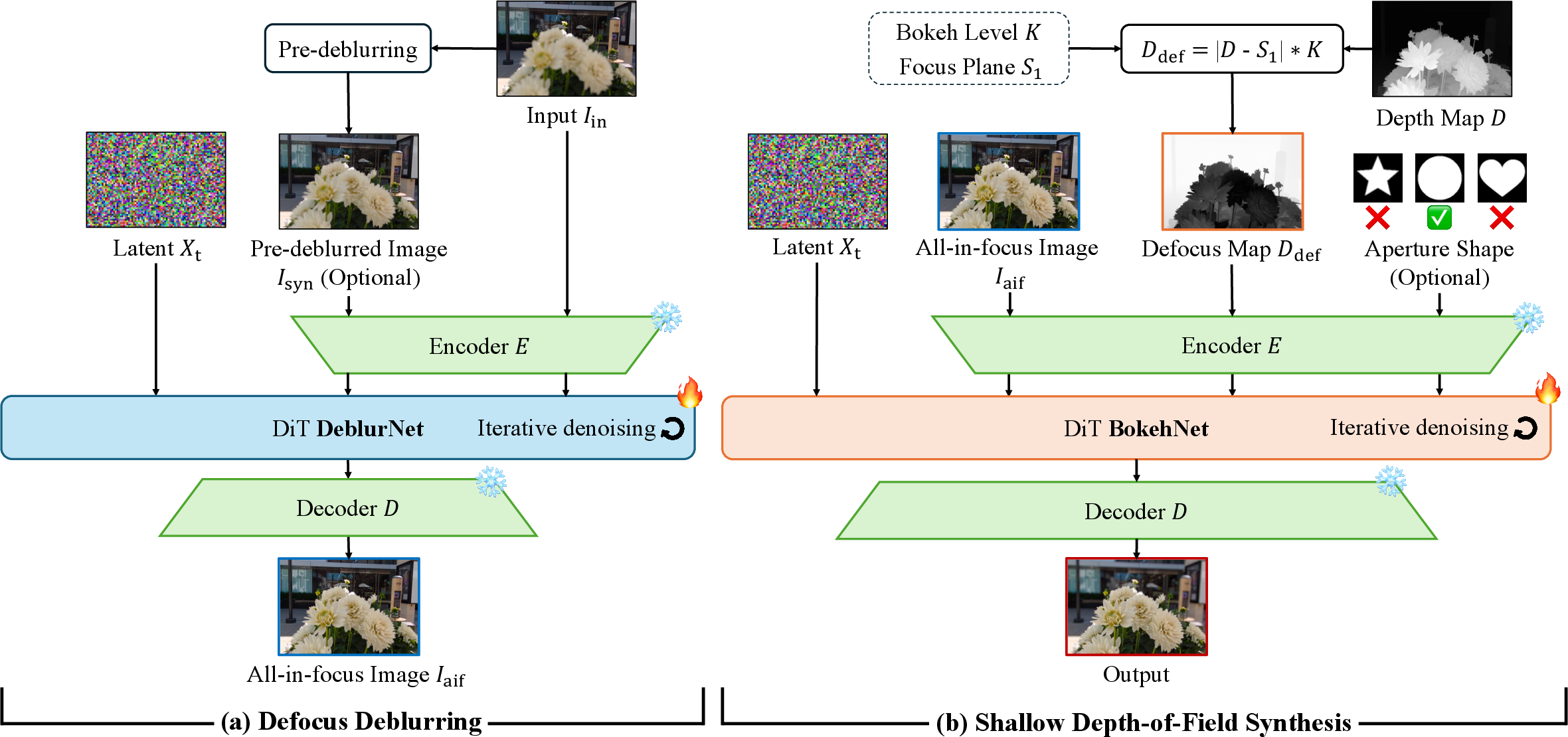
- DeblurNet: The paper’s diffusion-based deblurring module that recovers all-in-focus images from defocused inputs. "We introduce Generative Refocusing, a two-step process that uses DeblurNet to recover all-in-focus images from various inputs and BokehNet for creating controllable bokeh."
- Defocus deblurring: The restoration task of removing spatially varying blur caused by depth-of-field limitations. "Defocus deblurring recovers sharp images from spatially varying blur caused by limited depth of field."
- Defocus map: A per-pixel map specifying blur strength, parameterized by focus and scene depth. "Blur magnitude is dictated by a defocus map parameterized by a user-specified focus point and the scene depth."
- Depth map: A per-pixel estimate of scene depth used to compute the defocus magnitude. "The defocus map $D_{\text{def}$ is computed based on the estimated depth map ~\cite{Bochkovskiy2025DepthPro}, along with both the user-specified focus plane and bokeh level ."
- Depth-of-field (DoF): The range of scene distances that appear acceptably sharp in a photograph. "Depth-of-field control is essential in photography"
- DiT backbone: A diffusion transformer backbone used for processing latent image representations. "The VAE encoder and decoder convert images to latent representations for processing by the DiT backbone."
- DISTS: Deep Image Structure and Texture Similarity; a perceptual image similarity metric. "Method & LPIPS~ & DISTS~ & CLIP-I~ \"
- Dual-pixel sensors: Image sensors with split pixels enabling depth-from-defocus and improved blur-depth modeling. "Dual-pixel sensors~\cite{DPDD}, quad-pixel data~\cite{chen2025quad}, and disparity-aware techniques~\cite{IFANet,yang2023k3dn,wang2021bridging} improved blurâdepth modeling and the recovery of all-in-focus images from focal stacks."
- EXIF metadata: Embedded camera metadata (e.g., focal length, aperture) used to estimate real optical characteristics. "using EXIF metadata to capture real optical characteristics beyond what simulators can provide."
- FID: Fréchet Inception Distance; a metric comparing distributions of image features. "We report both reference-based metrics (LPIPS, FID) and no-reference perceptual quality metrics (CLIP-IQA, MANIQA, MUSIQ)."
- FLUX-1-dev: A specific generative diffusion backbone used as the base model. "Our base generative backbone is FLUX-1-dev \cite{ShakkerLabs2024FluxControlNetUnionPro}, fine-tuned via LoRA \cite{hu2022lora} with a multi-condition scheme following \cite{Tan2025OminiControl2}."
- Focus plane: The plane in the scene intended to be sharp, used to parameterize defocus control. "(b) illustrates focus plane control by shifting the sharp region from the middle subject to the background."
- Generative prior: Learned distributional knowledge from a generative model used to guide restoration or editing. "using FLUX's~\cite{ShakkerLabs2024FluxControlNetUnionPro} generative prior to enable controllable bokeh synthesis from any input."
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning technique for large models. "fine-tuned via LoRA \cite{hu2022lora}"
- LPIPS: Learned Perceptual Image Patch Similarity; a perceptual distance metric between images. "We report both reference-based metrics (LPIPS, FID) and no-reference perceptual quality metrics (CLIP-IQA, MANIQA, MUSIQ)."
- MANIQA: A no-reference image quality assessment metric based on attention mechanisms. "We report both reference-based metrics (LPIPS, FID) and no-reference perceptual quality metrics (CLIP-IQA, MANIQA, MUSIQ)."
- Monocular depth estimation: Estimating scene depth from a single image, often challenging under blur. "When the input is blurry, monocular depth estimation is brittle, undermining precise control over the defocus map and often yielding misfocus or artifacts."
- MUSIQ: Multi-scale Image Quality; a no-reference image quality metric. "We report both reference-based metrics (LPIPS, FID) and no-reference perceptual quality metrics (CLIP-IQA, MANIQA, MUSIQ)."
- NIQE: Natural Image Quality Evaluator; a no-reference image quality metric. "{MUSIQ} & {NIQE} & {CLIP-IQA} \"
- Occlusion handling: Managing visibility boundaries where objects block others to render realistic blur transitions. "Our BokehNet synthesizes bokeh effects that better match ground truth with realistic blur gradients and natural occlusion handling."
- Point spread function (PSF): The impulse response of the imaging system, defining blur kernel shape. "a shape kernel (binary/raster PSF), the simulator renders"
- Pre-deblur: An auxiliary initial deblurred estimate used to condition the main deblurring model. "a conservative pre-deblur generated by an off-the-shelf defocus deblurring model."
- Pre-deblur dropout: A regularization technique that randomly drops the pre-deblur input during training to improve robustness. "Pre-deblur dropout. During training, we stochastically replace $I_{\mathrm{pd}$ with a zero tensor (at a fixed probability),"
- Renderer bias: Systematic artifacts or distribution mismatch introduced by synthetic rendering/simulation. "This stage quickly trains the network to modulate the circle of confusion based on the defocus map, but it remains constrained by renderer bias and may introduce non-realistic artifacts."
- Semi-supervised training: Training that combines labeled (paired) synthetic data with unlabeled (unpaired) real data to improve realism. "Our main innovation is semi-supervised training."
- SSIM: Structural Similarity Index; a reference-based metric for image similarity. "we conduct a per-image binary search over the bokeh level and select the value that maximizes SSIM with the target."
- Tiling strategy: An inference technique that processes overlapping image patches and blends them to handle high resolutions. "We adopt a tiling strategy inspired by ~\cite{multidiffusion} at evaluation time"
- Token grid: The 2D arrangement of tokens after downsampling, used to encode positional information for transformers. "where denotes the side length of the token grid after downsampling $I_{\mathrm{in}$."
- VAE encoder/decoder: Variational Autoencoder components that map images to and from a latent space for efficient diffusion processing. "The VAE encoder and decoder convert images to latent representations for processing by the DiT backbone."
Collections
Sign up for free to add this paper to one or more collections.