- The paper presents a novel SRL approach that replaces high-dimensional cross-sectional distributions with low-dimensional price histories for computational efficiency.
- It employs Monte Carlo policy gradient and exact differentiation on known budget dynamics, achieving rapid convergence in models like Krusell-Smith and Huggett.
- Experimental results show SRL yields near-identical policy functions and aggregate dynamics compared to traditional VFI methods while reducing computational bottlenecks.
Structural Reinforcement Learning for Heterogeneous Agent Macroeconomics
Motivation and Background
Solving heterogeneous agent models with aggregate risk in macroeconomics is fundamentally hampered by the high dimensionality of the cross-sectional state space, as the agents' problem often depends on the entire distribution of individual states. The recursive formulation results in the notorious "Master equation," in which the cross-sectional distribution is a state variable in the Bellman equation, leading to pronounced computational bottlenecks. Even canonical models such as the Huggett model with aggregate shocks or HANK models with forward-looking constraints remain challenging for dynamic programming and deep learning solution frameworks.
This paper introduces a Structural Reinforcement Learning (SRL) methodology to address these computational problems. The key departure from conventional rational expectations or dynamic programming is the substitution of the high-dimensional distribution state with low-dimensional price histories as state variables for heterogeneous agents. Through simulated equilibrium paths, agents utilize RL principles to learn optimal policies, but exploit full structural knowledge of their individual budget dynamics—yielding efficient Monte Carlo policy gradient optimization. This approach ensures rapid convergence and allows global solutions to models with complex market-clearing conditions and forward-looking dynamics. The SRL method is validated in the Krusell-Smith, Huggett, and one-account HANK models.
Methodological Framework
Sidestepping the Master Equation
The central innovation is the representation of agent state via prices (and short price histories) rather than the explicit cross-sectional distribution. In standard recursive formulations, prices are not Markov given their own histories due to dependence on the distribution. SRL circumvents this by treating price dynamics as a sequential process learned by agents from simulation, restricting agent policies to depend on current or lagged prices:
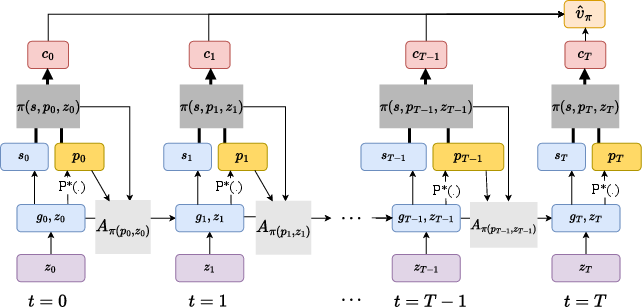
Figure 1: The computational graph underlying the SRL algorithm, demonstrating the separation between individual-state transitions (known structure) and aggregate price trajectories (learned environment).
Given agents' structural knowledge of their own transition dynamics, exact gradients are computed with respect to policy by differentiating through these transitions, while expectations over prices are attained via Monte Carlo averaging over simulated paths. The solution notion, "Sequential Restricted Perceptions Equilibrium" (RPE), ensures agents' expectations are statistically consistent with equilibrium price outcomes, but not fully rational expectations in the recursive sense.
Efficient Market-Clearing and Price Computation
In models with implicit market-clearing, such as Huggett’s zero-net-bond supply, the method leverages grid-based supply schedules: the policy function of agents directly provides an individual supply function as a function of price, and aggregate supply curves are computed via cross-sectional integration. The equilibrium price is then found via root-finding or interpolation at each timestep and trajectory.
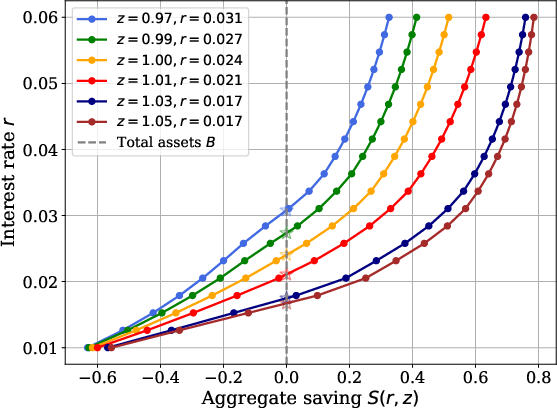
Figure 2: Aggregate saving function S(r,z) for a fixed cross-sectional distribution, displaying market-clearing interest rates across different aggregate shocks.
This approach is computationally efficient, avoiding nested inner-outer loops of traditional fixed-point solution strategies.
The SRL algorithm is implemented using JAX and enables highly parallelized GPU execution. Benchmark runtimes are reported for Krusell-Smith (≈55 seconds), Huggett (≈75 seconds), and HANK (≈199 seconds) models, with convergence achieved within a small number of epochs. Notably, SRL yields only a modest runtime increase from partial to general equilibrium Huggett, confirming the tractability of the general equilibrium problem.
Policy Quality and Robustness
Consumption policies produced by SRL are analytically monotonic and concave in wealth, conforming to theoretical expectations. The method’s accuracy is benchmarked via comparison to conventional Value Function Iteration (VFI) in partial equilibrium (PE), with negligible deviation:
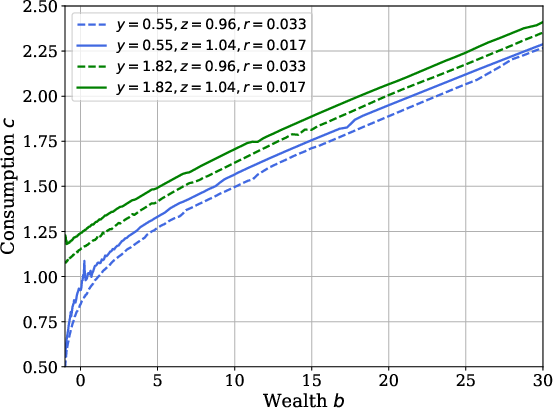
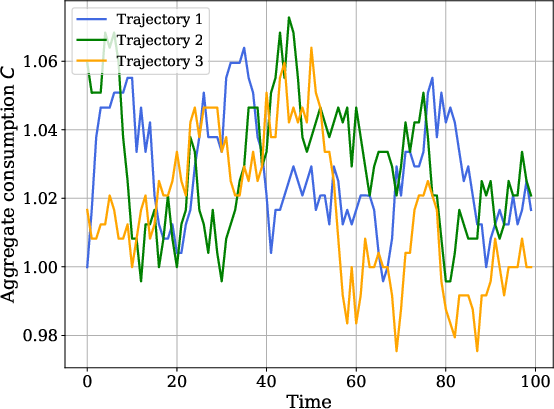
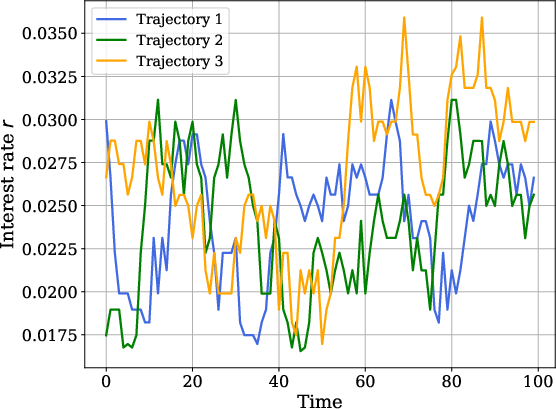
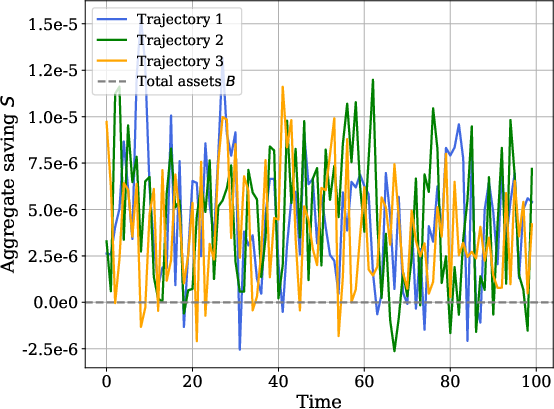
Figure 3: Optimal consumption policy as a function of wealth, showing proper monotonicity and concavity.
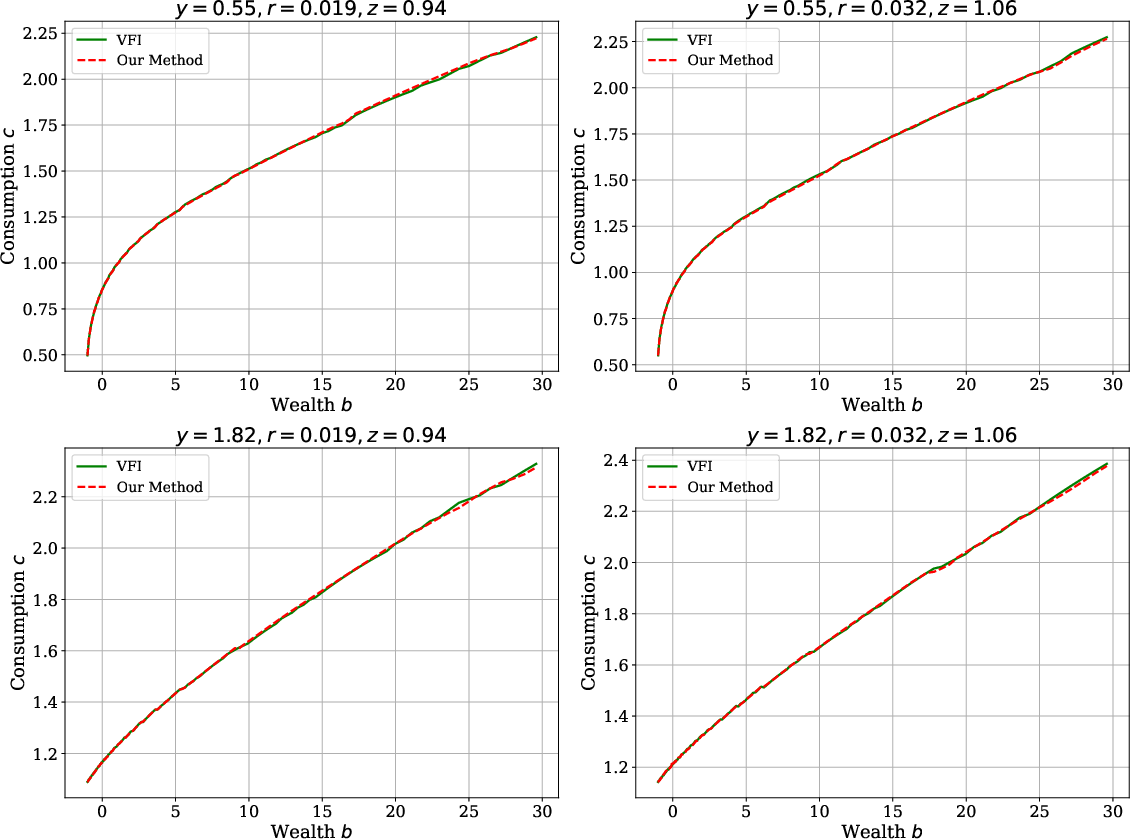
Figure 4: Solution comparison in the Huggett PE problem; SRL and VFI are indistinguishable.
Further, introducing lagged prices as state variables leads to policies nearly invariant to additional history, confirming that current prices encapsulate sufficient information for household behavior:
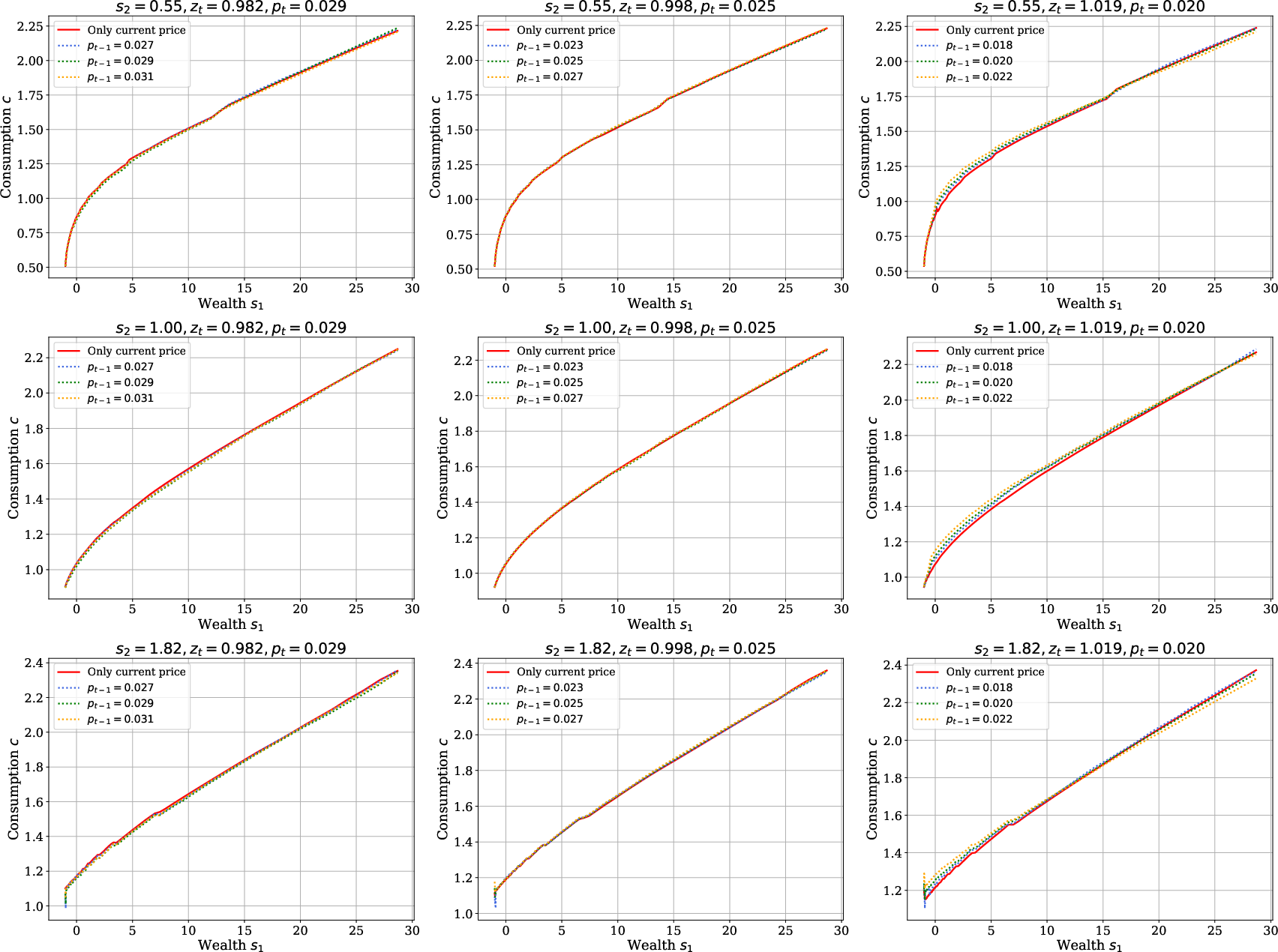
Figure 5: Consumption policy functions when conditioning on lagged price pt−1; negligible impact relative to current price only.
Policy estimation uncertainty is examined with respect to number of simulated trajectories, with confidence bands shrinking as the sample size increases and policy estimates stabilizing in mass-supported regions of the state space:
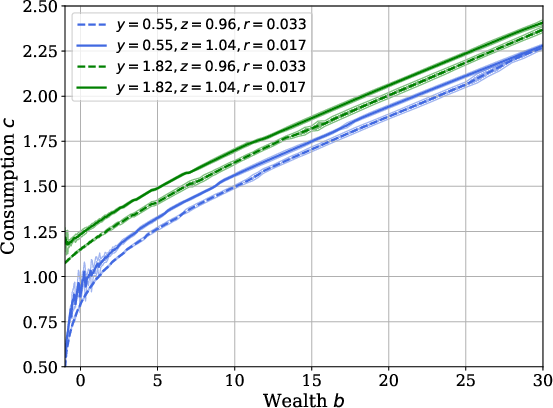
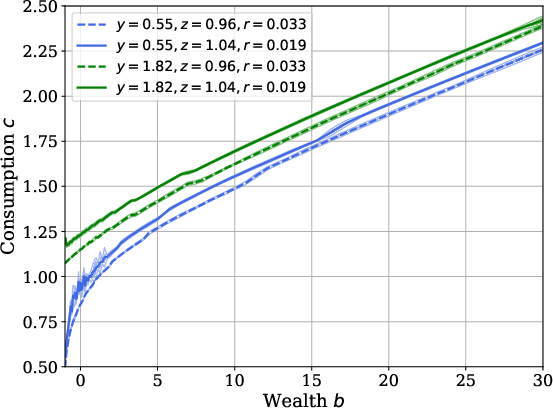
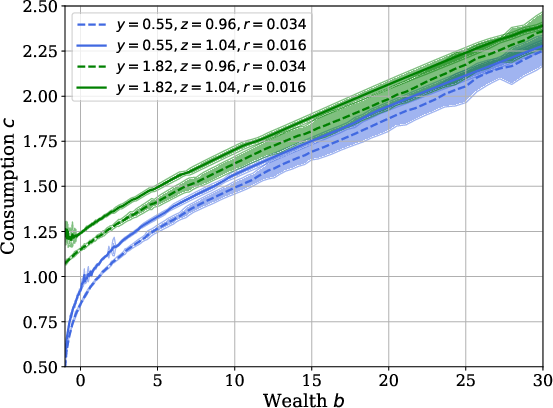
Figure 6: Policy confidence intervals as a function of trajectory sample size.
Equilibrium Dynamics
SRL replicates canonical aggregate dynamics and policy responses in all benchmark models. For Krusell-Smith, the aggregate consumption and capital paths generated by SRL match those computed via neural-network-based rational expectations methods (DeepHAM):
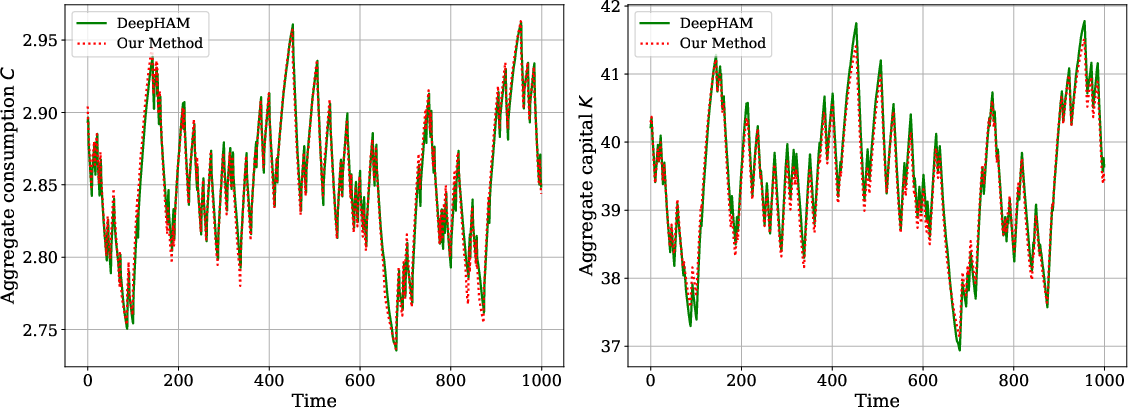
Figure 7: Aggregate consumption and capital paths obtained via SRL and DeepHAM; near-equivalence validates the SRL approach.
HANK model extension demonstrates the scalability and flexibility of the algorithm, implementing joint household-firm learning and global solution to the forward-looking Phillips curve via structural policy gradients.
Theoretical and Practical Implications
The SRL methodology marks a substantive advance in the tractable solution of global heterogeneous-agent macroeconomic models with aggregate risk. By focusing on price histories (observable, low-dimensional equilibrium objects) and exploiting structural individual dynamics, SRL circumvents the curse of dimensionality. The resulting solution concept (Sequential RPE) aligns agents' forecasting to actual realized price paths rather than requiring full rational expectations about the distribution, offering a computational equilibrium that is self-confirming in observable outcomes.
Practically, this approach enables fast, scalable computation as well as flexible model extension (e.g., lag structure, additional agent characteristics, new equilibrium mappings). It is especially promising for studying macro environments with nontrivial market-clearing—such as bond markets and monetary economies—and for empirical integration via sampled expectations formation.
Theoretically, the SRL framework can inform future developments where agent learning occurs not via recursive law-of-motion estimation but through price sequence sampling, possibly dovetailing with models of adaptive expectations or empirical survey evidence on economic forecasting. This also opens new avenues for integrating RL-based expectation formation into macroeconomic dynamics and policy analyses.
Conclusion
Structural Reinforcement Learning offers a robust framework for global equilibrium computation in heterogeneous agent macroeconomics with aggregate risk, replacing the high-dimensional state space with low-dimensional observables and leveraging exact differentiation through individual structure. Its accuracy, scalability, and flexibility make it a compelling solution methodology for both canonical and advanced macroeconomic models. The sequential RPE solution concept reconciles computational tractability with rich stochastic equilibrium dynamics, facilitating future model development, empirical research, and theoretical inquiry into agent expectation formation and macro policy transmission (2512.18892).