Sign Language Recognition using Parallel Bidirectional Reservoir Computing
Abstract: Sign language recognition (SLR) facilitates communication between deaf and hearing communities. Deep learning based SLR models are commonly used but require extensive computational resources, making them unsuitable for deployment on edge devices. To address these limitations, we propose a lightweight SLR system that combines parallel bidirectional reservoir computing (PBRC) with MediaPipe. MediaPipe enables real-time hand tracking and precise extraction of hand joint coordinates, which serve as input features for the PBRC architecture. The proposed PBRC architecture consists of two echo state network (ESN) based bidirectional reservoir computing (BRC) modules arranged in parallel to capture temporal dependencies, thereby creating a rich feature representation for classification. We trained our PBRC-based SLR system on the Word-Level American Sign Language (WLASL) video dataset, achieving top-1, top-5, and top-10 accuracies of 60.85%, 85.86%, and 91.74%, respectively. Training time was significantly reduced to 18.67 seconds due to the intrinsic properties of reservoir computing, compared to over 55 minutes for deep learning based methods such as Bi-GRU. This approach offers a lightweight, cost-effective solution for real-time SLR on edge devices.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
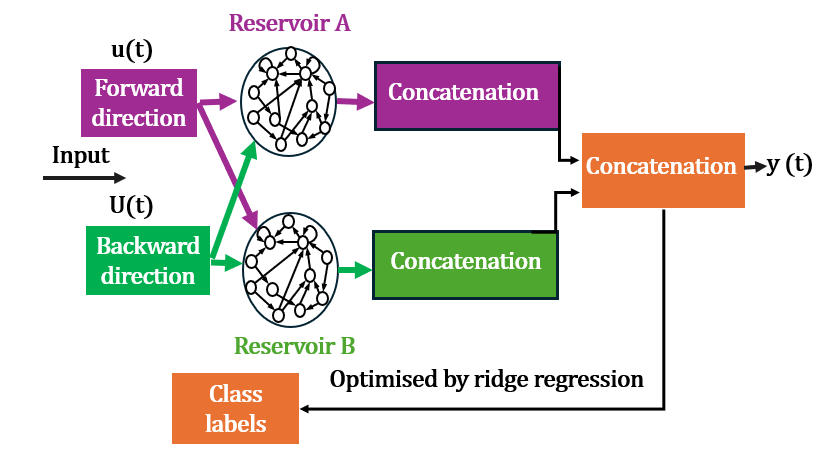
This paper is about teaching computers to understand American Sign Language (ASL) from videos in a way that is fast, affordable, and works well on everyday devices like phones and laptops. The authors introduce a lightweight system that uses a tool called MediaPipe to track hand and body points, and a special kind of simple-but-smart model called Parallel Bidirectional Reservoir Computing (PBRC) to recognize signs.
What questions were the researchers trying to answer?
They focused on three main questions:
- Can we recognize ASL signs accurately using a model that is much faster and cheaper than typical deep learning methods?
- Can this system run and train on regular computers (without powerful GPUs)?
- How does this new method compare to popular deep learning approaches in accuracy and speed?
How did they do it?
To make their system both efficient and effective, the researchers combined a few ideas:
The dataset
They used a well-known sign language video dataset called WLASL100, which contains short clips of people performing 100 different ASL words. It has separate videos for training, validation, and testing, so the model can learn and then be fairly checked.
MediaPipe: finding key points in video
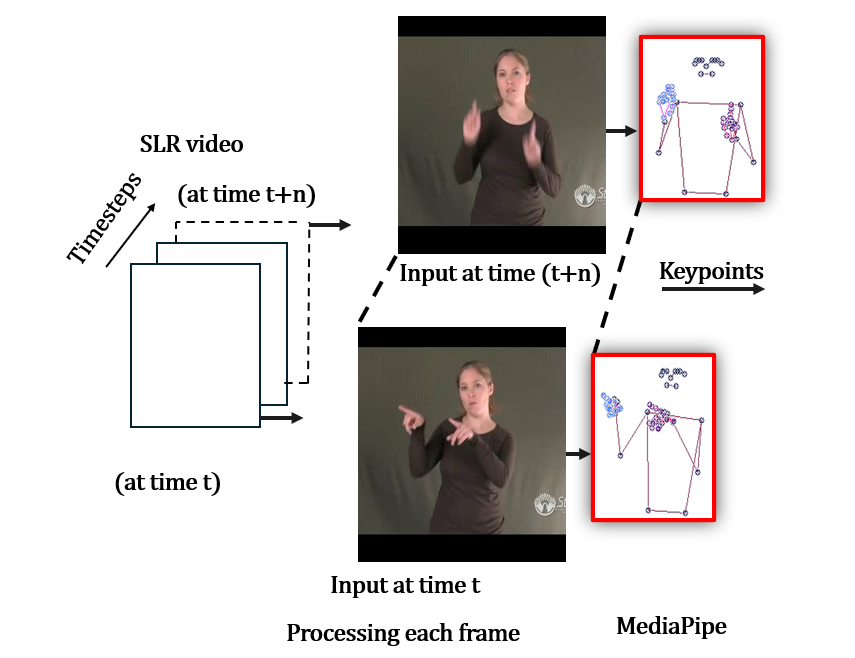
MediaPipe is a free toolkit from Google that can find important landmarks (points) on the hands, face, and body in real time. For hands, it finds 21 landmarks per hand; for the body, it finds 33. Think of these points like a stick-figure map of your fingers and arms. These numbers become the input to the recognition model.
Reservoir computing: a quick analogy
Reservoir Computing (RC) is a way to handle time-based data (like video frames) without heavy training. Imagine you drip different colored inks into a bowl of water (the “reservoir”). The ripples you see are complex patterns created by the ink drops over time. The reservoir is fixed (you don’t change the water itself), but you learn a simple rule to read those ripples and say which color (or sign) was used.
In RC, you only train the last layer (the “reader”) that looks at the ripples and decides the sign. This makes training super fast.
Bidirectional and parallel reservoirs
- Bidirectional means the model looks at the sequence both forward and backward—like watching a short video from start to finish and then in reverse. This helps it understand both past and future context.
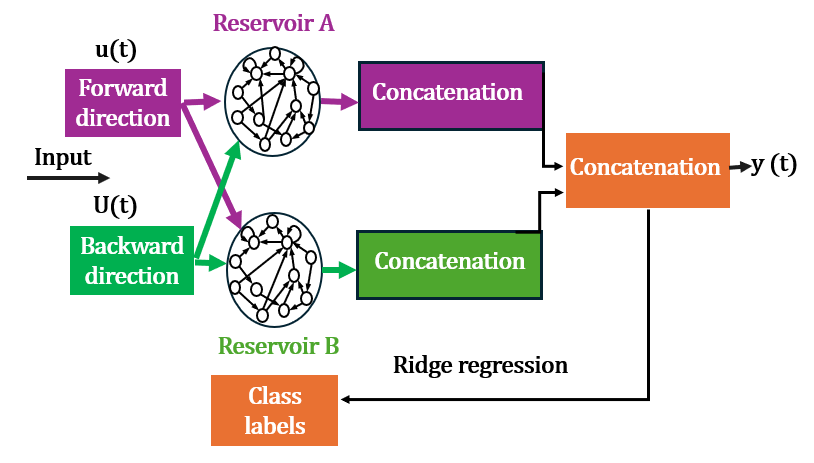
- Parallel means they used two bidirectional reservoirs side by side. Each one has slightly different random connections, so together they capture more diverse patterns from the same input. After both finish, their outputs are combined to form a richer feature set for classification.
Training the final step (ridge regression)
The last layer that makes the final decision uses a simple method called ridge regression. It’s like drawing a best-fit line through data, but with a small safety feature to avoid overfitting. Because only this last layer is trained, the entire system is quick to learn.
A deep learning baseline for comparison
They also tested a popular deep learning model called Bi-GRU (a type of recurrent neural network) using the same input points, to compare accuracy and training time.
What did they find, and why is it important?
They measured accuracy in three ways:
- Top-1: the model’s first guess is correct.
- Top-5: the correct answer is within the model’s top five guesses.
- Top-10: the correct answer is within the top ten guesses.
Here are the key results on the WLASL100 dataset:
- PBRC achieved Top-1: 60.85%, Top-5: 85.86%, Top-10: 91.74%.
- Training time for PBRC: about 18.67 seconds on a regular CPU.
- The deep learning Bi-GRU took over 55 minutes to train on the same machine and was less accurate (Top-1 around 50.01%).
- Compared to other methods reported in the literature, PBRC beat Pose-TGCN (Top-1: 55.43%) and was competitive with I3D (Top-1: 65.89%), even though I3D needed a powerful GPU and many hours to train.
Why this matters:
- The PBRC system is fast to train and runs on everyday computers. That makes it practical for real-time use on phones, tablets, and embedded devices.
- It reaches solid accuracy while being much cheaper and more energy-efficient than heavy deep learning models.
- Faster, lighter systems can help bring sign language technology to more people, making communication more inclusive for the deaf and hard-of-hearing community.
What does this mean for the future?
This work shows that we don’t always need big, expensive deep learning models to recognize sign language well. A smart combination of good feature extraction (MediaPipe) and lightweight time-based modeling (PBRC) can achieve strong accuracy with very short training times. In the future:
- The method could be improved further to boost accuracy.
- It could be extended from recognizing single words (isolated signs) to full sentences (continuous sign language), including facial expressions and body posture.
- Because it’s efficient, it could be deployed widely in apps and devices, helping more families, schools, and workplaces communicate more easily using sign language.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes what remains missing, uncertain, or unexplored, focusing on concrete, actionable issues for future work:
- Dataset generalization: Results are reported only on WLASL100; no validation on other ASL or non-ASL datasets (e.g., MSASL, ASLLVD, LSA64), multilingual signs, or cross-domain scenarios.
- Cross-signer generalization: No explicit evaluation on unseen signer splits or signer-independent protocols to assess robustness to signer identity, style, speed, and handedness.
- Fairness of baselines: Comparisons mix different input modalities and hardware (e.g., keypoints for PBRC vs raw RGB for I3D, CPU vs GPU), making it unclear how much performance stems from the architecture versus feature/source differences; standardized, apples-to-apples baselines are needed.
- Deep model tuning: Bi-GRU baseline (nine hidden layers) appears atypical; hyperparameter tuning, architecture selection, and training regimen for deep models are insufficiently documented, risking under-optimized baselines.
- Continuous SLR not addressed: The system is limited to isolated signs; segmentation, coarticulation, and temporal alignment for continuous sign streams remain open.
- Language modeling integration: No decoding with LLMs or priors to resolve lexical ambiguity; investigating how LM integration affects top-k→top-1 conversion is unexplored.
- Multimodal features omitted: The approach uses primarily hand keypoints; facial expressions, mouthings, head pose, and upper-body cues (critical in ASL grammar) are not modeled; impact of adding these streams is unknown.
- Depth and 3D cues: MediaPipe’s 2D landmarks may lose depth information needed for disambiguation; evaluation with 3D hand/pose estimation or stereo/depth sensors is absent.
- Two-hand coordination: Handling of bimanual signs, occlusions between hands, and inter-hand timing dependencies is not explicitly analyzed or benchmarked.
- Preprocessing clarity: Details on keypoint normalization (scale, rotation, translation), coordinate systems, camera viewpoint correction, and per-sequence temporal normalization (padding/truncation, resampling) are missing.
- Sequence length handling: How variable-length sequences are processed (e.g., fixed-length windows, padding strategies) is not documented; sensitivity to sequence duration remains unknown.
- MediaPipe robustness: No robustness study against landmark tracking errors, jitter, self-occlusions, lighting changes, motion blur, or camera viewpoint shifts.
- Class imbalance: WLASL label distribution and imbalance handling (sampling, weighting) are not reported; per-class performance disparities and confusion analysis are missing.
- Metrics breadth: Only accuracy and top-k are reported; per-class recall/precision, macro/micro F1, calibration, and confusion matrices are absent, limiting diagnostic insights.
- Statistical rigor: Top-k variances/significance tests are not provided; reported standard deviations only for some comparisons; confidence intervals and statistical tests are needed.
- Inference performance: Real-time claims lack quantitative evidence on inference latency, throughput (fps), memory footprint, and energy consumption on actual edge devices (smartphones, MCUs).
- Deployment validation: No end-to-end edge deployment or user study; on-device measurements, thermal behavior, battery impact, and UX considerations remain untested.
- Model size and footprint: Parameter counts, memory usage for reservoirs and readout, and storage requirements are not reported; compression/quantization strategies unexplored.
- PBRC design rationale: Why two bidirectional reservoirs (A/B) are complementary is not demonstrated; diversity mechanisms (different seeds, spectral radii, input scalings) and their impact are not analyzed.
- Ablation studies: Missing ablations on bidirectionality vs unidirectional, single BRC vs PBRC, reservoir size, leak rate α, spectral radius ρ, input scaling, and readout variants to isolate contributions.
- Hyperparameter transparency: Ridge regression’s λ value, tuning procedure, and sensitivity are not reported; stability across seeds and runs needs quantification.
- Readout choice: Only ridge regression is tested; alternative readouts (logistic/softmax regression, SVM, kernelized or shallow MLP) and their accuracy–complexity trade-offs are unexplored.
- Reservoir theory: No analysis of memory capacity, ESP verification, effective temporal horizon, or theoretical understanding of shared recurrent weights between forward/backward streams.
- Training protocol clarity: Train/val/test split fidelity to WLASL protocols, data leakage controls, and number of runs for top-k metrics are not fully specified.
- Error analysis: Absent qualitative analysis of frequent confusions (e.g., minimal pair signs), failure modes for movement-hold patterns, or signs requiring facial grammar.
- Robustness to domain shift: No tests under camera/viewpoint change, different resolutions/frame rates, background clutter, or signer attire; domain adaptation remains open.
- Online/continual learning: The readout is trained offline; feasibility of on-device incremental learning/adaptation to new signers without catastrophic forgetting is not investigated.
- Privacy/ethics: Considerations for on-device processing, data retention, and user privacy in real-world SLR applications are not discussed.
- Reproducibility: Source code, random seeds, MediaPipe version/configuration, and full preprocessing pipeline are not provided, hindering exact replication.
Practical Applications
Immediate Applications
The paper demonstrates a lightweight, CPU-friendly pipeline for isolated ASL word recognition using MediaPipe for keypoint extraction and a Parallel Bidirectional Reservoir Computing (PBRC) classifier trained via ridge regression. The following applications can be deployed now, with noted dependencies.
- ASL-to-text mobile or tablet app for on-device, privacy-preserving communication
- Sectors: software, accessibility, daily life, healthcare
- Tools/products/workflows: smartphone camera → MediaPipe hand/pose keypoints → PBRC inference → top-k predictions UI with user confirmation; optional text-to-speech output
- Assumptions/dependencies: sufficient lighting and camera quality; MediaPipe availability on device; current performance is for isolated words (Top-1 ≈ 60.85%); human-in-the-loop (e.g., top-5 suggestion) recommended to correct errors
- Low-cost reception/kiosk assistance in public services and clinics
- Sectors: government services, healthcare, retail
- Tools/products/workflows: PC or embedded box with a webcam running the PBRC pipeline; staff-facing display of top-k predicted words to support basic interactions when interpreters are unavailable
- Assumptions/dependencies: controlled camera placement; consistent framing; isolated word interactions; staff training on confirmation workflows
- Classroom and self-learning sign tutoring with instant feedback
- Sectors: education
- Tools/products/workflows: tablet/PC app that recognizes isolated signs and provides immediate corrective feedback; supports low-end hardware without GPUs
- Assumptions/dependencies: isolated sign drills; MediaPipe keypoint quality; accuracy suitable for formative feedback but not for grading without human review
- Rapid personalization and small-vocabulary deployment for NGOs and community programs
- Sectors: accessibility, education, non-profit
- Tools/products/workflows: quick on-device fine-tuning (≈ seconds) to add a local set of signs (e.g., hospital-specific terms), leveraging PBRC’s fast ridge-regression training
- Assumptions/dependencies: small vocabulary; few-shot samples per sign; controlled environment
- Video indexing for ASL content (offline processing on CPUs)
- Sectors: media platforms, education, research
- Tools/products/workflows: batch processing of educational videos to tag likely sign tokens using the PBRC pipeline; searchable metadata for curriculum creation
- Assumptions/dependencies: isolated sign segments or pre-segmented clips; content in ASL; manual review to ensure correctness
- Basic sign-command interfaces for robots and smart devices (word-level commands)
- Sectors: robotics, smart home/IoT
- Tools/products/workflows: device camera → MediaPipe → PBRC → command mapping for a small set of robust, distinct commands (e.g., “stop,” “help,” “open”)
- Assumptions/dependencies: limited vocabulary of distinct signs; stable camera view; operator training; safety interlocks for misclassification
- Teaching and research in resource-constrained AI courses and labs
- Sectors: academia
- Tools/products/workflows: PBRC as a teaching baseline for sequence modeling; reproducible CPU-only experiments; course modules comparing RC vs. DL training time and energy
- Assumptions/dependencies: WLASL or similar datasets; MediaPipe; emphasis on isolated recognition
Long-Term Applications
These applications require further research and development—particularly improvements in accuracy, robustness, and support for continuous (sentence-level) sign language recognition, multimodal cues, and broader language coverage.
- Continuous sign language recognition (sentence-level translation)
- Sectors: software, accessibility, media, customer service
- Tools/products/workflows: PBRC extended with segmentation, language modeling, and context handling; integration with NLP and ASR/TTS for end-to-end sign-to-speech/text workflows
- Assumptions/dependencies: larger, diverse continuous-sign datasets; improved temporal modeling of coarticulation and grammar; better facial/pose integration; evaluation standards
- Multimodal, multilingual SLR (face, mouth, body pose; multiple sign languages)
- Sectors: healthcare, education, global services
- Tools/products/workflows: MediaPipe face/pose + hand landmarks fused with PBRC; domain adaptation across sign languages (BSL, JSL, etc.)
- Assumptions/dependencies: comprehensive, labeled multimodal datasets; cross-lingual transfer methods; fairness and inclusivity across dialects and signer variability
- Ultra-low-power wearables and smart glasses for real-time sign interpretation
- Sectors: consumer electronics, accessibility
- Tools/products/workflows: neuromorphic/embedded RC hardware or optimized PBRC on microcontrollers; on-device inference and limited training; AR overlays displaying recognized text
- Assumptions/dependencies: hardware acceleration for RC; reliable camera stabilization; continuous recognition; privacy-preserving UX
- Policy-aligned accessibility deployments in public institutions
- Sectors: policy, public-sector IT
- Tools/products/workflows: procurement frameworks for low-power, on-device SLR solutions; performance benchmarks; human-in-the-loop protocols; privacy and data protection guidelines
- Assumptions/dependencies: standardized evaluation metrics for SLR; certification processes; training staff to manage error rates and confirm outputs
- Industry-grade SDKs and APIs for PBRC-based gesture recognition
- Sectors: software, robotics, education
- Tools/products/workflows: developer toolkits that abstract MediaPipe keypoint extraction and PBRC training/inference; bindings for C++/Python/embedded; integration with TTS/NLP
- Assumptions/dependencies: robust documentation and support; cross-platform compatibility; standardized model export and on-device optimization
- Smart-home and IoT ecosystems controlled via sign
- Sectors: consumer IoT, accessibility
- Tools/products/workflows: camera-equipped hubs using PBRC for a broader command inventory; context-aware disambiguation; personalization per household
- Assumptions/dependencies: continuous recognition; improved accuracy; privacy-by-design; edge compute constraints
- Safety-critical applications in industrial and emergency scenarios
- Sectors: manufacturing, emergency response
- Tools/products/workflows: gesture-based safety commands; multi-sensor redundancy (e.g., RF beacons, depth cameras); confidence gating and fail-safes
- Assumptions/dependencies: certified performance under occlusions, PPE, variable lighting; extensive robustness testing; legal/regulatory compliance
Cross-cutting assumptions and dependencies
- Current system is validated on WLASL100 (ASL, isolated words); generalization to continuous signing, other sign languages, and unconstrained conditions requires additional data and modeling.
- Performance constraints: Top-1 accuracy ≈ 60.85% necessitates top-k UI, confirmations, or hybrid approaches (e.g., adding LLMs or human oversight) for reliable deployment.
- Environmental factors: camera placement, lighting, occlusions, and signer orientation materially affect MediaPipe keypoint quality and downstream accuracy.
- Software stack dependencies: continued support for MediaPipe; efficient linear algebra libraries for ridge regression (e.g., Eigen, BLAS/LAPACK) to maintain low latency on edge hardware.
- Ethical and privacy considerations: on-device processing is preferred; clear consent, data minimization, and secure handling of any stored samples for personalization.
Glossary
- Activation function: A nonlinear function applied to neural units to introduce nonlinearity into state dynamics. "The function is a nonlinear activation function, commonly chosen as or $\sigma(\cdot) = \frac{1}{1 + e^{-x}$, which introduces nonlinearity into the reservoir state dynamics."
- Bidirectional gated recurrent unit (Bi-GRU): A recurrent neural network variant that processes sequences in both forward and backward directions. "We also employed a deep learning-based method, Bi-GRU, for sign language recognition and compared the results with those of the PBRC-based architecture."
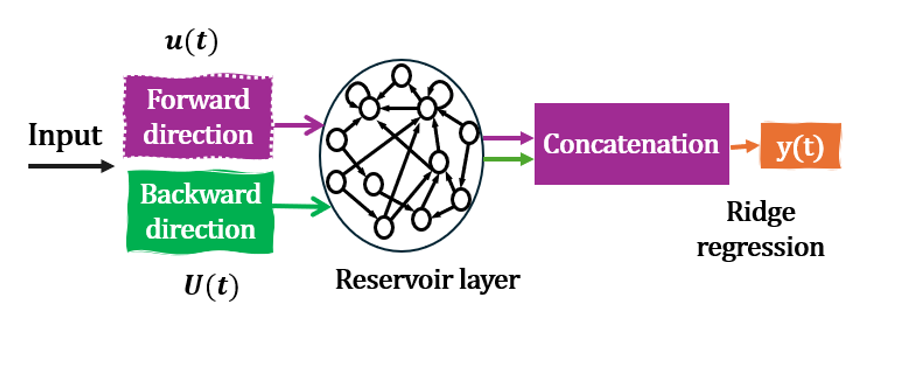
- Bidirectional reservoir computing (BRC): A reservoir computing setup that processes input sequences in forward and backward directions to capture full temporal context. "In a standard ESN, inputs flow in one direction, whereas bidirectional reservoir computing (BRC) can process the input sequence in both forward and backward directions simultaneously \cite{17}."
- Concatenation operator (⊕): The operation of joining vectors end-to-end to form a single feature vector. "where denotes the concatenation of both states of BRC."
- Convolutional neural network (CNN): A deep learning architecture using convolutional layers, commonly for visual tasks. "Deep learning-based models, such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs), are widely used by researchers for developing SLR-based systems \cite{3}."
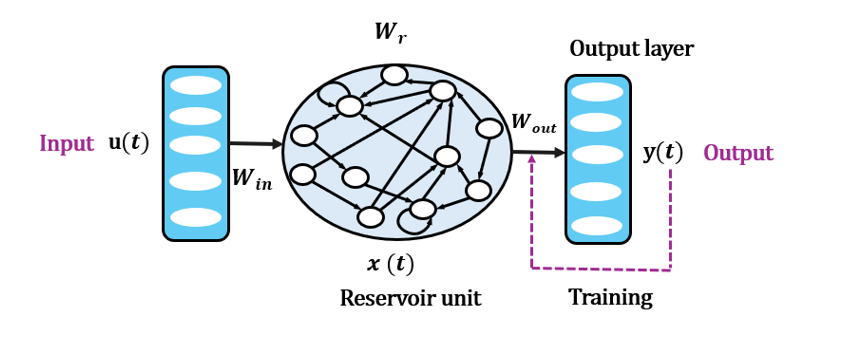
- Echo state network (ESN): A type of reservoir computing with a fixed recurrent reservoir and trainable readout, suited for temporal data. "ESN is a type of reservoir computing that relies on the dynamics of a randomly connected recurrent neural network to process temporal data, as shown in Fig.~\ref{fig:2}."
- Echo state property (ESP): A stability condition ensuring reservoir states are driven by inputs and do not diverge. "The spectral radius of the reservoir is scaled to ensure that the echo state property (ESP) is maintained."
- Eigenvalue: A scalar indicating how a linear transformation scales its eigenvector; used to characterize reservoir stability. "denoted as , is defined as the largest absolute eigenvalue of , i.e., , where are the eigenvalues of ."
- Graphics processing unit (GPU): Specialized hardware for parallel computation, often used to train deep learning models. "These models require high-end hardware, such as graphics processing units (GPUs) or tensor processing units (TPUs),"
- I3D: An inflated 3D convolutional network architecture for video action recognition. "Accuracy comparison of PBRC with DL-based approaches (Pose-TGCN, I3D) and MRC for SLR on the WLASL100 dataset"
- Leak rate: A parameter controlling the speed of reservoir state updates in leaky-integrator ESNs. "The parameter is the leak rate that controls the update speed of the forward reservoir states."
- Loihi: Intel’s neuromorphic chip/platform designed for spiking neural network computation. "Intelâs neuromorphic platform, Loihi,"
- MediaPipe: An open-source framework providing real-time hand tracking and landmark extraction for gesture analysis. "MediaPipe enables real-time hand tracking and precise extraction of hand joint coordinates, which serve as input features for the PBRC architecture."
- Multicollinearity: High correlation among predictor variables that can destabilize linear regression estimates. "especially when dealing with multicollinearity among predictor variables."
- Multiple reservoir computing (MRC): An approach using multiple reservoirs to enhance feature diversity and performance. "Accuracy comparison of PBRC with DL-based approaches (Pose-TGCN, I3D) and MRC for SLR on the WLASL100 dataset"
- Parallel bidirectional reservoir computing (PBRC): An architecture with two bidirectional ESN reservoirs operating in parallel to enrich temporal features. "we propose a lightweight SLR system that combines parallel bidirectional reservoir computing (PBRC) with MediaPipe."
- Pose-TGCN: A pose-based temporal graph convolution network for sign/action recognition. "Accuracy comparison of PBRC with DL-based approaches (Pose-TGCN, I3D) and MRC for SLR on the WLASL100 dataset"
- Readout layer: The trainable output layer that maps reservoir states to targets. "since only the readout layer requires training via ridge regression,"
- Readout weight matrix: The learned linear mapping from reservoir states to outputs in RC. "The output is generated using the readout weight matrix $W_{\text{out}$ as shown in Eq.~(\ref{eq:parallel_bidirectional_output_sharedW})."
- Reservoir computing (RC): A framework with fixed recurrent dynamics and trained readout, efficient for sequential tasks. "Reservoir computing (RC) is well-suited for resource-constrained environments because it requires training only the output layer,"
- Recurrent neural network (RNN): Neural architectures with feedback connections for processing sequences. "Deep learning-based models, such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs), are widely used by researchers for developing SLR-based systems \cite{3}."
- Ridge regression: A regularized linear regression method adding an L2 penalty to mitigate overfitting and multicollinearity. "We employed ridge regression to train and fine-tune the PBRC-based model for SLR."
- Spectral radius: The largest absolute eigenvalue of a matrix; in ESNs, it governs reservoir stability and memory. "The spectral radius of the recurrent weight matrix , denoted as , is defined as the largest absolute eigenvalue of ,"
- Spiking neural network (SNN): Neural models that use discrete spikes for communication, often on neuromorphic hardware. "The authors implement four distinct SNN models on Intelâs neuromorphic platform, Loihi,"
- Tensor processing unit (TPU): Google’s ASIC optimized for tensor computations in machine learning workloads. "These models require high-end hardware, such as graphics processing units (GPUs) or tensor processing units (TPUs),"
- Top-1 accuracy: The fraction of samples where the model’s highest-confidence prediction matches the ground-truth label. "achieving top-1, top-5, and top-10 accuracies of 60.85\%, 85.86\%, and 91.74\%, respectively."
- WLASL100: A 100-class subset of the Word-Level American Sign Language dataset used for SLR benchmarking. "We used WLASL100 dataset for SLR \cite{11}."
- Word-Level American Sign Language (WLASL): A video dataset of isolated ASL signs for recognition tasks. "We trained our PBRC-based SLR system on the Word-Level American Sign Language (WLASL) video dataset,"
Collections
Sign up for free to add this paper to one or more collections.