- The paper introduces explicit geometric priors that enforce orientation, alignment, and scale constraints to recover scene-consistent Gaussian representations from sparse views.
- It demonstrates backbone-agnostic performance, achieving state-of-the-art results in novel-view synthesis, depth rendering, and relative pose estimation across diverse datasets.
- Quantitative and qualitative evaluations reveal superior mesh reconstruction, reduced artefacts, and enhanced generalizability compared to previous Gaussian splatting approaches.
Geometrically Consistent Generalizable Gaussian Splatting: An Expert Analysis of G3Splat
Introduction and Motivation
G3Splat introduces a paradigm shift in generalizable 3D Gaussian splatting by explicitly enforcing geometric priors to recover scene-consistent Gaussian representations from sparse, unposed multi-view inputs. Most preceding approaches adapt multi-view geometry backbones to regress per-pixel 3D Gaussians, but rely almost entirely on photometric view-synthesis loss. This typically sidesteps the geometric ambiguities and overparameterization inherent in 3D splat representations, resulting in degenerate orientation, scale, and opacity predictions. The lack of strong geometric constraints limits the reliability of such splats for structure recovery and undermines any downstream tasks requiring scene-consistent geometry.
G3Splat exposes these intrinsic ambiguities and systematically formulates geometric regularizers that enforce both orientation alignment with local surface normals and pixel-grid consistency of Gaussian means. The method is designed to be backbone-agnostic, demonstrating strong performance across both DUSt3R and VGGT architectures. Its robust generalization is substantiated through state-of-the-art results in novel-view synthesis, geometry recovery, and relative pose estimation—even on unseen datasets like ScanNet and ACID.
Problem Characterization and Proposed Solution
The technical bottleneck addressed by G3Splat is twofold: overparameterization of Gaussian splats and inadequate photometric supervision. Unlike depth maps or point clouds (where per-pixel predictions enjoy unique geometric correspondence), a set of Gaussians with arbitrary orientations and covariances can yield plausible renderings but lack scene-grounded geometry. This ill-posed recovery results in misaligned normals and nonphysical scales, as demonstrated by the comparative visualizations of baseline methods.
G3Splat resolves these issues via three key regularizers:
- Orientation Prior ($\mathcal{L}_{\text{orient}$): Aligns each Gaussian's principal axis (normal) with finite-difference surface normals computed directly from local 3D Gaussian means. This direct supervision is agnostic to rasterization artifacts and yields stable training.
- Pixel-Grid Alignment ($\mathcal{L}_{\text{align}$): Penalizes deviations of each Gaussian center from its corresponding pixel's viewing ray, enforcing direct geometric consistency in the canonical image frame.
- Scale Anisotropy Bias ($\mathcal{L}_{\text{flat}$): For 3DGS, discourages near-isotropic covariances, promoting splats that preferentially capture planar or surfel-like structures.
These regularizers are incorporated into the downstream view-synthesis objective, yielding a joint loss:
$\mathcal{L}_{\text{total} = \mathcal{L}_{\text{synthesis} + \lambda_{o} \mathcal{L}_{\text{orient} + \lambda_{a} \mathcal{L}_{\text{align}.$
Qualitative and Quantitative Evaluations
Qualitative Analysis of Gaussian Prediction
G3Splat demonstrates markedly improved geometric veracity over previous generalizable splatting frameworks. Visual analyses reveal that the orientations and scales predicted by G3Splat remain near-Manhattan structured on planar surfaces, only becoming skewed in regions with strong geometric discontinuities or edges (Figure 1).

Figure 1: Qualitative comparison of predicted Gaussian parameters, highlighting the geometric consistency and near-circular eigen-scales on planar regions produced by G3Splat.
Novel-View Depth and Surface Rendering
When evaluated on novel-view synthesis tasks across RE10K, ACID, and ScanNet, G3Splat renders depth maps with sharply delineated structures and minimal texture-driven artefacts (Figure 2). Competing baselines (pixelSplat, MVSplat, NoPoSplat) often hallucinate surface boundaries or exhibit noise in textureless regions, whereas G3Splat's priors ensure physically plausible spatial layouts.























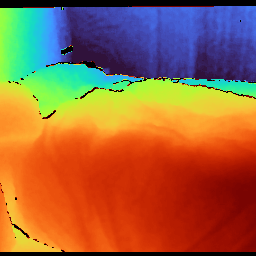
Figure 2: Qualitative comparison of rendered novel-view depth, demonstrating sharp and geometrically plausible interpolation across datasets.
Geometric Mesh Reconstruction
By fusing virtual rendered depths using TSDF-Fusion, G3Splat produces complete and accurate mesh reconstructions, with superior accuracy, completeness, and Chamfer distance relative to baselines. The benefits of integrating geometric priors are evident across architectures, as both DUSt3R and VGGT variants with priors outperform their prior-free counterparts (Figure 3).

Figure 3: Qualitative ablation of reconstructed meshes, showing reduced noise and sharper planar regions through G3Splat’s geometric regularization.
Sora-Generated Video Generalization
G3Splat's robustness extends to generative video data (e.g., Sora-generated sequences), where reconstructed splats maintain alignment under large baseline variations and produce spatially coherent scene layouts (Figure 4).

Figure 4: Qualitative mesh results on Sora-generated orbital camera video, demonstrating consistent alignment under extreme view diversity.
Ablations and Loss Impact
Systematic ablation studies confirm the synergy of orientation and alignment priors. Using only $\mathcal{L}_{\text{align}$ yields correct pixel correspondence but does not resolve ambiguous splat orientation; conversely, adding $\mathcal{L}_{\text{orient}$ corrects normal alignment and enables robust depth rendering (Figure 5).
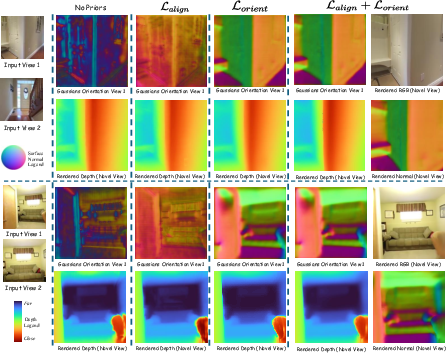
Figure 5: Ablation visualizations illustrating the critical role of orientation prior alongside pixel alignment in achieving consistent novel-view geometry.
Numerical Results: Depth, Pose, and Novel-View Synthesis
Relative Pose Estimation
G3Splat sets new standards for zero-shot relative pose estimation (PnP + RANSAC) across in-domain (RE10K) and cross-domain settings (ScanNet, ACID). When compared against pose-supervised architectures (RoMa, DUSt3R, MASt3R) and prior pose-free splatting methods (NoPoSplat, SelfSplat), G3Splat achieves higher AUC scores at all error thresholds, despite relying on self-supervised training and content-sparse source data.
Depth Estimation
In both source- and novel-view depth estimation on ScanNet, G3Splat delivers the lowest absolute relative errors and highest accuracy at δ1<1.10 and δ1<1.25 thresholds. Notably, pose-free methods with geometric priors surpass even pose-required baselines in cross-domain generalization.
Mesh Completeness and Accuracy
Mesh evaluation on ScanNet confirms superior structural fidelity when using G3Splat, with lower Chamfer distance and increased completeness/accuracy. Priors consistently enhance mesh quality for both DUSt3R and VGGT backbones.
Backbone Agnosticism and Scalability
G3Splat demonstrates that its priors are architecture-agnostic. Adaptation to VGGT, a generalist geometry transformer, leads to further gains in reconstruction quality and relative pose estimation, especially in multi-view settings. Misalignment issues in vanilla VGGT adaptation (without priors) grow with view diversity; in contrast, prior-assisted models maintain spatial coherence even with >20 unposed views.
Failure Modes and Prior Comparison
Rendered normal–depth consistency (2DGS regularizer) lacks stability and geometric precision when deployed without explicit orientation supervision, resulting in degenerate reconstructions (Figure 6). G3Splat's priors avoid such minima, effecting improvement in geometric alignment even with large unposed input sets.
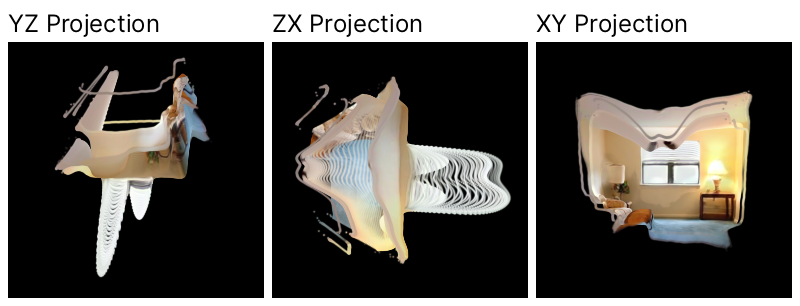

Figure 6: Failure visualization for rendered normal–depth consistency; degeneracy is precluded by G3Splat’s direct orientation prior.
Implications and Future Directions
G3Splat establishes that self-supervised, generalizable splatting is viable for reliable structure and pose estimation from sparse, unposed multi-view imagery. The explicit geometric priors proposed here robustly resolve the ambiguity and overparameterization issues that have previously plagued generalizable Gaussian scene recovery.
The framework’s backbone independence enables broad applicability to any transformer-based geometry predictor. This opens avenues for integration into SLAM, AR/VR, robotics, and NeRF-aligned pipelines, especially where pose information is unavailable or unreliable. G3Splat’s approach to 3D scene recovery without pose or dense supervision should influence future AI systems aiming for scalable geometry estimation in unknown environments, and informs design of differentiable scene representations targeting both generative and predictive tasks.
Conclusion
G3Splat delivers a rigorous solution to pose-free, generalizable Gaussian splatting, enforcing geometrically grounded priors that elevate the reliability of feedforward 3D scene recovery. It sets new performance benchmarks for both photometric view synthesis and geometric structure estimation, substantiates the necessity of direct orientation and alignment regularization, and demonstrates stability and backbone-zeroed generalization. Future research on neural 3D reconstruction should leverage explicit geometric priors for faithful scene abstraction, whether targeting downstream geometry-based analytics or novel-view synthesis applications (2512.17547).