- The paper introduces a hybrid model that combines diffusion-based denoising, sparse attention, and a mixture-of-experts mechanism to tackle long-document generation.
- It demonstrates significant improvements in metrics like ROUGE, BLEU, and accuracy across several benchmarks compared to conventional models.
- The architecture leverages dilated local and global attention to preserve semantic coherence while drastically reducing computational complexity.
SA-DiffuSeq: Efficient Long-Document Generation via Sparse Attention and Diffusion
Motivation and Problem Setting
The proliferation of long-form textual corpora in domains such as scientific writing, code repositories, and multi-turn dialogues highlights a central bottleneck: existing generation models are fundamentally challenged by the joint requirements of computational efficiency and global semantic coherence over long sequences. Classic Transformer-based models, although effective due to their self-attention mechanism, are not inherently scalable for thousands of tokens due to quadratic complexity in sequence length. The emergence of diffusion models for text generation, such as DiffuSeq, offers improved controllability and denoising-driven robustness but inherits significant inefficiency through iterative computation over long contexts.
A core insight underlying this work is that both efficiency and expressiveness in long-document generation can be dramatically improved through the structured deployment of sparsity: selectively restricting attention and routing computation only to those segments of text where it is most impactful. However, naive sparsification is typically detrimental to the model’s ability to capture document-wide dependencies required for high-quality generation.
Model Architecture and Technical Contributions
SA-DiffuSeq proposes a hybrid of diffusion-based generation and transformer architectures integrating sparse attention and dynamic computation via a Mixture of Experts (MoE) mechanism.
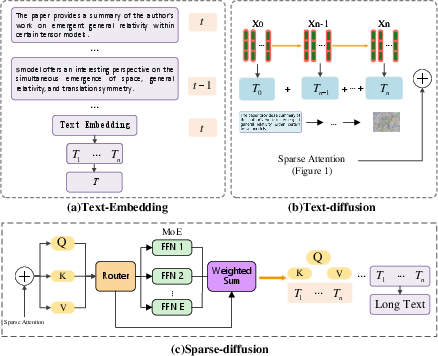
Figure 1: (a) Text embedding pipeline; (b) Progressive noise injection across layers; (c) Sparse attention with expert routing via MoE within the diffusion process.
Sparse Attention
Drawing inspiration from Longformer and related sparse transformers, SA-DiffuSeq replaces full attention with a sliding window attention map, drastically lowering computational complexity from O(n2) to O(nw), where w is the window size. To preserve the capacity for long-range information flow, the window is further dilated, expanding the receptive field without commensurately increasing compute or memory overhead.
Critically, a global attention variant is incorporated for select tokens (e.g., [CLS], question focus tokens), enabling those tokens to cross-attend to the full input and thus aggregate or disseminate global context efficiently. This synergy between dilated local and sparse global attention balances locality with global consistency.
Mixture of Experts Integration
To further optimize compute allocation, an MoE mechanism operates within each transformer layer. An input-adaptive gating function G(x) soft-selects expert subnetworks per token/segment, routing only a subset of parameters per forward pass. This dynamic specialization allows the architecture to scale capacity in accordance with semantic complexity rather than sequence length, enhancing expressivity without incurring uniform quadratic costs.
Diffusion Process Design
SA-DiffuSeq leverages a diffusion-based iterative denoising framework, generalizing DiffuSeq. At each stage, Gaussian noise is injected into latent representations, and the reverse process reconstructs the target sequence via learned denoising.
A major innovation is the introduction of a soft absorbing state tuned to the sparse attention architecture, controlling the stability and convergence of the denoising trajectory. This explicitly modulates the diffusion dynamics such that information is preserved even under highly sparse computation, mitigating the gradient misalignment and slow reconstruction typically found in long-sequence denoising.
The loss function comprises a joint denoising objective balancing the matching of denoised embeddings to the gold sequence across both continuous and discrete components, with regularization to stabilize latent magnitude.
Training & Inference
Sampling is substantially accelerated using advanced samplers, specifically DPM-solver++, reducing the count of required denoising steps without degrading quality. The training regime leverages consistent noise schedules and maintains sampling mechanisms closely aligned to those used during training, facilitating improved generalization to out-of-distribution or longer inputs.
Empirical Results
Extensive benchmarking was conducted on the Arxiv abstracts, HotpotQA (multi-hop QA), Commonsense Conversation, and Quora Question Pairs (QQP) datasets, comparing against baselines such as Longformer, DiffuSeq, and GPT-4 (for qualitative comparisons).
Key numerical improvements are summarized below:
| Dataset |
Metric |
Longformer |
DiffuSeq |
SA-DiffuSeq (Ours) |
| Arxiv Abs. |
R1/R2/RL |
41.44/17.52/38.70 |
39.12/16.43/37.88 |
44.41/18.73/39.89 |
| HotpotQA |
Ans. EM/F1 |
71.21/82.42 |
70.91/81.43 |
72.88/85.42 |
| Commonsense |
BLEU |
0.030 |
0.022 |
0.049 |
| QQP |
Acc. |
92.3 |
91.7 |
95.3 |
For sequence lengths up to 16k tokens, SA-DiffuSeq preserves performance much better than diffusion and dense-attention baselines, demonstrating stable ROUGE and F1 scores where both Longformer and DiffuSeq degrade rapidly.
Ablation confirms that sparse attention and higher diffusion steps are synergistic: removing sparse attention degrades ROUGE by up to 2 points; increasing window size slightly improves coherence, while increased diffusion steps yield diminishing but non-negligible gains.
Inference latency and n-gram novelty further corroborate the model's efficacy: at equivalent or lower computational cost, SA-DiffuSeq generates outputs with higher diversity (bi-gram novelty 0.90 vs. 0.75 for DiffuSeq, 0.60 for Longformer).
Implications
The introduction of a sparse attention/dilated window mechanism within a diffusion-based sequence model, combined with adaptive expert routing, yields a tractable architecture for long-document generation that does not sacrifice global coherence or content novelty. The successful deployment of a soft absorbing state demonstrates the adaptability of denoising processes to sparse, non-uniform computational settings, an observation with significant ramifications for the design of future scalable generative models.
Practically, this architecture is immediately applicable to domains with large context requirements: automatic generation of technical reports, scientific literature reviews, large-scale structured code generation, and multi-turn conversational AI where context retention is paramount.
Theoretical and Practical Outlook
From a theoretical standpoint, the coupling of diffusion dynamics with non-uniform, structured sparsity paves the way for a new class of generative sequence models capable of retaining global dependencies and semantic consistency at scale. The explicit disentanglement of computational cost from sequence length (through MoE and sparse attention) partially resolves the long-standing trade-off between efficiency and expressiveness in long-form text modeling.
Future work may refine gating functions for expert routing, further sparsify the diffusion process itself, or combine these with more sophisticated global context propagation schemes. Adapting this paradigm for semi-autoregressive, multimodal, or multi-agent generative settings has substantial potential for extending sequence modeling to broader, real-world tasks.
Conclusion
SA-DiffuSeq advances the state of the art in long-sequence text generation by synergistically integrating sparse attention, mixture-of-experts, and diffusion-based denoising with tailored absorbing states. This enables robust, efficient, and semantically consistent generation for sequences far beyond conventional LLMs or diffusion models, substantiated by consistent improvements across standard benchmarks and marked gains in both scalability and content diversity. The architectural principles introduced here are likely to inform future designs for efficient, context-aware generative models across domains.