Robust-R1: Degradation-Aware Reasoning for Robust Visual Understanding
Abstract: Multimodal LLMs struggle to maintain reliable performance under extreme real-world visual degradations, which impede their practical robustness. Existing robust MLLMs predominantly rely on implicit training/adaptation that focuses solely on visual encoder generalization, suffering from limited interpretability and isolated optimization. To overcome these limitations, we propose Robust-R1, a novel framework that explicitly models visual degradations through structured reasoning chains. Our approach integrates: (i) supervised fine-tuning for degradation-aware reasoning foundations, (ii) reward-driven alignment for accurately perceiving degradation parameters, and (iii) dynamic reasoning depth scaling adapted to degradation intensity. To facilitate this approach, we introduce a specialized 11K dataset featuring realistic degradations synthesized across four critical real-world visual processing stages, each annotated with structured chains connecting degradation parameters, perceptual influence, pristine semantic reasoning chain, and conclusion. Comprehensive evaluations demonstrate state-of-the-art robustness: Robust-R1 outperforms all general and robust baselines on the real-world degradation benchmark R-Bench, while maintaining superior anti-degradation performance under multi-intensity adversarial degradations on MMMB, MMStar, and RealWorldQA.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Degradation-Aware Reasoning for Robust Visual Understanding — Explained Simply
What is this paper about?
This paper tackles a big problem in AI that looks at images and answers questions (called multimodal LLMs, or MLLMs). In the real world, photos and videos are often messy—blurry, noisy, too dark, or covered by something. Most AI systems get confused by these “bad” images. The authors introduce a new way, called Robust-R1 (a “degradation-aware reasoning” framework), that teaches AI to first recognize what’s wrong with an image, then think through how that affects what it sees, and finally give an answer as if the image were clean.
What are the main goals?
In simple terms, the paper tries to help AI:
- Notice the kinds of problems in an image (like “blur” or “noise”) and how strong they are.
- Explain how those problems affect what can be seen or understood in the picture.
- Reason carefully enough to fix the confusion—but not waste time “overthinking.”
- Give correct and clear answers, with an understandable chain of reasoning.
How does the method work?
Think of the AI like a careful detective examining a messy photo before solving a case. The method has three main parts:
- Supervised Fine-Tuning (SFT): The AI is trained with examples that include a step-by-step “reasoning chain” using special tags:
<TYPE>: What kind of image problem it detected (e.g., noise, blur), and how strong it is.<INFLUENCE>: How those problems change what the AI can see or understand.<REASONING>: A logical reconstruction of what the scene would look like without those problems.<CONCLUSION>(and sometimes<ANSWER>): The final explanation and the answer.
- Reinforcement Learning (RL) with rewards: The AI practices and gets “points” (rewards) for doing two things well:
- Getting the image problems right: It earns more points when it correctly identifies the type and severity of the degradation.
- Using the right amount of thinking: If the image is very damaged, the AI should use a longer reasoning chain; if it’s only slightly damaged, it should keep the chain short. This prevents “overthinking.”
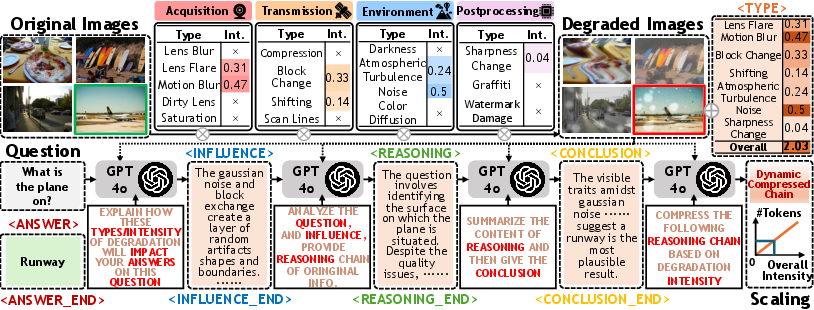
- A specialized dataset: The team built a new dataset of 11,000 examples where clean images were intentionally degraded in realistic ways across four stages of real-world processing:
- Acquisition (camera issues like lens blur or flare)
- Transmission (compression or scan lines)
- Environment (darkness, noise, air distortions)
- Postprocessing (sharpness changes, graffiti, watermark damage)
Each example includes the image problems, their effects, a clean reasoning path, and a conclusion—so the AI learns not just from images, but from explanations.
What did they find?
The method was tested on several benchmarks:
- R-Bench: A test specifically for understanding images with real-world degradation.
- MMMB, MMStar, and RealWorldQA: General visual understanding tests where the images were intentionally degraded.
Key results:
- The new approach (Robust-R1) beat both regular AI models and other “robust” AI models at different levels of image damage (low, medium, high).
- When images were attacked with multiple kinds of degradation, Robust-R1’s accuracy dropped much less than other models.
- The AI’s reasoning is more interpretable: it shows a clear chain of thought about what went wrong and how it handled it.
- The “length reward” helped the model avoid using overly long explanations when they weren’t needed, improving speed without hurting accuracy.
Why is this important?
In the real world, we often deal with imperfect images: think self-driving cars in rain, security cameras at night, phones with smudged lenses, or drones flying in fog. An AI that can:
- Recognize image problems,
- Explain how those problems affect what it sees,
- And still give reliable answers, is far more useful and trustworthy.
This research:
- Makes multimodal AI more robust and reliable in messy environments.
- Improves interpretability (you can see the reasoning steps).
- Offers a practical dataset and open resources to help other researchers build on this.
What’s the potential impact?
- Safer and more dependable systems in areas like transportation, healthcare imaging, robotics, and rescue operations.
- Better user trust because the AI shows how it handled visual issues.
- A foundation for future work on reasoning with degraded inputs—possibly extending to videos, audio, or real-time scenarios.
Overall, the paper’s message is simple: don’t just train AI to see better—teach it to recognize visual problems, think through them, and explain its reasoning. That’s how you get robust visual understanding in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Dataset realism and validation: The 11K corpus is fully synthetic and GPT-4o–annotated; no human validation of degradation labels, influence narratives, or reasoning chains is reported. Establish inter-annotator agreement and perceptual studies to verify realism and annotation quality.
- Limited degradation coverage: The four-stage degradation taxonomy omits common real-world artifacts (e.g., occlusion, chromatic aberration, rolling shutter, lens vignetting, glare from specular surfaces, viewpoint changes, overexposure, HDR clipping, sensor banding). Extend taxonomy and quantify coverage.
- Intensity calibration: Degradation intensity lacks mapping to physical units or standardized metrics (e.g., PSNR, blur kernel statistics, noise variance). Provide calibration protocols and conversions for cross-dataset comparability.
- Compositional effects of multiple degradations: The framework treats degradation parameters as independent and sums rewards across instances. Investigate interactions (nonlinear compounding, order effects) and add set matching (e.g., Hungarian assignment) to avoid double-counting and misalignment when multiple types co-occur.
- Reward function scope: RL rewards target
r_deg(parameter accuracy) andr_len(length matching), but not downstream task correctness (answer/caption accuracy). Evaluate adding correctness rewards and analyze trade-offs with parameter/length rewards. - “Optimal” reasoning length source: The ground-truth chain length used by
r_lenis generated by GPT-4o rather than derived from task performance/utility. Define a principled optimality criterion (efficiency–accuracy Pareto frontier) and learn length adaptivity from outcomes. - Text-to-number intensity parsing: The paper does not specify how the model outputs continuous intensities (from text to numeric) for
r_deg. Detail the parsing, discretization, or regression approach and its error characteristics. - Interpretability fidelity: Accuracy of predicted degradation parameters is shown only on the synthetic dataset. Assess on real-world images without ground-truth via proxy tasks (e.g., no-reference quality metrics, expert ratings) and measure calibration (ECE/Brier scores) for parameter predictions.
- Efficiency quantification: Dynamic reasoning depth is claimed to improve efficiency, but no latency, token count, FLOPs, or cost measurements are provided. Report compute–accuracy curves and speedups under diverse degradation intensities.
- Generalization across backbones: The approach is demonstrated only on Qwen2.5-VL-3B with frozen vision encoder. Test across different MLLMs (sizes and architectures), and analyze contributions from freezing vs. partial/joint tuning.
- Comparison with restoration pipelines: The method reconstructs “pristine semantic reasoning” without image restoration. Benchmark against hybrid pipelines (image restoration + standard reasoning) and explore integrating restoration modules or differentiable pre-processing.
- Task breadth: Evaluation targets MCQ/VQA/CAP; robustness for OCR-heavy tasks, chart/diagram interpretation, detection, segmentation, localization, and grounding is untested. Extend to tasks where degradations affect fine-grained perception.
- Prompt and question difficulty confounds: Reasoning length may correlate with question complexity independent of degradation. Disentangle the effects via controlled experiments varying degradation intensity and question difficulty.
- Real-world parameter estimation: The method aligns to synthetic parameter ground truths; no pathway is provided to obtain or estimate ground truths in real deployments (e.g., camera metadata, sensor readings). Propose unsupervised/weakly supervised parameter estimation methods.
- Security and safety implications: “Reconstructing pristine semantics” risks hallucinating unseen content (e.g., behind occlusions). Define safety constraints, uncertainty reporting, and conservative reasoning strategies to avoid overconfident extrapolation.
- Robustness beyond degradations: Adversarial robustness is evaluated via “real-world degradations,” but not gradient-based attacks, patch adversaries, or multimodal prompt-based adversaries. Extend evaluation to adversarial threat models common for MLLMs.
- Reward credit assignment granularity: Composite rewards are applied at the sequence level using GRPO; segment-specific credit assignment (e.g., per
<TYPE>,<INFLUENCE>,<REASONING>,<CONCLUSION>) is not explored. Investigate fine-grained RL signals to improve targeted components. - Overfitting to length–intensity template: Step (5) in the data pipeline enforces a template mapping intensity to chain length, potentially causing overfitting. Test generalization to unseen intensity distributions and alternative length heuristics.
- Real-world benchmarks with parameter labels: R-Bench does not supply degradation parameters. Create or adopt benchmarks with verified parameter labels to rigorously test
r_degalignment in the wild. - Fairness and domain shift: Training on A-OKVQA subset may bias content distribution. Examine robustness under domain shifts (medical, industrial, satellite imagery) and fairness across demographic and environmental contexts.
- Replicability of adversarial degradation setup: Details for generating “25%, 50%, 100%” degradations on MMMB/MMStar/RealWorldQA are sparse (types, parameters, seeds). Provide attack recipes, code, and reproducibility documentation.
- Statistical significance and variability: Results lack confidence intervals, seed variability, and significance testing. Report per-seed variance and conduct statistical tests to substantiate SOTA claims.
- Scaling laws and data size sensitivity: No analysis of how dataset size, RL/SFT ratio, or reward weights affect performance. Study scaling behaviors and identify data-efficient regimes.
- Failure mode analysis: The paper does not present qualitative analyses of cases where reasoning fails (e.g., compounded degradations, extreme darkness). Catalog error types to inform targeted improvements.
- Multimodal extension: The approach is image–text only. Explore extension to video (temporal degradations like motion blur, compression artifacts), audio-visual tasks, and multi-image reasoning under degradation.
- Framework identification: The method’s name is missing in several places (“,” placeholder). Clarify the model/framework naming and versioning to avoid ambiguity in citations and reproducibility.
- Ethical and deployment considerations: No discussion of user-facing uncertainty communication, calibration of confidence under degradation, or guidelines for deployment in safety-critical contexts. Develop reporting standards and fail-safe mechanisms.
Practical Applications
Summary
The paper introduces an explicit degradation-aware reasoning framework for multimodal LLMs (MLLMs) that can perceive visual degradation types and intensities, reason about their semantic impact, reconstruct pristine reasoning chains, and adapt reasoning depth to degradation severity. The authors release an 11K structured dataset, training code, model weights, and a Space demo (Robust-R1). Empirical results show state-of-the-art robustness across multiple degraded-vision benchmarks. Below are practical applications that leverage the framework’s findings, methods, and released artifacts.
Immediate Applications
These applications can be piloted or deployed now using the released model, dataset, and code; they rely on the framework’s structured reasoning chain, degradation-parameter perception, and dynamic reasoning depth.
- Robust VLM plugin for degraded inputs (software/ML tooling)
- Use case: Integrate “degradation-aware reasoning” as a drop-in module to enhance vision-language pipelines in apps that process user-generated images or camera feeds.
- Product/workflow: A wrapper that injects
<TYPE>,<INFLUENCE>,<REASONING>,<CONCLUSION>tokens; deploys Robust-R1 checkpoints; exposes a Degradation Parameter Perception API. - Assumptions/dependencies: Base VLM compatibility (e.g., Qwen2.5-VL family), modest latency overhead from longer chains, domain gap (trained on synthetic degradations), licensing of open weights.
- Quality-aware content moderation and UGC understanding (media/social platforms)
- Use case: Captioning, VQA, and misinformation/harm detection in compressed, noisy, or blurred uploads.
- Product/workflow: Moderation microservice that first detects degradation parameters and then generates interpretable reasoning and conclusions for audit.
- Assumptions/dependencies: False-positive risk under atypical artifacts; scaling inference at platform traffic volumes; alignment to platform policies.
- CCTV/edge monitoring with interpretable alerts (public safety, facilities management)
- Use case: Describe events under poor lighting, occlusion, lens dirt, or motion blur; generate explainable incident summaries.
- Product/workflow: Edge VLM node that estimates degradation and adjusts chain length for efficiency; dashboards show degradation type/intensity alongside scene interpretation.
- Assumptions/dependencies: On-device compute constraints; latency budgets; camera calibration to match synthetic degradation profiles.
- Industrial inspection under dirty lens/lighting variability (manufacturing/quality control)
- Use case: Identify defects or anomalies when camera optics are suboptimal (dirty lens, flare, saturation shift).
- Product/workflow: Degradation-aware inspector that first diagnoses acquisition/postprocessing artifacts and then reasons about product defects with traceable chains.
- Assumptions/dependencies: Domain-specific fine-tuning; mapping synthetic degradations to real production lines; integration with MES/QMS systems.
- Retail and logistics: robust product recognition and label reading (retail/warehouse)
- Use case: Barcode/label reading, shelf monitoring, and parcel verification when images have compression or scan-line artifacts.
- Product/workflow: Handheld/scanner app that runs robust VQA captioning and directs re-scans when degradation is detected.
- Assumptions/dependencies: OCR integration; variable lighting; throughput needs in busy operations.
- Assistive vision under poor capture conditions (accessibility/education)
- Use case: Scene description and question answering for users with low-quality cameras (noise, dark, blur).
- Product/workflow: Mobile app that outputs answers plus a human-readable chain explaining how degradations were handled.
- Assumptions/dependencies: Privacy/compliance for on-device inference; UI for showing reasoning; resource limits on consumer devices.
- Telemedicine photo/video triage (healthcare)
- Use case: Non-diagnostic assistance in triaging patient-provided images (teleconsults) despite compression or noise.
- Product/workflow: Front-end triage assistant that flags severe degradation, requests retakes, or provides contextual reasoning for clinicians.
- Assumptions/dependencies: Not a diagnostic tool; requires clinical oversight; domain adaptation and cautious deployment in regulated settings.
- Stream/video quality monitoring with semantic resilience (media streaming/OTT)
- Use case: Identify transmission-related artifacts (compression, block change, scan lines) and maintain semantic understanding of scenes for QC dashboards.
- Product/workflow: Monitoring bot that estimates degradation parameters frame-wise and produces interpretable reports.
- Assumptions/dependencies: Extension from images to video; throughput optimization; ground truth for incident labeling.
- Research benchmark augmentation (academia)
- Use case: Train and evaluate robust VLMs against structured degradation annotations; reproduce results with Robust-R1.
- Product/workflow: Dataset and code usage for SFT/RL (GRPO) with r_deg and r_len rewards; interpretability analyses.
- Assumptions/dependencies: GPT-4o-generated reasoning annotations may bias style; ensure mixed-domain validation; compute resources for RL.
- AI audit logs for decision transparency in poor data conditions (policy/compliance)
- Use case: Provide interpretable traces explaining decisions with degraded inputs for compliance audits.
- Product/workflow: Add reasoning chains to AI outputs; policy dashboards highlighting degradation diagnosis and compensation steps.
- Assumptions/dependencies: Standardization of reasoning formats; acceptance by regulators; storage and privacy practices.
Long-Term Applications
These applications require further research, scaling, domain adaptation, or integration into safety-critical environments.
- Safety-critical autonomy with degrade-aware perception (transportation/robotics)
- Use case: ADAS/robot navigation under rain/flare/darkness with explicit degradation diagnosis and adaptive reasoning depth.
- Product/workflow: Fusion of degrade-aware VLM with sensor stacks (LiDAR/RADAR) and formal runtime monitors.
- Assumptions/dependencies: Real-time guarantees; certification; extensive field validation beyond synthetic degradations.
- Clinical imaging assistance under imperfect acquisitions (healthcare)
- Use case: Supporting workflows when scans or photos are suboptimal (e.g., portable devices, emergency settings).
- Product/workflow: PACS-integrated assistant that flags artifacts and produces explainable reasoning; suggests reacquisition steps.
- Assumptions/dependencies: Rigorous clinical validation; domain-specific training; regulatory approvals.
- Closed-loop network and codec optimization (telecom/media)
- Use case: Use perceived transmission degradations to adapt streaming codecs or network policies in real time.
- Product/workflow: Controller that maps detected artifact types/intensity to encoding params (bitrate, resolution, error correction).
- Assumptions/dependencies: Access to encoder APIs; fast inference under live conditions; robust video extensions.
- Dynamic compute governance for LLMs (software/infra)
- Use case: Generalized reasoning-length controllers that allocate compute based on input quality to reduce overthinking.
- Product/workflow: Inference scheduler leveraging r_len-like metrics without ground-truth; cross-model policy for budget-aware reasoning.
- Assumptions/dependencies: Learning length policies unsupervised; stability across tasks and models.
- Standardized explainability for degraded sensing (policy/standards)
- Use case: Industry-wide templates and tokens reporting environmental conditions and reasoning steps for compliance.
- Product/workflow: Open standards for degradation reporting (<TYPE>, <INFLUENCE>, <REASONING>, <CONCLUSION>) embedded in outputs.
- Assumptions/dependencies: Multi-stakeholder consensus; tooling across vendors; harmonization with existing AI transparency frameworks.
- Domain-specific degradation synthesis services (data/ML ops)
- Use case: Generate realistic, labeled degradations for domains like satellite, underwater, microscopic imaging.
- Product/workflow: SaaS pipeline that mirrors the paper’s 4-stage model and structured reasoning annotations; supports SFT/RL.
- Assumptions/dependencies: Quality and diversity of synthetic degradations; annotation cost; licensing for large-scale use.
- Robust adversarial defense via degradation diagnostics (security)
- Use case: Detect adversarial perturbations by identifying anomalous degradation parameter patterns before model inference.
- Product/workflow: Gatekeeper that filters or sanitizes inputs; triggers hardening workflows when suspected attacks are detected.
- Assumptions/dependencies: Coverage of attack types beyond natural degradations; false-positive/negative management.
- Disaster response and earth observation (energy/public sector)
- Use case: Maintain scene understanding with atmospheric turbulence, smoke, or compression in aerial imagery.
- Product/workflow: Mission-planning assistant that diagnoses image quality and produces robust captions/VQA for situational awareness.
- Assumptions/dependencies: Multi-sensor fusion; geo-specific training; operational constraints in the field.
- Extreme-environment robotics (mining, underwater, space)
- Use case: Reliable perception under occlusions and noise with explicit reasoning and adaptive compute.
- Product/workflow: Integration with SLAM/vision stacks; explainable perception modules feeding autonomy layers.
- Assumptions/dependencies: Hardware constraints; resilience testing; cross-modal extensions.
- Forensic analysis of degraded evidence (legal/public safety)
- Use case: Transparent reasoning over low-quality CCTV or bodycam footage to support investigations.
- Product/workflow: Forensics toolkit that logs degradation parameters and reasoning steps; helps assess evidence quality.
- Assumptions/dependencies: Legal admissibility of AI-assisted analyses; audit trails; human-in-the-loop review.
Cross-cutting assumptions and dependencies
- Synthetic-to-real generalization: Performance depends on how closely synthetic degradations match field conditions; domain-specific finetuning may be required.
- Annotation sources: Some dataset annotations were generated via GPT-4o; style or bias could propagate; independent validation recommended.
- Compute and latency: Explicit reasoning can increase token lengths; r_len mitigates but edge deployments still need careful optimization.
- Modalities and video: The framework is image-focused; extending to video/audio requires additional modeling and dataset work.
- Governance: Interpretable chains are promising for policy, but standards and regulator acceptance will take time.
Glossary
- A-OKVQA: A benchmark dataset for open-ended visual question answering used for constructing and evaluating reasoning tasks. "To support this approach, we construct an 11K dataset from A-OKVQA~\cite{schwenk2022aokvqabenchmarkvisualquestion}, comprising 10K training and 1K validation samples."
- Adversarial degradation: Artificial, often worst-case, corruptions applied to images to stress-test model robustness. "Furthermore, when subjected to adversarial degradation on general visual understanding benchmarks (MMMB~\cite{sun2025parrotmultilingualvisualinstruction}, MMStar~\cite{chen2024we}, and RealWorldQA~\cite{xai2024grok15v}), \ maintains significantly robust performance."
- Adversarial pre-training: Pretraining models using adversarially corrupted data to enhance robustness at scale. "More recent approaches, such as Robust LLaVA~\cite{malik2025robust}, have sought to mitigate these issues through large-scale adversarial pre-training."
- Approximation operator: A notation indicating the goal of making outputs under degraded inputs approximate those under clean inputs. "the approximation operator $\xrightarrow{\text{approx}$ signifies the objective of approximating the output under pristine visual conditions."
- Atmospheric Turbulence: Image distortion caused by refractive index fluctuations in the atmosphere, leading to blur and warping. "Environment (Darkness, Atmospheric Turbulence, Noise, Color Diffusion)"
- Block Change: Visual artifact associated with block-based transmission or compression causing unnatural block boundaries. "Transmission (Compression, Block Change, Shifting, Scan Lines)"
- Color Diffusion: A color artifact where hues bleed or spread, degrading image fidelity. "Environment (Darkness, Atmospheric Turbulence, Noise, Color Diffusion)"
- Compression: Reducing image data size, often introducing artifacts that degrade visual quality. "Transmission (Compression, Block Change, Shifting, Scan Lines)"
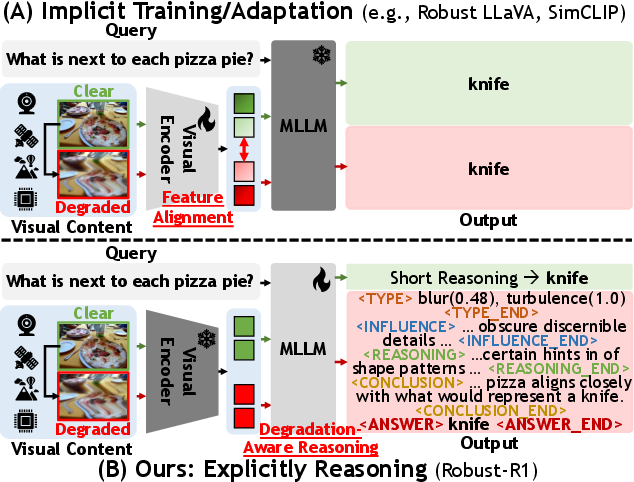
- Degradation-aware reasoning: An explicit reasoning process that infers degradation type/intensity, its impact, and reconstructs clean semantics. "we explicitly integrate the degradation-aware reasoning chain into MLLM."
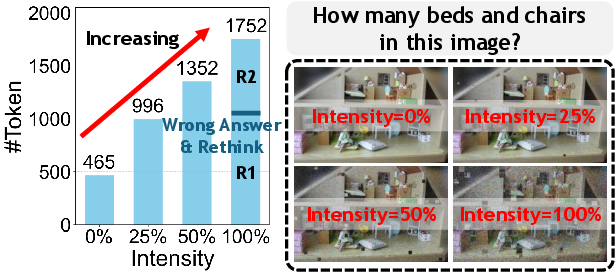
- Degradation intensity: The quantitative severity level of a visual degradation applied to an image. "The complexity of these reasoning chains is dynamically scaled with the degradation intensity to balance robustness with computational efficiency."
- Degradation parameters: The set of variables describing degradations, typically type and intensity. "degradation parameters (type and intensity)"
- Degradation parameter space: The space of all possible degradation types and intensities used for alignment and evaluation. "we design a reward function that directly operates in the degradation parameter space"
- Dirty Lens: Artifacts caused by dust or smudges on the camera lens that obscure or distort the image. "Acquisition (Lens Blur, Lens Flare, Motion Blur, Dirty Lens, Saturation)"
- Dynamic reasoning depth scaling: Adjusting the number of reasoning steps based on degradation severity to balance accuracy and efficiency. "(iii) dynamic reasoning depth scaling adapted to degradation intensity."
- Environment: The stage in the imaging pipeline where real-world conditions (e.g., darkness, turbulence) introduce degradations. "Environment (Darkness, Atmospheric Turbulence, Noise, Color Diffusion)"
- Graffiti: Visible marks or overlays that act as postprocessing damage, occluding or distorting content. "Postprocessing (Sharpness Change, Graffiti, Watermark Damage)"
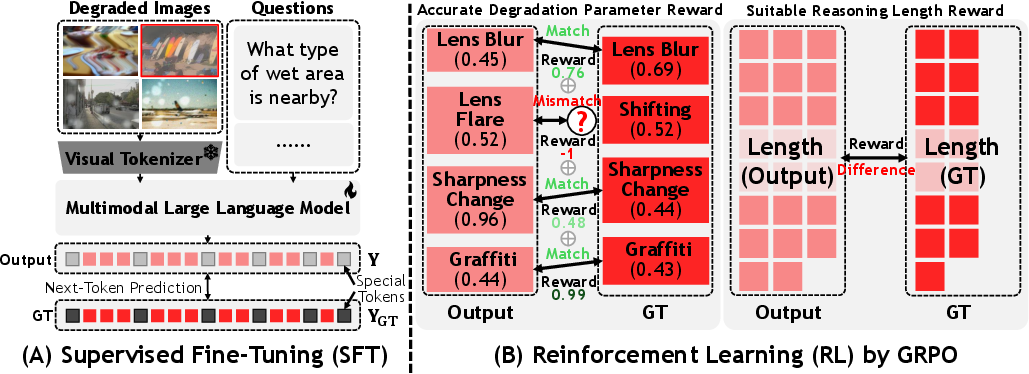
- Group Relative Preference Optimization (GRPO): A reinforcement learning method that optimizes outputs based on group-relative rewards. "This composite reward drives Group Relative Preference Optimization (GRPO)~\cite{shao2024deepseekmath}"
- Kronecker delta function: A function that is 1 when two indices are equal and 0 otherwise, used to score matches in discrete parameters. "where denotes the Kronecker delta function~\cite{web_reference}."
- Lens Blur: Defocus-related blur introduced during acquisition due to lens or focus limitations. "Acquisition (Lens Blur, Lens Flare, Motion Blur, Dirty Lens, Saturation)"
- Lens Flare: Light artifacts caused by bright sources entering the lens, producing streaks or haze. "Acquisition (Lens Blur, Lens Flare, Motion Blur, Dirty Lens, Saturation)"
- Length-modulation reward: A reward term that encourages generating reasoning chains of suitable length for a given degradation. "we introduce a length-modulation reward (Figure~\ref{method}-B (right)):"
- Motion Blur: Blur resulting from camera or object motion during exposure. "Acquisition (Lens Blur, Lens Flare, Motion Blur, Dirty Lens, Saturation)"
- Multimodal combination operator: The operator used to combine visual and textual inputs within an MLLM. " indicates the multimodal combination operator."
- Multimodal LLMs (MLLMs): LLMs that can process and reason over multiple modalities, such as text and images. "Multimodal LLMs (MLLMs) have demonstrated remarkable capabilities in visual understanding tasks"
- Noise: Random signal variations that corrupt image data, reducing clarity and accuracy. "Environment (Darkness, Atmospheric Turbulence, Noise, Color Diffusion)"
- Postprocessing: The stage of image editing after capture that may introduce further artifacts. "Postprocessing (Sharpness Change, Graffiti, Watermark Damage)"
- R-Bench: A benchmark designed to evaluate visual understanding under real-world degradations. "On the real-world degradation benchmark R-Bench~\cite{li2024rbench}"
- Reinforcement Learning (RL): A learning paradigm where models optimize behavior based on rewards to improve performance. "Reinforcement Learning (RL): we propose two reward functions to (i) align precise degradation-aware space while (ii) adaptively scaling to suitable reasoning lengths based on degradation intensity."
- Saturation: The intensity of color; changes can cause unnatural visuals and loss of detail. "Acquisition (Lens Blur, Lens Flare, Motion Blur, Dirty Lens, Saturation)"
- Scan Lines: Horizontal line artifacts typically associated with scanning or transmission processes. "Transmission (Compression, Block Change, Shifting, Scan Lines)"
- Seed-1.5-VL: A vision-LLM variant used for analyzing reasoning length versus degradation. "Correlation between degradation intensity and reasoning chain length on Seed-1.5-VL~\cite{guo2025seed1}."
- Sharpness Change: Modifications to image sharpness that can introduce halos or artifacts. "Postprocessing (Sharpness Change, Graffiti, Watermark Damage)"
- Shifting: Spatial displacement artifact during transmission, misaligning image content. "Transmission (Compression, Block Change, Shifting, Scan Lines)"
- State-of-the-art (SOTA): The best performance or method currently known in the field. "\ achieves state-of-the-art (SOTA) performance across all degradation intensities (low, medium, and high)"
- Supervised Fine-Tuning (SFT): Adapting a pretrained model using labeled data to establish task-specific capabilities. "Supervised Fine-Tuning (SFT): we train the model using reasoning data to equip it with basic degradation-aware reasoning capability"
- Transmission: The stage where images are transported or encoded, potentially introducing compression and artifacts. "Transmission (Compression, Block Change, Shifting, Scan Lines)"
- Visual CoT: A visual chain-of-thought approach that structures reasoning over image content. "frameworks like Visual CoT~\cite{shao2024visual}"
- Visual encoder: The component that extracts feature representations from images in a multimodal model. "(A) is based on implicit training/adaptation, which only considers the visual encoder feature alignment."
- Vision Transformer (ViT): A transformer-based architecture adapted for image understanding. "which employs a redesigned Vision Transformer (ViT) as its vision encoder."
- Visual Question Answering (VQA): A task where models answer questions based on image content. "It incorporates three distinct task types (Multiple Choice Questions (MCQ), Visual Question Answering (VQA), and Image Captioning (CAP))"
- Watermark Damage: Degradation caused by overlayed watermarks or attempts to remove them. "Postprocessing (Sharpness Change, Graffiti, Watermark Damage)"
Collections
Sign up for free to add this paper to one or more collections.