- The paper's primary contribution is the development of AniX, a conditional autoregressive video generation framework that synthesizes temporally coherent videos in explorable 3D worlds using user-specified characters and natural language commands.
- It employs a Transformer-based architecture with multi-modal token encoding and Flow Matching diffusion training to achieve high character consistency and support a diverse set of open-ended actions.
- Using GTA-V and real-world datasets, AniX demonstrates state-of-the-art performance with significant inference acceleration (7.5× speedup), enabling realistic and interactive world exploration.
AniX: Conditional Autoregressive Video Generation for Interactive World Exploration
Introduction and Motivation
AniX introduces a conditional autoregressive video generation framework designed to synthesize temporally coherent videos in explorable 3D Gaussian Splatting (3DGS) worlds, given arbitrary user-specified 3D or multi-view characters and natural language commands. Existing paradigms predominantly fall into static world generators—with no agent interactions—or controllable-entity models limiting agents to restricted, predefined actions within uncontrollable backgrounds. AniX unifies these directions: it preserves the realistic spatial and appearance consistency of world models while expanding action repertoire and subject customization, supporting both locomotion and nuanced, open-ended behaviors.
Key capabilities of AniX include consistent environment-character fidelity, diverse action repertoire (hundreds of gestures and interactions), long-horizon temporal coherence, and geometrically-grounded camera control.
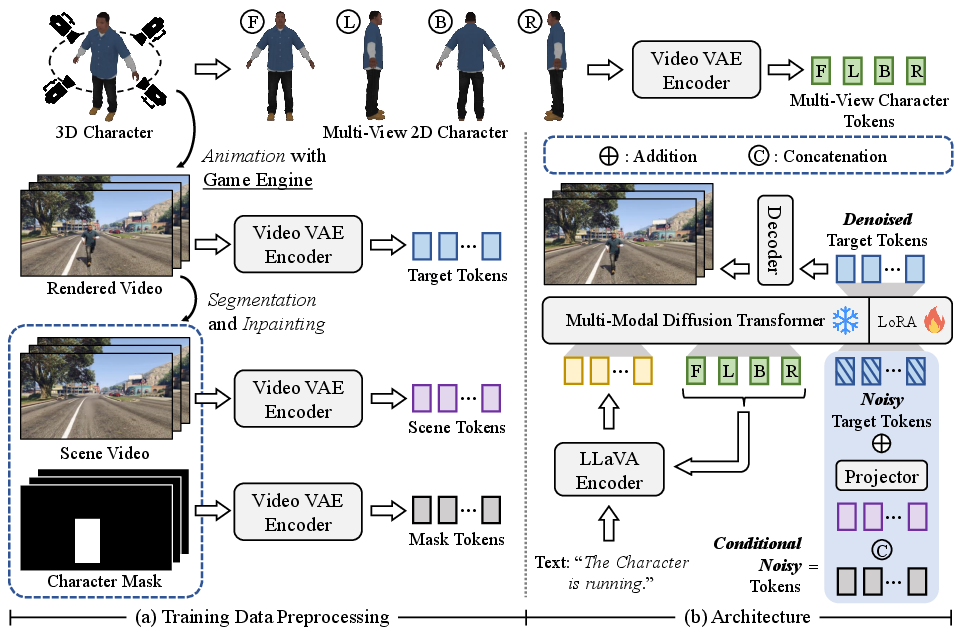
Figure 1: AniX workflow: training data linking a 3D character, segmented/inpainted scene video, character mask sequence, and text action is encoded; a Multi-Modal Diffusion Transformer predicts video tokens via Flow Matching.
Model Architecture and Training
AniX operates as a conditional autoregressive video generator centered on a full-attention Transformer backbone. At each iteration, it synthesizes video clips conditioned on multi-modal signals: previous video history, segmented scene video (encoding geometric anchoring), character representation (multi-view images), action text, and masks identifying dynamic agents.
Training uses GTA-V gameplay sequences segmented per-action. Each clip is processed via segmentation (Grounded-SAM-2), inpainting (DiffuEraser), annotation, and character rendering from four canonical views. All modalities are encoded into tokens via a video VAE (from HunyuanCustom) and LLaVA-based multi-modal encoder.
The model leverages Flow Matching for diffusion training, minimizing the MSE between predicted and ground-truth velocity in the latent token space. Conditional fusion uses projected scene and mask tokens added to noisy targets, concatenated with character- and text-based tokens for Transformer input.
Positional encoding employs 3D-RoPE and shifted-3D-RoPE for multi-view character tokens, preserving geometric correspondence to viewpoints.
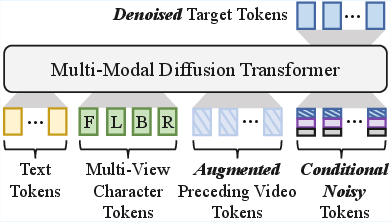
Figure 2: Auto-regressive training: preceding video tokens (ground truth) are integrated into the conditioning stack; Gaussian noise augmentation reduces train-infer mismatch.
Inference Workflow and Acceleration
Inference proceeds via three stages: (1) user configuration of character, 3DGS world, camera, and anchor; (2) text-driven parsing of action/camera behaviors, mapping to rendered camera trajectories; and (3) encoding all conditions (including optional previous clips) for iterative generation. This enables agent-centric exploration and temporally consistent long-horizon interactions.
Inference is accelerated by DMD2 distillation, reducing the default 30-step denoising schedule to 4 steps, achieving 7.5× speedup with negligible visual degradation.

Figure 3: AniX inference: user input (character, world, camera, anchor), text-driven trajectory rendering, and conditional generation can iterate for long-run coherence.
Experimental Evaluation
AniX is evaluated using the WorldScore (Duan et al., 1 Apr 2025), reporting across controllability (camera/object control, content alignment), visual quality (consistency, photometric/style fidelity), and dynamics (motion accuracy/magnitude/smoothness). The model's fidelity extends to open-ended actions (up to 150+), generalizing beyond training data, and is validated against state-of-the-art foundation models and specialized world-generators (Chen et al., 1 Jun 2025, Li et al., 20 Jun 2025, He et al., 18 Aug 2025).
Key findings include:
- WorldScore Static/Dynamic: AniX achieves 84.64/77.22, consistently outperforming all baselines.
- Action Success Rate: 100.0% for locomotion, 80.7% for gestures/object-centric interactions.
- Character Consistency: DINOv2 0.698, CLIP 0.721, substantially higher than any comparator.
- CLIP Text-Image Score: 0.305 for richer actions, indicating high semantic alignment.
Interpreted through post-training (LoRA-style finetuning), fine-grained control is achieved without compromising wide generative diversity inherent from base pre-training.

Figure 4: Screenshots: AniX generation across varied characters, actions, and worlds—demonstrates scene-character fidelity and behavioral diversity.
Ablations and Qualitative Insights
Multi-view character conditioning improves cross-view appearance consistency (Table: single-front view DINOv2 0.556 → four-view 0.698), and per-frame character anchors enable effective demarcation of dynamic agents (w/o anchor DINOv2 0.477 → per-frame 0.698). Both conditions significantly mitigate long-horizon degradation and preserve high aesthetic quality.
Hybrid training on GTA-V and real-world datasets disentangles stylization and yields higher photorealism (game-only DINOv2 0.686; hybrid 0.755), capturing high-frequency details (e.g., clothing wrinkles).

Figure 5: Hybrid data training boosts photorealism; real-world action clips yield true-to-life dynamics absent from synthetic-only models.
Distillation maintains visual performance within fractional margins while substantially reducing compute latency.

Figure 6: 4-step accelerated denoising matches original visual quality, yielding dramatic inference speedup.
(Figure 7, Figure 8)
Figure 7: Random novel actions—AniX generalizes to 84 unseen behaviors for a unique character.
Figure 8: Diverse actions with text annotation—character performs 25 randomly sampled instructions, preserving semantic and appearance alignment.
(Figure 9, Figure 10, Figure 11)
Figure 9: Scene exploration—flexible character navigation in a range of 3DGS worlds.
Figure 10 & 12: Diverse character locomotions—model generalizes to unseen assets and movement patterns.
Long-horizon generation is enabled via auto-regressive conditioning, allowing extended user-agent interactions with preserved continuity.
(Figure 12, Figure 13)
Figure 12: Long-horizon generation—multi-clip coherence validates auto-regressive memory fidelity.
Figure 13: Another example—iterative action/camera instructions yield consistent video sequences.
Implications and Future Directions
AniX advances interactive agent-centric video generation by:
- Decoupling character control from background constraints, enabling agent insertion in any world geometry.
- Supporting open vocabulary and dense action sets via text prompts, moving beyond rigid control schemas.
- Unifying appearance, spatial, and temporal fidelity across modality boundaries.
- Offering scalable, hardware-efficient inference pipelines (via DMD2).
Practically, AniX can underpin next-generation synthetic video environments: from simulation platforms for robotics/embodied AI, to scalable content creation and virtual world design. Theoretically, its modular autogressive setup informs approaches in world modeling, memory-augmented generative networks, and multimodal diffusion transformers.
Extensions could incorporate fine-grained physics simulation, entity collaboration, real-time reinforcement learning environments, and transfer to robotics simulation-to-real domains. Incorporating richer scene/agent annotations can promote semantic manipulation and environment editing. Memory architectures for even longer-horizon generation, and dynamic conditioning modalities, will further expand applicability.
Conclusion
AniX demonstrates a cohesive framework for user-customized character control and interactive world exploration, significantly improving motion dynamics, action controllability, character consistency, and generation quality over existing video models. Its memory-augmented, autoregressive design, combined with efficient inference and hybrid data strategies, establishes a strong foundation for agent-centric, open-ended video synthesis research and real-world applications.
(2512.17796)