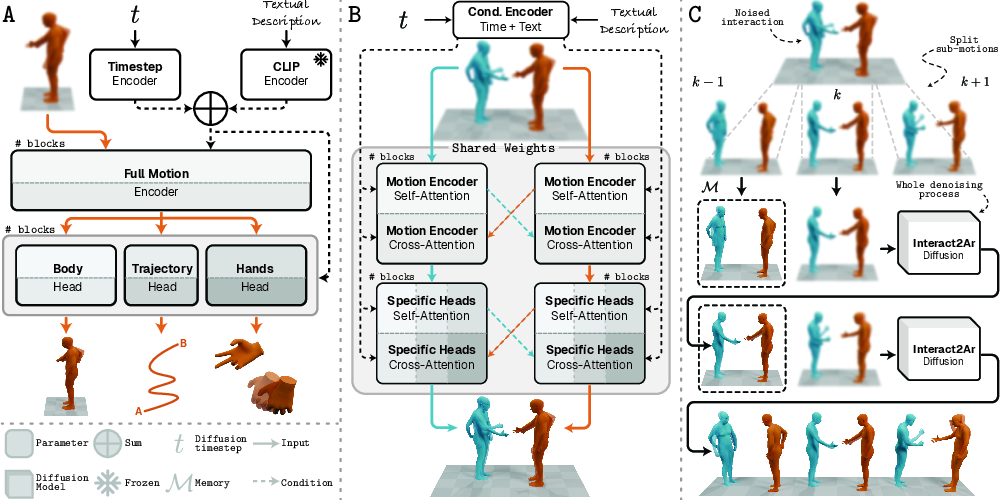
- The paper introduces a novel autoregressive diffusion model with cooperative denoising and mixed memory, enabling high-fidelity, text-driven full-body interactions.
- It employs specialized denoising heads for global trajectories, body, and hand articulation to ensure detailed motion generation and smooth transitions.
- The model outperforms prior state-of-the-art methods in metrics like R-Precision, FID, and jerk-based smoothness while supporting versatile downstream applications.
Interact2Ar: Full-Body Human-Human Interaction Generation via Autoregressive Diffusion Models
Introduction
The synthesis of physically plausible, text-conditioned full-body human-human interactions remains a nontrivial problem in generative modeling due to the necessity for fine-grained temporal and spatial coherence across multiple agents, including detailed hand articulation. Previous approaches either omitted hand modeling, suffered from limited inter-agent information flow, or generated motion with insufficient contextual adaptability. “Interact2Ar: Full-Body Human-Human Interaction Generation via Autoregressive Diffusion Models” (2512.19692) addresses these deficiencies via a novel architecture and learning paradigm that integrates cooperative agent denoising, body-part specialization, and autoregressive–diffusion with an adaptive mixed-memory mechanism. The model enables not only high-fidelity motion generation but also downstream adaptive applications, including compositional motion synthesis, perturbation adaptation, and multi-human interactions.
Architectural Innovations
Interact2Ar extends the diffusion modeling paradigm with a tripartite architectural configuration:
This configuration enables strong performance in both precision and fine-grained realism, particularly for high-dimensional hand articulations, which previous architectures either omitted or modeled inefficiently.
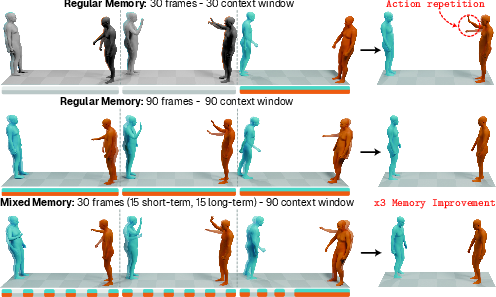
Mixed Memory for Temporal Context Management
Interacting agents often require both immediate and long-term historical information to maintain physical plausibility and avoid local repetitive artifacts or global inconsistency. To this end, Interact2Ar integrates a novel Mixed Memory mechanism:
Ablation experiments demonstrate that naive memory expansion impedes convergence, while Mixed Memory provides superior metrics at reduced resource cost.
Evaluation Methodology
To address the known limitations of prior evaluation protocols (e.g., insensitivity to global trajectory artifacts and inadequate hand assessment), the authors develop a robust set of evaluators:
- All evaluators operate on global joint positions (not rotations), ensuring sensitivity to spatial misalignments, especially critical in interaction contexts.
- Evaluators are body-component-specific (full, body, hands), supporting fine-grained analysis. This mitigates the risk of architectures overfitting to specific body parts at the expense of others.
Comprehensive quantitative and qualitative evaluation on the Inter-X dataset demonstrates the superiority of Interact2Ar across R-Precision, FID, multimodality/diversity, and jerk-based smoothness metrics, using both the baseline and newly proposed evaluators.
Comparative Results
Interact2Ar (both with and without autoregression) consistently surpasses prior SOTA models (e.g., InterGen, InterMask) in full-body, body-specific, and hand-specific metrics. Most notably, the autoregressive variant provides additional gains in adaptability and transition smoothness, addressing a previously unaddressed axis in multi-human generation.
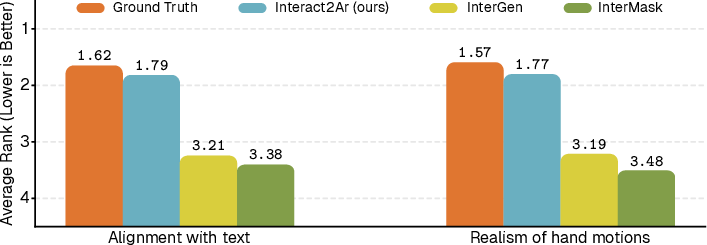
Figure 3: User study: Average ranking results highlight Interact2Ar’s strong performance in text alignment and hand fidelity.
Qualitative comparisons show superior compositional alignment and hand motion for Interact2Ar.
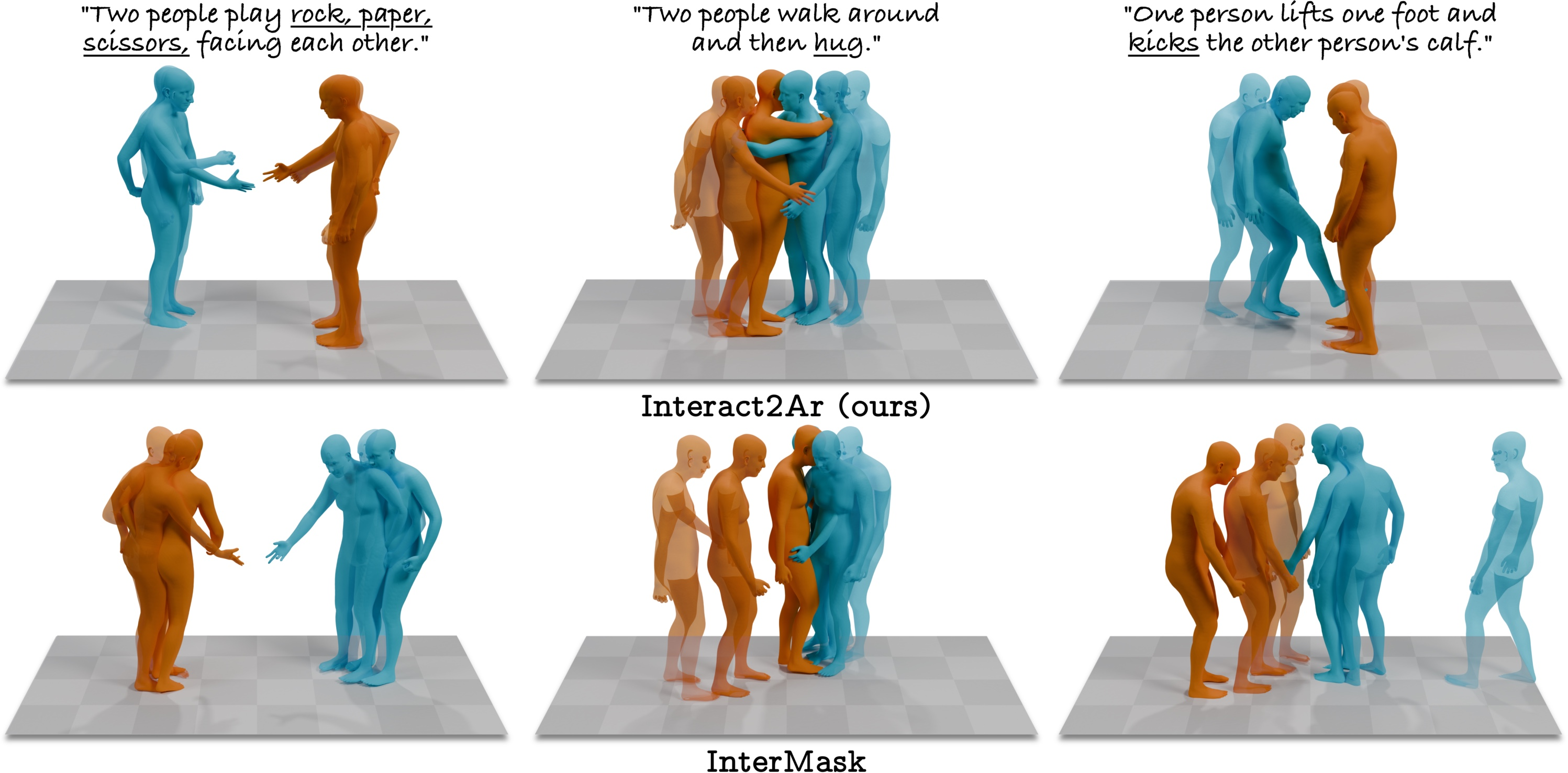
Figure 4: Interact2Ar vs. InterMask: Higher-quality interactions with improved text alignment and hand realism via Interact2Ar.
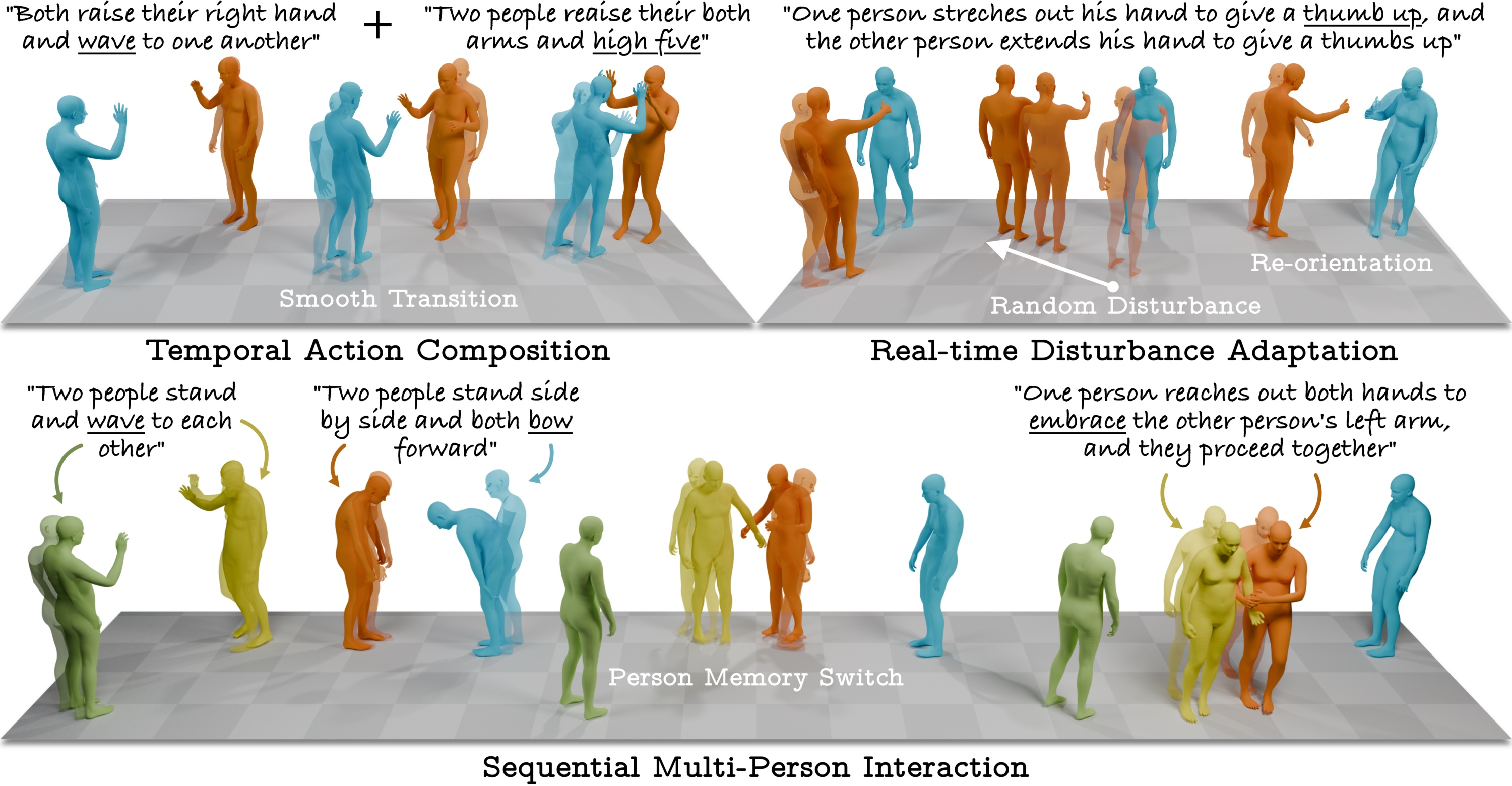
Adaptive and Downstream Applications
Autoregressive sampling with Mixed Memory brings nontrivial practical implications:
Implications, Limitations, and Future Work
The architectural and evaluation advances embodied by Interact2Ar meaningfully shift the baseline for text-conditioned, full-body, multi-human interaction generation. By incorporating detailed hand kinematics and autoregressive adaptation, this model facilitates practical deployment in virtual assistants, simulation, telepresence, and entertainment pipelines, where high-quality, adaptive, and compositional interaction is essential.
However, constraints remain primarily in dataset limitations, especially the lack of shape diversity in ground truth motion data. While SMPL-X provides strong parameterization for generative efficiency, it may obscure population-level variability crucial for some downstream tasks (e.g., hand contact precision, social signal diversity). Extending datasets and model conditioning to cover broader anthropometric distributions will further enhance realism.
From a theoretical perspective, the efficacy of Mixed Memory for extended context windows suggests promise for analogous architectures in other autoregressive diffusion tasks (e.g., language and vision multimodal modeling), especially those requiring efficient balance between local coherence and global structure.
Conclusion
Interact2Ar represents a holistic advance for modeling realistic, adaptable, text-driven human-human interactions with explicit hand modeling. The fusion of cooperative denoising, body-part specialization, autoregressive generation, and Mixed Memory offers compelling gains across practical and theoretical axes, and sets a rigorous evaluation and ablation standard for future research in multi-agent human motion synthesis (2512.19692).