- The paper presents a unified framework that blends probabilistic modeling with robust M-estimators to clarify RANSAC inlier scoring.
- It critically evaluates traditional methods, exposing derivation errors in MAGSAC++ and revealing its equivalence with a Gaussian-uniform marginal likelihood approach.
- The experimental study isolates scoring functions, demonstrating uniform performance and persistent sensitivity to threshold selection across methods.
RANSAC Scoring Functions: A Comprehensive Analysis and Experimental Re-examination
Motivation and Context
RANSAC remains the canonical consensus-based method for robust geometric model fitting in the presence of significant outlier contamination, with applications spanning relative pose estimation, homography, and absolute pose scenarios. Despite decades of development, the scoring function that evaluates the quality of a candidate model—and thus determines "best inliers"—is neither unified nor fully understood. Disparate theoretical justifications and empirical reports have led to widespread adoption of variants such as MSAC, MAGSAC++, and learned scoring functions, even as the true effect of these choices on robustness, accuracy, or parameter sensitivity remained ambiguous.
This study undertakes a rigorous synthesis of scoring function principles, delivering a unifying framework for probabilistic and robust M-estimator approaches, and provides a thorough critique of widely adopted methods—most notably MAGSAC++. Importantly, the experimental protocol isolates the score function from pipeline confounds and rigorously evaluates sensitivity to threshold selection with both large and small validation regimes.
Theoretical Foundation: Probabilistic and Robust Scoring Synthesis
Probabilistic Modeling and Geometric Manifolds
The analysis begins by formalizing geometric model estimation as a probabilistic mixture model, assuming a combination of inliers (distributed according to a spherically symmetric error model around the model manifold in observation space) and uniformly distributed outliers. A central contribution is the careful differentiation between the distribution of residuals orthogonal to the geometric manifold (the "ray density") and misleading alternatives, such as naïvely assuming χ-distributed residuals for all fit types, which is shown to be unsound apart from certain special cases.
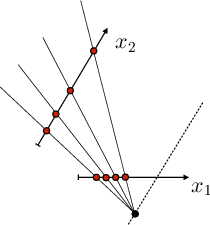
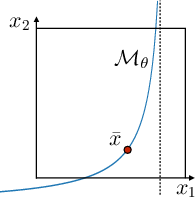
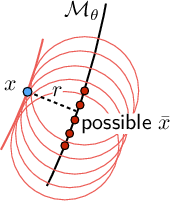
Figure 1: (a) Illustration of data correspondences under homography on a plane, (b) geometric model manifold Mθ, and (c) probabilistic marginalization of observed correspondences to a function of residuals orthogonal to Mθ.
Spherical noise models, whether Gaussian, Laplacian, or uniform, lead—after marginalization—to a univariate distribution of the orthogonal residual. The resulting formulation unifies the geometric error and classical robust statistics methods, showing that for most practical cases the inlier residual is approximately normal.
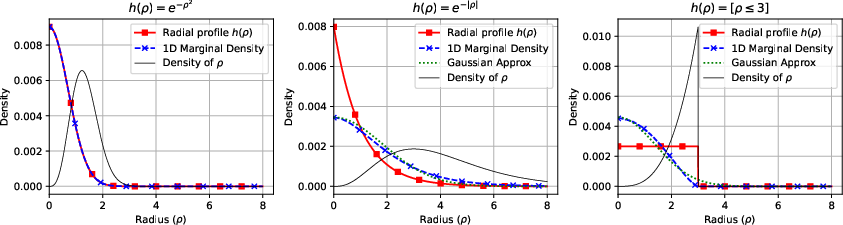
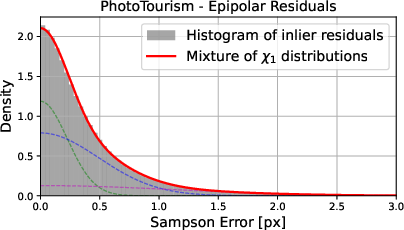
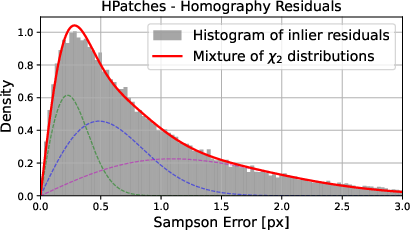
Figure 2: Marginalized 1D distributions of different profile functions (Gaussian, Laplacian, uniform) over four dimensions; all residual marginalizations are approximately Gaussian due to the central limit effect of manifold marginalization.
Likelihood, M-Estimators and the Unified Threshold Parameterization
Both marginal and profile (MAP) likelihoods form additive criteria over per-correspondence residuals; the associated "robust" M-estimators are thus shown to emerge directly from probabilistic foundations once thresholding (i.e., decision for inlier/outlier) is introduced. For example, MSAC is revealed to be the profile likelihood for a truncated Gaussian-uniform mixture model; a smoothly truncated version is derived for the marginal likelihood case. Crucially, all methods intrinsically depend on an inlier-outlier threshold, regardless of prior claims to the contrary.
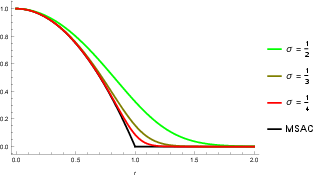
Figure 3: Comparison of MSAC and the smoothed (marginal) Gaussian-uniform score as a function of residual and threshold.
Iterative local improvement of model parameters—typically performed via IRLS or EM—is shown to be equivalent for the Gaussian-uniform scenario, and their convergence properties and weighting schemes are directly tied to the posterior inlier probability, unifying perspectives from robust statistics and expectation-maximization.
Derivation Errors and Numerical Equivalence
MAGSAC++ is widely acknowledged as the default SOTA scoring function in practice, but its underlying derivation is shown to contain pivotal errors. Specifically, it inappropriately assumes residuals themselves (not observations) are χν-distributed, which is only justifiable in restricted cases (e.g., known true point correspondences or special fitting cases). Residuals are instead dependent on the model and their distribution varies with the model parameters, leading to pathological behaviors such as the likelihood of the ground truth model vanishing.
Instead, the "scale-marginalized" form in MAGSAC++ yields, by accidental cancellation of errors, a function nearly identical to the marginal likelihood for the Gaussian-uniform mixture model with appropriate threshold scaling.
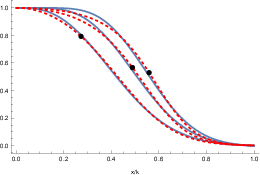
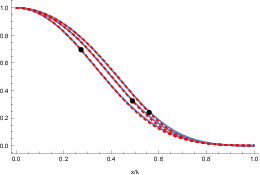
Figure 4: Left—MAGSAC++ normalized inlier weight for various ν and best-fit sigmoid posterior from the Gaussian-uniform mixture model; Right—the resulting normalized scoring functions.
This spectral equivalence demonstrates that MAGSAC++'s superior benchmark performance is not due to its modeling novelty or claimed theoretical advantages (like reduced sensitivity to threshold or better marginalization) but rather that it unintentionally mimics the threshold-parameterized, properly derived likelihood score.
Implications for Local Optimization and Scale
A further implication is that IRLS updates in MAGSAC++ (and preceding methods such as MLSAC) are well-justified only in the context of the Gaussian-uniform mixture with explicit thresholding. Claims of scale marginalization or improved sensitivity are not substantiated either by theory or numerical experiment.
Experimental Methodology: Isolating and Comparing Scoring Functions
To rigorously assess the merits of scoring functions, an experimental framework was constructed where scoring functions were compared in isolation, not as part of composite pipelines. This ensures that improvements are attributed to the scoring function itself, not to unrelated aspects such as minimal solver quality, local optimization, or result polishing stages.
Threshold Validation Protocols
Both large validation (to select optimal thresholds per method) and small random validation (to mimic real-world conditions of limited hyperparameter tuning data) are evaluated for robustness, statistical significance, and sensitivity. All evaluations are done across extensive datasets: homography estimation on HEB, relative pose estimation on PhotoTourism (including RootSIFT and learned feature correspondences), and the KITTI and LAMAR datasets.
The main empirical findings, confirmed across all settings, are:
- MAGSAC++ and the Gaussian-uniform marginal likelihood are numerically indistinguishable in all practical pipelines and do not outperform MSAC/MLESAC by any significant margin.
- All residual-based scoring functions (except basic RANSAC inlier-count) perform identically after threshold tuning, with similar sensitivity to threshold selection.
- No scoring function displays diminished sensitivity to threshold selection, contradicting previous claims.
- Learned additive inlier distributions ("ML" scores) offer no improvement whatsoever over engineered functions, and any perceived improvement stems from heavier tail fitting or cross-validation artifacts.
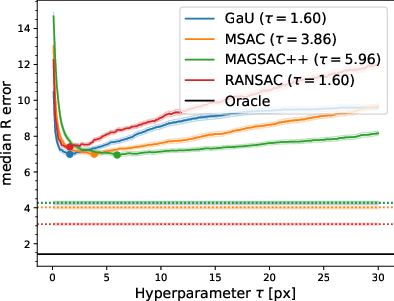
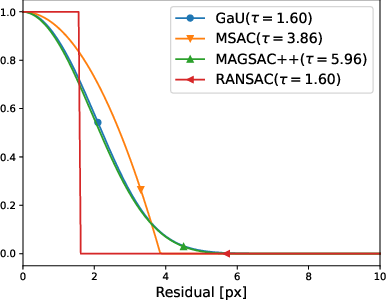
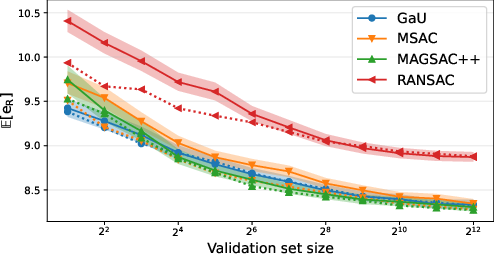
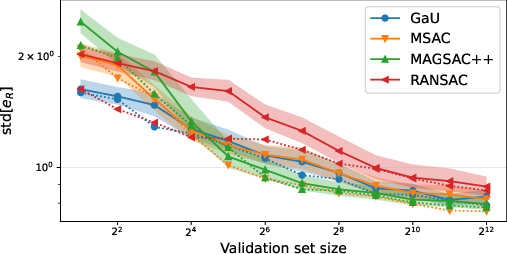
Figure 5: Validation error curves for HEB homography estimation; the curves for all robust scoring functions, including MAGSAC++ and Gaussian-uniform, are coincident at their respective optima.
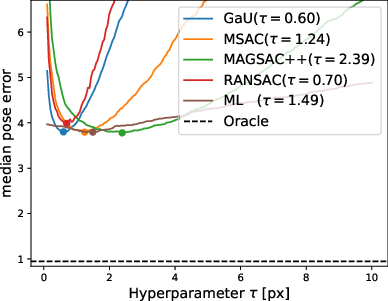
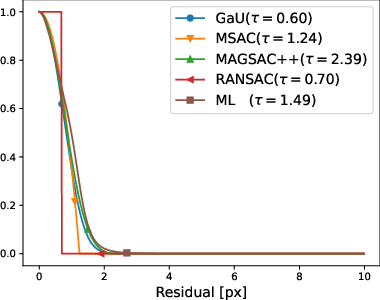
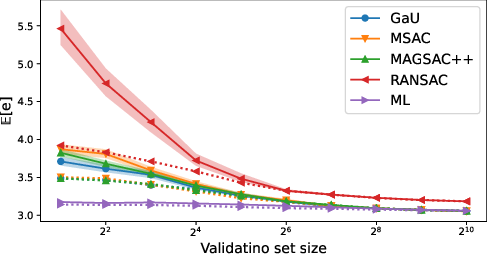
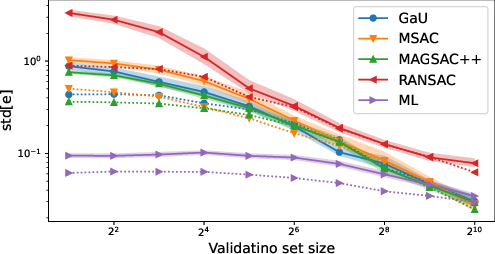
Figure 6: Distribution and variance of test error versus validation set size—demonstrating that all methods saturate to the same performance and exhibit similar threshold sensitivity.
Implications for Theory, Community, and Future AI Pipelines
The theoretical and empirical demystification presented here has several implications:
- RANSAC scoring function progress is not achieved by "more complex" marginalizations or learned functions unless one departs from residual additivity or the probabilistic mixture thresholding foundation. The consensus mechanism for inlier selection will remain fundamentally constrained by monotonicity and threshold sensitivity.
- Benchmark improvements ascribed to scoring functions (esp. MAGSAC++, MQNet) often actually derive from pipeline-level changes (e.g., post-processing, local optimization, or unreported data handling nuances). Isolated evaluation, as mandated here, must become standard.
- For practitioners, parameterization and interpretation are clarified. Gaussian-uniform marginal scoring yields interpretable weights, transparent threshold meaning, and natural EM/IRLS local update schemes—preferred for robustness and extensibility.
- Further improvement can only come from revisiting violated assumptions (e.g., allowing inlier scales to vary across correspondences, modeling descriptor dissimilarity directly, or leveraging non-additive, possibly learned, global quality scores) or combining geometry with image-based or scene-structural priors.
Conclusion
This work formalizes the relationship between probabilistic and robust statistics–based scoring in RANSAC, dismantles unfounded theoretical claims underlying SOTA methods, and experimentally demonstrates the equivalence of nearly all practical scoring functions after appropriate threshold adjustment. The methodology for score function comparison is itself of general purpose utility. These results reset expectations regarding what can be achieved with residual-additive scoring and redirect future research towards modeling innovations and domain-specific enhancements, rather than incremental scoring variants.
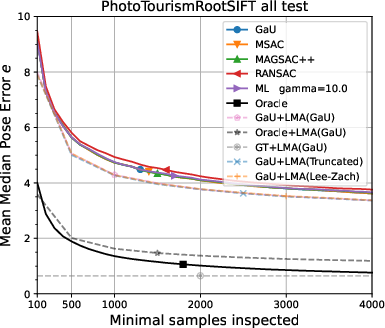
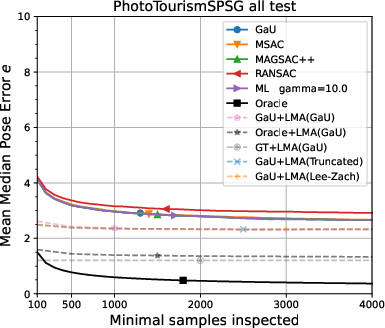
Figure 7: Selectivity of scores for different error axes; average scores decline monotonically for increased model-to-GT error along all tested axes, confirming internal consistency and the absence of systematic bias favoring inferior models.
(2512.19850)