SemanticGen: Video Generation in Semantic Space
Abstract: State-of-the-art video generative models typically learn the distribution of video latents in the VAE space and map them to pixels using a VAE decoder. While this approach can generate high-quality videos, it suffers from slow convergence and is computationally expensive when generating long videos. In this paper, we introduce SemanticGen, a novel solution to address these limitations by generating videos in the semantic space. Our main insight is that, due to the inherent redundancy in videos, the generation process should begin in a compact, high-level semantic space for global planning, followed by the addition of high-frequency details, rather than directly modeling a vast set of low-level video tokens using bi-directional attention. SemanticGen adopts a two-stage generation process. In the first stage, a diffusion model generates compact semantic video features, which define the global layout of the video. In the second stage, another diffusion model generates VAE latents conditioned on these semantic features to produce the final output. We observe that generation in the semantic space leads to faster convergence compared to the VAE latent space. Our method is also effective and computationally efficient when extended to long video generation. Extensive experiments demonstrate that SemanticGen produces high-quality videos and outperforms state-of-the-art approaches and strong baselines.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain‑English Summary of “SemanticGen: Video Generation in Semantic Space”
1) What is this paper about?
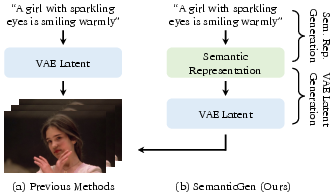
This paper introduces SemanticGen, a new way for computers to make videos from text. Instead of trying to draw every tiny detail right away, the system first creates a simple “plan” of the video (what’s in it and how things move), and then fills in the fine details like colors and textures. This two-step approach makes training faster and helps the system make longer, more consistent videos.
2) What questions did the researchers ask?
The paper focuses on two main questions:
- Can we speed up training for video generation by first planning in a high-level “semantic” space (the overall meaning and layout) before adding details?
- Can this make long videos (like a minute long) more stable, without characters or scenes drifting or changing randomly over time?
3) How did they do it? (Methods in simple terms)
Think of making a movie as two jobs: planning the storyboard and then painting each frame beautifully. SemanticGen separates these jobs.
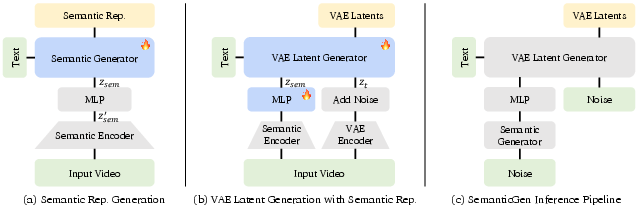
- Step 1: Plan in “semantic space”
- “Semantic space” is like a storyboard: it captures what objects are in the scene, where they are, and how they move—without getting bogged down in tiny details.
- To get these high-level features, they use a pretrained video-understanding model (a system that already learned to recognize what’s happening in videos).
- They compress these features into a smaller, simpler set of numbers using a small neural network (an MLP). This makes them easier and faster to learn and generate. The compression also shapes the features to behave like a nice, well-organized “cloud” of points (a Gaussian), which helps the generator learn quickly.
- Step 2: Add details in “pixel/latent space”
- After planning the storyboard, a second model turns that plan into a detailed video.
- It does this in a compact “latent” space (like a zipped version of the video), and then a decoder turns that into actual frames (the “unzipping” step).
- The overall generation uses a diffusion process, which you can imagine as starting from TV static and slowly “cleaning it up” step-by-step until a clear video appears. The plan from Step 1 guides the cleanup so the final video matches the intended content.
- Making long videos practical
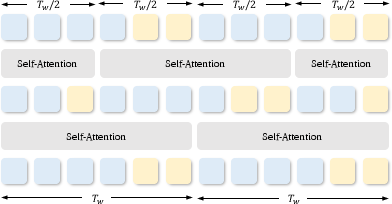
- “Attention” is how the model lets frames “talk to” each other. Letting every frame talk to every other frame is very slow for long videos.
- SemanticGen uses full attention only in the small, high-level plan (cheap and global), and uses a “shifted window” trick (overlapping chunks) for the detailed part. This keeps long videos consistent without blowing up the compute cost.
4) What did they find, and why does it matter?
Here are the main results:
- Faster learning: Training in the semantic (storyboard) space helps the model learn good videos more quickly than learning directly from low-level video details.
- High quality short videos: On short clips, SemanticGen matches or beats strong existing systems in how well it follows text prompts and how good the visuals look.
- Better long videos: For minute-long clips, SemanticGen shows fewer problems like characters changing appearance, colors shifting, or scenes falling apart over time (“drift”). The high-level planning step keeps the story and objects consistent.
- Compression helps: Shrinking the semantic features (for example, down to 64 or even 8 numbers per feature) actually improves stability and training speed.
- Semantic beats “just compressing pixels”: When they tried the same two-step idea but modeled compressed pixel codes instead of semantic features, learning was slower and results were worse. High-level meaning is a better starting point than raw visual details.
5) Why is this important? (Implications and impact)
- More reliable long videos: By planning first and detailing later, AI can make longer videos that stay consistent and follow the prompt more closely.
- More efficient training: Faster learning means less time and computing power are needed, making research and deployment more practical.
- Flexible design: The method can work with different video-understanding models and different video generators. It’s a general idea—first plan the meaning, then fill in the details—that others can reuse.
- Limitations and next steps: Fine textures can still drift in very long videos because the high-level plan doesn’t capture every tiny detail. Also, if the planning model looks at frames too slowly (low fps), quick motions might be missed. Future work could use better semantic encoders or mix in higher-frequency motion cues to keep both meaning and details sharp over time.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and concrete research directions suggested by the paper:
- Systematic comparison of semantic encoders: Evaluate multiple video-semantic encoders (e.g., Qwen-2.5-VL, V-JEPA2, VideoMAE2, 4DS) under matched setups to quantify effects on temporal understanding, compression ratio, convergence speed, and downstream video quality.
- Reproducibility and data transparency: Replace or complement proprietary training data and internal captioners with public datasets and open captions (e.g., WebVid, OpenVid), document data filtering, and release evaluation prompts/seeds to enable independent replication.
- Quantified convergence gains: Report wall-clock time, GPU-hours, and iterations to reach fixed quality targets versus strong baselines (including compressed-VAE approaches) to substantiate the “faster convergence” claim.
- Optimal semantic compression design: Explore the trade-off between compressed dimension and detail retention (identity, textures, color fidelity) across a broader range (e.g., 4–512 dims), different MLP architectures, and regularizers beyond KL-to-Gaussian; quantify with identity consistency and text-adherence metrics.
- Distributional modeling of semantic space: Test whether a Gaussian prior is appropriate for compressed semantics; compare alternative priors (mixture models, VAE, normalizing flows) and measure sample quality/stability.
- Noise injection strategy for z_sem: Precisely ablate where (training vs inference), how much, and how noise is scheduled; measure its impact on train–test gap, stability, and long-term coherence.
- Conditioning mechanism design: Compare concatenation with cross-attention, FiLM, gated adapters, and residual conditioning for injecting semantics; study effects on temporal drift and texture preservation.
- Long-video windowing choices: Ablate attention window size, stride/shift scheme, and number of Swin vs full-attention layers; quantify compute–quality trade-offs and coherence for 2–10+ minute videos.
- High-frequency temporal detail loss: Mitigate low-fps semantic sampling by testing multi-rate semantics (e.g., dual-stream high/low fps), optical flow or motion tokens, or temporal super-resolution; quantify flicker, motion realism, and action smoothness.
- Texture and identity consistency: Develop and evaluate multi-scale or residual-detail modules to recover fine textures; assess with face/body ReID and identity persistence metrics across long durations and scene transitions.
- Scalability to high resolution and fps: Benchmark 1080p/4K and ≥30 fps generation, reporting memory, latency, throughput, and quality; identify bottlenecks in both semantic and VAE stages.
- Robustness to domain shifts: Evaluate on stylized/cartoon, first-person, scientific/medical, and low-light domains; consider training domain-specialized semantic encoders or adapters.
- Sensitivity to semantic encoder errors: Measure robustness to encoder noise (occlusions, fast motion, compression artifacts) and bias; explore denoising, calibration, or teacher–student distillation for semantics.
- Controlled comparison to compressed-VAE methods: Run matched-compute/data experiments against TokensGen-like baselines to isolate the causal benefit of semantic vs compressed VAE spaces; include theory-inspired diagnostics (e.g., mutual information with pixels).
- Text–semantics alignment: Rigorously evaluate text adherence (e.g., CLIP-T, TIFA-Video) for complex, long, or compositional prompts; study how text encoders and prompt engineering affect the learned semantic distribution.
- Multi-shot narrative planning: Replace single-shot captions with shot lists or scripts; evaluate story coherence, character arcs, and causal event consistency; integrate LLM-based planners for hierarchical control.
- Editing and controllability: Test if semantic space enables local edits (object insertion/motion, style transfer) and conditioning from references (images, masks); evaluate on standard video-edit benchmarks.
- Audio and multimodal alignment: Extend to audio-conditioned or audio-synchronized video generation; evaluate lip-sync and audiovisual coherence for talking-heads and cinematic content.
- Inference efficiency: Report sampling steps, distillation/consistency-model variants, and real-time feasibility on commodity GPUs for both short and long videos.
- Human evaluation: Complement VBench and VBench-Long with human studies focused on narrative coherence, identity persistence, and aesthetic quality, especially for minute-level videos.
- Training stability and failure modes: Analyze training curves, mode collapse, and drift under out-of-distribution prompts; test curricula over video length and staged freezing/unfreezing of modules.
- Interaction with tokenizer choice: Validate benefits across different VAEs/tokenizers (including VA-VAE, DC-AE, MAETok, RAE/SVG); study joint training vs decoupled stages and their impact on detail fidelity.
- Theoretical grounding: Provide a formal explanation (e.g., information bottleneck, manifold complexity, sample complexity) for why semantic-space generation accelerates convergence and improves long-term consistency.
- Safety and bias: Audit demographic and content biases inherited from the semantic encoder and training data; implement and evaluate safety filters and content moderation pipelines.
Practical Applications
Practical Applications of “SemanticGen: Video Generation in Semantic Space”
Below are actionable applications derived from SemanticGen’s findings and techniques, grouped by deployment horizon. Each item highlights the sector, specific use cases, enabling tools/workflows, and key assumptions or dependencies that affect feasibility.
Immediate Applications
- Media and Entertainment — Previsualization and Storyboarding
- Use cases: Rapid previz for film/TV/commercials; generate 30–60s coherent scene drafts; plan camera moves/blocking; multi-shot look-dev with consistent characters and layouts.
- Tools/workflows: “Semantic plan → refine” plugin for Unreal/Blender/After Effects; semantic storyboard-to-video tool; reference-video-to-semantics for reblocking a scene while changing style.
- Dependencies: Access to a capable GPU; integration with DCC tools; licensed prompts/assets; limits in fine texture fidelity over long durations; semantic encoder coverage of desired content.
- Advertising and Marketing — Creative iteration at scale
- Use cases: Produce and A/B test many minute-long ad variants with brand-consistent story arcs; product-demo videos; social clips with controlled motion patterns and layouts.
- Tools/workflows: Creative assistant that locks semantic layout/motion and swaps styles/branding; batch pipelines that generate consistent multi-cut ad reels.
- Dependencies: Brand safety filters; prompt governance; content rights; compute budgets for batch inference; human review for claims accuracy.
- Education and Corporate Training — Instructional video generation
- Use cases: Generate procedure walkthroughs, lab demos, and explainer videos with long-term scene consistency; re-style and localize content while preserving motion/layout semantics.
- Tools/workflows: LMS plugin that takes structured scripts and returns minute-long coherent clips; semantic-templated lesson generator.
- Dependencies: Content accuracy review; alignment with accessibility standards; compute; semantic encoder ability to represent domain-specific scenes.
- Game Development — Cutscene prototyping and cinematic design
- Use cases: Draft long-form cutscenes and trailers; plan camera paths and character motion with consistent semantics; pre-production visualization.
- Tools/workflows: Engine-side previz generator using SemanticGen as a service; timeline-driven semantic planning controls (character/prop continuity).
- Dependencies: Integration with game engines; IP constraints; final-quality textures may still require manual polish or rendering pipelines.
- Video-to-Video Editing — Layout/motion-preserving restyling
- Use cases: Feed a reference clip to extract semantics (layout, motion, camera trajectory) and regenerate with new textures, lighting, or art styles.
- Tools/workflows: “Semantic-guided restyle” in NLEs; batch restyling for brand updates or localization.
- Dependencies: Quality of semantic encoder at low fps; content rights; potential artifacts on high-frequency motion/texture details.
- Synthetic Data for Vision/ML — Long video augmentation
- Use cases: Create long, coherent synthetic videos for training temporal models (tracking, action recognition) with reduced drift; scenario variations via semantic prompts.
- Tools/workflows: Data factory that parameterizes semantic layouts and motion; repository of semantic tokens for dataset versioning.
- Dependencies: Domain gap vs. real-world footage; annotation pipelines; compute; safety filters to avoid generating harmful content.
- R&D Efficiency — Faster model training and iteration
- Use cases: Train video generators with fewer GPU-hours by modeling in compressed semantic space; rapid ablation of long-context mechanisms (full attention on semantics, Swin on latents).
- Tools/workflows: Open-source recipes/SDKs adopting SemanticGen’s two-stage paradigm; academic benchmarks for drift reduction.
- Dependencies: Availability of a compatible semantic encoder (e.g., Qwen-2.5-VL vision tower); high-quality training data; reproducible engineering stack.
- Search and Retrieval — Semantic-first indexing of long videos
- Use cases: Index and retrieve video segments by compact semantic embeddings; align prompts to semantic tokens for targeted generation or editing.
- Tools/workflows: Semantic token store with Gaussianized compressed embeddings; prompt-to-semantics retrieval for clip-level operations.
- Dependencies: Encoder generalization across domains; storage/privacy policies for embeddings; inference-time noise injection alignment.
Long-Term Applications
- Professional-Grade Long-Form Production — End-to-end multi-minute content
- Use cases: Generate final-quality 1–5 minute narrative videos with consistent character identity, props, and environments across shots; controllable story beats.
- Tools/workflows: Multi-shot “semantic timeline” editor; character/asset binders that persist identity across scenes; collaborative review tools.
- Dependencies: Further research on texture/detail consistency over long durations; higher-res VAEs; richer control signals (shot lists, beat sheets); stronger safety filtering.
- Semantic-First Video Codec and Streaming
- Use cases: Transmit compact semantic tokens + local refinements; decode on edge devices; enable “regenerative playback” where clients reconstruct details conditioned on semantics.
- Tools/workflows: Codec combining Gaussianized semantic latents with residual synthesis; low-bitrate streaming modes; adaptive semantic frame rates.
- Dependencies: Standardization; hardware support; privacy/security of semantic representations; robust decoders across devices; graceful degradation handling.
- Interactive Real-Time Content (Live and Social)
- Use cases: Live semantic planning with on-the-fly refinement for streaming overlays, virtual hosts, or interactive stories.
- Tools/workflows: Low-latency inference stacks; caching/prefetch of semantic plans; incremental refinement schedulers.
- Dependencies: Major efficiency gains in inference; hardware acceleration; safety moderation at stream speed; UX guardrails.
- Robotics and Autonomous Systems — Scenario simulation videos
- Use cases: Generate long, coherent scenes for perception training and “what-if” scenario rehearsal with controllable motion trajectories and layouts.
- Tools/workflows: Scenario DSL to semantic plans; dataset curation that varies viewpoint, weather, crowd flows; training-time domain randomization.
- Dependencies: Physics consistency; sensor-faithful rendering; domain gap; validation against real-world data.
- Healthcare and Safety Training — High-stakes procedural content
- Use cases: Generate multi-step training videos (surgery, emergency response) with consistent spatial semantics and motion cues.
- Tools/workflows: Expert-in-the-loop validation pipelines; semantic checklists that align to clinical protocols; audit trails.
- Dependencies: Medical accuracy; regulatory compliance (HIPAA, MDR, etc.); provenance tracking; elevated texture and detail fidelity.
- Personalized Education — On-demand multi-minute lessons
- Use cases: Tailored explainer videos following a learner profile; consistent metaphors and visual anchors across a topic series.
- Tools/workflows: Curriculum-to-semantics compiler; learner model feeding semantic plan adjustments; accessibility overlays (captions, audio descriptions).
- Dependencies: Pedagogical validation; content safety; bias mitigation; edge-device decoding for schools with limited compute.
- Game and Virtual Worlds — Narrative engines with semantic planning
- Use cases: In-game, on-demand cutscenes derived from game state; consistent character identities across sessions; dynamic trailers.
- Tools/workflows: Semantic state bridge from gameplay logs; style adapters; identity locks for characters/assets.
- Dependencies: Performance budget; IP protection; stronger identity retention across long spans; player safety policies.
- Policy, Governance, and Risk — Auditable generative pipelines
- Use cases: Transparent control via semantic plans; drift monitoring in long-form outputs; provenance logs linking semantic tokens, prompts, and outputs.
- Tools/workflows: “Drift dashboards” using ΔM_drift-style metrics; semantic contract checks (forbidden content, bias heuristics); audit-ready metadata.
- Dependencies: Standardized metrics; regulatory acceptance; secure logging; red teaming for long-context behaviors.
- Accessibility and Localization — Consistent multi-lingual adaptations
- Use cases: Produce culturally adapted long-form content while preserving motion/layout semantics; future: accurate sign-language video synthesis.
- Tools/workflows: Semantic lock with language/style adapters; reviewer-in-the-loop; domain-specific semantic encoders (e.g., hand shape/motion).
- Dependencies: High-fidelity modeling of fine motor details; expert validation; region-specific content policies.
Assumptions and Cross-Cutting Dependencies:
- Compute and latency: Training/inference require capable GPUs; minute-long outputs remain resource-intensive even with SemanticGen’s efficiency gains.
- Semantic encoders: Compatibility and license of encoders (e.g., Qwen-2.5-VL) or alternatives (V-JEPA 2, VideoMAE 2, 4DS); encoder coverage of target domains.
- Quality limits: Current limitations in fine-grained textures over long durations and loss of high-frequency temporal details due to low-fps semantic sampling.
- Data and rights: Legally compliant training data; IP and likeness rights; robust content safety filters for deployment.
- Integration: Tooling to bridge semantic planning with creative suites, engines, and MLOps; reproducible pipelines for academia/industry.
- Governance: Provenance, drift monitoring, and auditability become critical as long-form generation scales and is used in regulated contexts.
Glossary
- Ablation study: A methodological analysis that removes or alters components of a system to assess their impact on performance. "Ablation studies further validate the effectiveness of our key design choices."
- Autoregressive: A generative modeling approach that produces outputs sequentially, conditioning each step on previous ones. "Autoregressive techniques \cite{genie, videopoet, weissenborn2019scaling, deng2024autoregressive, yin2025slow} generate each frame or patch of the video sequentially"
- Bidirectional attention: Attention that considers dependencies in both past and future directions across the entire sequence. "model all frames with bidirectional attention and generate all frames simultaneously"
- Compression ratio: The factor by which data is reduced in size during encoding, affecting token counts and computational costs. "modern VAEs typically have modest compression ratios"
- Conditional Flow Matching: A training objective for flow-based generative models that regresses a vector field to transport probability mass between distributions. "via Conditional Flow Matching~\citep{flow-matching}:"
- Cross-attention: An attention mechanism that allows one set of tokens (e.g., text) to attend to another (e.g., video latents). "and cross-attention modules."
- Diffusion model: A generative approach that iteratively denoises noisy data to sample from a learned distribution. "then train a diffusion model to fit the distribution of VAE latents."
- Diffusion Transformer (DiT): A transformer architecture adapted to diffusion modeling for high-capacity generative tasks. "Diffusion Transformers \cite{dit}"
- Drift metric (): A quantitative measure of quality degradation over time in long videos. "We also employ the drifting-measurement metric introduced in \cite{framepack}"
- Euler discretization: A first-order numerical method for solving differential equations by stepwise updates. "we employ Euler discretization for Eq. \ref{eq:ODE}"
- Fidelity: The degree to which generated content preserves detail and visual accuracy. "mitigating drift without sacrificing fidelity."
- Full-sequence attention: Attention computed over all tokens across the entire sequence, enabling global context modeling. "both causal modeling and full sequence attention."
- Gaussian distribution: The normal probability distribution often used to model latent variables and noise. "models the compressed feature space as a Gaussian distribution."
- In-context conditioning: Providing auxiliary inputs alongside the main input to guide generation within the same context window. "via in-context conditioning \cite{recammaster}."
- KL divergence: A measure of dissimilarity between two probability distributions, used as a regularizer. "we add the KL divergence objective as the regularizer"
- Latent video diffusion model: A diffusion model that operates in a compressed latent space rather than pixel space for efficiency. "It is a latent video diffusion model, consisting of a 3D Variational Autoencoder (VAE)~\citep{vae} and a Transformer-based diffusion model (DiT)~\citep{dit}."
- Noise schedule: The prescribed progression of noise levels across timesteps in diffusion processes. "for the noise schedule and denoising process."
- Ordinary differential equation (ODE): A differential equation involving functions of one variable and their derivatives, used to define probability flows. "an ordinary differential equation (ODE), namely:"
- Rectified Flow: A flow-based framework that defines a straight path between data and noise distributions for efficient sampling. "The generative model adopts the Rectified Flow framework~\citep{esser2024scaling}"
- Reconstruction objective: A training loss that encourages a decoder to accurately reconstruct inputs from their latent representations. "train a variational autoencoder (VAE) \cite{vae} with a reconstruction objective"
- Semantic encoder: A model that converts videos into compact, high-level representations capturing structure and dynamics. "we utilize the vision tower of Qwen-2.5-VL \cite{qwen25vl} as our semantic encoder"
- Semantic representation: A high-level feature tensor expressing a video's global layout and motion rather than low-level texture. "into a semantic representation "
- Semantic representation compression: Reducing the dimensionality of semantic features and regularizing them to a tractable distribution for training. "we propose semantic space compression via a lightweight MLP"
- Semantic space: A compact feature domain where high-level content and global planning are modeled before adding details. "generating videos in the semantic space"
- Shifted window attention (Swin): An attention scheme that computes local attention within windows and shifts them across layers to reduce complexity. "use shifted window attention \cite{swin} to map them into the VAE space."
- Sparse attention: An attention pattern that limits connections to reduce quadratic complexity while retaining essential context. "reduce complexity via sparse attention \cite{xi2025sparse, xia2025training}"
- Spatio-temporal attention: Attention that jointly models spatial and temporal dependencies across frames. "3D (spatial-temporal) attention"
- Temporal drift: Gradual deviation or inconsistency in generated content across time. "they often suffer from temporal drift or noticeable degradation in visual quality."
- Two-stage generation: A pipeline that first generates high-level semantics and then refines them into detailed latents or pixels. "SemanticGen adopts a two-stage generation process."
- VAE latents: Compressed codes produced by a VAE encoder representing videos in a latent space. "fit the distribution of VAE latents."
- Variational Autoencoder (VAE): A probabilistic encoder–decoder model that learns a latent distribution for data. "train a variational autoencoder (VAE) \cite{vae} with a reconstruction objective"
- Vector field (in diffusion): A function defining velocities that transport samples along a probability path between distributions. "we regress a vector field that generates a probability path"
- Video-understanding tokenizer: An encoder that produces tokens capturing video semantics (motion, layout) rather than raw pixels. "we leverage off-the-shelf video-understanding tokenizers as the semantic encoder."
- Vision-language alignment objective: A training objective that aligns visual features with text representations for multimodal understanding. "trained with a vision-language alignment objective \cite{clip}"
Collections
Sign up for free to add this paper to one or more collections.