How Much 3D Do Video Foundation Models Encode?
Abstract: Videos are continuous 2D projections of 3D worlds. After training on large video data, will global 3D understanding naturally emerge? We study this by quantifying the 3D understanding of existing Video Foundation Models (VidFMs) pretrained on vast video data. We propose the first model-agnostic framework that measures the 3D awareness of various VidFMs by estimating multiple 3D properties from their features via shallow read-outs. Our study presents meaningful findings regarding the 3D awareness of VidFMs on multiple axes. In particular, we show that state-of-the-art video generation models exhibit a strong understanding of 3D objects and scenes, despite not being trained on any 3D data. Such understanding can even surpass that of large expert models specifically trained for 3D tasks. Our findings, together with the 3D benchmarking of major VidFMs, provide valuable observations for building scalable 3D models.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-language summary of “How Much 3D Do Video Foundation Models Encode?”
What is this paper about?
This paper asks a simple question: if you train big AI models on tons of videos, do they naturally learn how the 3D world works—even if they were never given 3D data? The authors test this by “peeking inside” several powerful video models to see how much 3D understanding they already have.
What questions did the researchers try to answer?
The authors looked at four main questions:
- Extent: How good is the hidden 3D knowledge in video models compared to image models or special 3D models?
- Factors: What helps or hurts this 3D understanding? They test the effects of time (temporal reasoning), extra 3D training, and model size.
- Localization: Where inside the model is the 3D info strongest? Which layer and which moment in the model’s process?
- Implications: Can this hidden 3D knowledge actually help build better 3D tools when we don’t have much 3D training data?
How did they test it? (Methods in simple terms)
Think of a video model as a giant black box that turns video frames into “features,” like secret notes describing what’s in each frame. The researchers:
- Froze the big video models (they didn’t change them).
- Built a tiny “probe” model—a simple reader—to see if it could pull out 3D facts from those secret notes. This probe:
- Takes features from 4 frames of a video (the first frame and three others spaced out in time).
- Tries to predict:
- A point map: a 3D dot for each pixel, showing where that pixel is in the real world (like making a 3D scatter plot of the scene).
- Depth: how far each pixel is from the camera.
- Camera pose: where the camera is and how it’s turned for each frame.
- Only the small probe is trained; the big video model stays unchanged. If the probe does well with little training, it means the video model already “knows” a lot about 3D.
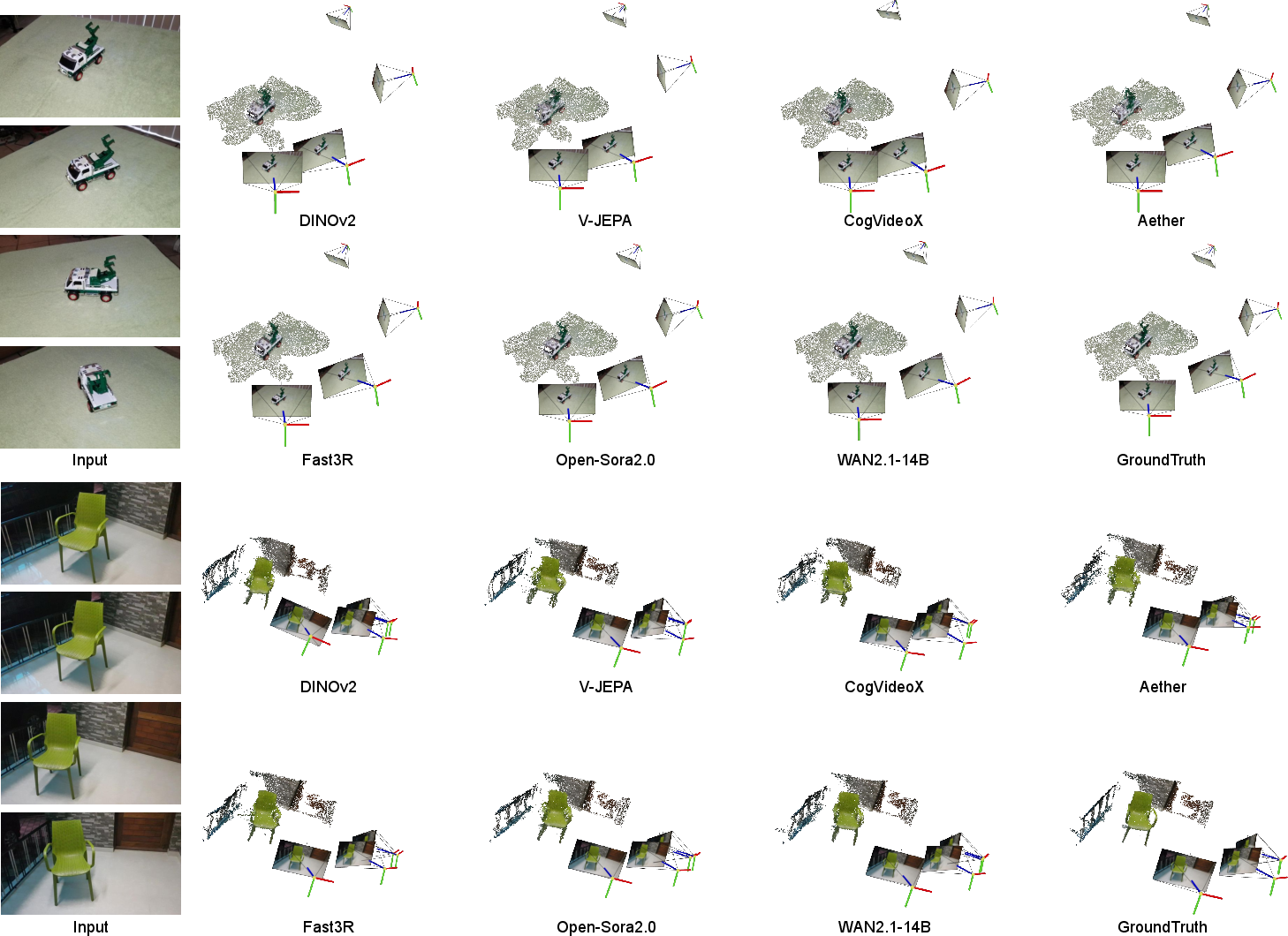
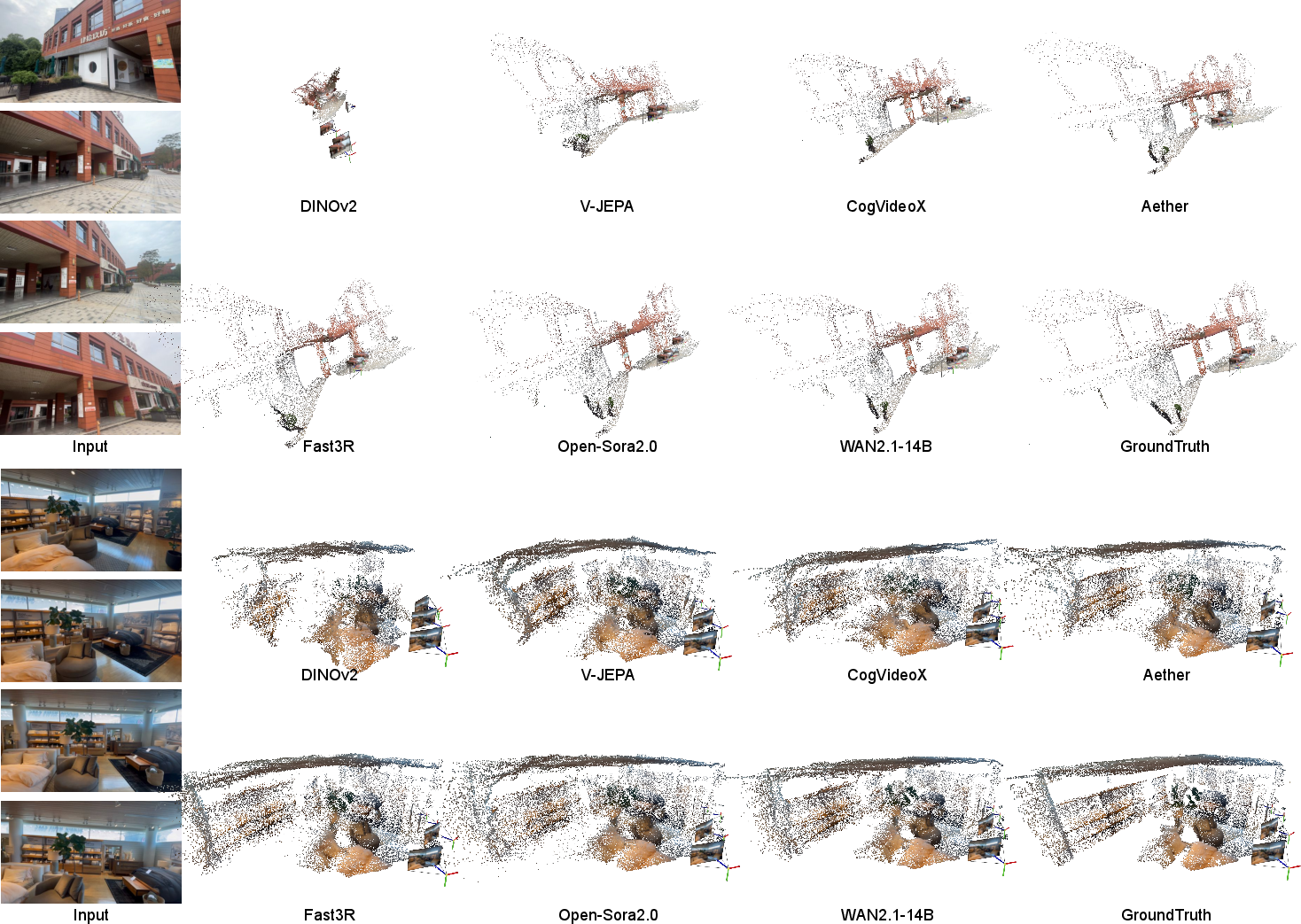
They tested many models, including:
- Strong video generators (models that make videos), like WAN and Open-Sora.
- A self-supervised video encoder (V-JEPA).
- Controls for context:
- An image model (DINOv2) that sees frames one by one without time.
- A specialized 3D model (Fast3R) trained directly on 3D tasks.
They evaluated on two datasets:
- CO3Dv2: mostly single objects turning on a table (clean and object-focused).
- DL3DV: big, messy, real-world scenes (harder).
To judge performance, they measured how accurate the predicted 3D points, depths, and camera positions were. You can think of it as checking how well the AI could “rebuild” the 3D scene from the video.
A quick note on diffusion models (many top video generators use them):
- These models create videos by removing noise in steps.
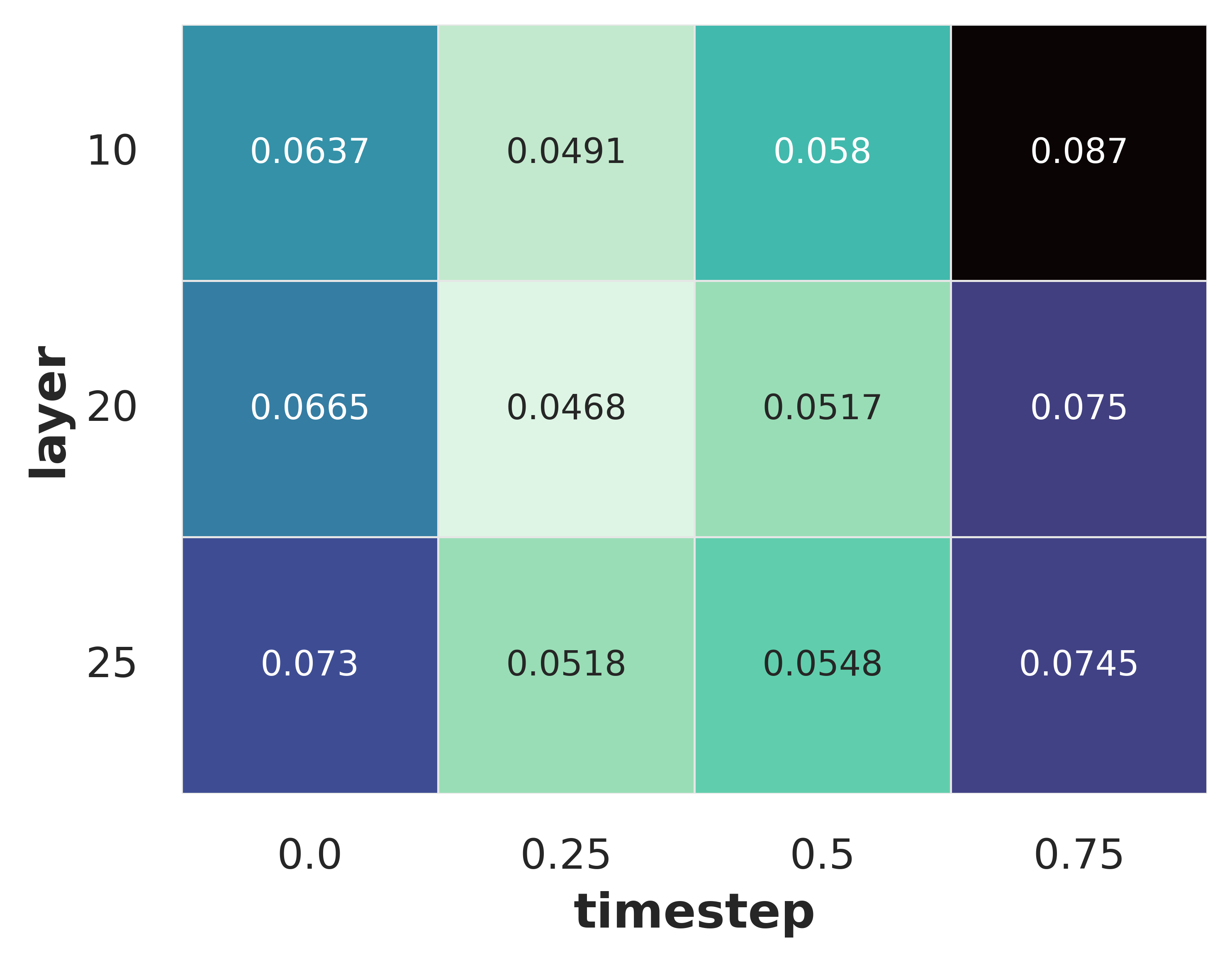
- The authors found it matters which step and which layer you pull features from. They tested different layers and time steps to find the sweet spot.
What did they find, and why does it matter?
Here are the key takeaways:
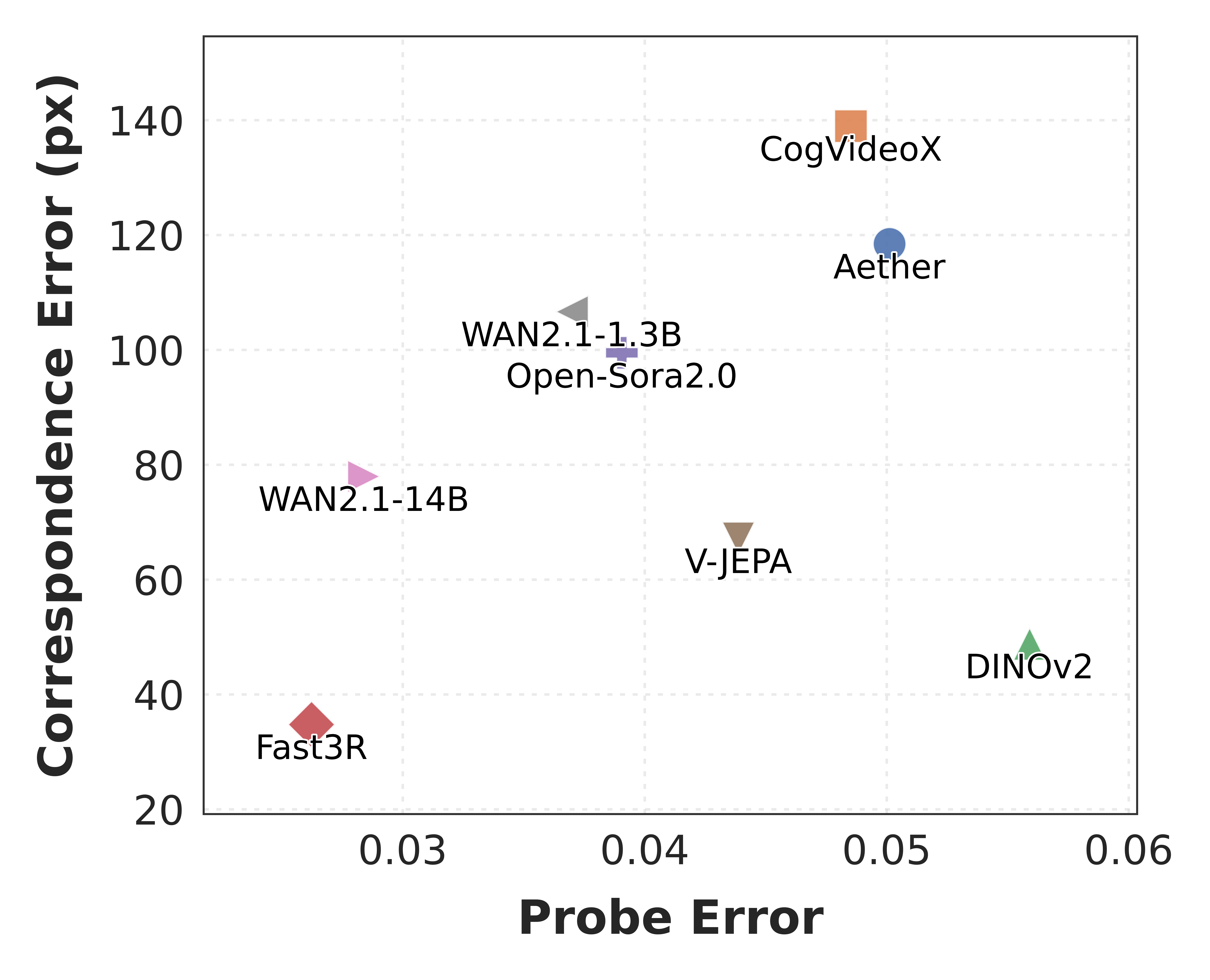
- Video generators “get” 3D surprisingly well. Top video models (like WAN and Open-Sora) showed strong 3D understanding—even beating a specialist 3D model on a challenging dataset. This is impressive because these video models were not trained on 3D labels.
- Time matters a lot. Models that can connect information across multiple frames (video models) learn global 3D structure much better than image-only models that see frames separately.
- Extra 3D fine-tuning is a mixed bag. Adding 3D objectives can help on similar data (in-domain) but may hurt generalization to different kinds of videos. In short: it can make the model “overfit” to one style of scenes.
- Bigger isn’t always better. Scaling up a model sometimes improves 3D understanding (as with WAN), but not always (one larger CogVideoX version did slightly worse). Data quality and training recipe also matter.
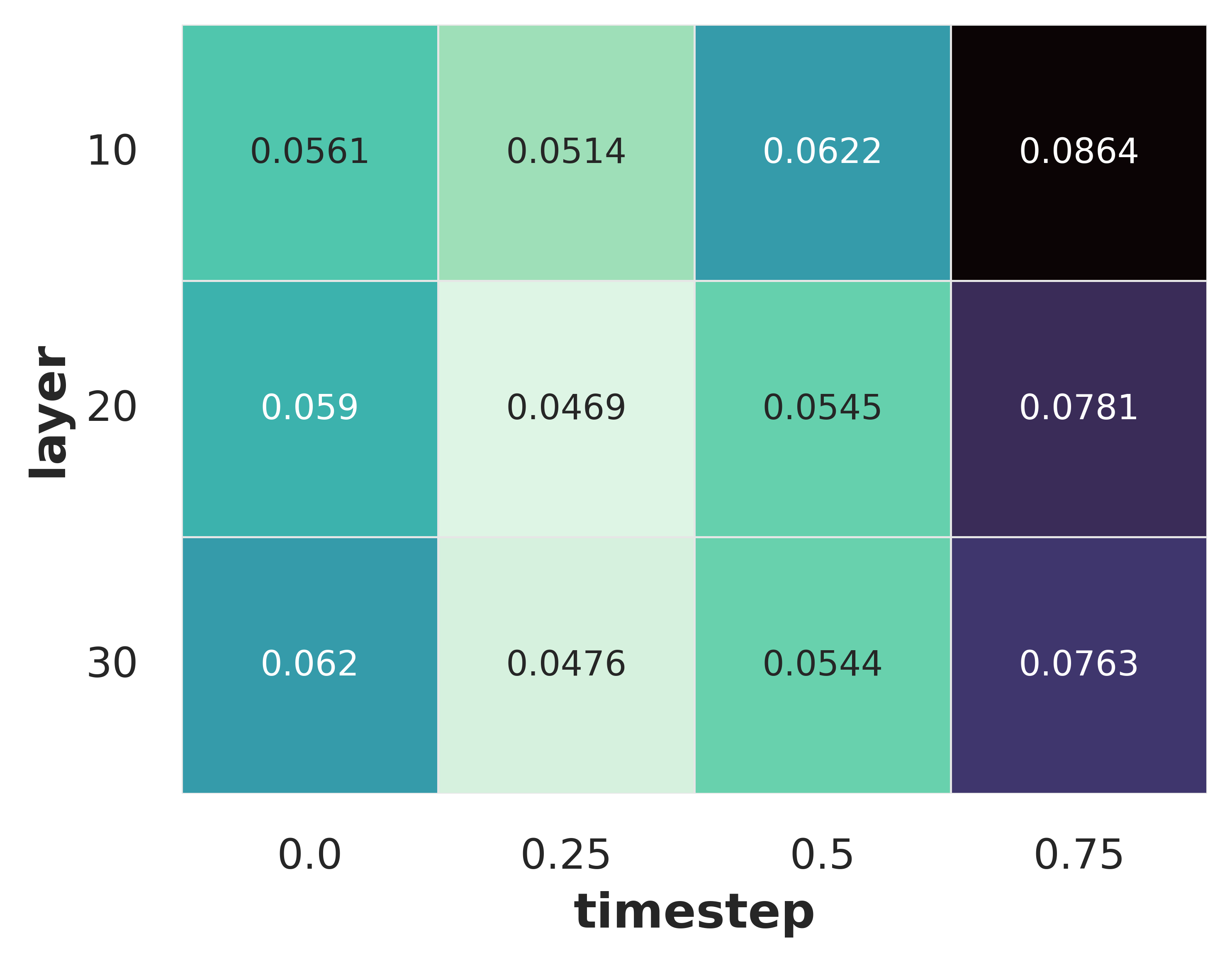
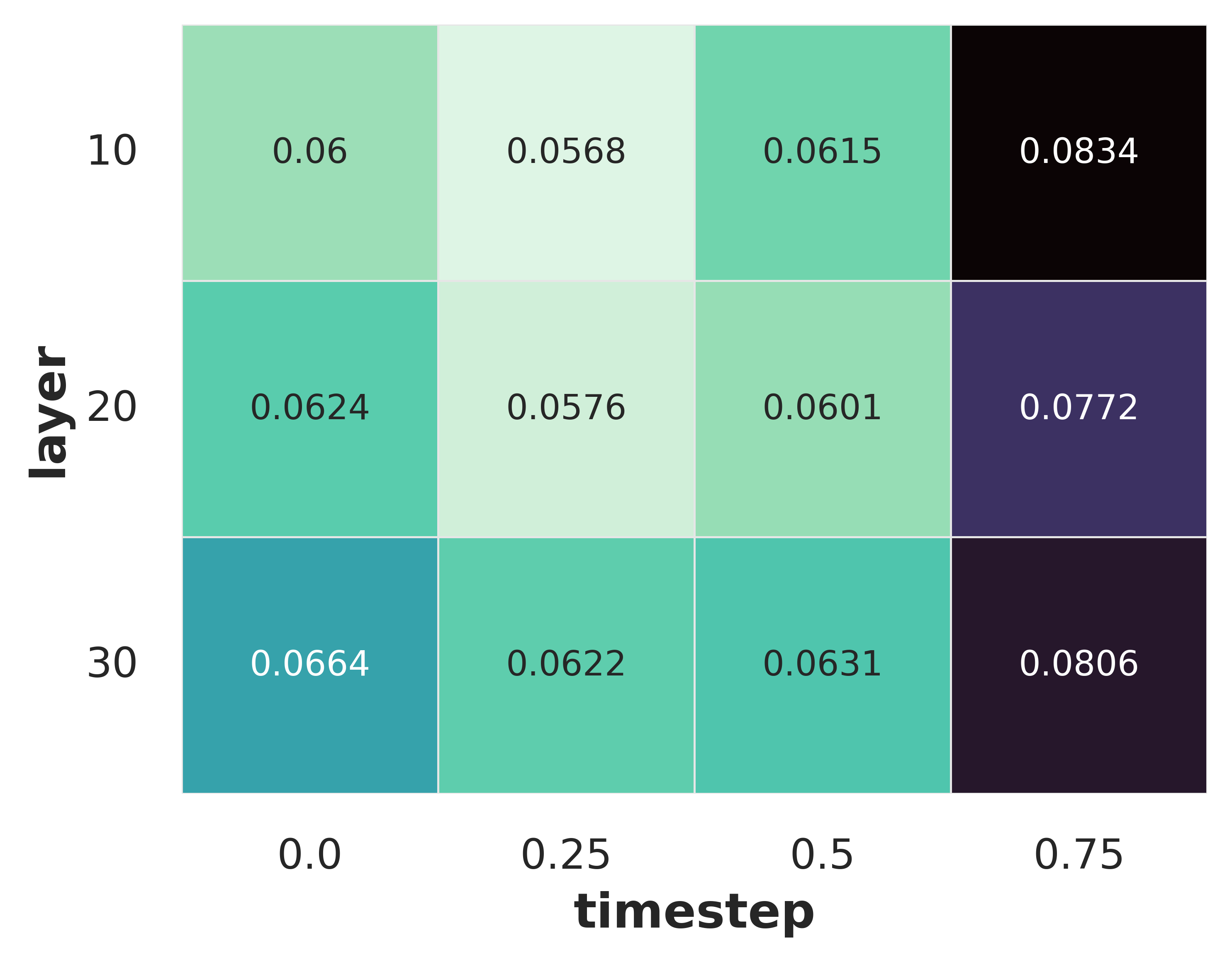
- Where is the 3D info hiding? The best features for 3D are found in the middle layers of the model and at early—but not the very first—denoising steps. Think “not too raw, not too polished.”
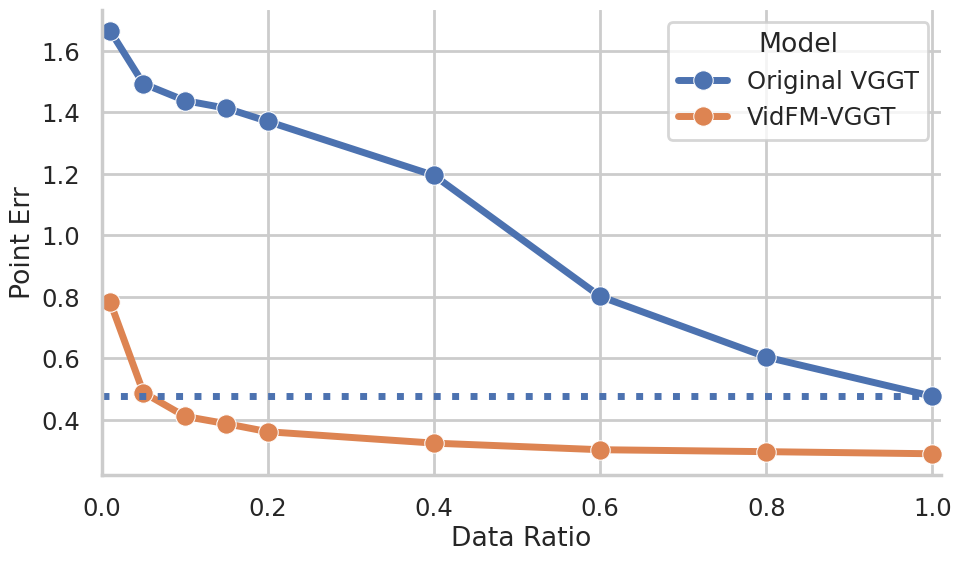
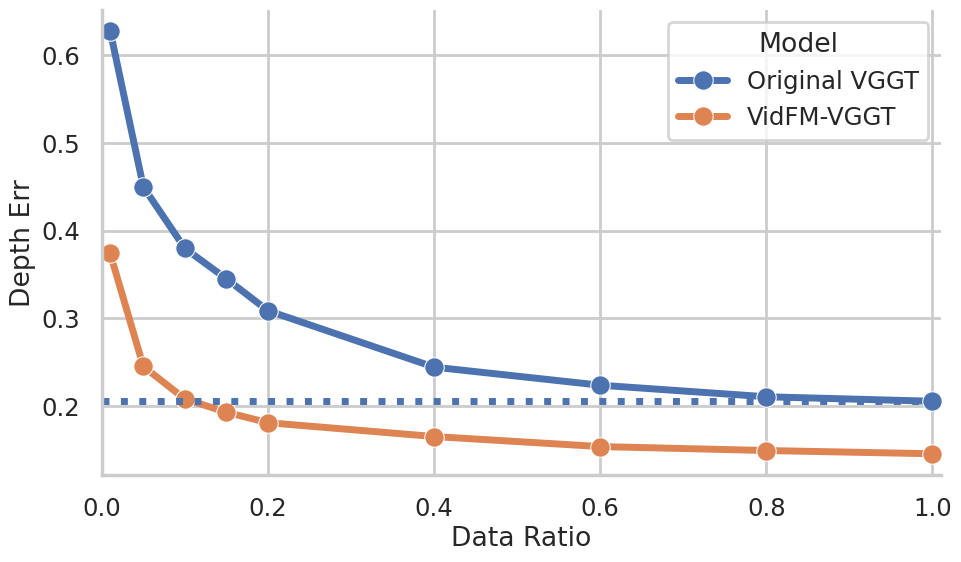
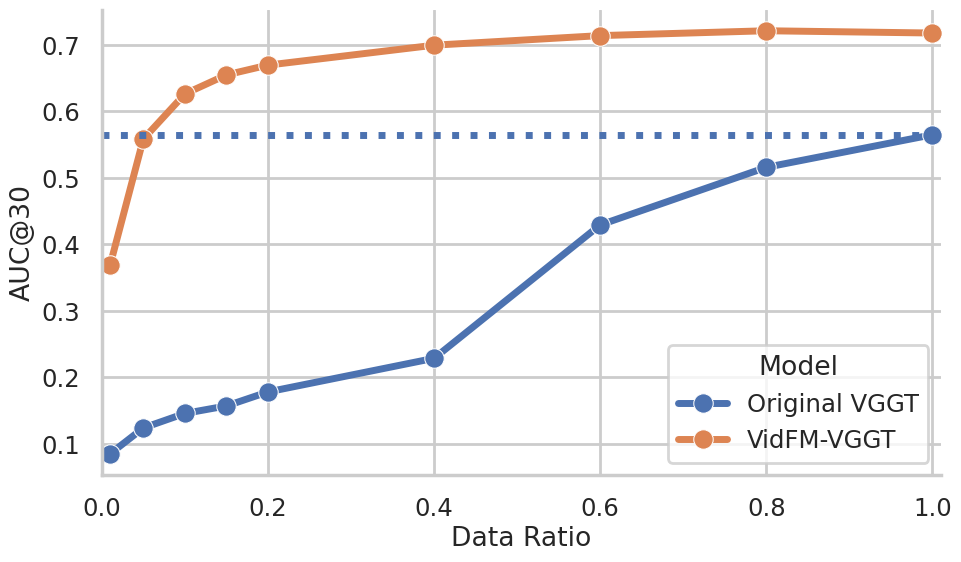
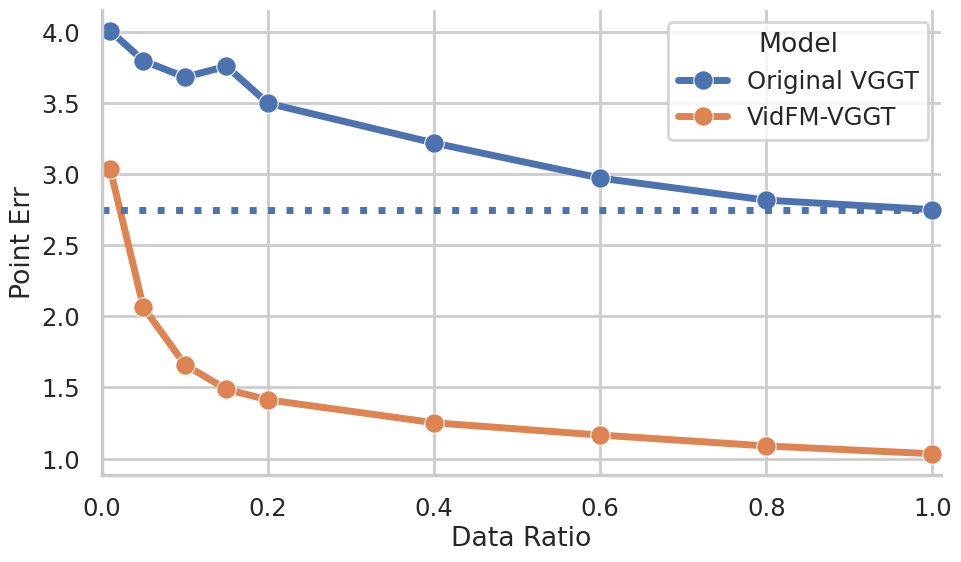
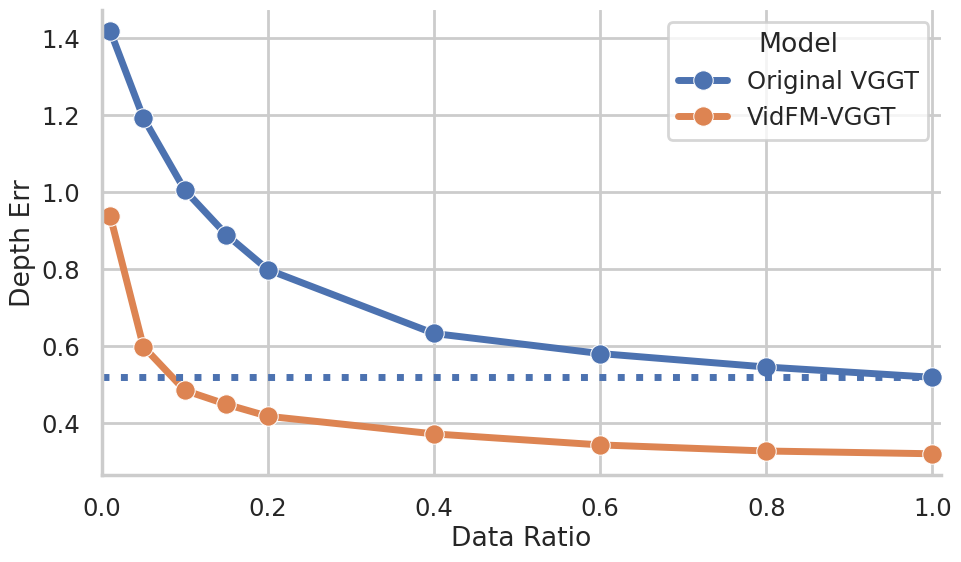
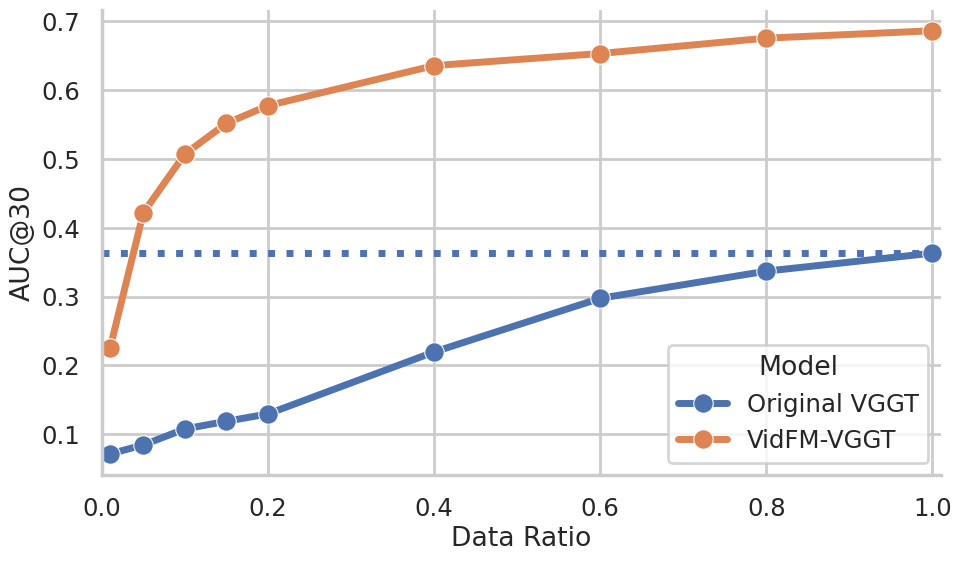
- Practical win: swapping features helps. When they replaced the usual image-based features in a popular 3D reconstructor (VGGT) with frozen features from a video model (WAN), the reconstructor got much better on both datasets—especially useful when 3D training data is limited.
Why is this important?
- Video is everywhere. It’s much easier to collect millions of videos than to collect accurate 3D scans. If video models naturally learn 3D, we can build strong 3D tools without needing tons of expensive 3D labels.
- Better AR/VR, robotics, and filmmaking. This could lead to more stable 3D reconstructions for augmented reality, safer robot navigation, and more realistic movie or game scenes.
- Smarter evaluation. The paper also provides a general way to measure 3D understanding in video models, which can guide future model design.
A quick note on limitations
The authors used publicly available models and didn’t retrain giant models from scratch, so not every variable (like training data scale) could be perfectly controlled. Still, the evidence across many models and tests is strong.
Bottom line
Big video models seem to learn a lot about 3D just from watching videos. With a small “reader” model, you can extract detailed 3D information—sometimes even better than expert 3D systems—without special 3D training. This opens a practical path to building powerful 3D tools using the abundance of video data we already have.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Dependence on VGGT-derived “ground truth”: All supervision and evaluation labels (points, depth, cameras) are generated by VGGT using all frames, not by high-fidelity sensors or photogrammetry pipelines. This risks biasing the probe toward VGGT-like targets and conflating errors due to VGGT with the VidFM features themselves. Future work: validate with metric ground truth (e.g., COLMAP with careful calibration, LiDAR, RGB-D) and report cross-label agreement.
- Scale and absolute pose are not evaluated: Point errors are computed after Umeyama similarity alignment (including scale), and pose metrics use only rotation and translation direction, not magnitude. This omits absolute scale and metric translation, which are critical for many 3D tasks. Future work: add scale-aware metrics (e.g., scale-consistent depth RMSE, absolute translation error), and evaluate intrinsics-aware reprojection errors.
- Limited data domains and scene types: Benchmarks focus on CO3Dv2 (object-centric turntables) and DL3DV (mostly static, cluttered scenes), missing dynamic scenes, handheld videos, moving objects, rolling shutter, motion blur, low light, and extreme occlusions. Future work: expand to dynamic, in-the-wild videos (e.g., smartphone benchmarks), and stress-test under adverse conditions.
- Readout capacity and fairness not isolated: Rankings may depend on the shallow VGGT-like probe’s design, capacity, and training protocol. There is no sensitivity analysis for probe depth/width, training set size, loss weights, or tokenization/feature preprocessing across models with different feature dimensionalities. Future work: systematically vary probe capacity and training regime, report robustness of model rankings to these choices.
- Temporal window limitations: Probing uses only S=4 frames with a minimum gap, and long videos are chunked with a shared first frame. This may artificially simplify relative pose estimation and underrepresent long-range temporal reasoning. Future work: measure performance vs. number of frames, sequence length, and baseline size; test without a shared reference frame; assess long-range consistency.
- Feature extraction confounds in diffusion models: Features are read via a DIFT-like single denoising step with fixed global timestep
τand selected mid-layer. Differences in noise schedules, layer semantics, and denoiser architectures across models are not controlled. Future work: compare multi-step denoising features, VAE encoder features vs. denoiser features, per-model timestep calibration, and alternative readout points (e.g., cross-attention blocks). - No analysis of text conditioning effects: Generative VidFMs are probed with empty text; the effect of informative prompts (scene/category cues) on 3D awareness is unexplored. Future work: quantify how textual conditioning modulates 3D features and whether prompt engineering can boost 3D readouts.
- Scaling confounded by data scale and training recipe: Observed size effects (e.g., WAN 14B vs. 1.3B; CogVideoX 2B vs. 5B) mix parameter count, training data quality/quantity, and training strategy. There are no controlled models where only data scale or only parameters vary. Future work: controlled ablations across matched data and training recipes to isolate causal factors.
- Limited breadth of VidFMs: The study focuses on latent diffusion generators and a single self-supervised encoder (V-JEPA). It omits other strong video encoders (e.g., VideoMAE, TimeSformer, Flamingo-like VLMs) and alternative generative families (autoregressive, rectified flow, masked modeling). Future work: broaden model families to test generality of findings.
- Incomplete layer/timestep localization: Only three layers and four timesteps are swept; mid-layer and early-but-not-first timestep emerge best, but without comprehensive coverage across blocks (e.g., attention vs. feedforward, cross-attention to text, skip connections) or model depth. Future work: fine-grained mapping of 3D information across all blocks and timesteps; causal interventions (ablations) to identify where 3D cues arise.
- Label efficiency and sample complexity not quantified: The claim that VidFM features help in limited 3D data regimes is shown at one data size. There is no curve of performance vs. training-set size or compute budget. Future work: report label-efficiency curves comparing VidFM vs. DINO features across probe sizes and datasets.
- Robustness to real-world artifacts untested: Sensitivity to compression, variable frame rates, resolution changes, lens distortion, rolling shutter, and sensor noise is not evaluated. Future work: controlled robustness suites spanning these artifacts.
- Task breadth limited to points, depth, and relative pose: Other 3D signals (surface normals, occupancy/TSDF, meshes, radiance fields), multi-view consistency beyond 4 frames, and downstream tasks (novel view synthesis, SLAM) are not assessed. Future work: extend probes and benchmarks to richer 3D targets and closed-loop applications.
- Potential advantage to feedforward-style 3D models: The probe architecture mirrors VGGT’s alternating attention; this could favor models whose features already support feedforward multi-view fusion. Future work: evaluate alternative probe designs (e.g., recurrent/epipolar-aware modules, graph-based multi-view modules) to check ranking stability.
- Per-frame image baseline may be overly weak: Only DINOv2 per-frame features are tested, with a simple reference-frame indicator. It does not include stronger multi-frame image baselines (e.g., DINOv2 + temporal aggregation, 2D feature tracking) that could reduce the gap attributed to “temporal reasoning.” Future work: add fair, temporally aggregated image baselines.
- Ambiguity about causal mechanisms of 3D emergence: The paper shows empirical 3D awareness but does not explain which architectural components (e.g., spatiotemporal attention, latent bottlenecks) or training signals (e.g., motion statistics, data diversity) induce it. Future work: use representational analyses (RSA, CKA), causal ablations, and synthetic datasets to isolate sources of 3D learning.
- No uncertainty estimates or statistical significance: Results are reported without error bars, confidence intervals, or significance testing across runs/seeds. Future work: include statistical testing and report variability to ensure reliable rankings.
- Computational cost and practicality of feature extraction: Reading denoiser features with noise injection incurs nontrivial compute/latency; the trade-offs vs. encoder-only features are unquantified. Future work: benchmark throughput, memory, and latency of feature extraction methods and their impact on downstream 3D pipelines.
- Generalization of VidFM-VGGT beyond small-data regimes: The VGGT variant with frozen WAN features is evaluated only on CO3Dv2/DL3DV; it is unclear whether benefits persist at larger scales or with end-to-end finetuning of VidFM backbones. Future work: test on larger 3D datasets and evaluate joint finetuning vs. frozen features.
- Chunking strategy and temporal consistency: For models with small context windows, videos are chunked and each chunk prepends the first frame. This may encourage consistent reference-frame alignment and inflate pose/point consistency. Future work: evaluate without chunking or without shared reference frames; test continuous sliding windows and longer contexts.
- Failure modes not deeply characterized: The qualitative note about boundary errors lacks quantitative analysis of where/why models fail (thin structures, specularities, textureless regions, wide baselines). Future work: stratified evaluation by scene attributes and controlled stress tests (e.g., synthetic ablations of texture/specularity).
- Prompt-to-geometry alignment not measured: For text-conditioned generators, whether textual semantics align with recovered 3D (e.g., “a tall chair” → taller geometry) is unknown. Future work: measure semantic-geometry consistency under controlled prompt manipulations.
Practical Applications
Immediate Applications
The following applications can be deployed using current video foundation models (VidFMs), the paper’s model-agnostic probe, and shallow readouts without fine-tuning the base video models. They leverage the finding that mid-layer, early-but-not-first diffusion timesteps encode strong, globally consistent 3D features.
- VidFM-augmented feedforward 3D reconstruction (software; robotics; AR/VR; mapping)
- Use frozen features from strong open-weight video generators (e.g., WAN2.1-14B, Open-Sora2.0) to drive a shallow VGGT-like probe for dense point maps, depth, and camera poses from casual video clips.
- Tool/product: “VidFM-3D Recon SDK” that wraps feature extraction (DIFT-style) and a lightweight alternating-attention probe; export meshes, point clouds, and camera trajectories.
- Workflow: capture 4+ frames (with ≥5-frame gaps) from a video; extract mid-layer features at early timesteps; run the probe to output 3D points/depth/poses; align/scale with Umeyama; post-process to mesh.
- Assumptions/dependencies: access to open-weight VidFMs and GPU inference; adherence to recommended layer/timestep settings; limited 3D supervision (can be bootstrapped via VGGT pseudo-GT); licensing terms for model use.
- Low-cost 3D content ingestion for e-commerce and marketplaces (retail; media/entertainment)
- Turn seller-uploaded videos into 3D product models with camera poses, enabling 360 viewers, AR try-ons, and dimension checks without specialized scanners.
- Tool/product: Shopify/Adobe plugin that converts short turntable-type product videos to point clouds/meshes using the probe.
- Assumptions/dependencies: object-centric footage (CO3Dv2-like); sufficient texture/lighting; device capture consistency; simple calibration optional.
- Real estate and facilities visualization from listing or walkthrough videos (AEC; real estate; digital twins)
- Produce floor-level 3D point clouds and camera trajectories from handheld walkthroughs; assist in space planning, virtual staging, and measurement.
- Tool/product: “Listing-to-3D” API integrated into MLS platforms; exports aligned point clouds and poses for downstream meshing.
- Assumptions/dependencies: indoor scenes resemble DL3DV-style; stable ego-motion; sufficient overlap; post-processing for scale (e.g., known door height).
- Drone and handheld inspection for infrastructure (energy; utilities; telecom; manufacturing)
- Generate 3D structure estimates from inspection videos (towers, pipelines, factories) for anomaly detection and maintenance planning.
- Tool/product: Recon module embedded in inspection software to quickly reconstruct geometry from video with minimal 3D data.
- Assumptions/dependencies: domain generalization is strong for large scenes (as observed on DL3DV), but textureless/repetitive regions still challenging; safety/regulatory constraints for data collection.
- Fast SLAM-lite for monocular streams (robotics; autonomous systems)
- Use VidFM features plus the probe to estimate camera poses and sparse geometry in real time-ish for navigation in structured environments.
- Workflow: run frozen VidFM on incoming frames; tap mid-layer features; predict pose/points; fuse across time; apply filtering for drift.
- Assumptions/dependencies: GPU edge compute; latency depends on VidFM size; pose accuracy thresholding (AUC@5/AUC@30) meets task needs; dynamic scenes may degrade performance.
- 3D-aware video editing and compositing (media/entertainment; VFX)
- Extract camera trajectories and coarse geometry from raw footage for matchmoving, set extension, and virtual production.
- Tool/product: NLE/VFX plugin that provides 3D camera solves and scene point clouds from frames via the probe; improves over purely 2D trackers.
- Assumptions/dependencies: feature quality from selected layers/timesteps; integration with Nuke/After Effects; scene normalization and alignment.
- Benchmarking and audit of 3D consistency in internal video models (academia; software; platform teams)
- Apply the paper’s model-agnostic 3D awareness benchmark (point/depth/pose errors, AUC@5/30) to evaluate proprietary VidFMs and guide layer/timestep selection.
- Tool/product: “3D Awareness Audit” harness to test new checkpoints and track impact of training data, temporal modules, and fine-tuning choices.
- Assumptions/dependencies: access to internal activations; standardized evaluation data; consistency in probe capacity and training schedules.
- Data-efficient 3D bootstrapping for small labs/teams (academia; startups)
- Replace DINO features with VidFM features in feedforward 3D pipelines to improve reconstruction on limited 3D datasets (as demonstrated vs. VGGT baseline).
- Workflow: swap backbone to frozen VidFM, keep a shallow probe; generate pseudo-GT with VGGT or small curated GT; train to convergence under matched compute.
- Assumptions/dependencies: reproducibility of the probe architecture; compute parity; awareness of domain gaps from fine-tuned generative models.
- Camera pose analytics for sports and industrial video (sports tech; quality assurance)
- Rapidly compute camera motion for stabilization, replay synthesis, and motion-aware analytics.
- Tool/product: pose-only readout head service exporting rotation/translation with AUC thresholds for quality flags.
- Assumptions/dependencies: sufficient parallax; non-degenerate motion; scaling and alignment for cross-scene comparisons.
Long-Term Applications
These opportunities require additional research, scaling, or productization—especially around domain generalization, dynamic scenes, compute efficiency, and standards.
- 3D-consistent video generation and editing with explicit geometry control (media/entertainment; software)
- Integrate the probe-style readouts or 3D-aware training signals to enforce geometry/pose consistency during generation, reducing 3D artifacts and drift.
- Product: “3D-stable Video Diffusion” that outputs both frames and geometry caches (depth/points/cameras) for downstream applications.
- Dependencies: robust multi-domain generalization; avoiding overfitting from 3D fine-tuning (observed trade-offs); efficient joint optimization of RGB and 3D heads.
- Universal video-to-asset pipeline for digital twins (smart cities; manufacturing; construction)
- Convert operational video streams (CCTV, mobile, drones) into continuously updated 3D world models for monitoring and simulation.
- Product: city/factory-scale digital twin systems with automated video ingestion, geometry updating, and versioning.
- Dependencies: scalable data handling; temporal fusion across long horizons (many models have short context windows today); privacy/compliance.
- Foundation-level 3D world models trained largely from video (academia; robotics; AR/VR)
- Leverage the paper’s evidence that VidFMs encode strong 3D priors to build large-scale 3D models primarily from video data, reducing reliance on scarce 3D annotations.
- Product: “Video-first 3D FM” with powerful temporal reasoning and emergent geometry; downstream APIs for SLAM, reconstruction, and planning.
- Dependencies: access to massive diverse video corpora; compute; controlled studies to isolate data vs. architecture effects; benchmarks and standards.
- Cross-domain 3D-aware robotics perception (autonomy; logistics)
- Deploy VidFM-based geometry and pose estimation in dynamic and cluttered environments (warehouses, urban streets), enabling robust planning without LiDAR.
- Product: monocular 3D perception stack enhanced by VidFM features for resource-constrained robots.
- Dependencies: dynamic scene handling (moving objects, occlusions); real-time performance; reliability and certification.
- Medical 3D reconstruction from endoscopic and surgical videos (healthcare)
- Infer 3D structure and camera motion in minimally invasive procedures for navigation, tool tracking, and documentation.
- Product: surgical navigation aids that recover geometry from monocular scopes.
- Dependencies: domain shift from natural to medical imagery; safety/regulatory validation; texture/lighting variability; robustness to specularities and fluids.
- Standards and policy for 3D consistency benchmarking of generative video models (policy; standards bodies; platform governance)
- Establish model-agnostic, geometry-aware metrics (point/depth/pose errors; AUC thresholds) as industry standards for 3D consistency.
- Outcome: procurement guidelines and compliance checks for vendors providing video generation or perception capabilities.
- Dependencies: open benchmarks and reference implementations; consensus on data splits; reporting practices.
- Automated 3D dataset curation and augmentation from video (academia; data ops; software)
- Use VidFM-3D probes to pre-label video collections with geometry/poses, easing the creation of training sets for downstream 3D tasks.
- Product: data pipelines that turn video archives into rich multi-view 3D datasets with confidence-weighted annotations.
- Dependencies: quality thresholds; de-biasing across domains; storage and compute costs; legal permissions for dataset transformation.
- Consumer-grade mobile 3D capture without depth sensors (daily life; creator economy)
- Commodity apps that turn phone videos into 3D models for sharing, printing, and AR scenes, relying on VidFM features rather than dedicated hardware.
- Product: “Video-to-3D” mobile app with on-device or cloud inference; instant AR exports.
- Dependencies: optimized, smaller VidFMs or distillation for mobile; energy efficiency; privacy-by-design; variable capture quality.
- Financial and insurance valuation from video (finance; insurance; proptech)
- Estimate geometry/volumes and camera trajectories from claim or listing videos to assist appraisal, risk assessment, and fraud analysis.
- Product: valuation tools that consume consumer or agent-captured footage and output measurable 3D assets.
- Dependencies: calibration/scale estimation; standardized capture protocols; regulatory acceptance and auditability.
Cross-cutting assumptions and dependencies
- Access and licensing: open-weight VidFMs (WAN2.1-14B, Open-Sora2.0) and legal rights to extract internal features; compliance with model licenses and data privacy.
- Compute and latency: large VidFMs are costly; immediate deployments may require model pruning/distillation; chunked processing for long videos due to context window limits.
- Domain generalization: 3D fine-tuning can improve in-domain performance but harm out-of-domain generalization; careful data selection and regularization are needed.
- Feature extraction choices: mid-network layers and early-but-not-first timesteps consistently yield the strongest 3D awareness; deviating may reduce quality.
- Scene constraints: textureless regions, repetitive patterns, dynamic objects remain challenging; post-processing and multi-view fusion help.
- Scale alignment: outputs are up-to-scale (scene normalization is used); real-world measurements require additional cues (known object dimensions, sensor fusion).
- Evaluation and quality control: use the paper’s metrics (point/depth errors, AUC@5/AUC@30) to set acceptance thresholds and monitor drift across domains and updates.
Glossary
- 3D awareness: The degree to which 3D structure and motion can be recovered from model features without fine-tuning. "We present the first model-agnostic framework to probe the 3D awareness of video foundation models (VidFMs) pretrained on large-scale video data."
- 3D caches/estimations: Auxiliary 3D outputs (e.g., geometry or depth) produced alongside video generation. "or by producing 3D caches/estimations~\cite{team2025aether,lu2025matrix3d,zhang2025world,huang2025jog3r,mai2025can,jiang2025geo4d,yu2024viewcrafter,gu2025diffusion,ren2025gen3c,huang2025voyager,wu2025video,liang2024wonderland,zhang2025spatialcrafter} along with the original frame synthesis target."
- 3D-inconsistency artifacts: Visual errors where generated frames are not geometrically consistent across views or time. "These works suggest that video priors are useful for 3D, but 3D-inconsistency artifacts, the requirement of 3D fine-tuning, and task-specific engineering leave it unclear whether video data alone can induce strong 3D awareness in a general-purpose setting."
- AUC@Θ: Area under the joint accuracy curve for pose errors up to angle Θ, requiring rotation and translation to be within the threshold simultaneously. "Following~\cite{wang2025vggt}, we report , the area under this joint accuracy curve as sweeps from to (e.g., )."
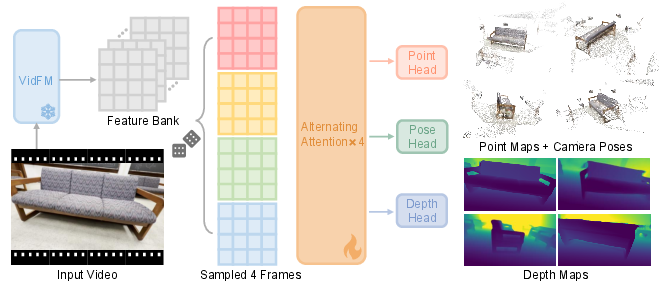
- alternating-attention: A transformer pattern alternating between per-frame and cross-frame attention to mix spatial-temporal tokens. "consisting of four alternating-attention layers and three read-out heads"
- Dense Prediction Transformer (DPT) head: A transformer-based head for dense per-pixel predictions like depth or point maps. "Two DPT heads produce dense point maps"
- denoiser: The component in diffusion models that iteratively removes noise from latent representations. "and a denoiser that denoises the latents."
- denoising timestep: The diffusion step index determining the noise level during feature extraction or generation. "we choose a denoising timestep , add noise, perform a single denoising step"
- DIFT: A technique for extracting features from diffusion models by reading hidden activations after a denoising step. "For diffusion-based video generators, we extract features similar to DIFT~\cite{tang2023emergent}"
- ego-motion: The camera’s own motion relative to the scene, recoverable from video. "We ask whether VidFMs develop internal representations of 3D structure and ego-motion"
- explicit 3D memory: A mechanism that stores 3D information explicitly to improve cross-view consistency during generation. "1) explicit 3D memory~\cite{yu2024viewcrafter,gu2025diffusion,ren2025gen3c,huang2025voyager,wu2025video};"
- geodesic angle on SO(3): The minimal rotation angle between two orientations measured on the rotation group . "rotation error is the geodesic angle on ,"
- Huber loss: A robust regression loss that is less sensitive to outliers, used here for camera pose training. "For camera poses, we use a Huber loss between the predicted poses and groundtruth poses."
- latent diffusion models: Generative models that denoise in a latent space (compressed representation) rather than pixel space. "All generative models here are latent diffusion models, which consist of a VAE that maps between raw videos and latents, and a denoiser that denoises the latents."
- model-agnostic framework: An evaluation or probing setup that applies across different architectures without modifying them. "we present the first model-agnostic framework to probe the 3D awareness of video foundation models (VidFMs) pretrained on large-scale video data."
- Multi-view Stereo (MVS): A classical method that reconstructs 3D structure from multiple calibrated images via dense matching. "Multi-view Stereo (MVS)~\cite{furukawa2015multi} techniques."
- point map: A dense per-pixel map of 3D coordinates (points) in a chosen reference frame. "a dense 3D point map that represents the 3D coordinates of visible pixels in the coordinate system of the first frame"
- post 3D optimization: Optimization procedures applied after generation to enforce 3D consistency or improve geometry. "2) post 3D optimization~\cite{sun2024dimensionx,liu2024reconx,chen2024v3d};"
- probe model: A lightweight network trained on frozen features to read out specific properties (e.g., 3D points, depth, camera poses). "Our probe model consists of a shallow transformer and three readout heads."
- readout head: A decoder module that outputs a specific target (e.g., depth, point map, camera pose) from shared features. "three readout heads."
- reference-frame indicator token: A special token marking the reference (first) frame to make multi-frame tasks well-posed. "we append a reference-frame indicator token that marks the first frame;"
- scale ambiguity: The inherent inability to determine absolute scale from monocular visual inputs without additional cues. "normalized before loss calculation to remove scale ambiguity."
- Structure from Motion (SfM): A pipeline that estimates 3D structure and camera motion from image sequences via feature matching. "Structure from Motion (SfM)~\cite{hartley2003multiple,schoenberger2016sfm,ozyecsil2017survey}"
- temporal reasoning: The capability of models to integrate information across time for coherent understanding (e.g., 3D). "Temporal reasoning is critical to the formation of global 3D understanding;"
- Umeyama algorithm: A method for estimating the similarity transform (rotation, translation, scale) that aligns two point sets. "align the predicted and ground-truth point clouds with the Umeyama algorithm~\cite{umeyama2002least},"
- Variational Autoencoder (VAE): A generative model component that encodes data into a latent distribution and decodes back to the data domain. "a VAE that maps between raw videos and latents"
- VGGT: A feedforward transformer model for multi-view 3D reconstruction and camera pose estimation. "We run VGGT~\cite{wang2025vggt} to generate ground truth for every frame: dense point maps, depth, and camera poses."
- video foundation models (VidFMs): Large video-trained models with broad capabilities and transferable representations. "Video foundation models (VidFMs) are deep models trained on massive video data that achieve strong performance across various downstream tasks."
- V-JEPA: A self-supervised video encoder trained with joint-embedding predictive objectives. "For self-supervised models, we evaluate V-JEPA~\cite{bardes2023v}, a large self-supervised video encoder."
Collections
Sign up for free to add this paper to one or more collections.