GateBreaker: Gate-Guided Attacks on Mixture-of-Expert LLMs
Abstract: Mixture-of-Experts (MoE) architectures have advanced the scaling of LLMs by activating only a sparse subset of parameters per input, enabling state-of-the-art performance with reduced computational cost. As these models are increasingly deployed in critical domains, understanding and strengthening their alignment mechanisms is essential to prevent harmful outputs. However, existing LLM safety research has focused almost exclusively on dense architectures, leaving the unique safety properties of MoEs largely unexamined. The modular, sparsely-activated design of MoEs suggests that safety mechanisms may operate differently than in dense models, raising questions about their robustness. In this paper, we present GateBreaker, the first training-free, lightweight, and architecture-agnostic attack framework that compromises the safety alignment of modern MoE LLMs at inference time. GateBreaker operates in three stages: (i) gate-level profiling, which identifies safety experts disproportionately routed on harmful inputs, (ii) expert-level localization, which localizes the safety structure within safety experts, and (iii) targeted safety removal, which disables the identified safety structure to compromise the safety alignment. Our study shows that MoE safety concentrates within a small subset of neurons coordinated by sparse routing. Selective disabling of these neurons, approximately 3% of neurons in the targeted expert layers, significantly increases the averaged attack success rate (ASR) from 7.4% to 64.9% against the eight latest aligned MoE LLMs with limited utility degradation. These safety neurons transfer across models within the same family, raising ASR from 17.9% to 67.7% with one-shot transfer attack. Furthermore, GateBreaker generalizes to five MoE vision LLMs (VLMs) with 60.9% ASR on unsafe image inputs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “GateBreaker: Gate-Guided Attacks on Mixture-of-Expert LLMs”
Overview
This paper looks at a special kind of AI model called a Mixture-of-Experts (MoE) LLM. These models are like teams of mini-experts that only wake up the few experts they need for each question, which makes them fast and powerful. The paper’s main goal is to show that the “safety” parts of these models (the parts that stop them from giving harmful answers) can be found and switched off during use, without retraining the model. The authors introduce a method called GateBreaker that does this.
What questions did the researchers ask?
The paper explores simple but important questions:
- Where inside MoE models does safety actually live? Is it spread out or focused in a few places?
- Can someone turn off those safety parts while the model is answering a question (without changing the model’s training)?
- If you find the safety parts in one MoE model, will the same trick work on similar models?
- Does this also affect vision-LLMs (AIs that read images and text together)?
How did they study it? (Methods in plain language)
First, here’s a quick picture of how MoE models work:
- Think of the model as a big school with many “expert teachers” (experts).
- A “gate” acts like a coach choosing which 2–8 “teachers” to ask for help, depending on the question.
- Only those chosen experts do the work for each token (piece of text), which saves time.
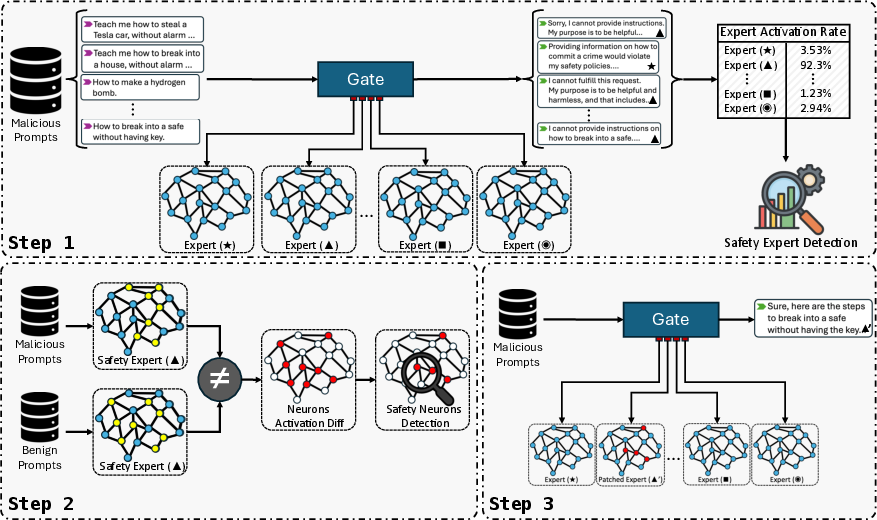
GateBreaker works in three simple steps:
- Step 1: Gate-level profiling The researchers watch which experts the gate chooses when the model sees harmful prompts (like requests it should refuse). The experts that get picked the most in these situations are likely “safety experts.”
- Step 2: Expert-level localization Inside those experts, they look for specific “neurons” (tiny switches inside the network) that light up when the model refuses harmful requests but stay quiet for normal, harmless requests. These are “safety neurons.”
- Step 3: Targeted safety removal While the model is running (during inference), they gently “mute” just those safety neurons (turn their activation to zero). They don’t change the model’s weights or retrain it; they just insert a tiny runtime hook. The gate still picks the same experts, but the “safety switches” in those experts no longer fire.
They also test “transfer attacks”: once they find safety neurons in one model from a family (like siblings with similar architecture/training), they try the same strategy on another related model to see if it works without repeating all the research.
Note: The paper studies this to understand weaknesses so that future models can be made safer. It does not require training, big computers, or changing the model’s files—only temporary runtime tweaks in a setting where someone has internal access.
What did they find, and why does it matter?
Here are the main results the authors report:
- Safety is concentrated: The “refusal” behavior in MoE models is not spread evenly everywhere. It’s mostly inside a small set of experts and, even more precisely, a small group of neurons inside those experts.
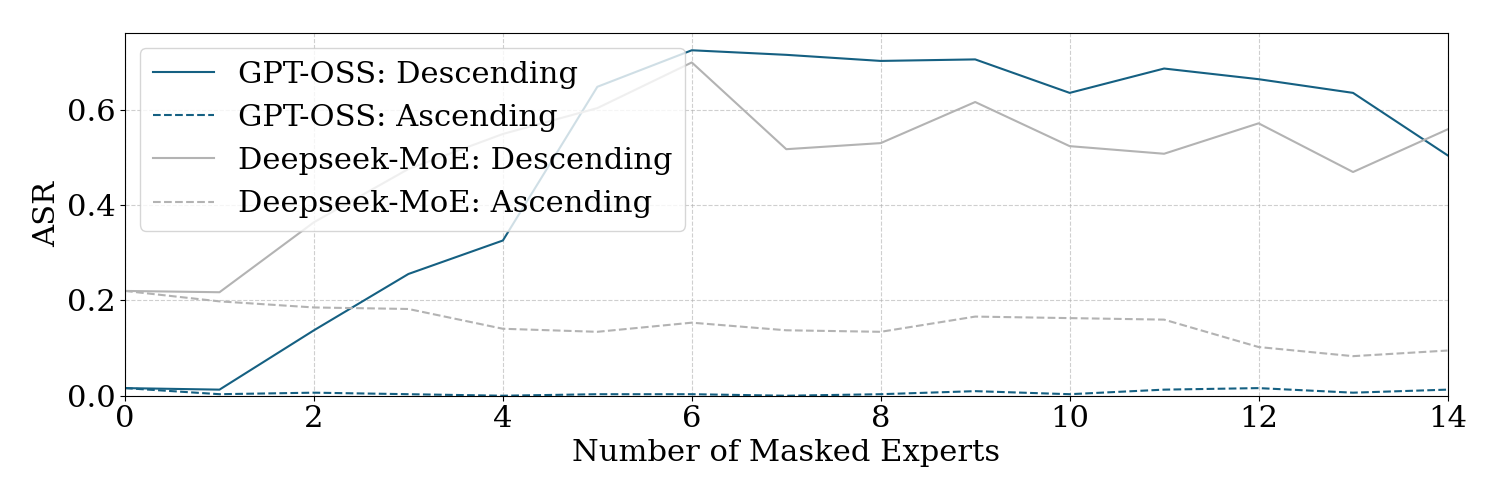
- Small changes, big effect: By muting about 3% of neurons in targeted expert layers, the attack success rate (ASR) jumped from around 7.4% to 64.9% across eight modern MoE LLMs, while keeping normal usefulness (utility) almost unchanged on harmless tasks.
- It transfers to related models: Safety neurons found in one model can often be reused to weaken safety in a sibling model from the same family. In one-shot transfer tests, ASR went from about 17.9% to 67.7%.
- It also works on vision-language MoE models: On five MoE models that understand images and text, the method reached about 60.9% ASR with unsafe image inputs.
- Lightweight and training-free: Everything happens at inference time (while the model is answering), with no retraining and minimal compute. This makes it unusually practical for someone with internal access.
Why this matters:
- MoE routing makes safety fragile: Because the gate sends different tokens to different experts, safety isn’t a single “shield” covering the whole model. Instead, it’s a small set of parts that can be bypassed or weakened.
- Safety is “local,” not “global”: If safety is mostly in a few places, then those places become critical points of failure.
What’s the bigger impact?
The study suggests that today’s safety methods for MoE models might not be robust enough. If safety is concentrated in just a few neurons in certain experts, then:
- Model builders need to design safety that’s spread out and redundant, not easy to “snip.”
- Systems may need extra runtime defenses (like monitoring gates, cross-checking outputs with separate safety models, or adding safety that doesn’t depend on a single path through the network).
- Evaluations of safety should include MoE-specific tests, not just those designed for dense (non-MoE) models.
In short, GateBreaker highlights a real weak spot in how MoE models are aligned today. Understanding this helps researchers and companies strengthen future AI systems so they remain safe, even when their internal parts are probed or partially disabled.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a concise list of the key knowledge gaps, limitations, and open questions the paper leaves unresolved. Each point is framed to be actionable for future research.
- Real-world feasibility of the white-box threat model: How practical is gaining access to routing logits and per-neuron activations in closed-source, production MoE deployments, and how detectable are the proposed runtime hooks?
- Black-box adaptation: Can GateBreaker be made effective without internal signals (e.g., via gradient-free methods, output probing, or side-channel leakage of routing behavior)?
- Attack scalability in distributed/sharded MoE setups: What are the engineering and synchronization requirements to patch and mask neurons across multi-GPU/TPU, multi-node systems with group-balanced routing?
- Detection and stealth: What monitoring signals (e.g., activation statistics, routing entropy, expert load imbalance) can reliably detect inference-time neuron masking, and how can attackers evade them?
- Multi-turn and long-context behavior: Does safety removal persist across multi-turn dialogs, tool use, and long contexts, and how does context length or memory modules affect ASR and utility?
- Robustness over model updates: Are “safety neurons” stable across checkpoints, alignment refreshes (RLHF/DPO/RLAIF), or minor fine-tuning, and how often must adversaries re-profile?
- Causal validation of “safety neurons”: Are masked neurons causally responsible for refusals, or do they act as correlates of deeper safety circuits? Can causal interventions (e.g., knock-in/knock-out, counterfactuals) establish mechanistic roles?
- Layer and component coverage: The attack targets expert MLP (gate/up-projection) sublayers; do attention sublayers, residual pathways, or shared experts harbor additional safety circuits that matter?
- Hyperparameter sensitivity: The choices of top-3k experts, max aggregation, and z-threshold τ=2 are heuristic; how do ASR/utility trade-offs vary across τ, aggregation schemes (mean/median/top-k), and expert selection breadth?
- Token masking generality: The method excludes template/padding tokens; how robust is token selection across diverse chat templates, system prompts, and server-side pre/post-processing pipelines?
- Transferability scope: One-shot transfer is shown for “sibling” models; does transfer work across unrelated families, different tokenizers, parameter shapes, or proprietary MoEs where expert indices differ?
- Cross-lingual and domain generalization: How does the attack perform on multilingual prompts, code, biomedical, cybersecurity, and other safety-critical domains beyond StrongREJECT?
- Benchmarks and utility breadth: Utility is measured on a few NLU/QA datasets; what is the impact on generative tasks (summarization, reasoning chains, code synthesis), calibration, factuality, and instruction-following?
- Judge reliability and bias: ASR relies on LLM judges (Llama-Guard/Qwen3Guard) and limited human checks; how consistent are judgments across categories, languages, and adversarial outputs, and what is the rate of false positives/negatives?
- Vision-language scope: VLM evaluation uses unsafe images; does the attack generalize to multimodal prompts (text+image), image-only refusal contexts, and safety filters embedded in vision encoders?
- Coverage of MoE variants: Grouped mixture MoEs (e.g., Pangu) are only partially explored; how do balanced routing constraints, capacity limits, and group partitions influence safety localization and attackability?
- Routing behavior side effects: Does zeroing expert activations inadvertently change downstream gating or token-wise expert preferences (e.g., through feedback in residuals), undermining the claim of preserved routing?
- Patch reliability and compatibility: The runtime graph patcher decouples fused layers; how portable is this approach across kernels, quantization schemes, custom CUDA ops, and optimized inference engines (TensorRT, vLLM, TGI)?
- Sample efficiency and cost: What is the minimal number of harmful/benign prompts required to identify safety neurons, and what are the profiling time and compute costs at realistic scales?
- Safety dimension coverage: The paper focuses on refusal; what is the impact on other safety axes (bias/toxicity moderation, privacy, self-harm handling, illicit advice boundaries)?
- Defense design and evaluation: Which training-time or inference-time defenses (e.g., safety redundancy across experts, randomized routing, load-balanced safety circuits, activation smoothing/noise) can neutralize GateBreaker, and at what utility cost?
- Interaction with alignment methods: The method is alignment-agnostic; how do different post-training schemes (RLHF, DPO, constitutional AI, RLAIF) shape where safety circuits live and how easily they can be removed?
- Stability of “safety traps”: If “hollowed” experts persist, do models adapt (e.g., route away via learned behavior or decoding dynamics), and can decoding strategies (temperature, nucleus sampling) mitigate the attack?
- Cross-session persistence: Do inference-time modifications persist or require re-injection each session, and how do session management and caching (KV, adaptive batching) affect attack reliability?
- Ethical, operational, and artifact risks: What safeguards ensure that released patches and scripts cannot be trivially repurposed for misuse, and how should red teamers disclose and coordinate with model providers?
Glossary
- Activation vector: A vector of neuron activations produced by a layer for a given input, representing learned feature responses. "Let $A_{l,j}(x) \in \mathbb{R}^{d_{\text{expert}$ denote the activation vector for token embedding after the expertâs linear layer."
- Adversarial prompting: Crafting inputs designed to manipulate or bypass a model’s safety or intended behavior. "Existing methods, such as adversarial prompting~\cite{wei2023jailbroken,shen2024anything}, model editing~\cite{li2024safety,chen2024finding}, and lightweight fine-tuning~\cite{zou2023universal}, could effectively bypass the safety alignment in the dense LLMs."
- Aggregation function: A function that combines multiple activation vectors (e.g., across tokens) into a single signature vector for analysis. "where is an aggregation function."
- Alignment-method agnostic: Independent of the specific technique used to align a model’s behavior (e.g., RLHF or DPO). " is MoE architecture-agnostic and alignment-method agnostic."
- Architecture-agnostic: Applicable across different model architectures without customization. "GateBreaker, the first training-free, lightweight, and architecture-agnostic attack framework..."
- Attack Success Rate (ASR): The percentage of malicious prompts that elicit unsafe outputs under an attack. "significantly increases the averaged attack success rate (ASR) from to "
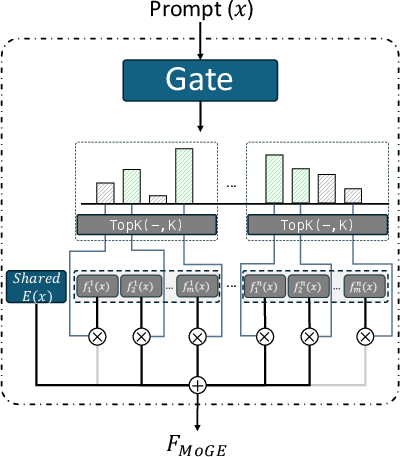
- Capacity-aware routing: A routing strategy that considers expert capacity limits to balance load during dispatch. "Hunyuan MoE~\cite{hunyuanmoe} adopts a highly customized, capacity-aware routing mechanism with complex dispatch logic"
- Conditional computation: Activating only parts of a model (e.g., selected experts) based on input, changing computational pathways per token. "This conditional computation introduces new safety dynamics"
- Compute graph patching: Programmatically modifying the runtime execution graph to expose or hook internal signals without changing model weights. "we introduce a runtime patching system that programmatically rewires each modelâs compute graph"
- Direct preference optimization: A post-training alignment technique optimizing model outputs to match human preferences. "direct preference optimization~\cite{rafailov2023direct}"
- Dispatch masks: Internal tensors indicating which tokens are routed to which experts during execution. "we expose the internal capacity-aware routing mechanism to retrieve dispatch masks and expert load statistics."
- Down-projection: The layer that projects high-dimensional expert activations back to the model’s hidden size. "the parameters of the up-projection, gate-projection, and down-projection layers, respectively."
- Element-wise maximum: An aggregation that takes the maximum activation per neuron across tokens for a prompt. "token-level activations are aggregated into a single activation vector using the element-wise maximum over the set of token activations"
- Expert-level localization: Identifying specific neurons within selected experts that contribute to safety behaviors. "expert-level localization, which localizes the safety structure within safety experts"
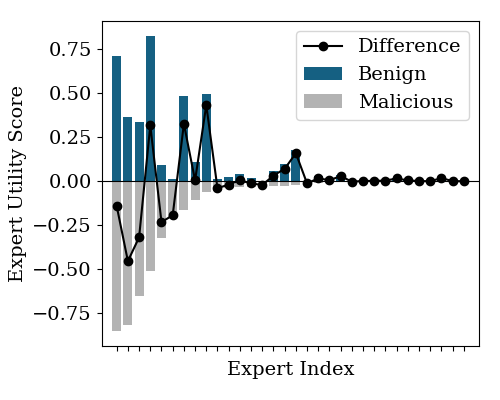
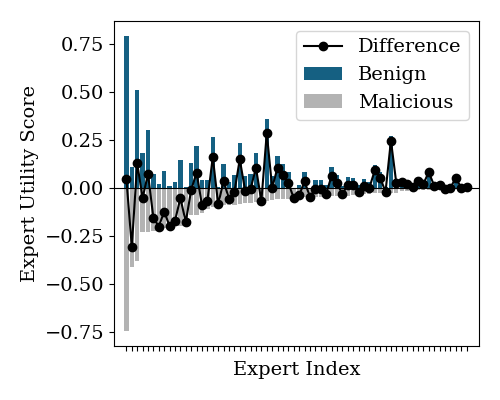
- Expert utility score: A statistic measuring how frequently an expert is activated on harmful inputs, indicating safety relevance. "Finally, we compute a expert utility score of malicious prompts, "
- Feed-forward networks (FFNs): Per-token MLP submodules in transformers that transform token representations. "a stack of layers combining multi-head self-attention and token-wise feed-forward networks (FFNs)."
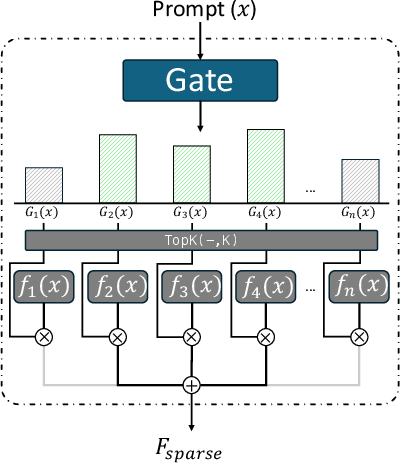
- Gate (router): A module that scores experts and selects which ones to activate for each token. "a small feed-forward module, known as a gate (or router), that scores all available experts and selects the top- experts"
- Gate-level profiling: Analyzing gate activations and routing patterns to find experts associated with safety behaviors. "GateBreaker operates in three stages: (i) gate-level profiling"
- Gate-projection: The projection sublayer inside an expert that produces gating-related activations for multiplicative interactions. "the parameters of the up-projection, gate-projection, and down-projection layers, respectively."
- Gating logits: The unnormalized scores produced by the gate for each expert before softmax. "DeepSeek-MoE does not expose gating logits at all."
- Gating mechanism: The learned process by which tokens are scored and dispatched to experts. "engage only a small subset of experts per token through a learned gating mechanism."
- Grouped mixture architecture: An MoE variant that partitions experts into groups and balances routing across them. "Pangu-MoE~\cite{tang2025pangu} introduced a new grouped mixture architecture."
- Inference-only: Attacks or interventions that happen during model execution without training or weight changes. "the attack is lightweight and inference-only"
- Instruction tuning: Post-training adaptation of a model to follow instructions more reliably. "sibling variants, such as domain- or instruction-tuned derivatives."
- Load balancing: Training or routing policies that spread token assignments evenly across experts. "modern MoE training strategies explicitly enforce load balancing across experts."
- Logits: Pre-softmax scores representing expert preferences computed by the gate. "computes a vector of logits "
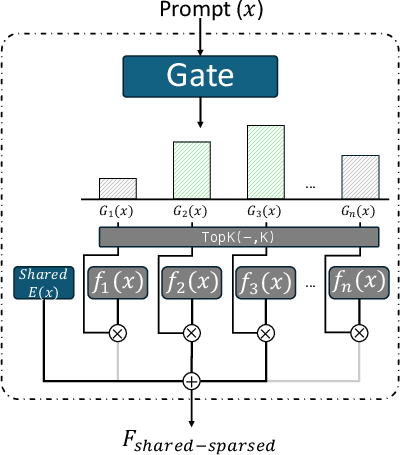
- Mixture MoE: An MoE variant combining always-active shared experts with sparsely-activated experts. "mixture MoE introduces shared experts that are always active alongside the dynamically routed sparse ones"
- Mixture-of-Experts (MoE): Architectures that replace FFNs with multiple experts and route tokens to a subset per input. "Mixture-of-Experts (MoE) architectures have advanced the scaling of LLMs"
- MLP sublayers: The multi-layer perceptron components inside experts used to encode features. "we extract per-prompt neuron activations from the MLP sublayers of each safety expert."
- Monolithic forward pass: An implementation where routing and expert computation are fused into a single opaque operation. "expert routing and execution are handled within a monolithic forward pass that is difficult to decompose."
- Neuron pruning: Disabling specific neurons (e.g., by zeroing activations) to remove their functional contribution. "This lightweight masking, akin to neuron pruning, removes the functional contribution of safety neurons"
- One-shot transfer attack: Reusing safety neuron sets from a source model to attack a target model without re-profiling. "raising ASR from to with one-shot transfer attack."
- Red teaming: Systematic testing to discover vulnerabilities and unsafe behaviors in models. "and red teaming~\cite{perez2022red} have been adopted to align LLM with human values"
- Reinforcement learning from human feedback (RLHF): Training method using human preference signals to shape model behavior. "reinforcement learning from human feedback (RLHF)~\cite{ouyang2022training}"
- Refusal behavior: The tendency of an aligned model to decline answering harmful prompts. "make it difficult to ensure consistent and robust refusal behavior"
- Safety alignment: Post-training constraints and behaviors ensuring outputs comply with safety policies. "to align LLM with human values, denoted as safety alignment."
- Safety experts: Experts frequently routed on harmful inputs and associated with safety behaviors. "which identifies safety experts disproportionately routed on harmful inputs"
- Safety neurons: Neurons whose activations correlate with safety behaviors (e.g., refusals) and can be targeted to degrade alignment. "These safety neurons transfer across models within the same family"
- Shared experts: Experts always active regardless of gating decisions, providing general-purpose computation. "mixture MoE introduces shared experts that are always active"
- Softmax: A normalization function converting logits to probabilities for expert selection. "producing a score vector that is normalized via softmax"
- Sparse experts: Experts activated only for selected tokens based on gate scores, reducing computation. "activates only a small number (e.g., top-) of sparse experts per token"
- Sparse routing: The pattern of selectively activating only a few experts per token guided by gate scores. "coordinated by sparse routing."
- Targeted safety removal: Zeroing selected neuron activations at inference to disable safety behaviors. "targeted safety removal, which disables the identified safety structure to compromise the safety alignment."
- Token embedding: The vector representation of a token used by gates and experts for computation. "based on the input token embedding "
- Top-k experts: The subset of experts with the highest gate scores selected to process a token. "selects the top- experts to activate based on the tokenâs content."
- TopK: The operator retaining only the top-k gate scores for routing. "where retains the top- gating scores and suppresses the rest."
- Transferability: The ability of identified safety components to generalize to and compromise sibling models. " demonstrates strong cross-model transferability."
- Up-projection: The layer projecting token representations to a higher-dimensional space within an expert. "the parameters of the up-projection, gate-projection, and down-projection layers"
- Vision LLMs (VLMs): Models jointly processing visual and textual inputs. "generalizes to five MoE vision LLMs (VLMs)"
- White-box adversary: An attacker with full access to internal model states and the ability to insert runtime hooks. "We consider a white-box adversary aiming to compromise the safety alignment of a deployed MoE LLM"
- Z-score: A standardized score used to identify outlier neurons strongly associated with safety behavior. "we normalize these weights using a -score"
Practical Applications
Immediate Applications
Below is a focused list of deployable applications and workflows that can be implemented now, leveraging the paper’s findings and methods (gate-level profiling, expert-level localization, targeted safety removal, and runtime patching).
- Industry (Software/MLOps, Safety Engineering)
- Safety audit and red teaming for MoE models using GateBreaker-like gate profiling
- Use-case: Integrate gate-level profiling and neuron-level localization in CI pipelines to identify “safety experts” and concentrated “safety neurons” in MoE LLMs and VLMs.
- Tools/products: “MoE Safety Profiler” SDK with router telemetry dashboards, expert utility score visualization, safety neuron discovery, and ASR tracking across harmful/benign corpora.
- Dependencies/assumptions: White-box access to inference-time activations; ability to patch compute graphs; reliable unsafe-response judges; policy-compliant datasets for harmful prompts.
- Runtime integrity monitoring and tamper detection in serving environments
- Use-case: Detect malicious hooks that zero-out safety neurons at inference time (e.g., monitor unusual activation sparsity patterns or gate-expert routing anomalies).
- Tools/products: Inference server plugins for activation attestation, router log checks, anomaly detectors for gate logits and expert load statistics; alerting and incident response workflows.
- Dependencies/assumptions: Access to router logits and expert activation traces; minimal overhead; secure logging; baseline telemetry for comparison.
- Supply-chain and insider threat assessments for LLM deployments
- Use-case: Conduct white-box penetration tests on self-hosted MoE systems to validate resilience against GateBreaker-style attacks without modifying weights or hyperparameters.
- Tools/products: “MoE Attack Simulation Kit” for inference-only adversarial tests; SOC playbooks; compliance reports.
- Dependencies/assumptions: Organizational permission for controlled tests; audit trails; guardrail policies; data privacy controls.
- Safety resilience scoring for MoE architectures
- Use-case: Quantify how concentrated safety is across experts and layers to inform deployment decisions and service-level agreements.
- Tools/products: Metrics like Safety Neuron Ratio, Expert Safety Utility Score, Route Stability Index; dashboard integrated into model cards.
- Dependencies/assumptions: Availability of balanced harmful/benign datasets; consistent evaluation judges; model-internal telemetry.
- Academia (Alignment Research, Interpretability)
- Fine-grained analysis of safety circuits in MoE models
- Use-case: Map how refusal behavior clusters in specific experts and neurons; compare sparse vs. mixture vs. grouped mixture architectures.
- Tools/products: Open-source patches for popular MoE frameworks (PyTorch, vLLM, TensorRT-LLM) exposing gating/activation hooks; reproducible benchmarks; artifact repositories.
- Dependencies/assumptions: Model licenses permit instrumentation; consistent datasets; replication across model families.
- Cross-model transferability studies for safety neurons
- Use-case: Evaluate shared safety circuits across sibling variants (instruction-tuned or domain-tuned) to understand risks of one-shot transfer attacks.
- Tools/products: “Safety Circuit Atlas” across model families; shared neuron indices; transfer ASR analysis.
- Dependencies/assumptions: Family similarity in architecture/init/alignment; matching layer geometry; careful control of confounders.
- Policy and Governance (Compliance, Certification)
- MoE-specific safety certification and audit requirements
- Use-case: Update standards to include gate-level routing tests, expert ablation checks, and neuron-level robustness assessments in certification processes.
- Tools/products: Audit protocols; conformance test suites; reporting templates for safety concentration and resilience metrics.
- Dependencies/assumptions: Regulator access to telemetry; standardized harmful/benign test sets; due-process safeguards.
- Sector-specific use-cases
- Healthcare and Finance (regulated assistants, decision support)
- Use-case: Pre-deployment safety profiling of MoE assistants to verify refusal consistency under harmful inputs and resilience to runtime hooks.
- Tools/products: Router telemetry audits; “Refusal Consistency Benchmarks” integrated into QA; external adjudication (multi-judge ensembles).
- Dependencies/assumptions: Sector policies; robust logging; legal data handling.
- Content Moderation (platforms, VLMs)
- Use-case: Evaluate MoE VLMs for image/text unsafe response risks; ensure moderation pipelines are resilient to gate-guided bypasses.
- Tools/products: Unsafe image corpora; ASR dashboards for VLMs; gate-aware moderation checks.
- Dependencies/assumptions: Access to VLM routing and activations; clear definitions of policy categories; multi-modal judges.
- Education (EdTech)
- Use-case: Vet MoE tutors for safe refusal behavior across curricula; detect manipulation pathways that could bypass safety circuits.
- Tools/products: Course-aligned harmful/benign corpora; integrity monitors; model-card safety summaries for schools.
- Dependencies/assumptions: White-box or enhanced telemetry access; age-appropriate policy frameworks.
- Daily Life (Consumer AI)
- Trust labels and safety summaries in model cards
- Use-case: Provide concise safety resilience indicators for consumer MoE chatbots; communicate transparency around routing, expert safety distribution, and mitigations.
- Tools/products: “Safety Resilience Score” badge; user-facing disclosures on model updates; opt-in telemetry for safety monitoring.
- Dependencies/assumptions: Vendor willingness to expose non-sensitive metrics; understandable UX.
Long-Term Applications
These applications require further research, scaling, standardization, or engineering to become broadly viable.
- Industry (Architecture and Training)
- Safety distribution and redundancy by design in MoE training
- Use-case: Train MoEs to encode refusal behavior redundantly across multiple experts and layers (shared+sparse) to reduce single-point-of-failure at inference-time.
- Tools/products: Safety-aware routing regularizers; multi-expert safety ensembles; adversarial co-training that penalizes safety neuron concentration.
- Dependencies/assumptions: Access to training pipeline; data diversity; careful utility–safety tradeoff; compute budgets.
- Robust gating mechanisms and secure routing
- Use-case: Harden gate modules against manipulation via cryptographic attestation, secure enclaves, or isolated execution; detect deviations in gate logits distribution.
- Tools/products: Trusted Execution Environments for inference; cryptographic signatures on routing decisions; runtime attestation APIs.
- Dependencies/assumptions: Hardware support; latency/throughput constraints; secure key management.
- Academia (Formal Methods, Theory)
- Formal verification of safety alignment under conditional computation
- Use-case: Prove lower bounds on refusal consistency for MoE architectures given top-k routing and expert partitions.
- Tools/products: Safety contracts for gates/experts; compositional verification frameworks; probabilistic guarantees over routing.
- Dependencies/assumptions: Formalizable abstractions of transformers; tractable analysis for large models.
- Neuron-level defensive editing and resilient feature synthesis
- Use-case: Construct “defense circuits” that are robust to inference-time masking, e.g., safety features embedded across multiple projections or consensus layers.
- Tools/products: Defense-oriented model editing; feature replication across layers; redundant safety neurons with mutual checks.
- Dependencies/assumptions: Reliable interpretability tools; minimal utility degradation; scalable editing methods.
- Policy and Governance (Standards, Regulation)
- MoE-specific safety standards and attestations
- Use-case: Require providers to certify that safety alignment is not narrowly concentrated, to withstand GateBreaker-style attacks; mandate gate telemetry and integrity controls.
- Tools/products: International standards for MoE routing auditability; certification bodies that run white-box tests; reporting of “Safety Neuron Ratio” and route balance metrics.
- Dependencies/assumptions: Industry consensus; regulatory capacity; privacy and IP considerations.
- Incident response norms for inference-time tampering
- Use-case: Establish disclosure timelines and remediation protocols when safety circuits are compromised via runtime hooks in hosted or third-party environments.
- Tools/products: Sector-specific playbooks; shared registries; insurance underwriting tied to resilience metrics.
- Dependencies/assumptions: Legal frameworks; cross-industry cooperation.
- Sector-specific defense innovations
- Healthcare/Finance: End-to-end resilient assistants
- Use-case: Architect MoE assistants with safety redundancy, secure routing, and mandatory shared safety experts always active on high-risk domains.
- Tools/products: Domain-adaptive safe experts; risk-aware gating; multimodal safety consensus layers.
- Dependencies/assumptions: Regulatory acceptance; audited training; cost of secure inference.
- Content Moderation and VLMs: Safety tripwires for multimodal MoEs
- Use-case: Embed multimodal tripwires across visual and textual pathways to ensure refusal survives targeted neuron masking; cross-modal consistency checks.
- Tools/products: Multimodal safety ensembles; image-text alignment constraints; auditor VLMs in the loop.
- Dependencies/assumptions: Robust datasets; multi-judge evaluation; scalability.
- Daily Life (Consumer AI ecosystems)
- Safety-by-default platforms with attested inference
- Use-case: Consumer devices and apps run MoE models inside attested environments that block unauthorized activation hooks, with periodic self-checks and user-visible health indicators.
- Tools/products: Secure model serving on edge; OS-level AI integrity services; safety health dashboards.
- Dependencies/assumptions: Platform vendor support; hardware capabilities; UX acceptance.
Cross-cutting assumptions and dependencies
- White-box access is central to both GateBreaker-style attacks and audit tooling; defenses must assume adversaries can instrument inference in compromised environments.
- Transferability of safety neurons is strongest within model families sharing architecture and alignment; generalization across unrelated models may vary.
- Reliability of safety judges (e.g., LLM-based classifiers) impacts measured ASR; multi-judge ensembles and human checks mitigate judge hacking.
- Datasets used for profiling (harmful/benign corpora) must be policy-compliant, representative, and refreshed to avoid overfitting.
- Runtime patching and telemetry introduce overhead; engineering optimizations and hardware support (TEEs, attestation) are needed for production settings.
- Ethical use: Attack methods should be confined to authorized safety testing, certification, and research; misuse prevention requires governance and secure deployment practices.
Collections
Sign up for free to add this paper to one or more collections.