SpatialTree: How Spatial Abilities Branch Out in MLLMs
Abstract: Cognitive science suggests that spatial ability develops progressively-from perception to reasoning and interaction. Yet in multimodal LLMs (MLLMs), this hierarchy remains poorly understood, as most studies focus on a narrow set of tasks. We introduce SpatialTree, a cognitive-science-inspired hierarchy that organizes spatial abilities into four levels: low-level perception (L1), mental mapping (L2), simulation (L3), and agentic competence (L4). Based on this taxonomy, we construct the first capability-centric hierarchical benchmark, thoroughly evaluating mainstream MLLMs across 27 sub-abilities. The evaluation results reveal a clear structure: L1 skills are largely orthogonal, whereas higher-level skills are strongly correlated, indicating increasing interdependency. Through targeted supervised fine-tuning, we uncover a surprising transfer dynamic-negative transfer within L1, but strong cross-level transfer from low- to high-level abilities with notable synergy. Finally, we explore how to improve the entire hierarchy. We find that naive RL that encourages extensive "thinking" is unreliable: it helps complex reasoning but hurts intuitive perception. We propose a simple auto-think strategy that suppresses unnecessary deliberation, enabling RL to consistently improve performance across all levels. By building SpatialTree, we provide a proof-of-concept framework for understanding and systematically scaling spatial abilities in MLLMs.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in plain language)
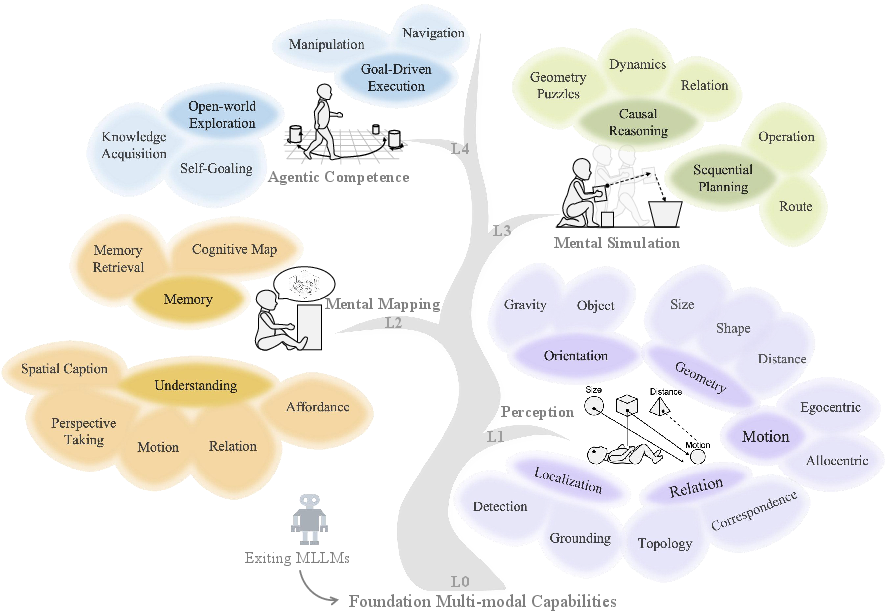
This paper is about teaching and testing AI models that can both see and read (called multimodal LLMs, or MLLMs) to be smart about space. “Space” here means things like how big objects are, how far away they are, where they are, how they move, and how to use that information to plan and act. The authors build a “SpatialTree,” a simple step-by-step ladder of skills that starts with seeing and ends with acting, and they create a big test to see how well different AIs do at each step.
Think of it like learning to drive: first you judge distances and sizes (perception), then you describe where things are (mapping), then you plan routes (simulation), and finally you actually drive and turn the wheel (acting).
What questions did the researchers ask?
They mainly asked:
- Can we organize “spatial smarts” into a clear set of levels, from basic seeing to real-world acting?
- How do these levels depend on each other? Do strong basics help with advanced skills?
- What kinds of training help or hurt these skills? For example, does making a model “think out loud” help with everything, or only some parts?
How they studied it (the approach, explained simply)
First, they built a four-level “SpatialTree” of abilities. Each level builds on the one below it:
- Level 1: Perception (L1)
- The model senses basic facts from images or videos: size, distance, shape, motion, orientation (which way is up), where objects are, and how they relate (inside/outside, left/right).
- Level 2: Mental Mapping (L2)
- The model connects what it sees to language: describing scenes in words, understanding action words, taking other viewpoints, noticing what objects can be used for (affordances), and building a simple “mental map” to remember where things are.
- Level 3: Mental Simulation (L3)
- The model imagines what will happen next and plans steps: if I push this, will it fall? How do I get from here to there? It’s like mentally running a mini-simulator.
- Level 4: Agentic Competence (L4)
- The model turns plans into actions: navigating a character in a game, telling a robot arm how to move, or choosing where to go next in a video of the real world.
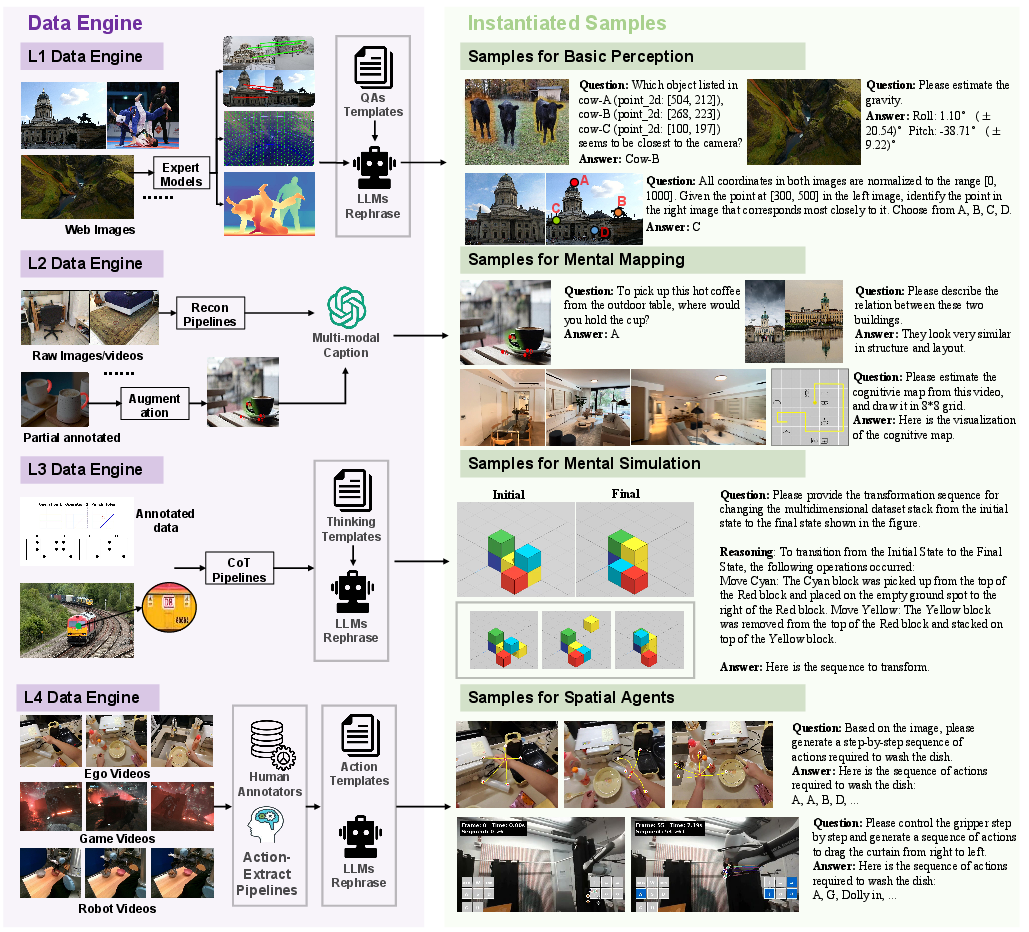
Then they built a big benchmark (a set of tests) covering 27 specific skills across these four levels. They pulled together and cleaned many existing datasets, added missing pieces, and created new tasks—especially for the acting level (L4). Tasks included multiple-choice questions, number estimates (like distance), and action choices for agents. They tested many popular models (both open-source and commercial).
Finally, they ran training experiments:
- Supervised fine-tuning (SFT): teaching a model with examples of the “right” answers for specific skills like distance or size.
- Reinforcement Learning (RL): rewarding the model when it gets tasks right. They tried “think a lot” training (encouraging step-by-step explanations) and a new “auto-think” approach that only encourages thinking when it’s useful.
They also checked how skills relate using simple statistics: if a model is good at skill A, is it also good at skill B?
The main findings (what they discovered and why it matters)
Here are the big takeaways:
- Basic skills are separate, advanced skills depend on each other.
- L1 (perception) abilities like distance, size, and motion don’t strongly move together—being great at one doesn’t guarantee being great at another.
- L3 and L4 (reasoning and acting) are strongly linked—if you’re good at one complex skill, you’re often good at others. Advanced tasks rely on combining several basics.
- Training one basic skill can hurt other basics but help advanced tasks.
- Teaching only “distance” or only “size” sometimes makes other L1 skills worse (negative transfer).
- But surprisingly, it can still make L3/L4 tasks better. In other words, stronger basics can boost higher-level performance even if they conflict with other basics.
- Training multiple basics together leads to synergy. Combining distance + size + correspondence helps more than training each alone, and even fixes some earlier drops.
- “Thinking a lot” isn’t always good.
- For complex reasoning and planning, encouraging the model to think step-by-step helps.
- For fast, intuitive perception (like estimating distance), overthinking makes things worse. It’s like overanalyzing when you just need a quick glance.
- A simple fix: auto-think.
- The authors propose an “auto-think” strategy: don’t force long explanations for quick perception tasks, but do encourage them for complex planning. With this, reinforcement learning improved results across all levels more consistently.
- Model performance snapshot.
- The strongest commercial “thinking” models did best overall, but the best open-source models were competitive and improving.
Why this research matters (the bigger picture)
- It gives a clear roadmap for building spatially smart AI.
- Train and test AI step by step, from seeing to acting, instead of mixing everything and hoping it works.
- Use multi-skill training at the basic level to avoid conflicts and unlock synergy.
- Control when the model should “think out loud” and when it should rely on fast, intuitive perception.
- It helps make better real-world agents.
- Robots that can grasp objects, navigate rooms, or help people.
- Game agents that plan and act intelligently.
- AR/VR assistants that understand where things are and what you can do with them.
- It offers a shared benchmark.
- Researchers can compare models fairly, find weak spots, and know what to improve next.
A simple way to picture it
Learning spatial intelligence is like learning to drive:
- L1: You quickly judge distance, size, and motion around you.
- L2: You describe routes and remember landmarks.
- L3: You plan the best path and predict what other cars will do.
- L4: You actually drive smoothly and safely. If you overthink when parallel parking, you might do worse. But for planning a long trip, careful thinking helps. The key is knowing when to think hard and when to act fast.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or left unexplored in the paper—phrased concretely so future work can act on it:
- L4 agentic competence is evaluated offline via discretized key–mouse primitives and multi-step MCQs; there is no closed-loop execution in simulators or real environments with measurable task success, recovery, and safety. Develop standardized interactive environments with executable action APIs and run-time feedback to assess end-to-end performance.
- The “auto-think” strategy is described qualitatively (suppressing unnecessary deliberation, length penalties) but lacks a formal decision policy or gating mechanism specifying when to think vs. act intuitively. Define and test adaptive gating (e.g., confidence-based, task-type classifiers, uncertainty thresholds).
- Pearson correlation analysis is observational and confounded by model family and scale; no controlled experiments isolate causal dependencies among abilities. Perform randomized ablations (e.g., keep model constant while varying single ability data) and use causal inference or Shapley value analyses to identify true drivers of cross-level performance.
- Single-ability SFT causes negative transfer within L1, but mitigation strategies are not explored. Investigate multi-task optimization methods (e.g., gradient surgery, orthogonal adapters, decoupled heads, loss-balancing, task-aware regularization) to reduce intra-level interference.
- Multi-ability “synergy” findings are based on one specific L1 combination (Distance+Size+Correspondence) in one model/training recipe. Test broader ability sets, different compositions, and multiple model families to determine generality and robustness.
- RL experiments are limited to Qwen2.5-VL-7B using GRPO and MCQ-based verifiable rewards; the approach’s generality across architectures, reward forms, and open-ended metrics is unknown. Benchmark across diverse models and RL algorithms (e.g., PPO, DPO variants, offline RL) and introduce rewards tied to continuous outcomes (e.g., spatial error, trajectory adherence).
- RL improves some high-level tasks while degrading Memory and certain L1 skills; causes are not diagnosed. Analyze token budget allocation, reasoning length vs. perception accuracy trade-offs, and introduce memory-specific rewards or architectures (e.g., external memory modules) to prevent regressions.
- L4 action space is discretized and embodiment-agnostic, potentially losing important control fidelity and subtleties of physics. Evaluate continuous-control tasks (robot manipulators, locomotion) and measure low-level command accuracy, stability, and sim-to-real transfer.
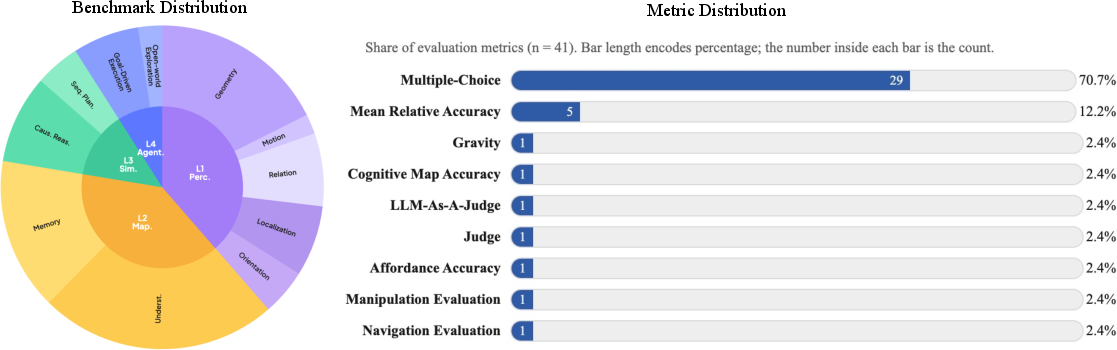
- The benchmark heavily relies on multiple-choice formats (≈70.7%) and LLM-as-a-Judge, which may favor test-taking heuristics and introduce subjectivity. Incorporate more reference-based, open-ended metrics and calibrate LLM judging with gold standards, human adjudication, and reliability audits.
- Distractor quality for MCQs (often LLM-generated/rephrased) is not validated for difficulty balance or bias. Systematically grade distractors (e.g., IRT-based difficulty modeling), ensure non-leading options, and release adverse sets for robustness testing.
- Memory (cognitive maps and retrieval) evaluation lacks standardized, transparent metrics; details are sparse. Define and publish metrics for map accuracy (e.g., IoU/IoE in BEV), localization error, temporal recall precision/recall, and occlusion-aware retrieval.
- Expert-model-derived labels (DepthAnything3, OrientAnything, trackers) can inject systematic noise or bias; no label-quality audits are provided. Quantify error rates, propagate uncertainty into training/evaluation, and benchmark against human annotations on stratified subsets.
- Many L1/L2 training sets are indoor (SUNRGBD, Hypersim, Matterport3D); outdoor, cluttered, weathered, and rare-scene coverage is limited. Expand to varied domains (urban, natural, extreme lighting/weather, sensor noise) and evaluate domain generalization.
- Orientation and gravity sensing are derived from vision-only cues; multimodal sensing (IMU, depth, LiDAR) is not considered. Test multimodal inputs to disentangle visual orientation from priors and quantify benefits of additional sensors.
- Cross-lingual spatial semantics and perspective-taking are not evaluated; tasks appear English-only. Create multilingual benchmarks capturing linguistic variability in spatial prepositions, frames of reference (egocentric/allocentric), and cultural differences.
- The taxonomy references L0 “foundational multimodal capabilities,” but these are not defined or evaluated. Specify L0 abilities (e.g., OCR, grounding, temporal coherence) and measure their influence on L1–L4 performance.
- Coverage gaps remain (despite SpatialPlus): e.g., occlusion reasoning, topological invariants beyond inside/outside/overlap, 3D rotational symmetry, multi-agent relational reasoning, and long-horizon partial observability. Add tasks explicitly targeting these abilities.
- Conversion of complex reasoning datasets to “hybrid multi-option + LLM-as-a-Judge” may alter task demands and evaluation validity. Compare original task formulations to converted ones, quantify any shifts in difficulty or solution strategies.
- The action mapping strategy aggregates embodiment-specific actions into unified key–mouse sequences; the mapping’s fidelity and ambiguity are not quantified. Report mapping error rates, reversibility, and ambiguity metrics; evaluate if mapping hinders learning of embodiment-specific affordances.
- Data contamination risks are acknowledged only for a subset (robot arm) and not systematically audited across all tasks. Implement and publish rigorous decontamination checks (hash-based, scene-level, instruction-level) against known pretraining corpora for each evaluated model.
- Average score weights and task difficulty normalization are not fully described; rankings may be sensitive to weighting. Publish the exact weighting scheme, justify choices, and include sensitivity analyses showing rank stability under alternative weights.
- No compute, token budget, or latency analysis is provided for “thinking vs. perceiving” trade-offs. Measure inference-time costs, throughput impacts, and efficiency gains of auto-think gating; report compute-performance Pareto fronts.
- The ability selection for SFT and RL focus (e.g., choosing three L1 abilities) was manual. Use principled selection (mutual information, causal discovery, feature importance) to pick abilities with maximal expected cross-level transfer.
- The benchmark mixes single-image, multi-image, and video, but point clouds/meshes are only tangentially referenced; direct 3D inputs are not systematically evaluated. Add native 3D tasks (point clouds, meshes) to test true 3D spatial reasoning and mapping.
- Tool-use at inference (e.g., external depth/pose estimators) is not discussed; models may benefit from calling tools for L1 tasks. Define tool-use protocols and evaluate how external perception tools impact the hierarchy without conflating pure MLLM ability.
- Safety, alignment, and ethical considerations for agentic tasks are unaddressed (e.g., unsafe action sequences, privacy). Include safe RL constraints, risk-aware planning metrics, and evaluation in safety-critical scenarios.
- Human cognitive alignment is asserted (Piagetian progression) but not empirically validated. Compare MLLM performance profiles to human benchmarks across age groups and task types to substantiate developmental parallels.
- Scaling laws and sample efficiency for spatial abilities are unexplored. Derive data scaling curves per ability and identify diminishing returns or optimal curricula for hierarchical training.
- The proposed hierarchy-aware reward design improves results, but its components (reward coefficients, length penalties) lack ablations. Publish detailed ablations to attribute gains to specific reward terms and quantify sensitivity.
- The paper’s conclusions are cut short; future work directions (e.g., curriculum design, unified training schedules, memory architectures) are not elaborated. Provide a concrete research roadmap specifying stage-wise training regimes, modular architectures, and evaluation expansions.
Practical Applications
Immediate Applications
The following applications leverage the paper’s benchmark, training insights, and inference strategies and can be deployed with current MLLMs and tooling.
- Industry (ML model development and evaluation)
- Use SpatialTree-Bench for capability-centric model selection, A/B testing, and continuous evaluation in CI pipelines.
- Sector: software, AI platforms
- Tools/workflows: integrate SpatialTree-Bench tasks and metrics; adopt the L1–L4 taxonomy in internal dashboards to diagnose weaknesses and track improvements
- Assumptions/dependencies: benchmark coverage matches target domains; licensing for datasets; LLM-as-a-Judge reliability for certain tasks
- Robotics and automation (manipulation and navigation)
- Boost agentic performance by targeted SFT on L1 geometry (e.g., distance) and blended L1 skill training (distance+size+correspondence), then validate gains on L4 tasks.
- Sector: robotics, manufacturing, logistics
- Tools/workflows: SpatialEngine-generated QA for L1; blended SFT recipes; task-specific eval; domain adaptation for grippers/arms
- Assumptions/dependencies: sim-to-real transfer; sensor calibration; safety guardrails for execution
- Apply “auto-think” inference (suppress unnecessary reasoning) to reduce latency and improve precision in intuitive perception tasks (e.g., alignment, orientation, counting).
- Sector: robotics, warehouse automation
- Tools/workflows: gated Chain-of-Thought at inference; token-length penalties for perceptual tasks
- Assumptions/dependencies: accurate task-type detection; stable latency/runtime budgets
- Vision-language GUI agents
- Execute screen-based action sequences by mapping vision observations to high-level key–mouse primitives for RPA-like workflows and game automation.
- Sector: software RPA, gaming
- Tools/workflows: action mapping to motion primitives; discrete multi-step policies; replay and safety filters
- Assumptions/dependencies: OS-level control permissions; robust visual grounding under UI variability
- Video analytics and retrieval
- Build cognitive maps and spatial memory retrieval for multi-view/video content: index “where” and “when” events occurred; query by spatial relations.
- Sector: media analytics, sports, retail, security
- Tools/workflows: BEV map generation; spatial captioning; retrieval APIs
- Assumptions/dependencies: data rights/privacy; multi-camera synchronization; evaluation alignment across numeric and semantic metrics
- Education and training
- Deploy spatial reasoning tutors and puzzle assistants using L2/L3 tasks; evaluate learners’ progression across the L1–L4 hierarchy.
- Sector: education, edtech
- Tools/workflows: curriculum aligned to SpatialTree; multi-format QAs (MCQ, numeric); progress dashboards
- Assumptions/dependencies: age-appropriate content; accessibility; guardrails for accuracy
- Assistive technologies and daily life
- Smartphone apps for quick distance/size estimation, object finding, and navigation cues in indoor settings.
- Sector: consumer software, accessibility
- Tools/workflows: L1 geometry and localization; on-device inference with gated reasoning for speed
- Assumptions/dependencies: camera quality; edge compute constraints; user safety and privacy
- Safety auditing and policy readiness
- Use the taxonomy to audit embodied AI systems and GUI agents for capability coverage and failure modes; adopt auto-think gating to mitigate overthinking-induced errors in perception.
- Sector: compliance, safety certification
- Tools/workflows: capability checklists; benchmark-driven reporting; inference policy configurations
- Assumptions/dependencies: acceptance by regulators; clear thresholds for pass/fail; reproducible test suites
- Academic research
- Design hierarchical curricula and controlled experiments to study transfer: validate negative transfers within L1 and cross-level synergy; compare RL vs. SFT outcomes with auto-think.
- Sector: academia, research labs
- Tools/workflows: SpatialTree-Bench; targeted SFT data generation; GRPO-based RL with hierarchy-aware rewards
- Assumptions/dependencies: compute availability; data decontamination; standardized metrics
Long-Term Applications
These applications extend the framework toward robust embodied agents, standardized evaluation, and sector-specific deployments that require further research, scaling, or development.
- Generalist spatial agents across embodiments
- Build a “Spatial Agent OS” that unifies perception, cognitive maps, simulation, and action execution for robots, drones, AR glasses, and GUI agents.
- Sector: robotics, AR/VR, smart devices
- Potential products: unified agent runtime with motion primitives; cross-embodiment policy libraries; memory and planning modules
- Assumptions/dependencies: reliable L4 execution; multi-sensor fusion; safety certifications; long-horizon memory
- Hierarchy-aware RL frameworks
- Industrialize RL with verifiable rewards and auto-think controllers that dynamically gate reasoning tokens by capability level and task difficulty.
- Sector: AI platforms, MLOps
- Potential products: “Reasoning Governor” service; RLVR pipelines with level-specific reward shaping
- Assumptions/dependencies: robust difficulty classifiers; stable reward signals; generalization beyond training distributions
- Standardization and policy
- Establish sector-wide standards for spatial intelligence evaluation and safety, borrowing the L1–L4 taxonomy to define certification tiers for embodied AI and GUI agents.
- Sector: policy, standards bodies (ISO/IEEE), public procurement
- Potential tools: certification benchmarks, conformance test suites, reporting templates
- Assumptions/dependencies: cross-stakeholder consensus; transparent benchmarks; independent testing bodies
- Spatial memory cloud services
- Persistent cognitive maps for home robots and smart environments (e.g., shared memory of object locations and navigational affordances).
- Sector: smart home, IoT
- Potential products: privacy-preserving map storage, household multi-agent coordination
- Assumptions/dependencies: robust identity/correspondence across views; privacy and consent; seamless updates
- Advanced healthcare and surgical assistance
- High-stakes spatial reasoning (L3–L4) for surgical robotics, AR-guided procedures, and rehabilitation planning.
- Sector: healthcare
- Potential products: surgical navigation assistants; patient-specific spatial planning
- Assumptions/dependencies: clinical validation; regulatory approvals; integration with medical imaging
- Autonomous systems and logistics
- Use mental simulation and sequential planning for autonomous navigation in warehouses, factories, and last-mile delivery; cross-level training to improve route planning and manipulation.
- Sector: logistics, supply chain, mobility
- Potential products: warehouse route planners; multi-agent coordination; task-level controllers
- Assumptions/dependencies: high reliability; robust domain adaptation; operations safety
- Disaster response and teleoperation
- Agentic competence for remote navigation, environment reconstruction, and manipulation via cognitive maps and simulation.
- Sector: public safety, defense
- Potential products: teleop assistants with spatial memory; autonomous scouting agents
- Assumptions/dependencies: bandwidth and latency constraints; extreme condition robustness; ethical governance
- Educational assessment frameworks
- Longitudinal evaluation of spatial cognition using the hierarchy to track progression and tailor interventions; connect human assessments with model-based diagnostics.
- Sector: education policy, edtech research
- Potential tools: standardized spatial ability assessments; personalized learning pathways
- Assumptions/dependencies: fair, validated measures; inclusivity; data protection
Cross-cutting assumptions and dependencies
- Data quality and coverage: Benchmarks and training data must match deployment domains; maintain rigorous data decontamination to avoid leakage.
- Compute and latency: Auto-think gating depends on accurate task-type detection and token budgets; edge vs. cloud trade-offs for consumer and robotics use.
- Reliability and safety: L4 agents require strong safety constraints, fail-safes, and regulatory compliance; GUI and physical agents need audit trails.
- Generalization: Transfer effects observed (negative within L1, synergistic cross-level) may vary by domain and model family; continued validation is required.
- Evaluation robustness: Numeric metrics and LLM-as-a-Judge protocols must be calibrated; align evaluation with end-user success criteria.
Glossary
- Affordance: The functional possibilities an object offers for interaction (e.g., grasping, sitting). "For other understanding tasks, such as affordance, we build on partially annotated datasets"
- Allocentric: A world-centered frame of reference for perceiving external object motion and speed. "Allocentric (perceiving the movement and speed of external objects)"
- Agentic Competence: The ability to translate plans into effective actions in dynamic environments. "Agentic Competence represents the culmination of spatial intelligence, bridging the gap between cognitive planning and practical execution."
- Agentic decision-making: Decision-making that integrates perception and reasoning to act in environments. "combine perception and reasoning to support complex, agentic decision-making."
- Auto-think strategy: A method that suppresses unnecessary reasoning to improve performance across tasks. "We propose a simple auto-think strategy that suppresses unnecessary deliberation, enabling RL to consistently improve performance across all levels."
- BEV maps: Bird’s-eye-view maps, a top-down spatial representation derived from visual data. "to generate BEV maps from videos"
- Causal Reasoning: Modeling cause–effect relationships in spatial interactions and dynamics. "Causal Reasoning allows MLLMs to model spatial interactions, physical dynamics, and entity relationships within a simulated mental space."
- Chain-of-Thought (CoT): Explicit step-by-step reasoning generated by a LLM. "explicit Chain-of-Thought (CoT) reasoning"
- Cognitive Map: An internal, global representation that integrates observations over time and views. "constructing a Cognitive Map, which synthesizes fragmentary observations (e.g., video frames or multi-view images) into a compact and unified global representation."
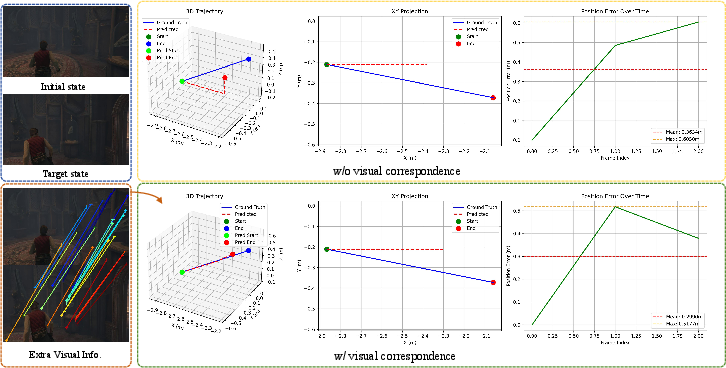
- Correspondence: Recognizing the same object or landmark across different viewpoints or conditions. "Correspondence (recognizing the same object or landmark across different viewpoints or visual conditions)"
- Data Decontamination: Ensuring no overlap between training and test data to avoid leakage. "Data Decontamination: The robotic arm data samples used for GRPO training are strictly separated from the SpatialTree-Bench testing data."
- Egocentric: A self-centered frame of reference for sensing one’s own motion and heading direction. "Egocentric (sensing self-motion and heading direction)"
- Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm for optimizing policies with grouped comparisons. "we employ Group Relative Policy Optimization (GRPO)"
- Grounding: Associating visual observations with spatial positions or coordinates. "Grounding (associating visual observations with spatial positions or coordinates)"
- GUI Agents: Agents that interact with environments via graphical user interfaces using language actions. "like GUI Agents"
- LLM-as-a-Judge: Using a LLM to evaluate or score outputs instead of fixed metrics. "converted to a hybrid multi-option + LLM-as-a-Judge format"
- Mental Mapping: Aligning spatial perception with language and constructing language-structured memory. "Mental Mapping (L2) marks a shift toward alignment with language."
- Mental Simulation: Internal reasoning that simulates spatial interactions before execution. "commonly referred to as mental simulation."
- Multimodal LLMs (MLLMs): LLMs that process multiple input modalities such as text, images, and video. "In multimodal LLMs (MLLMs), these abilities form the cornerstone of Spatial Intelligence (SI)"
- Pearson correlation coefficients: Statistical measures of linear correlation used to analyze ability dependencies. "using Pearson correlation coefficients computed from our benchmark scores."
- Perspective Taking: Mentally adopting alternative viewpoints to interpret spatial scenes. "Perspective Taking—the ability to mentally align with alternative viewpoints—"
- Reinforcement Learning with Verifiable Rewards (RLVR): RL approach where rewards are automatically validated against task criteria. "we further investigate the potential of Reinforcement Learning with Verifiable Rewards (RLVR)"
- Sequential Planning: Designing step-by-step strategies and abstract routes to achieve goals. "Sequential Planning converts causal insights into coherent, goal-directed action plans expressed in language."
- Spatial Captioning: Producing linguistic descriptions that capture spatial semantics of visual scenes. "through Spatial Captioning"
- Spatial Engine: A data pipeline integrating expert models to generate annotations and task QAs. "we construct a Spatial Engine that integrates multiple expert models"
- Topology: Basic spatial relations and configurations like inside, outside, and overlap. "Topology (perceiving basic spatial configurations such as inside, outside, or overlap)"
- Vision-Language Action Models (VLAs): Models that decode vision-language inputs into low-level robotic control signals. "Unlike Vision-Language Action Models (VLAs) decording the low-level control signals in robotics"
- Zero-shot: Generalizing to tasks without task-specific training or fine-tuning. "transfers in a zero-shot manner"
Collections
Sign up for free to add this paper to one or more collections.