- The paper presents a unified audio separation framework using text, visual, and temporal prompts integrated via a diffusion transformer architecture.
- It employs an innovative pseudo-labeling pipeline with multi-stage filtering to overcome data scarcity and enrich training diversity.
- The model achieves significant benchmark improvements in speech, music, and SFX separation, validating its high-fidelity performance across modalities.
SAM Audio: Segment Anything in Audio
Introduction
The "SAM Audio: Segment Anything in Audio" paper (2512.18099) introduces a large-scale, unified audio separation model designed to handle text, visual, and temporal prompts for audio source separation. This model, SAM Audio, leverages a diffusion transformer architecture and a multimodal conditioning interface to enable high-fidelity separation in challenging, open-domain multimodal scenarios. The approach is characterized by unified training across speech, music, and general sound, robust evaluation through novel benchmarks, and a pseudo-labeling pipeline to overcome data scarcity. This essay synthesizes the technical underpinnings and empirical findings of the work.
Unified Promptable Audio Separation
Audio source separation is reframed in this work as promptable generative modeling, where the separation target is flexibly specified via three types of conditioning: text (free-form language), visual (mask-based or bounding box on video), and temporal span (intervals indicating when a sound is active). All modalities can be used independently or in combination.
SAM Audio operates on the latent space of a high-fidelity DAC-VAE and is trained via flow matching, using a diffusion transformer backbone. Conditioning signals are injected through cross-attention (for text embeddings derived from T5-base), gated concatenation (for frame-aligned visual features from the Perception Encoder), and direct span tokens (converted from intervals). This design allows robust fusion of global, local, and temporal cues and makes the system robust to missing modalities.
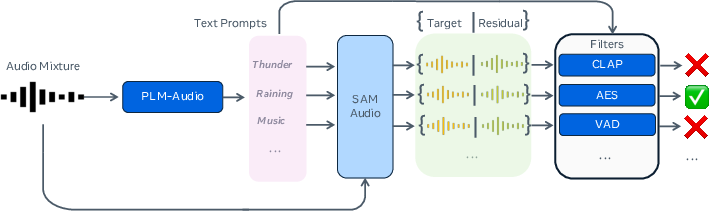
Figure 1: The pseudo-labeling data synthesis pipeline: PLM-Audio generates prompts, which guide initial SAM Audio to produce stems; low-quality outputs are filtered.
Use of pseudo-labeling is key to scale. PLM-Audio produces descriptive captions for sound events in unlabeled mixtures, which are used to generate new candidate stems via an early SAM Audio checkpoint. A multi-stage filtering process (CLAP for text-audio alignment, aesthetic models for cleanliness, ImageBind for A/V correspondence) ensures only high-quality pseudo-labels are incorporated. This massively increases the diversity and realism of training data while remaining scalable.
Prompt Generation and Data Considerations
Text prompts are curated through fusion of automatic captioning (PLM-Audio) and available human metadata, normalized into NP/VP form. Visual masks are generated with SAM2/SAM3, conditioned on both text and aligned video, enabling object-to-sound correspondence. Temporal spans are auto-derived via VAD, focusing on discrete sound events for efficacy.
Crucially, mixture-target-residual triplets are constructed using a combination of real, synthetic, and pseudo-labeled data, split across speech, music, and SFX domains. This mitigates biases imposed by fixed stem ontologies and supports open-domain flexibility.
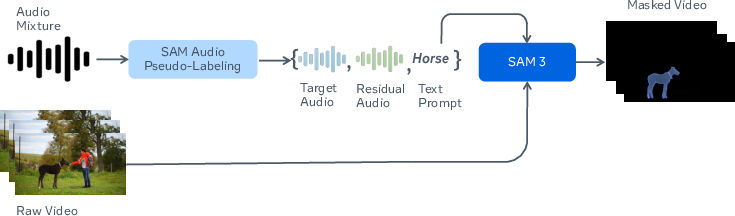
Figure 2: Pseudo-labeled visual data—generated audio captions serve as queries to obtain matching visual masks.
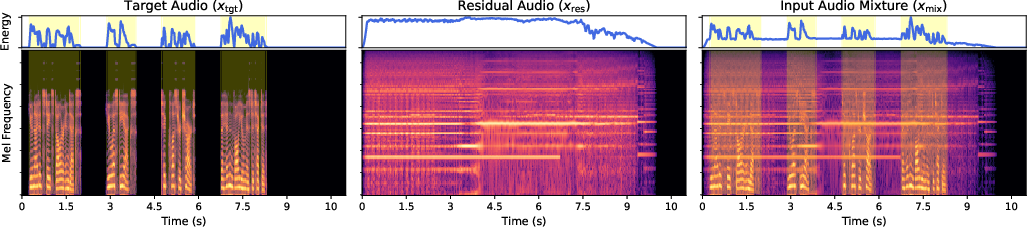
Figure 3: Span generation procedure: RMS energy and Mel-spectrograms illustrate span intervals associated with target events.
Evaluation Benchmarks and Metrics
SAM Audio-Bench
A new benchmark, SAM Audio-Bench, is introduced, designed for ecological validity, multimodal prompt coverage, and cross-domain breadth. Test items are sourced from in-the-wild and professional datasets, annotated with interchangeable text, visual, and temporal spans. Coverage includes general SFX, speech, speaker, music, and instrument separation. The construction enables controlled ablations and unified comparison across domains, modalities, and mixture types.
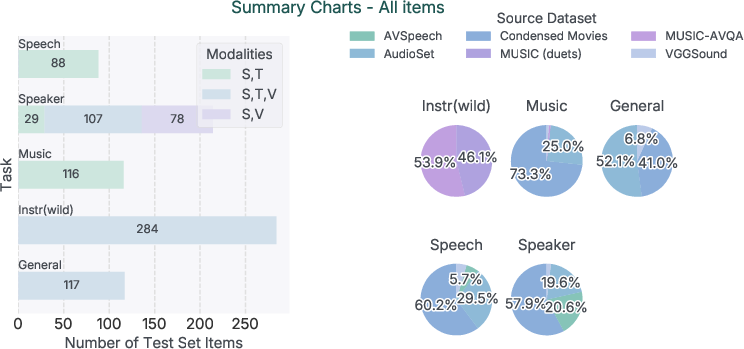
Figure 4: Summary of task, modality, and dataset coverage within SAM Audio-Bench.
SAM Audio Judge
The conventional reliance on SDR and CLAP scores is shown to be insufficient for open-domain, in-the-wild mixtures. The authors introduce the SAM Audio Judge (SAJ), a reference-free evaluation model specifically trained to align with perceptual human judgments across the dimensions of recall, precision, and faithfulness. SAJ is used both as an analysis tool and as a reranker for output selection in beam search.
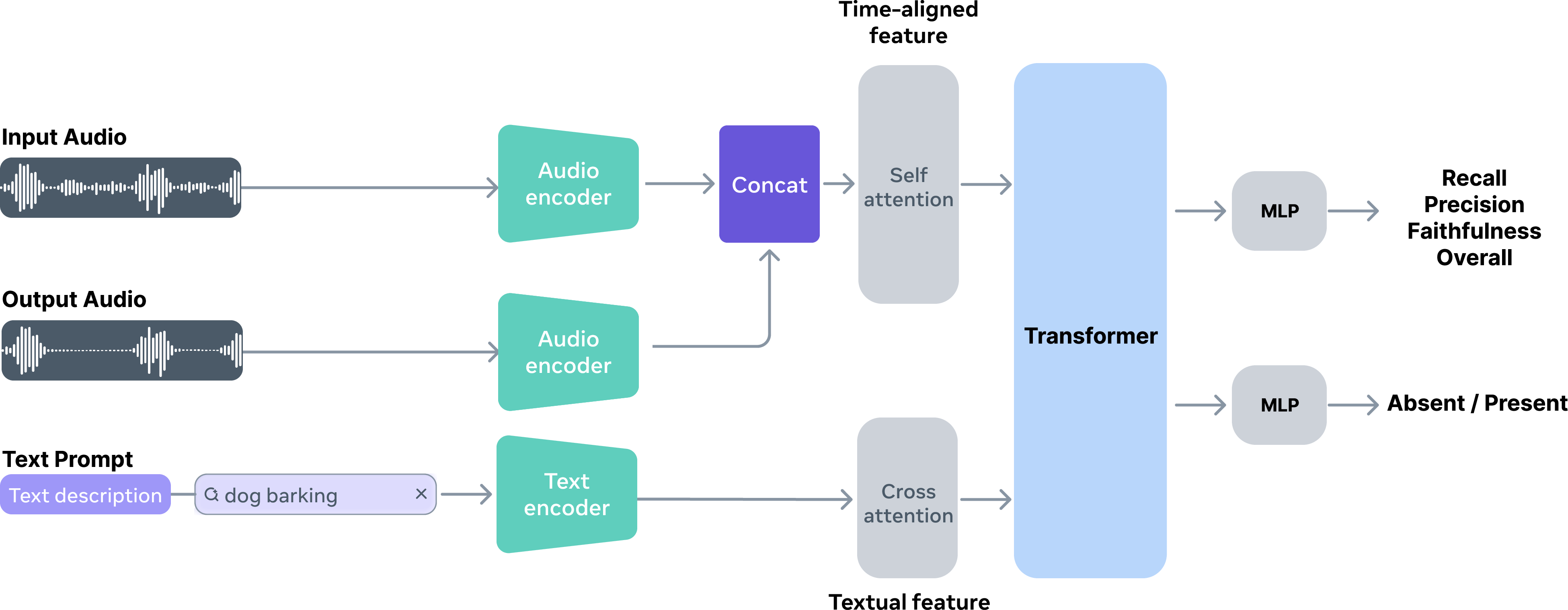
Figure 5: The SAJ model architecture, highlighting text, audio, and joint embeddings for perceptual scoring.
Experimental Results
Text-Prompted Separation
SAJ and human preference studies demonstrate that SAM Audio offers clear improvements over both open-domain and specialized baselines. SAM Audio achieves mean subjective scores (OVR) of 4.35–4.82 across general and specialized domains (speech, music, instrument, SFX, speaker), consistently outperforming previous state-of-the-art including proprietary systems.
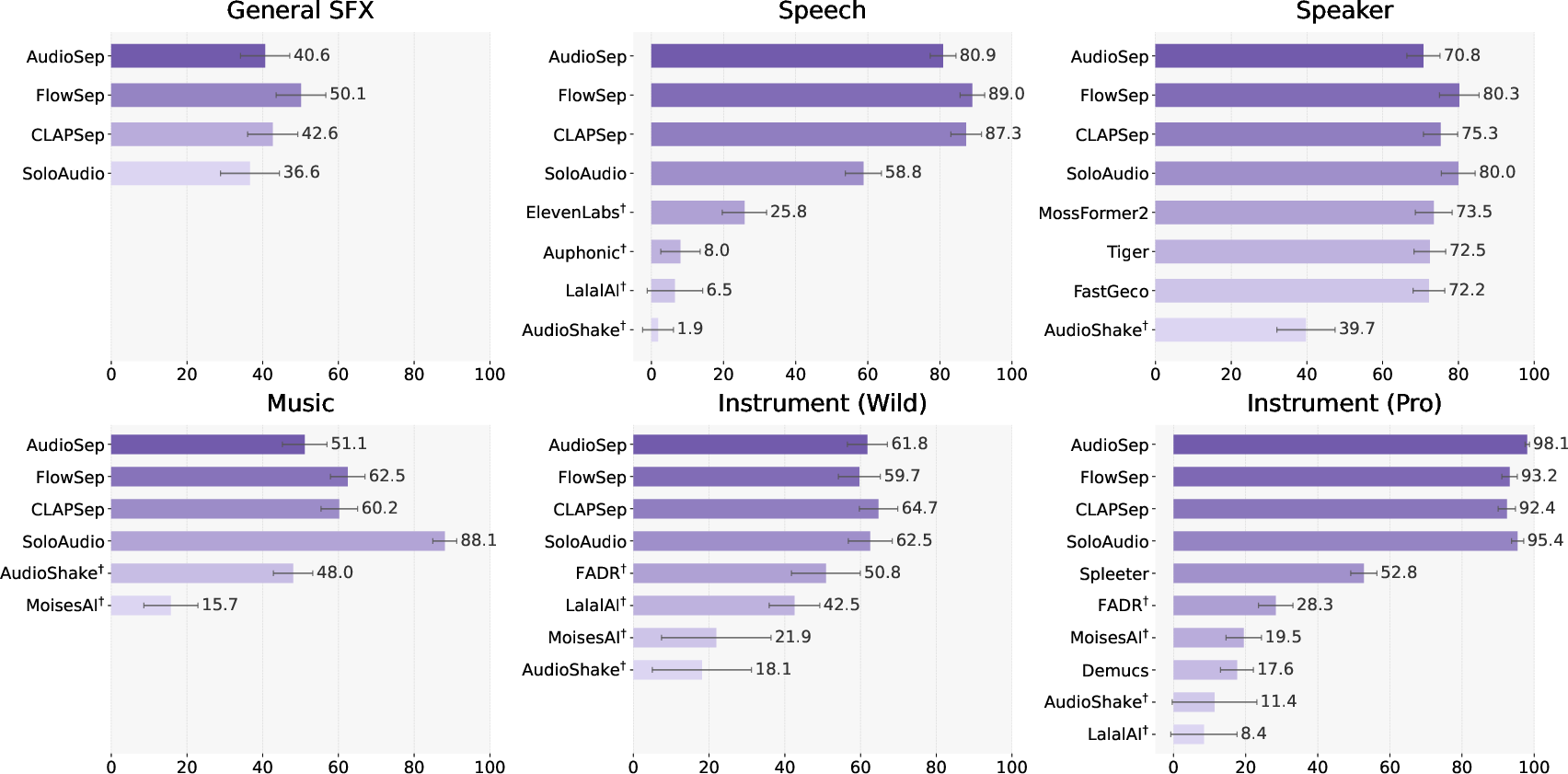
Figure 6: Net win rate (%) of SAM Audio against SoTA separation models in text-prompted tasks; dagger denotes proprietary models.
Visual-Prompted and Joint-Prompted Separation
Although less explored in previous work, SAM Audio robustly supports high-quality separation conditioned on visual masks. Net win rate gains up to 48% over diffusion-based visuo-audio baselines are reported for both speaker and instrument separation. The approach is robust in ambiguous text situations, where visual context is critical to resolve source overlap.

Figure 7: Net win rate (%) of SAM Audio against SoTA separation models in visual-prompted tasks.


Figure 8: Visual-prompted disambiguation—mask, mixture, and separated spectrograms for cases with overlapping/indistinct textual descriptions.
Temporal Span Prompting and Iterative Refinement
Span-only separation is effective for isolated/transient events but degrades for continuous backgrounds or ambiguous mixtures. However, coupling predicted spans (via PE-A-Frame) with text queries yields 13–39% net win rate improvements over text-only baselines, enabling frame-level separation without expensive manual labeling.
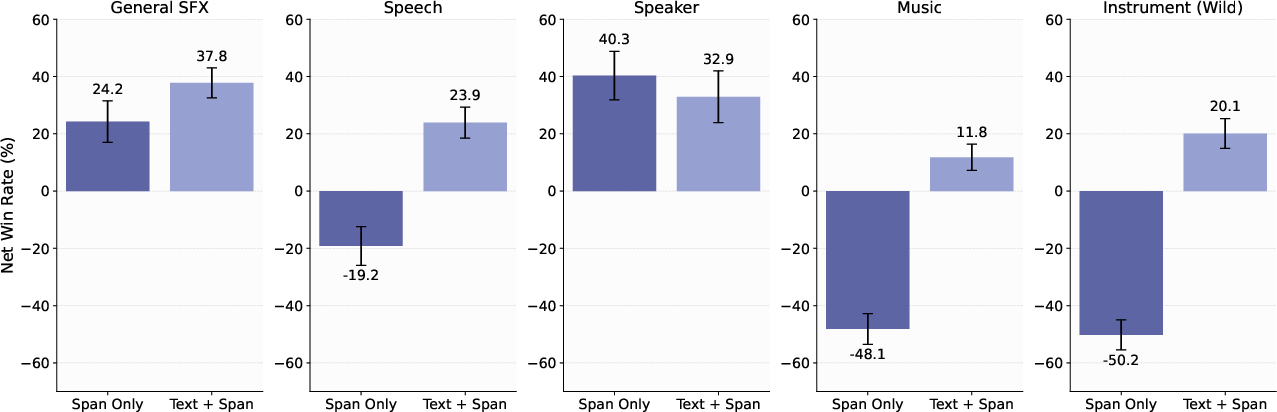
Figure 9: Net win rate (%) of SAM Audio with text+span or span prompts compared to text-only.
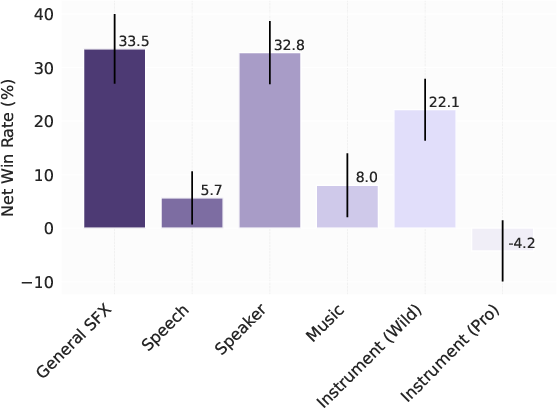
Figure 10: Left—objective and subjective metrics comparing text with/without predicted spans. Right—Net win rate improvement with predicted spans.
Sound Removal and Bidirectional Separation
Because SAM Audio jointly predicts target and residual stems, it enables high-fidelity removal as well as extraction. In music removal experiments, SAM Audio outperforms leading commercial systems (AudioShake, MoisesAI) by 1–8% OVR.
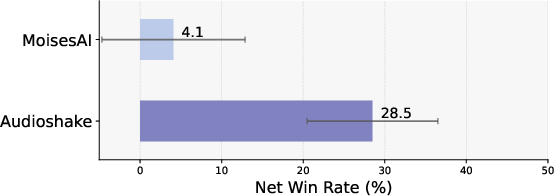
Figure 11: Left—OVR in music removal (table). Right—Net win rate over removal system baselines.
Model and Inference Scale
Scaling model capacity (500M, 1B, 3B) yields marked improvements in structured domains (music, instruments, speaker) with diminishing returns for SFX. Temporal fusion (multi-diffusion over chunked windows) enables seamless long-form (minute-scale) separation with no boundary artifacts.
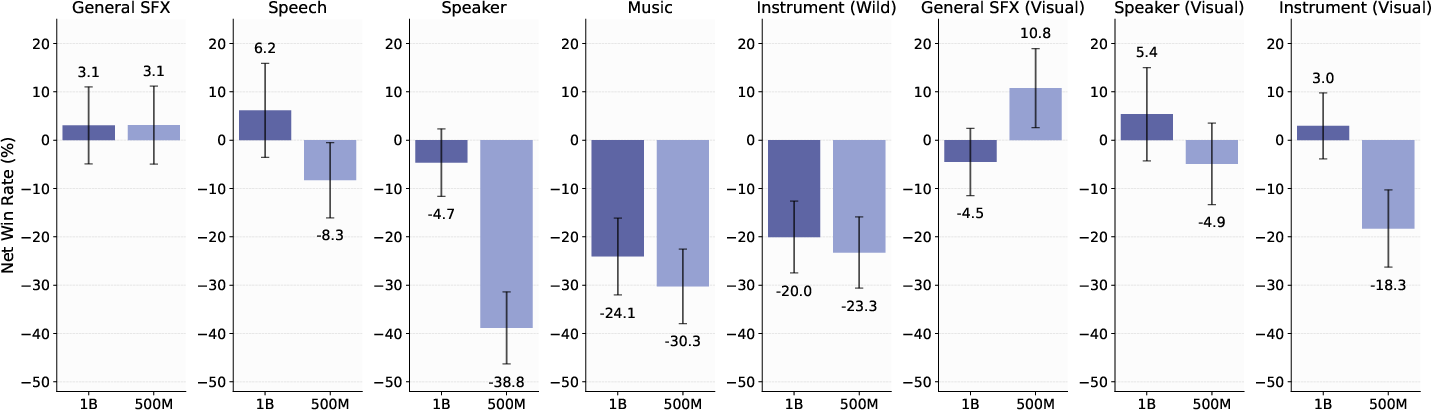
Figure 12: Net win rate (%) of smaller variants compared to SAM Audio-Large across core separation domains.
Practical, Theoretical, and Future Implications
SAM Audio demonstrates that universal multimodal prompting for audio separation is feasible and highly performant given (1) scalable pseudo-labeled data synthesis, (2) flow-based generative modeling for multimodal conditioning, and (3) robust perceptual evaluation. The architecture is extensible: more expressive prompt modalities and higher-capacity backbones yield cross-domain gains.
Challenges remain in further improving visual grounding, especially with off-screen or noisy visual contexts, and in achieving competitive results for highly complex, real-world SFX mixtures with significant overlap and ambiguity. Conversely, the span-prompting mechanism and the joint modeling of target and residual offer a practical path to iterative refinement and downstream integration.
On the theoretical side, the strong empirical correlation between SAJ and human ratings advances the case for dedicated, task-aware, reference-free evaluation metrics in generative modeling, potentially generalizable to other domains (images, video, code).
As the model and data regime scale, SAM Audio's methods suggest a path toward foundation models for general audio understanding—enabling direct instruction, source separation, editing, and reasoning over complex multimodal data using flexible natural-language and spatiotemporal queries.
Conclusion
SAM Audio (2512.18099) is the first universal multimodal foundation model for audio separation, robust to open-domain mixtures and diverse prompt types. The model surpasses specialized and generalist baselines in text, visual, and span prompting scenarios, and the supporting pseudo-labeling and perceptually aligned judge pipeline address core bottlenecks in data and evaluation. The work defines a new standard for flexible, interactive audio separation, marking an advance toward generally prompted multimodal audio systems.