Adversarial Robustness of Vision in Open Foundation Models
Abstract: With the increase in deep learning, it becomes increasingly difficult to understand the model in which AI systems can identify objects. Thus, an adversary could aim to modify an image by adding unseen elements, which will confuse the AI in its recognition of an entity. This paper thus investigates the adversarial robustness of LLaVA-1.5-13B and Meta's Llama 3.2 Vision-8B-2. These are tested for untargeted PGD (Projected Gradient Descent) against the visual input modality, and empirically evaluated on the Visual Question Answering (VQA) v2 dataset subset. The results of these adversarial attacks are then quantified using the standard VQA accuracy metric. This evaluation is then compared with the accuracy degradation (accuracy drop) of LLaVA and Llama 3.2 Vision. A key finding is that Llama 3.2 Vision, despite a lower baseline accuracy in this setup, exhibited a smaller drop in performance under attack compared to LLaVA, particularly at higher perturbation levels. Overall, the findings confirm that the vision modality represents a viable attack vector for degrading the performance of contemporary open-weight VLMs, including Meta's Llama 3.2 Vision. Furthermore, they highlight that adversarial robustness does not necessarily correlate directly with standard benchmark performance and may be influenced by underlying architectural and training factors.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at how easy it is to trick two popular AI models that can understand both pictures and text. These models are used to answer questions about images. The researchers tested how small, sneaky changes to images can make the models give wrong answers, and measured how much their performance drops when attacked.
Key Objectives and Questions
The paper sets out to answer simple but important questions:
- Can tiny, almost invisible changes to a picture confuse vision-LLMs?
- Which model holds up better under attack: LLaVA-1.5-13B or Llama 3.2 Vision-8B-2?
- Does doing well on normal tests also mean being strong against attacks?
Methods and Approach
To test the models, the researchers used:
- A dataset called VQA v2 (Visual Question Answering). It has lots of pictures paired with questions like “What color is the bus?” The model must look at the image and answer correctly.
- An attack method called Projected Gradient Descent (PGD). Think of PGD like a careful, repeated “nudge” to the pixels in an image:
- The attacker makes tiny changes to the image that are hard to see with the naked eye.
- After each small change, they check if the model gets more confused.
- They keep nudging but never go beyond a preset limit, like staying inside a safe “bubble” of how much the picture can be changed.
- The attack was “untargeted,” which means the goal wasn’t to force a specific wrong answer. Instead, any wrong answer counted as a success for the attacker.
- The researchers measured accuracy using the standard VQA score before and after the attacks, then compared how much each model’s accuracy dropped.
Main Findings and Why They Matter
The results showed:
- Both models can be fooled by tiny image changes. Their accuracy goes down when attacked.
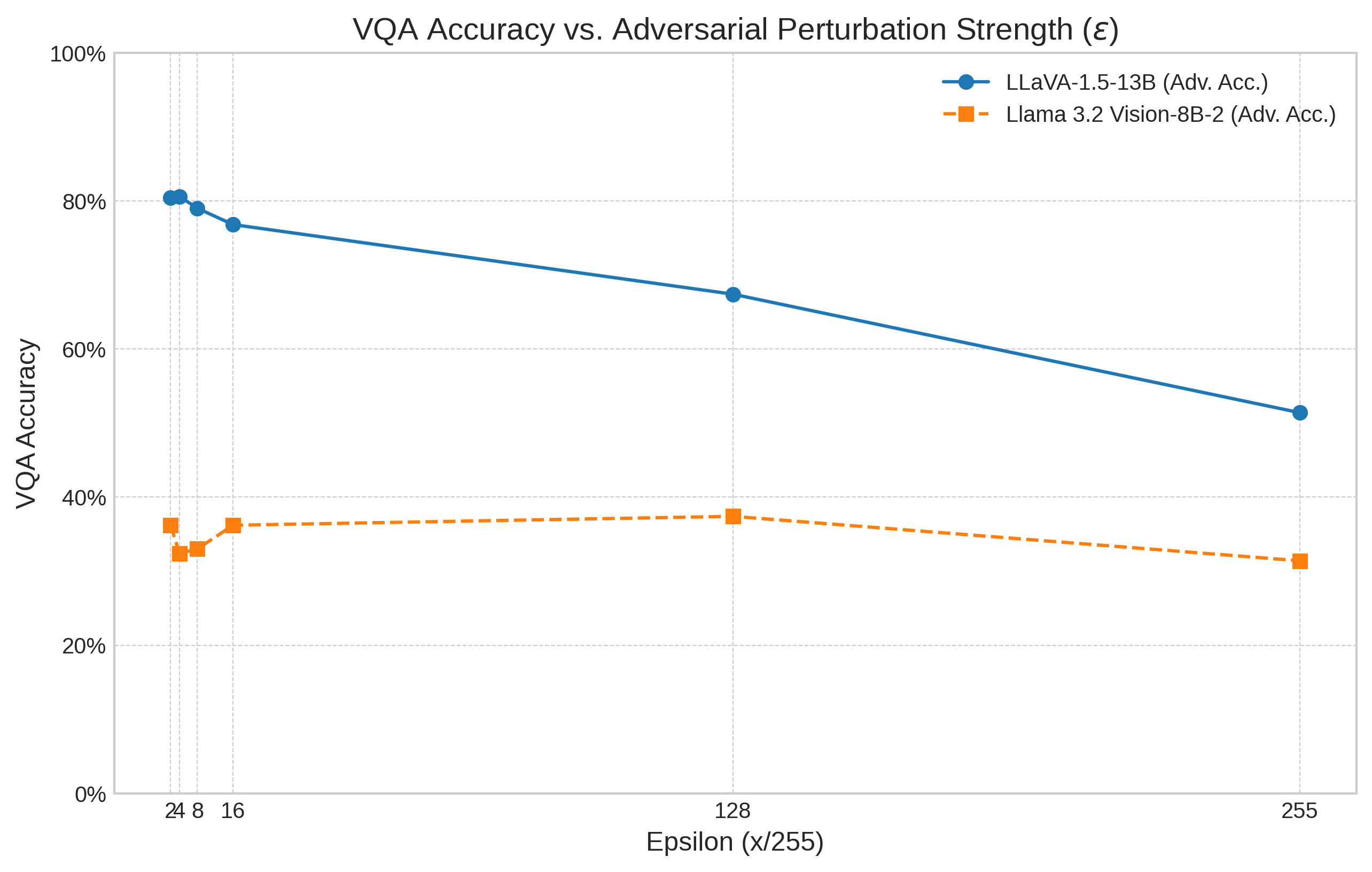
- Llama 3.2 Vision had a lower starting accuracy in this setup, but it didn’t lose as much performance under stronger attacks compared to LLaVA. In other words, it was more “robust” to the attacks at higher levels of image changes.
- The vision part of these models is a real weakness that attackers can use to make the models perform poorly.
- Being good on standard benchmarks does not automatically mean a model is strong against adversarial attacks. Robustness can depend on how the model is built and trained, not just how accurate it is on clean test images.
This matters because vision-LLMs are used in many real-world tools (like assistive apps, content moderators, and creative tools). If they can be tricked by tiny changes to images, they might give unsafe or unreliable answers in practice.
Implications and Potential Impact
- Security testing for AI should include the visual side, not just the text side. Tiny image tweaks can cause big problems.
- Model builders should use defenses that improve robustness (for example, adversarial training, smarter input checks, or attack detection methods).
- Evaluations should include robustness metrics, not only accuracy on clean data.
- Design and training choices matter: how the vision and language parts are connected and trained can make a model more or less resistant to attacks.
- Open-weight models (whose internals are publicly available) are great for research and innovation, but their transparency can also make it easier for attackers to craft effective image-based tricks—so they especially need strong defenses.
In short, the paper shows that small visual changes can significantly affect how these models behave, and it encourages developers and users to put more effort into making them safer and more reliable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Based on the paper’s scope and methodology, the following concrete gaps remain unresolved and can guide future research:
- Threat model clarity: Precisely specify what gradients and components the attacker can access (full VLM vs. vision encoder only), whether text inputs/prompts are known/controllable, and whether decoding is deterministic or stochastic during attacks.
- Attack diversity: Evaluate robustness beyond untargeted PGD by including targeted PGD, CW, AutoAttack, Square, SPSA/NES, and transfer attacks to rule out attack-specific artifacts.
- Norms and perceptual constraints: Systematically compare , , and budgets and incorporate perceptual metrics (LPIPS, SSIM) and human studies to ensure perturbations are truly imperceptible at reported budgets.
- Hyperparameter sensitivity: Report and sweep PGD step size, iterations, restarts, and random starts; quantify how conclusions change across attack configurations.
- Robustness curves: Provide robust accuracy vs. epsilon curves (and area-under-curve) rather than point estimates to enable fair cross-model comparison.
- Evaluation metrics: Complement VQA accuracy with attack success rate (ASR), confidence calibration under attack (ECE/Brier), logit margins, and hallucination/error typology.
- Dataset scope: Move beyond a VQAv2 subset to full VQAv2 and additional benchmarks (GQA, TextVQA, OK-VQA, VizWiz, ScienceQA) to test compositional reasoning, OCR, and OOD robustness.
- Task coverage: Assess vision-only captioning, image classification, OCR-heavy tasks, multi-turn dialogue, and multi-image reasoning to test modality interactions under attack.
- Per-question robustness: Break down VQA degradation by question type (yes/no, counting, attribute, spatial, commonsense) to identify failure modes.
- Prompt/template effects: Quantify robustness across different instruction templates, few-shot exemplars, chain-of-thought prompts, and decoding settings (temperature, nucleus sampling).
- Combined multimodal attacks: Study joint visual+textual adversarial inputs and their composition (e.g., benign text + adversarial image, or vice versa) to reflect realistic adversaries.
- Transferability: Test cross-model transfer (attack crafted on model A, evaluated on B) and cross-architecture transfer to estimate real-world black-box risk.
- Physical-world robustness: Evaluate adversarial patches, print–scan, display–camera pipelines, and EOT-based attacks for physically realizable threats.
- Safety/jailbreak under visual attack: Measure whether visual perturbations bypass safety alignment (ASR on jailbreak prompts, toxicity, disallowed content) for both models.
- Architectural attribution: Conduct controlled ablations (projection vs. cross-attention adapters; ViT-L/14 vs ViT-H/14; number/placement of cross-attention layers) to isolate which design choices drive robustness differences.
- Training pipeline factors: Test the impact of pretraining data volume/quality, adapter annealing, and post-training (SFT, DPO, safety tuning) on robustness via controlled training interventions.
- Model scale effects: Compare multiple parameter scales within each family (e.g., 7B/13B/34B) to establish robustness–scaling laws and disentangle scale from architecture.
- Vision tokenization and resolution: Study the effect of input resolution, patch size, visual token count, and cropping strategies on attack success and robustness.
- Stochasticity and sanity checks: Run iterative vs. single-step comparisons, white-box vs. black-box gaps, and gradient-free attacks to rule out gradient masking/obfuscation.
- Certified robustness: Explore certification methods (randomized smoothing, interval bound propagation) for the vision pathway to provide worst-case guarantees.
- Defenses and trade-offs: Benchmark preprocessing (JPEG, denoising), feature denoising, adversarial training (single-/multi-norm), robust contrastive pretraining, and detection methods; quantify accuracy–robustness trade-offs and inference cost.
- Error analysis: Provide qualitative and quantitative analyses of failure cases under attack (e.g., object misbinding, counting errors, OCR slips) to guide targeted defenses.
- Generalization and OOD: Test robustness under distribution shifts (ImageNet-C/S, synthetic renders, domain-specific images) to estimate out-of-distribution vulnerability.
- Reproducibility details: Release code, seeds, exact evaluation scripts (answer normalization, string matching), and decode settings to ensure repeatability and fair comparison across studies.
Practical Applications
Immediate Applications
Below are actionable uses that can be deployed today based on the paper’s findings (PGD-based adversarial testing on VQA, comparative robustness of LLaVA vs Llama 3.2 Vision, and the documented visual attack surface of VLMs).
- Application: Multimodal red‑teaming harness for vision inputs
- Sectors: Software/Cloud (MLOps), Security, AI product teams, Academia
- What/Value: Integrate untargeted PGD attacks against the visual modality of open-weight VLMs (e.g., LLaVA-1.5-13B, Llama 3.2 Vision-8B-2) into continuous evaluation to quantify accuracy drop under perturbations at multiple ε levels.
- Tools/Workflows: Torchattacks/Foolbox/AutoAttack; evaluation harnesses for VQAv2-style tasks; accuracy-drop dashboards; CI/CD gates that fail builds when robustness falls below thresholds.
- Assumptions/Dependencies: White-box gradients or strong transfer/score-based approximations; GPU capacity; dataset alignment with your domain; acceptance of VQAv2-like metrics as proxies for your tasks.
- Application: Model selection with robustness-aware criteria
- Sectors: Software, Robotics, Healthcare, Finance, Education
- What/Value: Use “accuracy drop under attack” as a selection metric in addition to baseline accuracy; prefer models showing smaller robustness degradation (e.g., Llama 3.2 Vision in this study) for safety-critical use cases, even if baseline accuracy is lower.
- Tools/Workflows: Model scorecards including baseline accuracy and adversarial accuracy at ε ∈ {1/255, 2/255, …}; procurement templates requiring robustness KPIs.
- Assumptions/Dependencies: Results are task- and dataset-dependent; trade-offs between top-line accuracy and robustness must be explicitly accepted.
- Application: Threat modeling and risk assessment for multimodal systems
- Sectors: Policy/Compliance, Security, Product Risk, Industry consortia
- What/Value: Incorporate visual adversarial vectors (L∞-bounded perturbations, cross-modal jailbreaks) into formal threat models, referencing NIST’s AML taxonomy and best practices (e.g., avoiding gradient masking).
- Tools/Workflows: Security reviews, STRIDE-style MM threat models, red-team playbooks covering visual inputs, incident response runbooks.
- Assumptions/Dependencies: Organizational security maturity; access to model internals varies across vendors.
- Application: Input sanitization policies for images
- Sectors: Social media/content moderation, GenAI platforms, Enterprise IT
- What/Value: Apply image pre-processing (JPEG recompress, resizing, bit-depth reduction, light denoising) before passing images to VLMs to reduce some adversarial high-frequency perturbations.
- Tools/Workflows: Pre-ingress media pipelines; configurable image transforms; A/B testing to calibrate utility vs. robustness trade-offs.
- Assumptions/Dependencies: Adaptive attackers can overcome simple transforms; may degrade vision task performance; not a substitute for robust models.
- Application: Adversarial image anomaly detection
- Sectors: Security, Cloud inference providers, Content platforms
- What/Value: Deploy detectors that flag suspicious frequency spectra or gradient-based sensitivity spikes indicative of adversarial manipulation before inference.
- Tools/Workflows: Frequency-domain feature monitors; randomization tests; input-consistency checks (small random noise shouldn’t cause large output shifts); quarantine/escalation workflows.
- Assumptions/Dependencies: False positives/negatives; detectors can be evaded; must be paired with defense-in-depth.
- Application: Domain-specific evaluation suites for robustness
- Sectors: Academia, Enterprise AI teams (healthcare imaging QA, KYC document VQA, industrial inspection)
- What/Value: Curate VQA-like subsets in the target domain and quantify adversarial accuracy drop; publish internal “robustness leaderboards.”
- Tools/Workflows: Data collection pipelines; reproducible attack configs (ε, steps, step size); reporting templates aligned with the paper’s VQA accuracy metric.
- Assumptions/Dependencies: Data governance; privacy/PII constraints; annotation quality.
- Application: Safety gating in multimodal assistants
- Sectors: Consumer apps, Enterprise copilots, Accessibility/assistive tech
- What/Value: Trigger human-in-the-loop or fallback pathways when small, randomized perturbations to an input image cause large output variation, signaling fragility.
- Tools/Workflows: Stability probes (multi-sample inference on perturbed inputs), uncertainty thresholds, human escalation UIs.
- Assumptions/Dependencies: Latency budget; increased inference cost; requires policy definitions for escalation.
- Application: KYC/Document-understanding hardening
- Sectors: Finance/Fintech, eID/KYC vendors, Government services
- What/Value: Evaluate and harden VLM-based document understanding against adversarially perturbed scans/photos to prevent bypass or misclassification.
- Tools/Workflows: Robustness tests at multiple ε; combined OCR+VLM pipelines; pre-processing and detection as guardrails; vendor SLAs including robustness metrics.
- Assumptions/Dependencies: Real-world capture conditions vary; physical-world attacks may differ from digital L∞ constraints.
- Application: Content moderation under adversarial images
- Sectors: Social media, Messaging, Marketplaces
- What/Value: Test and improve moderation VLMs for adversarially perturbed images that could evade toxicity/safety filters or jailbreak text generation via images.
- Tools/Workflows: Adversarial image corpora; attack success rate (ASR) tracking; safety filters tuned for multimodal inputs; multi-stage review pipelines.
- Assumptions/Dependencies: Evolving attacker strategies; trade-offs between recall and precision.
- Application: Robotics and autonomy risk checks
- Sectors: Robotics, Drones, Smart cameras
- What/Value: Evaluate vision-language components in planning/control stacks for robustness to image perturbations; restrict model capabilities or add cross-sensor validation where brittleness is detected.
- Tools/Workflows: Simulation with adversarial frames; redundancy (LIDAR/RADAR) cross-checks; safe fallback behaviors.
- Assumptions/Dependencies: Closed-loop safety analyses; domain-specific sensors may mitigate but not eliminate risk.
- Application: Robustness reporting in model cards
- Sectors: AI vendors, Model marketplaces, Open-source communities
- What/Value: Add “accuracy drop under PGD” curves to model cards and datasheets; disclose ε budgets, attack settings, and task metrics.
- Tools/Workflows: Standardized reporting templates; automated benchmarking scripts; governance review.
- Assumptions/Dependencies: Community agreement on metrics; reproducibility of attacks.
- Application: Team training on multimodal attack surface
- Sectors: Industry, Academia
- What/Value: Update security/ML curricula to include visual adversarial attacks, cross-modal jailbreaks, and evaluation pitfalls (e.g., gradient masking).
- Tools/Workflows: Labs replicating the paper’s PGD evaluations on LLaVA/Llama 3.2 Vision; case studies (Image Hijacks, compositional attacks).
- Assumptions/Dependencies: Access to GPUs and open-weight models; institutional buy-in.
Long-Term Applications
The following applications will benefit from further research, scaling, or development before broad deployment.
- Application: Adversarial training for VLMs at scale
- Sectors: Software, Research labs, Model vendors
- What/Value: Incorporate strong, iterative image attacks (PGD) into pretraining/fine-tuning loops for VLMs to improve robustness with minimal accuracy loss.
- Tools/Workflows: Curriculum adversarial training; mixed clean+adversarial batches; robust optimization; adaptive attack suites during training.
- Assumptions/Dependencies: Significant compute; stability of training; transfer to physical-world robustness.
- Application: Architecture-level robustness by design
- Sectors: Foundation model developers
- What/Value: Explore architectural choices (e.g., cross-attention adapters vs projection layers; vision encoder size; adapter placement) that correlate with lower robustness degradation, as suggested by the paper’s comparative findings.
- Tools/Workflows: Ablation studies; robustness-accuracy Pareto analysis; automated architecture search with robustness objectives.
- Assumptions/Dependencies: Causality vs correlation must be established; results may differ across tasks/datasets.
- Application: Certified robustness benchmarks for multimodal models
- Sectors: Standards bodies, Academia, Industry consortia
- What/Value: Establish standardized multimodal robustness suites (akin to RobustBench) with agreed threat models, metrics, and reporting, spanning classification, captioning, VQA, and dialogue.
- Tools/Workflows: Open datasets, evaluation servers, leaderboards with ε-sweeps and ASR; reproducibility artifacts.
- Assumptions/Dependencies: Community consensus on tasks and perturbation budgets; continuous maintenance against dataset contamination.
- Application: Physical-world adversarial robustness for VLMs
- Sectors: Robotics, Automotive, Public safety, Retail
- What/Value: Extend beyond digital L∞ perturbations to robustify models against printed patches, camera pipelines, and environmental conditions.
- Tools/Workflows: Real-world capture labs; differentiable renderers; domain randomization; physical adversarial training.
- Assumptions/Dependencies: Complex, costly data collection; generalization gaps between simulation and reality.
- Application: Formal verification and certifiable bounds for vision pipelines
- Sectors: Safety-critical industries (medical, aviation, autonomous driving)
- What/Value: Develop certifiable robustness guarantees for vision encoders and multimodal adapters within bounded perturbations and specified domains.
- Tools/Workflows: Interval bound propagation, convex relaxations, verification frameworks extended to multimodal stacks.
- Assumptions/Dependencies: Current methods scale poorly; may require architectural constraints.
- Application: Robust OCR + VLM joint defenses
- Sectors: Finance (documents/KYC), Government services, Enterprise NLP
- What/Value: Co-design OCR and VLM components to resist adversarial images that exploit text-in-image channels (e.g., compositional OCR+visual triggers).
- Tools/Workflows: Joint training; cross-consistency regularization; robust text rendering and detection.
- Assumptions/Dependencies: Coordination of multiple model components; evaluation complexity.
- Application: Hardware and in-sensor defenses
- Sectors: Edge devices, Cameras, Smartphones, IoT
- What/Value: Embed analog/digital pre-processing blocks (e.g., sensor noise shaping, randomized sampling) that reduce exploitable perturbations before they reach the VLM.
- Tools/Workflows: Co-design of ISP pipelines and ML models; secure firmware updates; randomized defenses with provable properties.
- Assumptions/Dependencies: Vendor ecosystem changes; cost/performance trade-offs; adaptive attackers.
- Application: Safety APIs and middleware for multimodal inference
- Sectors: Cloud providers, Model hosting platforms
- What/Value: Offer standardized pre-inference safety services that scan, sanitize, and score image inputs for adversarial risk, with policy hooks for downstream applications.
- Tools/Workflows: Multi-tenant safety layers; rate limits on “risky” inputs; explainable safety scoring.
- Assumptions/Dependencies: Business models; interoperability with diverse models; privacy considerations.
- Application: Robustness labeling and insurance/assurance products
- Sectors: Insurance, Procurement, Compliance
- What/Value: Create risk scores and warranties tied to measured adversarial robustness (accuracy drop curves, ASR), informing premiums and procurement decisions.
- Tools/Workflows: Third-party audits; standardized attestations; continuous monitoring clauses.
- Assumptions/Dependencies: Legal frameworks; method consensus; moral hazard mitigation.
- Application: Regulatory frameworks mandating multimodal robustness testing
- Sectors: Policy/Regulators, Public sector procurement
- What/Value: Require disclosure of robustness metrics under defined perturbation budgets; mandate safety testing for public-facing VLM deployments.
- Tools/Workflows: Compliance checklists aligned with NIST AML; certification programs; audit trails.
- Assumptions/Dependencies: Legislative timelines; alignment across jurisdictions; proportional requirements by risk class.
- Application: Adaptive defense orchestrators
- Sectors: Security, Platform engineering
- What/Value: Systems that dynamically switch defenses (sanitization, detection thresholds, human review) based on live adversarial risk signals and model sensitivity.
- Tools/Workflows: Policy engines; real-time telemetry; feedback loops to training data.
- Assumptions/Dependencies: Operational complexity; risk of overfitting defenses to known attacks.
- Application: Cross-model transfer risk assessment tools
- Sectors: Security research, Platform ops
- What/Value: Score the transferability of adversarial images across deployed VLMs to forecast systemic risk and set isolation policies between tenants/models.
- Tools/Workflows: Attack banks; similarity metrics across model families; sandbox testing.
- Assumptions/Dependencies: Access to multiple model variants; evolving transfer dynamics.
Notes on feasibility across applications
- The paper’s evaluation is on VQA with untargeted PGD in digital settings; physical-world and targeted/jailbreak attacks may behave differently.
- Robustness does not necessarily correlate with top-line accuracy; organizations must explicitly prioritize and measure both.
- Access to model weights (for white-box PGD) may be restricted for closed models; black-box approximations and transfer attacks remain viable but may understate/overstate risk in specific deployments.
- Compute and data requirements for robust training and large-scale evaluation are substantial and may require phased adoption.
Glossary
- Adaptive Adversary Attacks: Attacks tailored to defeat a specific defence by optimizing against it. "Adaptive Adversary Attacks: Testing against optimised attacks specifically designed to overcome the proposed defence, rather than relying solely on standard, pre-existing attacks."
- Adversarial Examples: Inputs intentionally perturbed to cause model errors while appearing normal to humans. "The vulnerability of neural networks to adversarial examples was first systematically demonstrated in the seminal paper 'Intriguing Properties of Neural Networks'."
- Adversarial Image Attacks: Carefully crafted pixel-level perturbations to images that induce incorrect model outputs. "Specifically, VLMs are susceptible to adversarial image attacks – carefully crafted, often imperceptible, perturbations applied to input images that can deceive the model and cause erroneous or unintended textual outputs."
- Adversarial Machine Learning (AML): The field studying attacks against ML systems and corresponding defences. "These discoveries have spurred the growth of Adversarial Machine Learning (AML) as a field dedicated to studying attacks on machine learning systems and developing defences."
- Adversarial Robustness: A model’s ability to maintain performance under adversarially perturbed inputs. "Adversarial robustness refers to a model's ability to maintain performance and security when confronted with inputs specifically crafted to deceive it."
- ALIGN: A large-scale dual-encoder vision-LLM trained with contrastive objectives on noisy web data. "The effectiveness of scale in vision-language learning was further demonstrated by ALIGN \citep{jiaScalingVisualVisionLanguage2021}."
- Attack Success Rate (ASR): The percentage of attempts where an attack achieves its goal. "Using three image generation methods, they found an average increase in Attack Success Rate (ASR), exceeding 30\% in LLaVA-1.5-7B, and that text-only alignment proves insufficient for securing these systems."
- Behaviour Matching: A targeted PGD-based algorithm to make a VLM produce predefined behaviours. "The authors conducted white-box attacks against LLaVA ..., employing their 'Behaviour Matching' algorithm—a targeted approach based on Projected Gradient Descent (PGD)—to generate adversarial images."
- BLIP (Bootstrapping Language-Image Pre-training): An open-source multimodal model combining ViT and BERT encoders with a generative decoder. "BLIP (Bootstrapping Language-Image Pre-training) \citep{liBLIPBootstrappingLanguageImage2022} further advanced open-source vision-language modelling."
- BLIP-2: An open-source model that uses a Q-Former adapter to connect a frozen vision encoder to a frozen LLM. "BLIP-2 \citep{liBLIP2BootstrappingLanguageImage2023} introduced an open-source alternative through its innovative Q-Former architecture."
- Black-box attacks: Attacks where the adversary has no access to the model’s internals. "Black-box attacks, where no internal model details are accessible."
- Carlini–Wagner (CW) attacks: Optimization-based attacks minimizing perturbation while enforcing misclassification. "The author's family of attacks have come to be known as Carlini {paper_content} Wagner (CW) attacks \citep{carliniEvaluatingRobustnessNeural2017} and are designed to be particularly effective against defensive techniques like defensive distillation."
- CLIP (Contrastive Language-Image Pre-training): A dual-encoder model trained to align images and text in a shared embedding space via contrastive objectives. "CLIP (Contrastive Language-Image Pre-training) \citep{radfordLearningTransferableVisual2021} paired a vision transformer with a GPT-based text encoder in a dual-encoder architecture."
- Colluding vs non-colluding (attack mode): Whether multiple agents coordinate during an attack. "The manifestation categorises adversarial attacks by their specificity (targeted vs untargeted), mode (colluding vs non-colluding), and type (poisoning/training time attacks vs evasion/run time attacks)."
- Compositional Adversarial Attacks: Attacks that combine benign text with adversarial images to bypass safety. "The paper Jailbreak in Pieces: Compositional Adversarial Attacks on Multimodal LLMs \citep{shayeganiJailbreakPiecesCompositional2023} introduced 'compositional adversarial attacks' that exploit cross-modal alignment vulnerabilities in Vision-LLMs (VLMS)."
- Contrastive Learning: Training by pulling matched image-text pairs closer and pushing mismatched pairs apart in embedding space. "Building upon the architectural innovations of ViT, contrastive learning emerged as a powerful method for training robust vision-LLMs."
- Contrastive Loss Function: A loss that aligns related image-text pairs while separating unrelated ones. "The training utilised a contrastive loss function, which encouraged the alignment of related image-text pairs while separating unrelated ones."
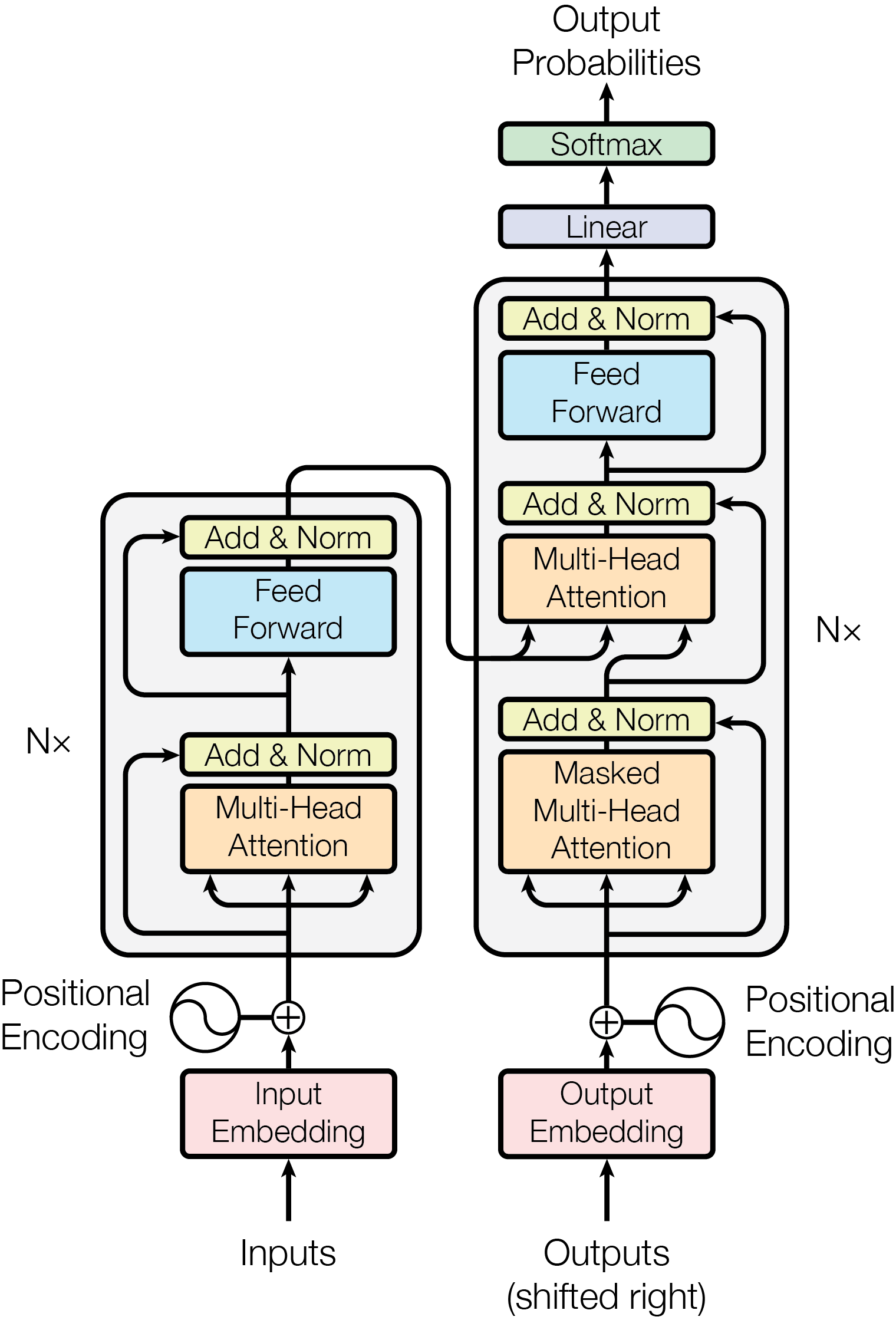
- Cross-attention: Attention mechanism that allows one sequence (e.g., text) to attend to another (e.g., visual features). "The architecture consists of three main components: ... an image adapter with cross-attention layers that integrate visual information into the LLM."
- Cross-Modal Adversarial Attacks: Attacks exploiting interactions between modalities (vision and language). "Cross-Modal Adversarial Attacks"
- Defensive Distillation: A training defence that can mask gradients and is vulnerable to stronger attacks like CW. "Carlini {paper_content} Wagner (CW) attacks ... are designed to be particularly effective against defensive techniques like defensive distillation, which FGSM might fail to overcome."
- Direct Preference Optimisation (DPO): A post-training alignment method optimizing model outputs to match human preferences. "The post-training phase follows a similar recipe to the text-only models, with several rounds of alignment, including supervised fine-tuning, rejection sampling, and direct preference optimisation, along with safety mitigations..."
- Dual-encoder architecture: A design with separate encoders for images and text trained jointly via contrastive objectives. "CLIP ... paired a vision transformer with a GPT-based text encoder in a dual-encoder architecture."
- Encoder–decoder architecture: A neural design where an encoder maps inputs to representations and a decoder generates outputs from them. "The subsequent introduction of the Sequence-to-Sequence (Seq2Seq) framework ... formalised the encoder-decoder architecture for NMT tasks."
- Evasion (run-time) attacks: Attacks applied at inference time to bypass models without tampering with training data. "type (poisoning/training time attacks vs evasion/run time attacks)."
- Fast Gradient Sign Method (FGSM): A single-step gradient-based attack that perturbs inputs in the direction of the loss gradient sign. "Fast Gradient Sign Method (FGSM)"
- Flamingo: A conversational multimodal model connecting a frozen LLM to vision inputs via adapters. "Flamingo \citep{alayracFlamingoVisualLanguage2022} addressed this limitation by pioneering a fully conversational vision-LLM."
- Foundation Models: Large-scale pre-trained models that transfer to many downstream tasks. "Recent advances in artificial intelligence have led to the development of foundation models – large-scale models pre-trained on vast, diverse datasets, exhibiting remarkable capabilities across a range of downstream tasks..."
- Gradient Masking/Obfuscation: Phenomena where gradients are hidden or uninformative, giving a false sense of robustness. "Gradient Masking/Obfuscation: Some defences inadvertently (or deliberately) make it harder to find useful gradients, hindering gradient-based attacks."
- GPT-4V (GPT-4 Vision): A closed-source multimodal model with strong visual understanding capabilities. "A significant evolution in vision-LLMs arrived with OpenAI's GPT-4V \citep{GPT4VisionSystemCard2024}, also known as GPT-4 Vision."
- Image Hijacks: Adversarial images that control generative VLMs at runtime. "Image Hijacks: Adversarial Images Can Control Generative Models at Runtime \citep{lukebaileyImageHijacksAdversarial2023}"
- Image–Text Matching: A pre-training objective to align images with corresponding text. "UNITER ... through four pre-training tasks: masked language modelling, masked region modelling, image-text matching, and optimal transport-based word-region alignment."
- Jailbreaking: Inducing a model to bypass safety constraints and generate prohibited content. "While the security of foundation models is an active research area, much focus has centred on the textual vulnerabilities of LLMs, such as prompt injection or jailbreaking."
- Layer Normalisation: A normalization technique applied within transformer sub-layers to stabilize training. "Each sub-layer is wrapped with a residual connection followed by layer normalisation."
- Llama 3.2 Vision: Meta’s open-weight multimodal model using adapters and a ViT-H/14 encoder. "LLaMA 3.2 Vision \citep{grattafioriLlama3Herd2024} represents Meta's entry into multimodal foundation models with an open-weights approach..."
- LLaVA (Large Language and Vision Assistant): An instruction-tuned open VLM connecting CLIP vision to a Llama-based LLM via a projection layer. "LLaVA (Large Language and Vision Assistant) \citep{liuVisualInstructionTuning2023} marked a significant milestone as the first multimodal instruction-tuned model for vision-language tasks."
- L∞ ball (L-infinity ball): The set of points within a maximum absolute deviation ε from an original input. "projecting the result back onto the allowed perturbation region (e.g., an ball of radius around the original input ) after each step."
- L_p norm: A measure of perturbation magnitude defined by the p-norm of the difference vector. " represents the norm measuring perturbation magnitude..."
- LXMERT: A dual-stream VLM architecture contemporaneous with ViLBERT. "Experimental results showed that these single-stream architectures consistently outperformed dual-stream counterparts like ViLBERT and LXMERT..."
- Masked Language Modelling (MLM): A pre-training task where certain tokens are masked and predicted by the model. "UNITER ... through four pre-training tasks: masked language modelling, masked region modelling, image-text matching, and optimal transport-based word-region alignment."
- Masked Region Modelling (MRM): A task where visual regions are masked and predicted, analogous to MLM for vision. "UNITER ... through four pre-training tasks: masked language modelling, masked region modelling, image-text matching, and optimal transport-based word-region alignment."
- Min–max optimisation (for robustness): Framing robustness as maximizing loss over perturbations and minimizing over model parameters. "Madry et al. \citep{madryDeepLearningModels2019} framed adversarial robustness within a min-max optimisation perspective..."
- Multi-head self-attention: Attention mechanism using multiple parallel heads to capture diverse relationships. "Each encoder layer contains two sub-layers: a multi-head self-attention mechanism and a position-wise fully connected feed-forward network."
- Multimodal Adapters: Learnable modules that interface visual embeddings with a LLM. "By integrating a frozen LLM (Chinchilla) with visual inputs through learnable multimodal adapters, Flamingo enabled seamless interactions..."
- Multimodal Foundation Models: Models handling multiple data modalities (e.g., text and vision) with broad generality. "Multimodal Foundation Models inherently present a more complex security landscape than their unimodal counterparts."
- Neural Machine Translation (NMT): Translation systems based on neural architectures rather than statistical phrases. "This led to a significant shift away from phrase-based statistical methods towards neural machine translation (NMT)."
- NIST adversarial machine learning taxonomy: A standardized classification of attacks, defences, and evaluations. "More recently, the National Institute of Standards and Technology (NIST) introduced a comprehensive classification formalising an industry-wide standard for evaluating both attacks and defences..."
- OpenFlamingo: An open-source implementation of the Flamingo architecture evaluated for adversarial robustness. "a study \citep{schlarmannAdversarialRobustnessMultiModal2023} further investigated similar vulnerabilities through an evaluation of the adversarial robustness of OpenFlamingo..."
- Open-weight (models): Models whose parameters are publicly available for research and use. "Overall, the findings confirm that the vision modality represents a viable attack vector for degrading the performance of contemporary open-weight VLMs..."
- Optimal Transport-based Word–Region Alignment: A pre-training objective aligning words with image regions via optimal transport. "UNITER ... through four pre-training tasks: ... optimal transport-based word-region alignment."
- Perceiver Resampler: A module that adapts high-dimensional visual features into a compact set suitable for an LLM. "The model's perceiver resampler architecture efficiently transformed visual features from a frozen vision encoder into a format compatible with the LLM's token representations."
- PGD (Projected Gradient Descent): An iterative, first-order attack projecting perturbations back to a constrained set after each step. "Projected Gradient Descent (PGD) \citep{madryDeepLearningModels2019} is arguably the most widely used and powerful first-order adversarial attack..."
- Poisoning (training-time) attacks: Attacks that compromise data or training procedures to degrade model integrity. "type (poisoning/training time attacks vs evasion/run time attacks)."
- Prefix Language Modelling: A generative objective where a model learns to continue sequences given a prefix, enabling multimodal generation. "SimVLM employed a novel prefix language modelling objective that allowed for more efficient training with weakly supervised image-text pairs."
- Prompt Injection: Maliciously crafted inputs that steer a model toward unintended behaviours. "much focus has centred on the textual vulnerabilities of LLMs, such as prompt injection or jailbreaking."
- Q-Former: A lightweight query transformer adapter that bridges a vision encoder with a LLM. "BLIP-2 ... introduced an open-source alternative through its innovative Q-Former architecture."
- Reinforcement Learning from Human Feedback (RLHF): Post-training method using human preference signals to align model behaviour. "To address this, techniques like Reinforcement Learning from Human Feedback (RLHF) were developed..."
- Residual Connection: A skip connection adding layer input to output to ease training of deep networks. "Each sub-layer is wrapped with a residual connection followed by layer normalisation."
- Scaling Laws for Neural LLMs: Empirical relationships showing performance improves with model/data scale. "This trend was formalised by the 'Scaling Laws for Neural LLMs' paper \citep{kaplanScalingLawsNeural2020}..."
- Seq2Seq (Sequence-to-Sequence): Framework mapping input sequences to output sequences via encoder–decoder networks. "The subsequent introduction of the Sequence-to-Sequence (Seq2Seq) framework \citep{sutskeverSequenceSequenceLearning2014a} formalised the encoder-decoder architecture..."
- Single-stream architecture: Design where visual and textual tokens are jointly processed in one transformer. "VisualBERT \citep{liVisualBERTSimplePerformant2019} introduced a unified single-stream architecture that processed visual and textual data within a single Transformer encoder."
- Taxonomy of Adversarial Machine Learning: A structured categorization of attack types and phases. "Taxonomy of Adversarial Machine Learning"
- Threat Model Specification: Formal description of attacker goals, knowledge, and capabilities used for robust evaluation. "Threat Model Specification: Clearly defining adversarial goals (e.g., misclassification), knowledge (white-box, black-box, grey-box), and capabilities (e.g., perturbation budget specified by norm)."
- Transformer: An attention-based architecture replacing recurrence/convolutions for sequence modeling. "Building upon the concept of attention, the Transformer architecture, introduced in Attention Is All You Need \citep{vaswaniAttentionAllYou2017}, revolutionised sequence modelling..."
- UNITER: A single-stream VLM trained with multiple pre-training objectives for fine-grained alignment. "UNITER \citep{chenUNITERUNiversalImageTExt2020} further advanced the single-stream approach through four pre-training tasks..."
- Untargeted attack: An attack aiming to cause any incorrect output without specifying a particular target outcome. "These are tested for untargeted PGD (Projected Gradient Descent) against the visual input modality..."
- ViLBERT: A dual-stream VLM with co-attentional layers for cross-modal interaction. "ViLBERT (Vision-and-Language BERT) \citep{luViLBERTPretrainingTaskAgnostic2019} pioneered this extension by building upon the BERT ..."
- ViT (Vision Transformer): A transformer-based vision model that processes images as patch tokens. "This limitation was addressed by the Vision Transformer (ViT) introduced in \citep{dosovitskiyImageWorth16x162020}."
- Vicuna: A fine-tuned Llama-based LLM used as the text backbone in LLaVA. "LLaVA's architecture connected a frozen CLIP Vision Encoder (ViT-L/14) with Vicuna—a fine-tuned version of Meta's Llama LLM—through a trainable projection layer..."
- Visual Question Answering (VQA): A task requiring models to answer questions about images. "and empirically evaluated on the Visual Question Answering (VQA) v2 dataset subset."
- Vision-LLMs (VLMs): Models that integrate visual understanding with language processing. "Prominent examples include LLMs, which process text, and more recently, Vision-LLMs (VLMs), which integrate visual understanding alongside language capabilities."
- White-box attacks: Attacks with full access to model architecture, parameters, and gradients. "White-box attacks, where the attacker has complete knowledge of the model's architecture, weights, and gradients, ..."
- Zero-shot generalisation: The ability to perform unseen tasks or classes without task-specific fine-tuning. "CLIP achieved remarkable zero-shot generalisation across a diverse range of tasks."
- Zero-shot learning: Recognizing classes not seen during training by leveraging semantic relationships. "This enabled zero-shot learning capabilities, allowing the model to recognise object categories not seen during training..."
Collections
Sign up for free to add this paper to one or more collections.

